一种车道线动态检测和车道分界线的拟合方法与流程
本发明涉及一种道路交通标志检测领域,尤其是涉及一种基于条件对抗深度网络的车道线动态检测方法和面向抛物线的车道线建模方法。
背景技术:
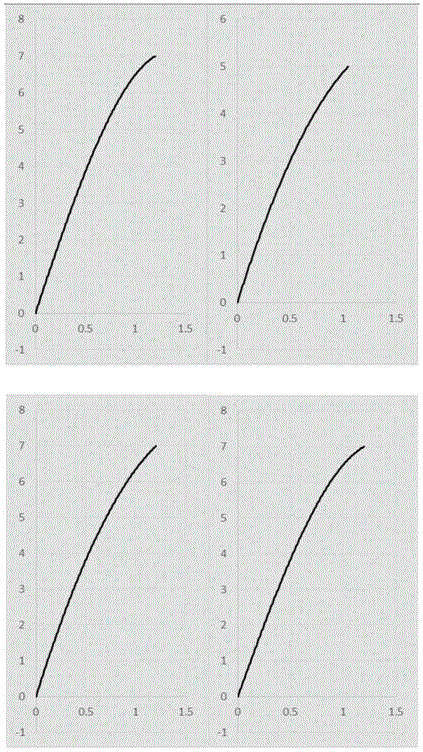
:目前多数车道线检测大多是采用基于激光雷达的检测算法和基于计算机视觉的图像检测算法两种。基于激光雷达的检测算法对激光雷达的设备以及对车道线的粉刷材料质量要求高。而基于计算机视觉的车道线检测方法前一种方法相比具有成本低廉而且不受道路的粉刷质量的影响的优点,因此具有更强的实用价值。前人的车道线检测算法大多基于传统的计算机视觉的方法,基本思路是在已有车道线的情况下,采用传统的卷积滤波的方法获取边缘图像,然后采用样条拟合和曲线匹配的方法来检测车道线。这类方法存在一些问题,比如实际应用时需要大量手动调参,鲁棒性较差等。近年来,深度学习领域在各领域得到了广泛的应用并实现了很好的效果,而基于生成对抗网络的无监督的图像生成技术也发展快速,利用图像生成方法生成增强后的感知图像为车道线的检测提供了新的思路。技术实现要素:发明目的:本发明目的在于针对现有技术的不足,提供一种基于条件对抗深度网络的车道线动态检测方法和面向抛物线的车道线曲线建模方法,检测视频图像帧中的车道线并采用抛物线对车道线进行拟合,得到车道线的曲线方程,适用于对视频的图像帧中,车道线的检测和车道线曲线拟合。技术方案:本发明所述车道线动态检测和车道分界线的拟合方法,包括如下步骤:s1、提取道路航拍录像的视频帧,选取部分原始视频帧,并在原始视频帧上采用区别色彩人工描绘车道线后与原始视频帧共同作为生成对抗网络的训练集;s2、基于步骤s1中得到的图像集训练生成对抗网络的图对图翻译模型,获得模型的最优实验参数及生成器和判别器的训练参数;s3、将未标记车道线的视频帧作为测试集,用步骤s2中训练得到的图对图翻译模型检测测试集,输出车道线的检测结果;s4、根据像素点的颜色识别s3得到的不同车道线上点的坐标,采用最小二乘法拟合车道线曲线得到车道线的三次抛物线方程。本发明进一步优选地技术方案为,步骤s1的训练集的提取步骤为:s11、提取道路航拍录像的视频帧,选取部分视频帧作为训练集的输入图像;s12、人工描绘车道线,选取区别于视频中所含其他特殊颜色为车道颜色,作为基于条件对抗网络的图像转换算法得到具有车道线的输出图像。作为优选地,步骤s2具体包括如下步骤:s21、设置学习率以及损失函数权重;s22、学习输入图像,更新判别器,判别器可以对生成的图像和原始的未标记车道线的图像分类,该判别器被训练成尽可能地检测发生器的“假”,首先从样本集中随机采样,然后用样本所含信息更新判别器的参数;s23、学习输入图像,更新生成器g,生成模型采用生成对抗网络,学习从随机噪声向量z到输出图像y的映射,g:z→y,随机噪声相当于低维的数据,经过生成器g的映射变为一张生成的图像;相反,条件生成对抗网络学习从观察图像x和随机噪声矢量z到y,g:{x,z}→y的映射;训练生成器g以产生不能通过对侧训练的判别器d与“真实”图像区分的输出,首先从样本集中随机采样,然后用样本所含信息更新生成器参数,生成输出图像,即标记车道线的图像;s24、梯度下降1次更新判别器中参数,继续生成输出图像;s25、梯度下降1次更新生成器中参数,继续对生成的图像和真实的图像分类;s26、重复步骤s23、s24,直到基于条件对抗的深度网络收敛,此时判别器的输出接近1/2,判别网络无法分辨生成的图像和原始的未标记车道线的图像;s27、用训练完的基于条件对抗的深度网络实现测试集图像的车道线检测,生成输出图像。优选地,生成网络采用条件生成对抗网络作为训练框架,u-net作为生成器的网络结构,加入l1损失参数,网络输入包含观察图像x和随机噪声z;条件生成对抗网络的目标函数表示为:lcgan(g,d)=ex,y[logd(x,y)]+ex,z[log(1-d(x,g(x,z))];其中g的目标是最小化目标函数,d的目标是最大化目标函数;目标函数为min-max博弈,优化后的公式为:l1重建损失函数的公式如下;ll1(g)=ex,y,z[||y-g(x,z)||1];最终生成网络的目标函数为:优选地,生成对抗网络训练框架中的生成器网络和判别器网络的网络基本单元是卷积神经网络卷积单元;其中生成器中间层基本单元采用卷积-批正则化-线性整流函数结构,瓶颈层采用u-net架构,即通过在编码层与解码层间添加短路连接,将编码层的特征层直接传递到对应尺度的解码层;判别器中间层的基本单元采用卷积-批正则化-线性整流函数结构。优选地,判别器网络采用利用马尔科夫性的判别器,判别器的输出为k×l的概率网络,表示图像局部像素为真实样本分布的概率,k、l表示将图像划分成k×l个分块,马尔科夫判别器将图像看作一个马尔科夫随机场,像素之间相互独立,每个分块是一个纹理或者风格的集合,马尔科夫损失可以看作是分块的纹理或者是风格损失,公式如下:其中n是一个批次的样本数,k、l为判别器的网络输出高度和宽度,i、k、l表示第i样本的k行l列的判别器输出值,范围在[0,1]。优选地,每次迭代在d下降一个梯度然后g下降下一个梯度间交替。优选地,基于条件对抗的深度网络的训练过程中算法优化器采用adam优化器。优选地,步骤s3具体包括如下步骤:s31、识别图片里全部人工描绘车道线所采用的区别色彩,并记录其在图片中的位置,即像素点的坐标,对于距离很小的两点,合并两点取坐标均值作为合并后点的坐标;s32、设定一个阈值,根据点之间横向距离与阈值的大小比较判断哪个点属于哪条车道线,提取出每条车道线所含点的坐标;s33、对每条车道线上的点采用最小二乘法拟合,得到各车道线的抛物线方程。有益效果:本发明提出了一种基于条件对抗深度网络的车道线动态检测方法和面向抛物线的车道线曲线建模方法,该方法从道路航拍视频的图像帧中进行车道线检测,对车道线进行标记,并拟合出车道线的三次抛物线方程。该方法包含提取航拍道路视频帧,训练生成对抗网络,车道线检测和车道线方程拟合三个部分。首先提取图像帧中并手动对车道线用特殊色进行标记;接着训练基于条件对抗的深度网络,并检测测试集中的车道线;最后提取车道线上特殊色像素点坐标并用最小二乘法拟合,获得车道线的三次抛物线方程。将此方法应用于航拍道路视频中的车道线检测和拟合,验证本发明的检测性能。本发明的方法对不同位置的车道线均获得较高的准确率,得到了较好的检测效果。附图说明图1为本发明的车道线动态检测和车道分界线的拟合流程图;图2为本发明中步骤s2的网络训练算法流程图;图3为实施例中检测实验时视频帧中航拍道路图;图4为基于条件对抗的深度网络算法对图3道路航拍图像的检测结果图;图5为图3中各车道线拟合的曲线和方程结果。具体实施方式下面通过附图对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。实施例:一种车道线动态检测和车道分界线的拟合方法,适用于对视频的图像帧中车道线检测和车道线曲线拟合。如图1所示,具体流程为:s1、提取道路航拍录像的视频帧,选取部分视频帧,对这些视频帧用特殊颜色人工描绘车道线与原始视频帧共同作为生成对抗网络的训练集;s2、用步骤s1中得到的图像集训练基于生成对抗网络的图对图翻译模型,得到模型的最优实验参数及生成器和判别器的训练参数;s3、用步骤s2中训练得到的图对图翻译模型检测测试集,即未标记车道线的视频帧中的车道线,输出车道线的检测结果;s4、根据像素点的颜色识别s3得到不同车道线上点的坐标,采用最小二乘法拟合车道线曲线得到车道线的三次抛物线方程。所述步骤s1包括以下步骤:s11、提取道路航拍录像的视频帧,选取部分视频帧作为训练集的输入图像;s12、人工描绘车道线,选取区别于视频中所含其他特殊颜色作为车道颜色,如红色,作为基于条件对抗的深度网络得到的具有车道线的输出图像;如图2所示,所述步骤s2包括以下步骤:s21、设置学习率以及损失函数权重;s22、学习输入图像,更新判别器,判别器可以对生成的图像和真实的图像(原始的未标记车道线的图像)分类。该判别器被训练成尽可能地检测发生器的“假”。首先从样本集中随机采样,然后用样本所含信息更新判别器的参数;s23、学习输入图像,更新生成器g,生成对抗网络是生成模型,可以学习从随机噪声向量z到输出图像y的映射,g:z→y。随机噪声相当于低维的数据,经过生成器g的映射就变成了一张生成的图像。相反,条件生成对抗网络学习从观察图像x和随机噪声矢量z到y,g:{x,z}→y的映射。训练生成器g以产生不能通过对侧训练的判别器d与“真实”图像区分的输出。首先从样本集中随机采样,然后用样本所含信息更新生成器参数,生成输出图像(标记车道线的图像);s24、梯度下降1次更新判别器中参数,继续生成输出图像;s25、梯度下降1次更新生成器中参数,继续对生成的图像和真实的图像分类;s26、重复步骤s23、s24,直到基于条件对抗的深度网络收敛,此时判别器的输出接近1/2,判别网络无法分辨生成的图像和真实图像;s27、用训练完的基于条件对抗的深度网络实现测试集图像的车道线检测,生成输出图像。步骤s2中的基于的生成对抗深度网络的车道线检测模型所采用生成网络采用条件生成对抗网络作为训练框架,u-net作为生成器的网络结构,加入l1损失参数,网络输入包含观察图像x和随机噪声z。条件生成对抗网络的目标函数表示为:lcgan(g,d)=ex,y[logd(x,y)]+ex,z[log(1-d(x,g(x,z))]其中g的目标是最小化目标函数而d的目标是最大化目标函数。因此目标函数是一个min-max博弈,优化后的公式为:以往的研究发现将生成对抗网络的目标与更传统的损失混合是有益的,例如l2距离度量方法。l2距离倾向于学习到多模态分布空间中的平均值,而l1距离倾向于学习到多模态分布空间中的中值,并且对网络的权值参数具有稀疏作用,因此l1生成的图像要比l2清晰。l1重建损失函数的公式如下;ll1(g)=ex,yz[||y-g(x,z)||1]最终生成网络的目标函数为:基于条件对抗深度网络的车道线动态检测方法的生成对抗网络训练框架中的生成器网络和判别器网络的网络基本单元是卷积神经网络卷积单元。其中生成器中间层基本单元采用卷积-批正则化-线性整流函数结构,瓶颈层采用u-net架构,即通过在编码层与解码层间添加短路连接,将编码层的特征层直接传递到对应尺度的解码层。判别器中间层的基本单元也采用卷积-批正则化-线性整流函数结构。基于条件对抗深度网络的车道线动态检测方法的判别器网络采用利用马尔科夫性的判别器。马尔科夫判别器的输出为k×l的概率网络,表示图像局部像素为真实样本分布的概率,k、l表示将图像划分成k×l个分块。马尔科夫判别器将图像看作一个马尔科夫随机场,像素之间相互独立。每个分块是一个纹理或者风格的集合。因此马尔科夫损失可以看作是分块的纹理或者是风格损失,公式如下:其中n是一个批次的样本数,k、l为判别器的网络输出高度和宽度,i、k、l表示第i样本的k行l列的判别器输出值,范围在[0,1]。基于条件对抗深度网络的车道线动态检测方法,为了优化生成对抗网络网络,遵循生成对抗网络的标准方法,每次迭代在d下降一个梯度然后g下降下一个梯度间交替。基于条件对抗深度网络的车道线动态检测方法,深度网络的训练过程中算法优化器采用计算高效并且适用于非稳态目标的adam优化器。步骤s3所包含的面向抛物线的车道线建模方法,包括以下步骤:s31、假设车道线为红色,识别图片里全部红色的像素,记录其在图片中的位置,即像素点的坐标,对于距离很小的两点,比如距离为一条线宽度的点,合并两点取坐标均值作为合并后点的坐标;s32、设定一个阈值,根据点之间横向距离与阈值的大小比较判断哪个点属于哪条车道线,提取出每条车道线所含点的坐标;s33、对每条车道线上的点采用最小二乘法拟合,得到各车道线的抛物线方程。最小二乘法的原理为,对于给定的数据点,使数据点的各纵坐标与所求的近似曲线上对应点的纵坐标的偏差最小。最小二乘法的原理为,对于给定的数据点,使数据点的各纵坐标与所求的近似曲线上对应点的纵坐标的偏差最小。具体来说,最小二乘法的推导过程如下:给定数据点pi(xi,yi),其中i=1,2,…,n。求近似曲线y=φ(x),使近似qu曲线与y=f(x)的偏差最小。设拟合多项式为:y=a0+a1x+…+akxk各点到拟合曲线的距离之和,即偏差平方的和如下:为了求得符合条件的a值,对等式右边求ai的偏导数,因而得到了:……将等式左边进行化简,得到下面的等式:……把这些等式表示成矩阵的形式,就可以得到下面的矩阵:将这个范德蒙得矩阵化简,得到:也就是说x·a=y,那么a=(x·x)-1·x·y,便得到了系数矩阵a,同时也得到了拟合曲线。下面对本发明的方法进行检测实验及分析。本发明的检测实验采用基于64位的win10操作系统,cpu的主频为3.4ghz,内存为8gb,仿真实验的平台是python(2.7版本)和tensorflow库(2.4.13版本)以及matlab(2014b版本)。本发明的道路航拍视频采用南宁北湖立交视频,北湖立交是南宁市交通要道,车流量很大,因此采用其监控视频进行船舶检测具有一定的实际意义。我们将采集的道路航拍视频典型场景如图3所示。对场景采用基于条件对抗的深度网络进行车道线检测。每个场景的视频帧速率是23帧每秒,每帧的分辨率为512×512,共有210帧图片用于评价基于条件对抗深度网络算法在航拍图像车道线检测和车道线的曲线拟合的效果。实验参数设置如下:批处理大小为50,数据集轮询次数为200。图像预处理采用框架内置的调整大小函数,将原始数据集的图像先缩小,再剪裁到256×256,同时像素值也从[0,255]正则化到[-1,1]之间,并通过随机翻转照片实现数据增益。生成器和判别器训练时采用加动量的adam优化器,学习率为0.0002,动量值为0.5,生成器损失函数中l1的权重系数λ为100。基于条件对抗的深度网络采用tensorflow框架实现。检测效果如下所述:图4为基于条件对抗的深度网络算法对图3所示道路航拍图像的检测结果。如图4所示,本发明所采用基于条件对抗的深度网络算法几乎能检测取像范围到该帧所有的车道线。本发明方法的车道线检测方法的采用若干图像与图像之间的差异指标进行评估。采用的衡量指标包括均方差(meansquarederror,简称mse),峰值信噪比peaksignaltonoiseratio,简称psnr)和结构相似性指标(structuralsimilarity,简称ssim),三者计算公式分别如下:mse(x,y)=||x-y||2是图像像素强度最大值的平方。ssim(x,y)=l(x,y)·c(x,y)·s(x,y)式中,是图像像素强度最大值的平方。ssim(x,y)=l(x,y)·c(x,y)·s(x,y)式中,l(x,y),c(x,y)和s(x,y)代表亮度,对比度和结构三方面度量的相似性,而μx和μy代表图像x和y的均值,σx和σy代表图像x和y的方差,σxy代表图像x和y的协方差。将训练模型对210份样本的测试集进行测试得到表1:表1车道检测评价指标msepsnrssim68.7634.890.97mse、psnr是主要衡量像素之间的误差的指标,ssim是衡量感知误差的指标。mse的值越小越好,psnr和ssim的值越大越好。psnr大于30,说明生成图像的绝对误差比较小,ssim接近最大值1.0,表明生成图像在局部纹理的构建非常接近真实图像。综合来看,基于pix2pix的车道线检测技术是有效的。本发明方法的车道线曲线拟合方法用r2进行评估。r2的计算方式如下:将训练模型对210份样本的测试集进行测试得到表2:表2车道线拟合度评价车道线r210.8920.7130.7440.92r2越大,拟合效果越好。从表2可知,两边的车道线,即车道线1、4的拟合度要好于中间的,这是因为中间的车道分界线是虚线,有较多缺失点。采用最小二乘法拟合的三次抛物线,在4条车道线的拟合上均取得了较好的检测效果。如上所述,尽管参照特定的优选实施例已经表示和表述了本发明,但其不得解释为对本发明自身的限制。在不脱离所附权利要求定义的本发明的精神和范围前提下,可对其在形式上和细节上作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1