重复数据删除系统中基于强化学习的指纹索引预取方法与流程
本发明属于计算机存储技术领域,涉及一种基于强化学习的指纹索引预取方法。当今信息世界的数据量呈爆炸式增长,有效地分析和管理这些数据成为当前大数据时期海量存储系统技术领域所关心的重点内容。特别是,数据中心作为大数据存储和大数据分析的基础支撑,通过虚拟化技术为各种应用提供高效可靠的存储和计算服务。本发明所提出的方法将针对提高数据资源的高效存储。
背景技术:
重复数据删除技术作为一种新型的数据缩减技术,通过在数据流中发现和去除重复的内容来提高数据的存储能力以及传输效率,这也称为数据去重或数据重删技术。一般的处理过程是:首先将数据文件分割成一组数据块,为每个数据块计算指纹,然后进行指纹索引的查找,匹配则表示该数据块为重复数据块,仅存储数据块索引号,否则则表示该数据块是一个新的唯一块,对数据块进行存储并创建相关元信息。
对于数据量非常大的重删系统而言,数据块的指纹索引是重复数据检测的关键数据结构。早期的重删系统将所有数据块指纹索引全部存储在内存中,便于快速完全的识别重复数据。但随着数据量的爆炸式增长,数据块指纹的数量会变得非常庞大,而指纹索引的大小也急剧增加,难以在内存中全部存放,导致需要频繁的访问低速率的磁盘来查询指纹索引。例如,假设使用平均大小为8kb的数据块和sha-1安全加密哈希算法,那么100tb的数据量将产生250gb的数据块指纹,这么庞大的指纹量在内存无法完全存储。由于随机访问磁盘的速率远低于内存访问速率,导致指纹索引的查找非常缓慢,频繁的访问磁盘上的指纹索引会使系统吞吐量相当低,大大降低了系统的吞吐量,从而形成了磁盘访问的性能瓶颈。因此,这成为大规模数据重删系统中迫切需要解决的难题。
为了解决该性能瓶颈,已有的研究已经提出了多种解决方法,主要基于局部性和基于相似性。这些方法主要通过将一些强烈相关联的小文件进行合并,将大文件进行分割,以挖掘更多的相似性,同时利用数据流的局部性对相似检测进行补充,解决相似性未检测出的数据块,利用两种策略的合理结合来提高性能。从指纹索引预取上看,很大程度上依赖于局部性,可以利用存储流数据局部性或者备份流局部性进行优化。因此,重删系统的指纹索引组织方法是提高重删系统性能和重删率的关键。
为此,本发明针对重复数据检测中指纹索引访问的磁盘瓶颈和数据恢复中数据碎片化等关键问题,提出新型的自适应方法,并改进数据缓存机制,提高数据存储效率和恢复性能,为增强数据中心数据存储的服务质量提供技术保障。
技术实现要素:
本发明的目的是解决现有技术存在的指纹索引组织管理缺少适应性的问题,提出一种重复数据删除系统中基于强化学习的指纹索引预取方法。本发明利用强化学习和局部性结合互补的方法,通过反馈激励,增强指纹与预取单元之间的关联性,动态调整缓存预取来提高重删系统的性能。基于强化学习的指纹索引预取方法具有更好的重删率和低内存占用,且能适用于不同的数据流,同时指纹索引也能适应系统,更具有灵活性。
本发明的技术方案
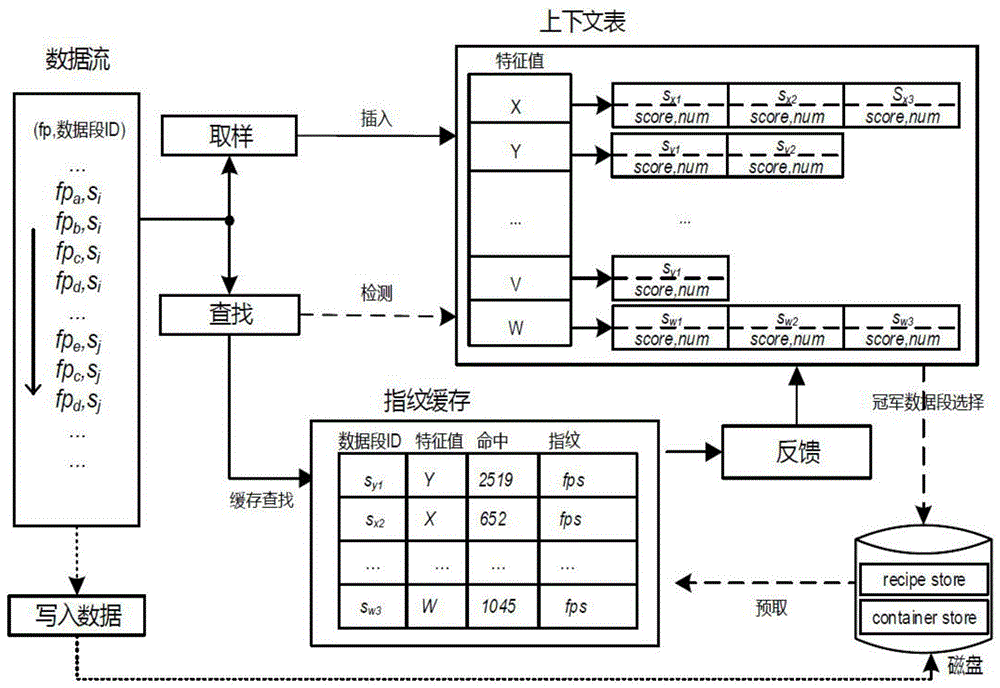
一种重复数据删除系统中基于强化学习的指纹索引预取方法。如图1,该方法具体包含以下的主要内容:
第1、依据数据流的字节内容,将输入的数据流划分成各个可变长的数据段
通过可变长度分块方法将数据流划分可变长的数据段。为了确定数据段的边界,基于内容的分割方法利用滑动窗口分析数据流。滑动窗口中数据的指纹仅依赖于其内容和设定的哈希函数,相同的数据块的边界能够不同的位置重新捕获,确保再次检测出重复数据。这通常选用rabin指纹算法计算窗口内数据的指纹,这是由于该方法计算效率远高于用于生成块指纹的安全一致哈希算法。
第2、通过随机采样的方法,提取数据段的特征指纹
假设每个数据段选择m个特征,通过比较规则选择m个最小的指纹作为特征,每个特征利用哈希函数关联到上下文表中的一项;采样的特征越多,选择的冠军就会越多,同时最后能识别的重复数据块也越多。由于数据量庞大而内存空间受限,不能将所有的指纹索引都存放在内存,所以本方法选择采样的方式,只存储一部分的指纹索引代替完全索引,从而降低内存的占用开销。
通过采样的方式从数据段选取部分合适的指纹作为特征。为了计算数据段之间的相似性,稀疏索引方法通过一定的比例从每个数据段采样小部分特征存到索引结构。这里对指纹流随机取样,根据数据块的内容产生指纹,进而随机哈希挑选作为特征指纹代表一段数据流。这样,每段数据流采样少量的特征指纹,使得内存开销更少。假设每个数据段选择特定的m个特征。一种简单的方式就是通过特定的比较规则选择m个最小的指纹作为特征,每个特征关联到上下文表中的一项。采样的特征越多,选择的候选比较数据段(称为冠军)就会越多,同时最后能识别的重复数据块也越多。
第3、制定选择策略,选出特定数据段作为冠军
基于强化学习的方法其主要挑战是如何从k个数据段中选择一个合适的冠军数据段。每个数据段都记录了一个分数用于反映过去重删的有效性;然而,这仍然会有一个分数为0的数据段,特别是最新的一个数据段,直到它被选择分数才会更改。由于加载数据段开销较大,故没有必要对k个数据段都进行重删,并且因为局部性这些数据段可能会非常相似,因此加载数据段的全部指纹没有意义,反而会降低缓存利用率。
根据数据流的不同特性,本方法可结合三种选择策略实现数据段的优化选择:最近策略,随机策略,ε-贪婪策略。最近策略每次选取当前最新的数据段,这种适合于时序性很好的数据流备份。随机策略,从k个有用的候选集中以相同概率随机选择一个。但这两种策略在过去的试验中都没有记录学习知识,只是简单的根据现有知识进行选择,缺乏对已有知识的认识和利用。贪婪策略,该方法是随机策略的一种改进。基于一个概率对利用和探索进行折中:每次试验,以1-ε概率进行利用,选择当前平均奖励最高的数据段,即利用过去已知,得分最高的通常是在过去试验中命中率最高的,那么对于接下来的数据流,极大概率上也会有很好的重删率;以ε的概率进行探索,即以均匀概率随机选择其中一个数据段,探索未知的可能存在的效果较好的数据段。因此,通过选择一个已知最好的数据段和探索一个未知的但未来可能获得更好奖励的数据段,在实施过程中找到两者之间平衡关系,从而不断扩展发现重复数据的能力。
第4、根据命中情况给数据段反馈奖励值
当冠军数据段选择后,其后的数据段被预取,然后与即将重删的数据段进行指纹查找比较。其中一个查找命中意味着一个重复数据块被识别。在冠军数据段被移出缓存之前,累积该数据段的查询命中,当数据段被移除时将积分反馈更新给上下文表,并更新数据段相应的分数。
假设一个数据段s被选为冠军后,在n次反馈中的命中结果分别为r1,r2,…,rn,并设qn(s)是n次反馈的最终结果;那么,该反馈值作为数据段被命中的情况。一个直观的方法是以平均反馈来计算qn(s),即
这样存在一个如何高效计算该反馈值的问题,内存和计算开销会随时间一直增长没有限制。因此,进行如下优化:
其中,初始化q0(s)为0。
这种计算方法只需要计算qn-1(s)和n的内存开销以及rn的计算开销。该过程是无监督的。在训练过程仅依赖于反馈要么加强要么减弱一次未来数据段关联。加高的反馈将会增强数据段成为冠军的概率;反之,则降低数据段成为冠军的概率。反馈以懒惰的方式上处理,需要一个时间界限;相反,基于当前知识的冠军选择决策是实时。
第5、更新上下文表
上下文表保存所有特征和对应的数据段。当一个数据段的特征选定后,如果该特征不在上下文表中,则将该特征与其关联的数据段作为新的一项插入上下文表,否则,数据段信息添加到对应的特征项中。在上下文表中的每一项,同一个特征最多对应k个数据段存储在一个队列中,当队列满了,一个新的数据段总是插入队尾,旧的数据段会从队列移除。
根据数据源的特点采取合适的替换策略可以对重删性能的提高有很大帮助。本方法考虑两种替换策略:先进先出策略和最小值策略。先进先出策略是从队列头部移除最高分以外的数据段。最小值策略是指移除最低分的数据段,如果存在多个最低分的数据段则再根据先进先出策略进行替换。
本发明的优点和有益效果:
1)通过引入基于强化学习的指纹索引预取方法,使得重删系统性能在重删率和内存占用有了一定的提高,提高了系统的吞吐量;2)本发明有效的解决了磁盘指纹索引问题;3)本发明挖掘了指纹序列与数据流上下文关系,更能适应系统的变化,具有对存储数据流的自适应适性。
附图说明
图1为基于强化学习方法的基本框架。
图2为重复数据删除算法的实施流程。
图3为在不同大小的数据段和不同的采样率下,分别针对(a)kernel、(b)vmdk、(c)fslhomes和(d)macos工作负载下评价系统的重删率。
图4在ε-贪婪策略下设定的ε参数下,针对两种工作负载(a)kernel和(b)user014数据流分别测量数据重删率。
图5为采用最小值和先进先出替换策略,分别针对(a)fslhomes、(b)kernel、(c)macos和(d)vmdk工作负载下测量重删率。
具体实施方式
下面结合附图2的处理流程,对本发明进一步描述本发明的具体实施方式。
重复数据删除的基本流程如图2所示。首先,将存储系统输入的数据流分成若干个相对较小的数据块序列,用哈希安全加密方法(md5或sha-1)计算每个数据块的哈希值,该哈希值是用于进行数据块识别的指纹,有相同指纹的数据块被认为是重复的。指纹索引用于映射已存储的数据块的指纹到它的物理地址。针对每一个数据块都利用指纹进行比较,如果指纹与索引中的指纹相同则说明该数据块是重复的,不需要存储,反之,数据块唯一,写到一个固定大小的容器中,容器是用于存储数据块的存储单元。数据流的指纹序列需要保存用于数据恢复。
为了说明本发明的有效性,使用四种不同数据集进行性能评估,代表了不同工作负载。其中kernel和vmdk是真实数据集,而fslhomes和macos表征的是日志数据集。文件平均分成若干个4kb大小的数据块,在存储阶段,新的数据块被存储到固定大小为4m的容器中。具体说明如下:
a)数据集kernel包含了linux-2.3.0到linux-2.5.75的155个kernel源代码版本,代表数据备份中的源代码负载,该数据集大多数都是小文件,并且具有很高的重复率。
b)数据集vmdk是包含110个不同操作系统的不同版本的虚拟机镜像,由于各个版本之间缺少数据冗余,所以该数据集代表重复数据较少的负载。
c)数据集fslhomes是纽约州立大学石溪分校文件系统和存储实验室(fsl)采集的日志数据集。使用2011年9月16号到30号14天9个用户的数据日志。由于每个用户的备份数据认为是一个数据流,所以这里每天的数据对应多数据流负载。
d)数据集macos也是纽约州立大学石溪分校学术计算机实验室mac服务器的数据日志。由于数据量过于庞大,这里仅选取了18天的数据集日志。
步骤01获取特征值与数据段的关联关系
首先将数据文件分割成一组数据块,数据块序列的数据流通过基于内容的分割方法分成多个数据段,对每一个即将重删的数据段st,通过采样方法获取特征f,st与f之间有一个对应的关联关系即:f→st。并将两者及其关系存放在键值索引结构中。每个特征f在上下文表中最多对应k个数据段,也就是最多有k个数据段共享该特征f。
如图3,在不同的数据集下,设定不同数据段长度下,使用不同采样率获得特征值得到的重删率不同。其中1024、2048、4096分别是数据块个数,而平均数据块的大小是4kb,分别测量了4mb、8mb、16mb大小的数据段下采样1个,2个,4个,8个特征的情况。从图中可以看出,在相同数据段大小情况下,采样特征越多,重删效果越好;在采样特征数一样时,数据段越小,重删率越高,实际上也说明了采样特征数决定了重删的效果。因为这里数据块的查重检测,主要依赖于采样的特征值进行预取数据段,从而达到很好的近似去重的效果。
步骤02制定选择策略,选出特定数据段作为冠军
本方法的采用的是最近策略,随机策略及贪婪策略三种策略相结合的方法。根据一个给定的特征映射的所有候选者,首先用贪婪策略选择第一个数据段,倾向于以1-ε概率选择最高分的数据段或ε概率随机选择一个数据段;再以最近策略选择一个与已选择的数据段。在选择过程中,冠军之间具有尽可能少的共同特征。这使得选取的冠军数据段之间得到互补,又避免了通过指纹特征选取的数据段过于相似而失去查重效果。
以kernel(图4-a)和fslhomes中用户user014(图4-b)连续半个月的数据为测试数据集,选择ε分别为0.1、0.3、0.5、0.7、0.9,以平均重删率为标准。从图4可以看出,随着ε的增加,重删率是降低的,而ε=0.1表示以0.1的概率随机选择一个数据段,以0.9的概率选择得分最高的数据段。说明选择得分最高的数据段得到的效果更好。
步骤03根据命中情况给数据段反馈奖励值
利用步骤02中选定的冠军数据段事先预取其后固定长度的数据段到缓存,以便使后续需要重删的数据段可直接在缓存中被找到,提高缓存的命中率,并且减少磁盘指纹索引访问。其中缓存利用lru策略进行替换。
预取冠军数据段及其之后的数据段,与即将重删的数据段进行指纹查找比较。一个查找命中意味着一个重复数据块被识别,在冠军数据段被移出缓存之前,累积该数据段的查询命中,当数据段被移除时将积分反馈更新给上下文表。图4显示的结果验证了分数的有效性,即反馈奖励值的作用。
步骤04更新上下文表
上下文表是一个键值索引结构:键表示指纹特征,值表示指纹特征对应的k个数据段。每个数据段的属性包括分数和允许预取的数据段个数,利用队列实现,其中分数有助于冠军数据段的选择,也是反馈的依据。如图5所示,其中元数据存储(recipestore)用于存储备份流的指纹序列便于数据恢复使用,数据块存储(containerstore)存放所有的数据块。
在上下文表中的每一项,同一个特征最多对应k个数据段存储在一个上下文队列中,当上下文表队列满时,一个新的数据段总是插入队尾,根据先进先出替换策略或最小值替换策略将旧的数据段从队列移除。例如,特征x队列满时,若采用先进先出替换策略则删除sx1节点,将新的数据段插入sx3节点之后;若采用最小值替换策略则删除分值最小的节点,将新的数据段插入sx3节点之后。
如图5所示,在不同数据集下,同时设定ε=0.3,测量最小值替换策略和先进先出替换策略比较的实验结果。其中,在fslhomes(图5-a),macos(图5-c)和vmdk(图5-d)三个数据集都表明最小值替换策略的重删率更高,同时也说明了分数的有效性。而在kernel(图5-b)上相反,这是由于kernel数据集都是连续的备份版本,都是一些小文件,且具有非常强的时序性,所以使用先进先出策略效果更好。
针对不同的数据流特征,选择合适的替换策略更新上下文表,对重删性能的提高有很大的帮助,这也是所提出的强化学习方法的一个优势体现。
- 还没有人留言评论。精彩留言会获得点赞!