一种基于机器学习的集群配置自动优化方法和系统与流程
[0001]
本发明涉及分布式搜索引擎技术领域,尤其涉及一种基于机器学习的集群配置自动优化方法和系统。
背景技术:
[0002]
目前,集群的应用日益普及,例如,elasticsearch是一种使用广泛的分布式搜索引擎。由于elasticsearch通常应用于有巨大吞吐量需求的场景之中,其性能对提高工业生产效率有着非常重要的影响。在使用中,常常需要让插入数据或检索数据的速度满足指定的要求。但由于其配置选项的数目较多,往往很难手动调整参数使其达到最优性能。
[0003]
对于elasticsearch的性能优化,目前主要是采用手动调优的方式。在了解elasticsearch集群的原理后,结合一些优化策略,手动调整集群的配置参数。
[0004]
然而,elasticsearch拥有上百个配置选项,对于不同的数据和软硬件环境来说,能达到最佳性能的配置参数是不同的。大量的配置参数在给软件使用带来灵活性的同时,也给有性能优化需求的使用者带来了负担。不同的配置选项对性能指标有不同的影响,他们彼此之间也存在相关性。使用者必须对搜索引擎的工作过程和结构有深入的了解,才能在不同的情况下对配置参数做出合适的调整,在一定程度上提高集群的性能。由于大量参数与性能关系的复杂性,在实际使用过程中,经常出现不当配置,使得工作效率大幅下降,甚至集群崩溃的情况。
[0005]
因此,需要对现有技术进行改进,提供面向集群的配置自动优化方法。
技术实现要素:
[0006]
本发明的目的在于克服上述现有技术的缺陷,提供一种基于机器学习的集群配置自动优化方法和系统,能够利用机器学习方法自动高效地获得最优的配置参数,从而显著改善集群性能。
[0007]
根据本发明的第一方面,提供了一种基于机器学习的集群配置自动优化方法。该方法包括以下步骤:
[0008]
收集训练样本集,该训练样本集反映配置参数和集群性能的对应关系;
[0009]
基于所述训练样本集通过机器学习获得集群性能预测模型,将待优化的多组配置参数输入到所述集群性能预测模型,获得各组配置参数的预测的集群性能;
[0010]
对于待优化的各组配置参数,以预测的集群性能作为其适应值,利用遗传算法寻找使集群性能最优的配置参数。
[0011]
在一个实施例中,收集训练样本集包括:
[0012]
对于随机产生的一组配置参数,将其划分为静态配置部分和动态配置部分;
[0013]
将静态配置部分在启动集群前写入到文件中,并将该文件发送到集群的各节点,将动态配置部分在启动集群后提供给集群的应用程序编程接口,并向集群发出修改配置参数的请求;
[0014]
在集群修改所请求的配置参数后,通过运行基准测试程序,获得该组配置参数对应的集群性能。
[0015]
在一个实施例中,运行基准测试程序包括:
[0016]
在elasticsearch集群上,搭建esrally集群,在各节点上启动rally守护进程,该守护进程允许rally与远程计算机进行通信;
[0017]
在所搭建的esrally集群中选择一个节点作为运行rally测试的基准协调器;
[0018]
运行数据收集脚本,收集各组配置参数对应的集群性能。
[0019]
在一个实施例中,基于所述训练样本集通过机器学习获得集群性能预测模型包括:构建包含多个回归树的随机森林模型;对所述训练样本集进行随机抽样,得到多个大小相同的子样本集,利用子样本集对各回归树独立进行训练;将回归结果进行算术平均作为训练的最终结果。
[0020]
在一个实施例中,利用遗传算法寻找使集群性能最优的配置参数包括:
[0021]
步骤s51:产生n组随机配置参数作为初始种群,其中,n是大于等于2的整数;
[0022]
步骤s52:将该n组随机配置参数输入到所述集群性能预测模型,获得各组配置参数对应的集群性能作为适应值,并保存最小适应值对应的配置参数组合,作为父代的最优配置参数;
[0023]
步骤s53:根据适应值大小进行个体选择,并进行基因交叉和变异,产生n-1组新的配置参数;
[0024]
步骤s54:将所获得的父代最优配置参数和所产生的n-1组新的配置参数复制到子代中,得到子代种群;
[0025]
步骤s55:通过对子代种群进行迭代搜索,寻找使集群性能最优的一组配置参数。
[0026]
在一个实施例中,利用遗传算法寻找使集群性能最优的配置参数包括:
[0027]
产生n组随机配置参数作为初始种群,并指定迭代次数,其中n为大于等于2的整数;
[0028]
基于所述集群性能预测模型获得各组配置参数对应的集群性能,作为其适应值,保存其中适应值最小的一组配置参数,作为父代最优配置参数;
[0029]
每次从种群中随机选择两组配置参数,比较其适应值大小,将较小的一组配置参数复制到子代种群中,重复该过程,直到子代种群的大小比父代种群小1;
[0030]
对于所选择的两组配置参数中一组配置参数,有0.6的概率在其中随机选择k个配置,再从另一组中随机选择n-k个配置,得到一组新的配置参数,其中k小于n;
[0031]
对于所选择的两组配置参数中的一组配置参数,有0.01的概率进行基因突变操作,随机选择该组配置中的一个配置参数,在指定取值范围和步长的情况下进行随机取值;
[0032]
将所保存的父代最优配置参数复制到子代中,得到一个与父代种群大小相等的子代种群,对该种群进行迭代操作,直到达到指定的迭代次数。
[0033]
在一个实施例中,基于elasticsearch的索引操作与查询操作的特征选择所述待优化的配置参数。
[0034]
在一个实施例中,在收集各组配置参数对应的集群性能时,以索引操作的99%时延和查询操作的99.9%时延作为性能指标。
[0035]
根据本发明的第二方面,提供一种基于机器学习的集群配置自动优化系统。该系
统包括:
[0036]
用于收集训练样本集的模块,其中该训练样本集反映配置参数和集群性能的对应关系;
[0037]
用于基于所述训练样本集通过机器学习获得集群性能预测模型,将待优化的多组配置参数输入到所述集群性能预测模型,获得各组配置参数的预测的集群性能的模块;
[0038]
用于对于待优化的各组配置参数,以预测的集群性能作为其适应值,利用遗传算法寻找使集群性能最优的配置参数的模块。
[0039]
与现有技术相比,本发明的优点在于:在不同的情况下,自动为当前集群选择一组能够优化性能的配置参数,保证能够最大程度的利用集群资源,达到最佳性能。本发明通过自动优化方法,用户可以通过例如在集群上运行数据收集功能,收集性能数据,从而得到一个能预测集群在不同配置下性能表现的性能模型;通过在配置参数优化过程中调用该模型,找到一组使现有集群性能达到最优的配置参数组合。
附图说明
[0040]
以下附图仅对本发明作示意性的说明和解释,并不用于限定本发明的范围,其中:
[0041]
图1是根据本发明一个实施例的基于机器学习的集群配置自动优化方法的流程图;
[0042]
图2是根据本发明一个实施例的性能数据收集过程的示意图;
[0043]
图3是根据本发明一个实施例的获取集群性能预测模型的流程图;
[0044]
图4是根据本发明一个实施例的寻找优化配置参数过程的示意图。
[0045]
图5是根据本发明一个实施例的基于机器学习的集群自动优化系统的框架图;
具体实施方式
[0046]
为了使本发明的目的、技术方案、设计方法及优点更加清楚明了,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
[0047]
在本文示出和讨论的所有例子中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它例子可以具有不同的值。
[0048]
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。
[0049]
本发明实施例提供一种基于机器学习的集群配置自动调优方法,简言之,该方法包括:数据收集过程,用于获取配置参数组合和集群性能情况的对应关系的样本数据集;机器学习训练过程,用于利用机器学习训练获得集群性能预测模型;配置参数优化过程,用于通过调用集群性能预测模型,利用遗传算法寻找使集群性能最优的配置参数组合。在下文中,将以elasticsearch集群为例进行介绍,但应理解的是,所描述的方法同样适用于其他类型的集群。
[0050]
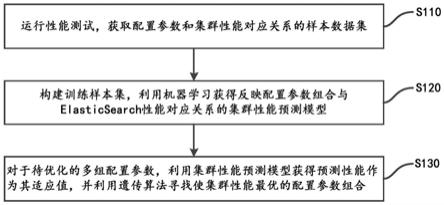
具体地,参见图1所示,该方法包括以下步骤:
[0051]
步骤s110,运行性能测试,获取配置参数和集群性能对应关系的样本数据集。
[0052]
首先,基于elasticsearch的操作特点,选择待优化的配置项。例如,考虑到
elasticsearch有两个主要操作:索引操作与查询操作,针对这两个操作的工作过程,分别选取一部分性能敏感的配置选项,同时还有一些对于两种操作均有影响的配置,如jvm的堆大小,也纳入待优化的配置项中。例如,配置项包括但不限于设置jvm相关运行参数的环境变量、配置索引的分片和副本数量、节点锁住内存等。
[0053]
性能数据的数据过程是:在选择待优化的配置项之后,随机产生一组配置参数后,将其配置到集群,使用esrally压力测试工具提供的数据集测试集群性能,获取测试报告中的性能数据。例如,在现有的elasticsearch集群上,搭建esrally集群,在各节点上启动rally守护进程,该守护进程允许rally与所有远程计算机进行通信;选中其中一个节点作为运行rally测试的基准协调器;运行数据收集脚本,收集性能数据。
[0054]
具体地,参见图2的实施例,一次样本数据收集的过程包括:首先,将随机产生的一组配置参数分为两部分,即静态配置部分和动态配置部分,其中,静态配置部分在启动集群前写入elasticsearch.yml文件中,再将该文件发送到各节点,来保证各节点配置的一致性;动态配置部分在启动集群后通过elasticsearch提供的api(例如,cluster-update-settings api),向整个集群发出修改配置参数的请求;修改完成后通过esrally运行一次基准测试程序,测试运行结束后从csv格式的测试报告文件中获取索引操作的99%时延和查询操作的99.9%时延作为性能指标;最后,将本次测试的配置参数组合与性能指标写入文件。
[0055]
例如,针对每个数据集产生400组随机配置参数组合,对其中的每一组都进行10分钟左右的性能测试,获取对应的性能表现,形成后续机器学习训练的输入样本数据。
[0056]
应理解的是,本发明实施例中的性能指标包括但不限于时延、资源利用率等。本文主要以时延为例进行介绍。
[0057]
步骤s120,构建训练样本集,利用机器学习获得反映配置参数组合与elasticsearch性能对应关系的集群性能预测模型。
[0058]
在此步骤中,通过训练集群性能预测模型,拟合在不同的配置参数下elasticsearch的性能表现。由于配置参数数量较多,形成了一个高维的参数空间,本发明实施例通过机器学习模型,输入一定大小的训练样本集,建立精确度较高的回归模型,从而能够预测在不同的配置参数下,elasticsearch对应的性能。
[0059]
例如,参见图3所示,以训练随机森林为例,使用收集到的样本数据作为训练样本集,训练随机森林模型,该随机森林模型包含多个回归树。训练过程包括:对训练样本集进行随机抽样(数据预处理),得到多个大小相同的子样本集,使用子样本集对各个回归树独立训练,回归结果进行算术平均作为模型训练的最终结果。
[0060]
通过训练,能够获得集群性能预测模型,对于新的配置参数组合,将其输入到已保存的集群性能预测模型,即可获得elasticsearch集群的性能预测结果,形成平均拟合度达到80%的性能预测模型。
[0061]
需说明的是,本发明实施例中随机森林模型也可替换为其他的回归分析模型。
[0062]
步骤s130,对于待优化的多组配置参数,利用集群性能预测模型获得预测性能作为其适应值,并利用遗传算法寻找使集群性能最优的配置参数组合。
[0063]
为了在配置参数组合形成的高维空间里寻找一个最优解,在此步骤中,使用遗传算法,通过反复调用已获得的集群性能预测模型,得到在不同的数据集和不同的系统条件
下,使集群性能达到最优的一组配置参数,在本文中,将此过程称为配置参数组合优化。
[0064]
在一个实施例中,配置参数组合优化过程包括:
[0065]
步骤s201,产生n组随机配置作为初始种群。
[0066]
步骤s202,根据集群性能模型预测各组配置的适应值,并保存其中最佳配置,例如,采用时延作为性能指标时,较小适应值对应的是最佳配置。
[0067]
步骤s203,进行个体选择、基因交叉和变异,产生n-1组新的配置组合。
[0068]
步骤s204,将步骤s202得到的父代最优配置组合和步骤s203得到的n-1组新的配置组合复制到子代中,得到子代种群。
[0069]
步骤s205:对子代种群进行下一轮迭代搜索,返回步骤s202。
[0070]
根据上述过程,在多次优胜劣汰后,找到全局最优的一组配置参数。
[0071]
具体地,参见图4所示,使用遗传算法的思想寻找全局最优配置参数的过程包括:
[0072]
(1)、产生多组(例如n组)随机配置参数作为初始种群,并指定迭代次数,其中n大于等于2;
[0073]
(2)、根据集群性能模型预测各组配置参数对应的性能指标作为其适应值,保存其中适应值最小的一组配置参数,作为父代最优配置参数;
[0074]
(3)、进行个体选择,例如,采用锦标赛选择的方法,每次从种群中随机选择两组配置参数,比较其适应值大小,将适应值较小的一组复制到子代种群中,重复该过程,直到子代种群的大小比父代种群小1;
[0075]
(4)、进行基因交叉,例如,对于一组配置参数,有0.6的概率在其中随机选择k个配置参数,再从另一组中随机选择n-k个配置参数,得到一组新的配置参数,其中k小于n;
[0076]
(5)、进行基因突变,例如,有0.01的概率对一组配置参数进行基因突变操作,随机选择该组配置参数中的一个配置参数,在指定取值范围和步长的情况下进行随机取值;
[0077]
(6)、将(2)中保存的父代最优配置参数复制到子代中,此时得到了一个与父代种群大小相等的子代种群(新配置组合种群),对该子代种群进行下一轮迭代操作,跳转到步骤(2),直到达到指定的迭代次数。
[0078]
具体实施时,本发明还提供一种基于机器学习的elasticsearch自动调优系统,该系统可实现上述方法的一个方面或多个方面。例如,参见图5所示,该系统包括:数据收集模块,预测模块,优化模块,其中,数据收集模块利用现有的elasticsearch集群,运行多组性能测试,将每组的配置参数和性能指标记录下来,作为样本数据;预测模块基于样本数据进行训练,拟合出配置参数与性能指标间的回归关系,获得集群性能预测模型;优化模块随机产生多组配置参数,不断调用经训练的集群性能预测模型来评估各组配置参数的性能表现,例如,结合遗传算法最终选取最优的一组配置参数。
[0079]
综上所述,本发明实施例提供的基于机器学习的集群配置自动调优的方法和系统能够实现自动化地配置参数调优;利用机器学习获得的集群性能预测模型能够准确地拟合配置参数组合和集群性能之间的关系;在配置参数优化过程中,通过反复调用集群性能预测模型并结合遗传算法,能够快速地找出最优的配置参数,而不会陷入局部最优解的快速下降陷阱;此外利用遗传算法的内在并行性,能够方便地进行分布式计算,加快求解速度。
[0080]
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺
序,只要能够实现所需要的功能即可。
[0081]
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
[0082]
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
[0083]
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1