基于深度学习和注意力机制的单目视觉里程计算方法与流程
本发明属于移动机器人自主定位领域,具体涉及基于深度学习和注意力机制的单目视觉里程计算方法。
背景技术:
视觉里程计技术是视觉同时定位与地图构建中的前端技术。通过视觉里程计得到帧间位姿估计可以获取局部地图,该局部地图经过后端优化后可以得到里程计所经过的路径的全局地图。从而可以进一步进行地图构建和三维重建等任务。
视觉里程计技术被广泛应用于移动机器人自主定位、自动驾驶、虚拟现实技术中,是近年来的热门研究领域。视觉里程计技术的主要研究任务是利用视觉特征向量来进行准确的帧间位姿估计。传统的视觉里程计技术分为直接法和特征向量点法。特征向量点法通过匹配相邻帧间的特征向量来估计相机位姿,其性能直接受特征向量设计的合理性以及特征向量匹配的准确性影响。由于特征向量的设计具有极强的人为性,导致所设计的特征向量具有局限性,使用特征向量点忽略了除特征向量点以外的其它信息。而且相机可能运动到特征向量点缺失的地方,这些地方没有明显的纹理信息。除此之外特征向量点的提取和描述子的计算十分耗时。直接法通过最小化光度误差来估计相机运动和像素的空间位置,其能够在特征向量不明显的场景中,例如走廊或者光滑的墙面上,取得较好的效果,但其只适用于运动幅度较小、图片整体亮度变化不大的情形。
传统的视觉里程计算方法都存在着以下两个问题:第一,必须需要知道相机的内参;第二,存在着精度与速度之间的艰难取舍。
技术实现要素:
针对现有技术中的上述不足,本发明提供的基于深度学习和注意力机制的单目视觉里程计算方法解决了传统的视觉里程计算方法存在的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种基于深度学习和注意力机制的单目视觉里程计算方法,包括以下步骤:
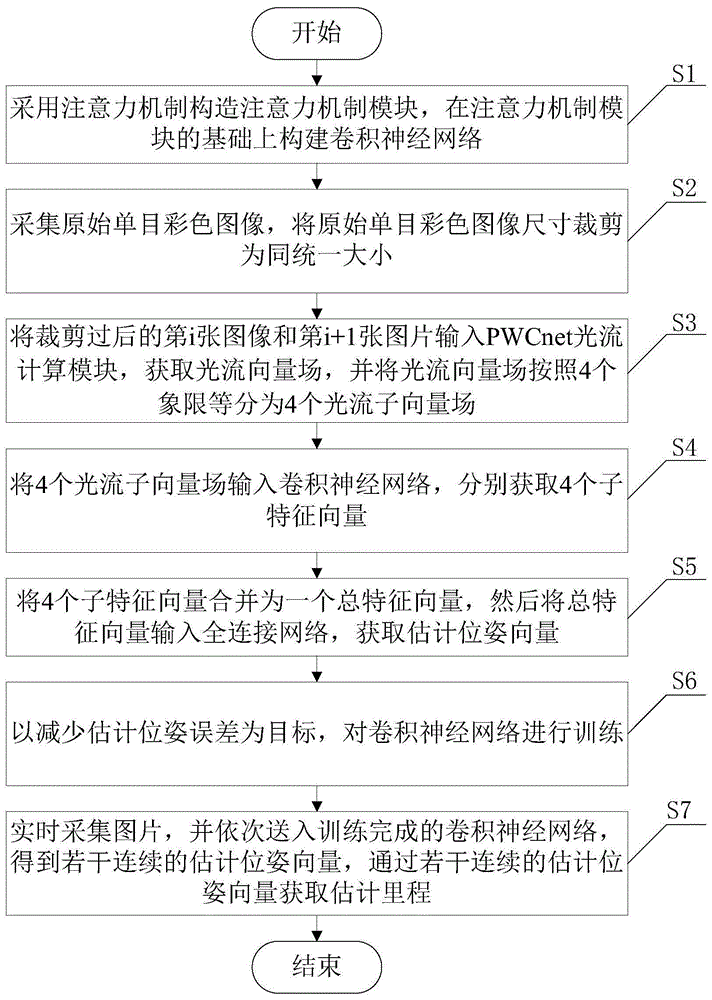
s1、采用注意力机制构造注意力机制模块,并在注意力机制模块的基础上构建卷积神经网络;
s2、采集原始单目彩色图像,并将原始单目彩色图像尺寸裁剪为统一大小;
s3、将裁剪过后的第i张图像和第i+1张图片输入pwcnet光流计算模块,获取光流向量场,并将光流向量场按照4个象限等分为4个光流子向量场;
s4、将4个光流子向量场输入卷积神经网络,分别获取4个子特征向量;
s5、将4个子特征向量合并为一个总特征向量,然后将总特征向量输入全连接网络,获取估计位姿向量;
s6、以减少估计位姿误差为目标,对卷积神经网络进行训练;
s7、实时采集图片,并依次送入训练完成的卷积神经网络,得到若干连续的估计位姿向量,通过若干连续的估计位姿向量获取估计里程。
进一步地,所述卷积神经网络包括4条通道,所述4条通道的结构相同,均包括依次连接的第一卷积层、第一注意力机制模块、第二卷积层、第二注意力机制模块和第一特征向量合并模块,所述第一注意力机制模块还与第一特征向量合并模块的输入端连接,所述第一特征向量合并模块用于将第一注意力机制模块的输出数据和第二注意力机制模块输出数据组合;
所述第一卷积层为卷积核大小为9×9且卷积核数量为64的卷积层,所述第二卷积层为卷积核大小为3×3且卷积核数量为20的卷积层。
进一步地,所述第一注意力机制模块和第二注意力机制模块结构相同,均包括通道注意力模块和空间注意力模块;
所述通道注意力模块包括第一最大池化层、第一平均池化层、多层感知机、第一加法器和第一sigmoid激励函数单元,所述第一最大池化层的输入端为注意力机制模块的第一输入端,所述第一平均池化层的输入端为注意力机制模块的第二输入端,所述第一最大池化层的输出端和第一平均池化层的输出端分别与多层感知机的输入端连接,所述多层感知机的输出端与第一加法器的输入端连接,所述第一加法器的输出端与第一sigmoid激励函数单元的输入端连接;
所述空间注意力模块包括第二最大池化层、第二平均池化层、第二加法器、上卷积层和第二sigmoid激励函数单元,所述第二最大池化层的输入端和第二平均池化层的输入端分别与第一sigmoid激励函数单元的输出端连接,所述第二最大池化层的输出端和第二平均池化层的输出端分别与第二加法器的输入端连接,所述第二加法器的输出端与上卷积层的输入端连接,所述上卷积层的输出端与第二sigmoid激励函数单元的输入端连接,所述第二sigmoid激励函数单元的输出端为注意力机制模块的输出端。
进一步地,所述步骤s2中将原始单目彩色图像尺寸裁剪为1226×370×3,其中1226为图片宽度,370为图片高度,3为通道数。
进一步地,所述步骤s3中光流向量场数据格式为1226×370×2,其中1226为图片宽度,370为图片高度,2为通道数;4个光流子向量场数据格式均为613×185×2,其中613为图片宽度,185为图片高度,2为通道数。
进一步地,所述步骤s4中将4个光流子向量场输入卷积神经网络具体为:将第一象限的光流子向量场输入卷积神经网络的第一通道,将第二象限的光流子向量场输入卷积神经网络的第二通道,将第三象限的光流子向量场输入卷积神经网络的第三通道,将第四象限的光流子向量场输入卷积神经网络的第四通道;
所述4个光流子向量场在与其对应的通道中均经过以下步骤:
a1、通过第一卷积层提取数据维度为6×20×64的第一特征向量;
a2、将第一特征向量传递给第一注意力机制模块进行优化,获得数据维度为6×20×64的第二特征向量;
a3、将第二特征向量传输给第二卷积层,通过第二卷积层获取数据维度为2×5×20的第三特征向量;
a4、将第三特征向量传递给第二注意力机制模块进行优化,获得数据维度为2×5×20的第四特征向量;
a5、将数据维度为6×20×64的第二特征向量拉直成长度为7680的第五特征向量,将数据维度为2×5×20的第四特征向量拉直成长度为200的第六特征向量;
a6、通过第一特征向量合并模块将第一特征向量和第二特征向量合并为长度为7880的第七特征向量;
将4个光流子向量场对应4个第七特征向量作为4个子特征向量。
进一步地,所述步骤s5包括以下分步骤:
s5.1、通过第二特征向量合并模块将卷积神经网络4个通道输出的特征向量合并为长度为31520的第八特征向量,并将第八特征向量作为总特征向量;
s5.2、将第八特征向量传输给全连接网络中节点数为1024的第一全连接层处理后,经过一个elu激励函数,获取激励结果;
s5.3、将激励结果传递给第二全连接层,获取6自由度的估计位姿向量。
进一步地,所述步骤s6中对卷积神经网络进行训练的过程为:通过估计位姿向量获取估计位姿向量误差,根据深度学习理论,使用adam优化器对卷积神经网络进行训练,使估计位姿向量误差下降至0.1时训练完成。
进一步地,所述估计位姿向量误差loss为:
loss=||tpred-ttruth||2+β||rpred-rtruth||2(1)
对卷积神经网络的训练时,将初始学习率设置为1×10-4,将训练过程每次传入神经网络的光流向量场个数设置为32,将训练的轮数设置为100,前70轮训练保持学习率保持不变,后30轮训练将学习率衰减至1×10-5;
其中,rpred为预测的旋转向量,rtruth为实际的旋转向量,tpred为预测位移向量,ttruth表示实际的位移向量,β表示平衡系数。
进一步地,所述估计里程s为:
s=[s0,s1,s2,...,sn-1,sn](2)
其中,si表示第i次运动的估计位资向量,i=1,2,...n,xi表示第i次运动x轴的分量,yi表示第i次运动y轴的分量,zi表示第i次运动z轴的分量,φi表示旋转向量ri的在xy平面的欧拉角分量,θi表示旋转向量ri的在yz平面的欧拉角分量,
本发明的有益效果为:
(1)本发明卷积神经网络来进行特征向量提取,避免了传统特征向量提取方法的特征向量人为性大的问题,同时使用全连接层回归位姿的方法也避开了复杂的特征向量匹配计算,大大提高了运算速度。
(2)本发明中的光流提取算法是一种十分高效快速的深度学习算法,这也提高了算法的整体速度。
(3)本发明采用注意力机制构造注意力机制模块,在注意力机制模块的基础上构建卷积神经网络,注意力机制模块对卷积神经网络的优化作用使整个神经网络进行视觉里程估计更加准确,保证了里程估计的高精度。
(4)本发明与传统的方法相比无需手动获知相机参数,是一种全自动的视觉里程计实现方法。
(5)本发明作为一种单目视觉里程计算方法,其位移精度可与双目视觉里程计算方法媲美。
附图说明
图1为本发明提出的基于深度学习和注意力机制的单目视觉里程计算方法流程图。
图2为本发明提出的卷积神经网络的示意图。
图3为本发明提出的注意力机制模块示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
下面结合附图详细说明本发明的实施例。
如图1所示,一种基于深度学习和注意力机制的单目视觉里程计算方法,包括以下步骤:
s1、采用注意力机制构造注意力机制模块,并在注意力机制模块的基础上构建卷积神经网络;
s2、采集原始单目彩色图像,并将原始单目彩色图像尺寸裁剪为统一大小;
s3、将裁剪过后的第i张图像和第i+1张图片输入pwcnet光流计算模块,获取光流向量场,并将光流向量场按照4个象限等分为4个光流子向量场;
s4、将4个光流子向量场输入卷积神经网络,分别获取4个子特征向量;
s5、将4个子特征向量合并为一个总特征向量,然后将总特征向量输入全连接网络,获取估计位姿向量;
s6、以减少估计位姿误差为目标,对卷积神经网络进行训练;
s7、实时采集图片,并依次送入训练完成的卷积神经网络,得到若干连续的估计位姿向量,通过若干连续的估计位姿向量获取估计里程。
如图2所示,卷积神经网络包括4条通道,所述4条通道的结构相同,均包括依次连接的第一卷积层、第一注意力机制模块、第二卷积层、第二注意力机制模块和第一特征向量合并模块,所述第一注意力机制模块还与第一特征向量合并模块的输入端连接,所述第一特征向量合并模块用于将第一注意力机制模块的输出数据和第二注意力机制模块输出数据组合.
所述第一卷积层为卷积核大小为9×9且卷积核数量为64的卷积层,所述第二卷积层为卷积核大小为3×3且卷积核数量为20的卷积层。
第一注意力机制模块和第二注意力机制模块结构相同,均包括通道注意力模块和空间注意力模块;
如图3所示,通道注意力模块包括第一最大池化层、第一平均池化层、多层感知机、第一加法器和第一sigmoid激励函数单元,所述第一最大池化层的输入端为注意力机制模块的第一输入端,所述第一平均池化层的输入端为注意力机制模块的第二输入端,所述第一最大池化层的输出端和第一平均池化层的输出端分别与多层感知机的输入端连接,所述多层感知机的输出端与第一加法器的输入端连接,所述第一加法器的输出端与第一sigmoid激励函数单元的输入端连接。空间注意力模块包括第二最大池化层、第二平均池化层、第二加法器、上卷积层和第二sigmoid激励函数单元,所述第二最大池化层的输入端和第二平均池化层的输入端分别与第一sigmoid激励函数单元的输出端连接,所述第二最大池化层的输出端和第二平均池化层的输出端分别与第二加法器的输入端连接,所述第二加法器的输出端与上卷积层的输入端连接,所述上卷积层的输出端与第二sigmoid激励函数单元的输入端连接,所述第二sigmoid激励函数单元的输出端为注意力机制模块的输出端。
步骤s2中将原始单目彩色图像尺寸裁剪为1226×370×3,其中1226为图片宽度,370为图片高度,3为通道数。
步骤s3中光流向量场数据格式为1226×370×2,其中1226为图片宽度,370为图片高度,2为通道数;4个光流子向量场数据格式均为613×185×2,其中613为图片宽度,185为图片高度,2为通道数。
步骤s4中将4个光流子向量场输入卷积神经网络具体为:将第一象限的光流子向量场输入卷积神经网络的第一通道,将第二象限的光流子向量场输入卷积神经网络的第二通道,将第三象限的光流子向量场输入卷积神经网络的第三通道,将第四象限的光流子向量场输入卷积神经网络的第四通道;
所述4个光流子向量场在与其对应的通道中均经过以下步骤:
a1、通过第一卷积层提取数据维度为6×20×64的第一特征向量;
a2、将第一特征向量传递给第一注意力机制模块进行优化,获得数据维度为6×20×64的第二特征向量;
a3、将第二特征向量传输给第二卷积层,通过第二卷积层获取数据维度为2×5×20的第三特征向量;
a4、将第三特征向量传递给第二注意力机制模块进行优化,获得数据维度为2×5×20的第四特征向量;
a5、将数据维度为6×20×64的第二特征向量拉直成长度为7680的第五特征向量,将数据维度为2×5×20的第四特征向量拉直成长度为200的第六特征向量;
a6、通过第一特征向量合并模块将第一特征向量和第二特征向量合并为长度为7880的第七特征向量;
将4个光流子向量场对应4个第七特征向量作为4个子特征向量。
步骤s5包括以下分步骤:
s5.1、通过第二特征向量合并模块将卷积神经网络4个通道输出的特征向量合并为长度为31520的第八特征向量,并将第八特征向量作为总特征向量;
s5.2、将第八特征向量传输给全连接网络中节点数为1024的第一全连接层处理后,经过一个elu激励函数,获取激励结果;
s5.3、将激励结果传递给第二全连接层,获取6自由度的估计位姿向量。
步骤s6中对卷积神经网络进行训练的过程为:通过估计位姿向量获取估计位姿向量误差,根据深度学习理论,使用adam优化器对卷积神经网络进行训练,使估计位姿向量误差下降至0.1时训练完成。
估计位姿向量误差loss为:
loss=||tpred-ttruth||2+β||rpred-rtruth||2(1)
对卷积神经网络的训练时,将初始学习率设置为1×10-4,将训练过程每次传入神经网络的光流向量场个数设置为32,将训练的轮数设置为100,前70轮训练保持学习率保持不变,后30轮训练将学习率衰减至1×10-5;
其中,rpred为预测的旋转向量,rtruth为实际的旋转向量,tpred为预测位移向量,ttruth表示实际的位移向量,β表示平衡系数。
进一步地,所述估计里程s为:
s=[s0,s1,s2,...,sn-1,sn](2)
其中,si表示第i次运动的估计位资向量,i=1,2,...n,xi表示第i次运动x轴的分量,yi表示第i次运动y轴的分量,zi表示第i次运动z轴的分量,φi表示旋转向量ri的在xy平面的欧拉角分量,θi表示旋转向量ri的在yz平面的欧拉角分量,
在本实施例中,特征数据进入注意力机制模块后,经过以下步骤:
b1、输入的特征数据分别输入第一最大池化层和第一平均池化层中,获取两种优化过后的特征;
b2、两种优化过后的特征经过多层感知机处理后,经过第一加法器组合,获取第一组合特征;
b3、第一组合特征经过第一sigmoid激励函数单元激励后,获取通道域优化特征;
b4、通道域优化特征分别输入第二最大池化层和第二平均池化层中,将两种优化过后的特征经过第二加法器组合后,获取第二组合特征;
b5、第二组合特征经过上卷积层处理后,经过第二sigmoid激励函数单元激励,获取空间域优化特征。
其中,空间域优化特征为注意力机制模块的输出数据。
本发明卷积神经网络来进行特征向量提取,避免了传统特征向量提取方法的特征向量人为性大的问题,同时使用全连接层回归位姿的方法也避开了复杂的特征向量匹配计算,大大提高了运算速度。
本发明中的光流提取算法是一种十分高效快速的深度学习算法,这也提高了算法的整体速度。
本发明采用注意力机制构造注意力机制模块,在注意力机制模块的基础上构建卷积神经网络,注意力机制模块对卷积神经网络的优化作用使整个神经网络进行视觉里程估计更加准确,保证了里程估计的高精度。
本发明与传统的方法相比无需手动获知相机参数,是一种全自动的视觉里程计实现方法。本发明作为一种单目视觉里程计算方法,其位移精度可与双目视觉里程计算方法媲美。
- 还没有人留言评论。精彩留言会获得点赞!