一种面向嵌入式移动设备的深度神经网络压缩方法与流程
本发明涉及一种压缩方法,尤其涉及一种面向嵌入式移动设备的深度神经网络压缩方法。
背景技术:
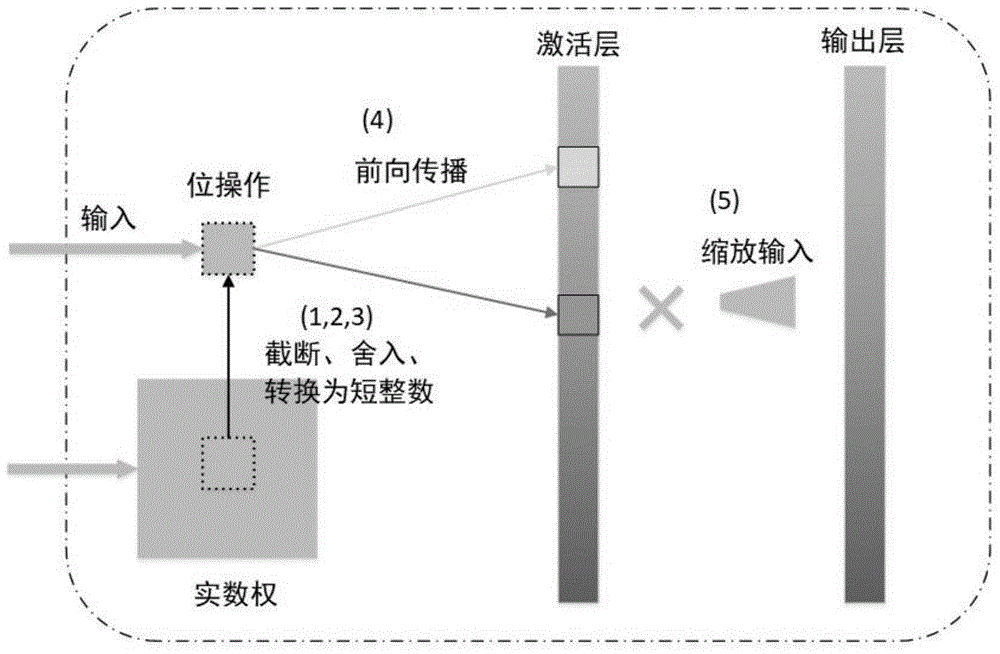
:深度神经网络在自然语言处理、计算机视觉和语音识别方面达到了工业级别的应用。但是深度神经网络高度参数化,通常需要数亿个参数才能获得最先进的结果,这导致计算和内存的浪费。例如,深度神经网络alexnet在imagenet挑战赛中显示了极高的效率,但是它的模型通常占用超过200mb的内存存储空间,并且对计算能力要求很高。深度网络模型压缩通常用于降低模型复杂性和资源需求,从而支持在本地移动设备上实现深度学习模型推理、降低任务响应时延和实现较少的隐私问题。然而基于深度学习的方法在训练和测试阶段都需要大量的乘法计算。同时,深度神经网络模型一般都包含海量的参数,存储这些参数会占用嵌入式设备的大部分存储和内存带宽。因此,需要一种压缩技术来在不损耗深度神经网络模型性能的前提下,对其进行加速和压缩。技术实现要素:为了解决上述技术所存在的不足之处,本发明提供了一种面向嵌入式移动设备的深度神经网络压缩方法。为了解决以上技术问题,本发明采用的技术方案是:一种面向嵌入式移动设备的深度神经网络压缩方法,包括以下步骤:ⅰ、权值截断;通过整流器构建一个神经网络,在神经网络中先随机生成模型的参数值,并且在[-1,1]区间内对实值权重w进行截断,对于神经网络中每一个权重值w,使w满足公式①:其中,clip()表示权重截断操作,保证w在[-1,1]区间内;if表示取值条件,otherwise表示[-1,1]区间之内的取值;ⅱ、权值舍入;将实值权重w四舍五入到以或为底的指数中;具体方法为:给定一个正实值权重w和一系列的指数表示其中和是关于近似w的前两个最接近的指数表示;基于阈值μ的四舍五入方法如公式②所示:并且,根据公式③获得w的概率分布;其中,φ(w)表示概率分布;ⅲ、保留存储指数权重的指数部分;将步骤ⅱ中得到指数转换为短整数,即保留指数权重的指数部分,并存储起来,其中每个短整数指示输入值需要进行的右移位操作;ⅳ、压缩模型的前向传播和后向传播;压缩模型在每次参数更新过程中的操作步骤:在进行深度神经网络的前向后向传播过程中,保留实值权重以在训练阶段累积随机梯度下降参数的更新,因为量化权重可能导致梯度消失问题,因此,仅在前向和后向传播期间量化权重操作,而在参数更新期间使用原来的实数权重;ⅴ、缩放输入信号;使用放大系数α来缩放每个批量标准化层的输出;ⅵ、哈夫曼编码压缩;使用哈夫曼编码来进行一步压缩由步骤ⅲ产生的短整数,即完成了对深度神经网络的压缩。进一步地,步骤ⅳ中量化权重的方法如公式④所示:其中,δw表示实值变量的更新累积,是示例(xi,yi)上的损失函数,其中wi-1和bi-1是量化的权重和偏差,表示变化率;σ表示求和;权重的最终离散化值wq通过公式⑤计算:wq=quantize(wr-ηδwr),公式⑤其中,wr是初始权重的浮点值,δwr是在训练阶段由公式⑤计算的累积梯度,η是学习率,quantize表示离散函数。进一步地,步骤ⅱ中四舍五入方法包括如公式⑥所示的确定性四舍五入和如公式⑦所示的随机性四舍五入;随机性四舍五入是通过平均隐藏层的所有权重之间的离散化来补偿信息损失的合理替代方案,即所有实值权重随机舍入到指数上限或下限指数的概率;其中,withprobabilityφ(w)表示w四舍五入结果的概率值;round表示四舍五入操作。进一步地,右移位操作如公式⑧所示:y=sign(w)(|w|>>x)+b,公式⑧其中sign表示取符号操作,>>表示右移操作,sign(w)(|w|>>x)+b表示对原运算y=wx+b的右移近似计算;将原运算右移,可消除大部分的乘法,提升模型运行效率。近年来神经网络的初始化大多采用“axvier”方法,该方法解决了非常深模型难以收敛的问题。然而,这种方法在某些量化网络中并不适用。例如,binaryconnect在minst上使用纯高斯分布初始化网络时,获得1.19%的验证错误率,但在“axvier”初始化情况下,性能下降到1.7%。在本发明中,使用整流器而不是sigmod式的激活单元来构建网络。因此,本发明使用稳健的方法初始化神经网络,该方法理论上relu激活考虑在内。更详细的网络初始化对minst数据集的影响如表1所示。表1不同初始化策略对minst数据集的影响initializerbs-netbinaryconnectplainnetworksuniform1.26%1.19%1.72%henormal1.11%1.70%1.23%本发明以指数去逼近深度神经网络中的权值,并使用短整数将指数的幂使用短整型存储起来,可以减少3倍的参数存储空间;使用哈夫曼编码来进一步压缩模型参数,最终可以达到10-13倍的模型压缩率;使用位运算中的右移操作消除了大部分的乘法,提升模型运行效率。附图说明图1为本发明的原理流程图。图2为考虑权重的截断、舍入和保留指数部分的实例图。图3为α为500时缩放批量标准化层输出的前后变化示意图。图4为不同数据集上的权重分布图。图5为在mnist数据集上训练不同方法的曲线变化图。图6为跨mnist和cifar10数据集的不同位宽下的测试错误率对比图。具体实施方式下面结合附图和具体实施方式对本发明作进一步详细的说明。图1所示的一种面向嵌入式移动设备的深度神经网络压缩方法,包括以下步骤:ⅰ、权值截断;通过整流器构建一个神经网络,在神经网络中先随机生成模型的参数值,并且在[-1,1]区间内对实值权重w进行截断,对于神经网络中每一个权重值w,使w满足公式①:其中,clip()表示权重截断操作,保证w在[-1,1]区间内;if表示取值条件,otherwise表示[-1,1]区间之内的取值。在实际模型运行过程中如果权值绝对值不大于1,只需要考虑神经网络中正确的位偏移量,极大地简化了模型的运算过程。因此,整数权的负号表示对输入特征x的位不操作,而不是位移动的方向。在小范围内缩减学习权重主要有两个原因。首先,它保证了在深度网络中,量化的权值近似于具有容差卷积的结果。例如,给定一个学习实值权值w和一个输入值x,令x=8,如果w=0.45,我们提出的网络和普通网络的计算结果分别为4和3.6,其中偏差由|wx-sign(w)x>>|=0.4计算得出。但是,如果w=2.7,误差将增加到5.6,这可能会降低网络的性能。另一方面,如果权值绝对值不大于1,我们只需要考虑bq-net中正确的位偏移量,这大大简化了本发明方法。因此,整数权的负号表示对输入特征x的位不操作,而不是位移动的方向。ⅱ、权值舍入;将实值权重w四舍五入到以或为底的指数中;具体方法为:给定一个正实值权重w和一系列的指数表示其中和是关于近似w的前两个最接近的指数表示;基于阈值μ的四舍五入方法如公式②所示:并且,根据公式③获得w的概率分布;其中,φ(w)表示概率分布;考虑到负实值权重的情况,它也可以以类似的方式将实数值转换为以为底的指数。四舍五入方法包括如公式⑥所示的确定性四舍五入和如公式⑦所示的随机性四舍五入;随机性四舍五入是通过平均隐藏层的所有权重之间的离散化来补偿信息损失的合理替代方案,即所有实值权重随机舍入到指数上限或下限指数的概率;其中,withprobabilityφ(w)表示w四舍五入结果的概率值;round表示四舍五入操作。ⅲ、保留存储指数权重的指数部分;将步骤ⅱ中得到指数转换为短整数,即保留指数权重的指数部分,并存储起来,其中每个短整数指示输入值需要进行的右移位操作;如图2所示。右移位操作如公式⑧所示:y=sign(w)(|w|>>x)+b,公式⑧其中sign表示取符号操作,>>表示右移操作,sign(w)(|w|>>x)+b表示对原运算y=wx+b的右移近似计算;将原运算右移,可消除大部分的乘法,提升模型运行效率。ⅳ、压缩模型的前向传播和后向传播;压缩模型在每次参数更新过程中的操作步骤:在进行深度神经网络的前向后向传播过程中,保留实值权重以在训练阶段累积随机梯度下降参数的更新,因为量化权重可能导致梯度消失问题,因此,仅在前向和后向传播期间量化权重操作,而在参数更新期间使用原来的实数权重;在参数更新期间保持完全精确的权重是sgd(随机梯度下降)工作良好所必需的。由于通过梯度下降获得这些参数变化是微小的,即,sgd在极限改变方向上执行大的数字,这最大程度地改善了训练目标(加上噪声)。以binaryconnect和dropoutconnect方法为例,它们都在训练网络时传播期间涉及学习参数的噪声,其中dropoutconnect方法是高斯噪声,binaryconnect的噪声来自二进制采样。但是,两者提到的网络不同,本发明是一个指数舍入过程,它是一个弱得多的噪声,因此量化权重可以在内部相位和测试参考中得到充分利用。简而言之,在测试时间推断中使用的最终量化权重由sgd更新确定,该更新累积在实值变量中。量化权重的方法如公式④所示:其中,δw表示实值变量的更新累积,是示例(xi,yi)上的损失函数,其中wi-1和bi-1是量化的权重和偏差,表示变化率;σ表示求和;权重的最终离散化值wq通过公式⑤计算:wq=quantize(wr-ηδwr),公式⑤其中,wr是初始权重的浮点值,δwr是在训练阶段由公式⑤计算的累积梯度,η是学习率,quantize表示离散函数。因此,bq-net在训练时和测试推断时在前向传播期间将实值权重量化为整数。然而,sgd更新由实值变量累加,并且量化权重仅在其梯度下降足够大时更新。ⅴ、缩放输入信号;使用放大系数α来缩放每个批量标准化层的输出,结果如图3所示。对于深度网络,如果在训练期间仅输入层和输出层白化,则隐藏层逐渐偏离零均值,单位方差和不相关条件,这称为内部协变量转移。批量标准化的目的是适当地解决这个问题。然而,由于本方法使用位操作而不是多次执行卷积操作,因此需要保证每个卷积层的大多数输入特征值远大于1。例如,如果偏移量b设置为1并且所有权重w的值都是不大于1或小于-1,由位操作计算的卷积运算的结果总是等于1,这对卷积神经网络没有任何意义。为了解决这个痛点,我们使用放大系数α来缩放每个bn(批量标准化)层的输出,这使得99%的数据的绝对值大于1。ⅵ、哈夫曼编码压缩;使用哈夫曼编码来进行一步压缩由步骤ⅲ产生的短整数,即完成了对深度神经网络的压缩。哈夫曼(huffma)编码是一种最佳预处理编码,通常用于无损数据压缩。哈夫曼编码使用可变长度代码表来编码源符号。该表是从每个源符号的估计出现频率导出的,主要原则是使用较低的位数来编码更频繁出现的数据。图4显示了所提出的bq-netonmnist,cifar-10和svhn数据集的量化权重的直方图。其中横坐标为权重(quantizedweight),纵坐标为百分率(percenttage)。量化权重的所有分布都是有偏差的,其中大多数量化权重保持在两侧,例如0和±1。实验表明,huffman编码可以压缩超过70%的量化神经网络模型的存储大小。本发明在完全连接的神经网络上进行了三个数据集的实验:mnist,cifar10和svhn。数据集具体设置如下:(1)minst数据集实验设置:mnist是手写数字的大型数据集,包含60,000个训练样例和10,000个测试示例。每个样本是2828灰度图像,写入0到9范围内的整数。在对mnist数据集的实验中,首先将所有训练集的数据和混洗训练集的最后10,000个样本用作防止过度拟合的验证集。使用的网络结构类似于二元连接。应用一个4层完全连接的神经网络,分别有784,1024,1024,1024个节点,批量大小设置为200。在最后输出层使用l2-svm,并将方铰链损耗作为成本函数。bq-net和没有正则化器的cnn网络的训练曲线如图5所示,其中,横坐标为迭代次数(epoch),纵坐标为错误率(validationerrorrate).并注意尝试在验证推理期间应用binaryconnect,训练曲线在图6中表示,其中横坐标为位宽(bitwidth),纵坐标为错误率(errorrate)。(2)cifar10数据集实验设置:cifar-10数据集由60,000个32×32rbg图像组成,具有50,000个训练样本和10,000个测试示例。使用全局对比度归一化以及zca白化技术来预处理数据而无需任何数据增强。选择l2-svm作为输出层的线性分类器。批处理大小设置为100。(3)svhn数据集实验设置:svhn是一个庞大的家庭数字数据集,其中包括超过600,000个训练图像和完整版本的约26,000个测试图像。但是,使用裁剪版本的svhn来评估本发明提出的方法。所有数字都已从原始图像裁剪,并调整为固定分辨率为32×32像素。与cifar-10的神经网络一样,在svhn数据集的模型中应用相同数量的卷积层和完全连接层,但每个隐藏层中的滤波器数量不同。批处理大小设置为50。实验证明本发明提出的压缩模型可以在模型压缩率大于10的条件下达到或者接近未压缩的深度学习算法性能,模型错误率结果如表2所示。模型压缩率结果如表3所示。本发明将模型大小减小到普通模型的近8%。表2压缩模型mnist,cifar-10,svhn数据集的一般性能(错误率)数据集普通深度模型二元连接模型本发明mnist1.23%1.31%1.11%cifar1010.64%9.55%9.31%svhn2.55%2.94%2.87%表3量化和哈夫曼编码的压缩细节datasetplainmodelquant.quant.+huff.compressratemnist38.3m10.1m2.7m7.05%cifar10122m37.5m11.5m9.43%svhn57.4m19.8m4.4m7.67%本发明与现有技术相比具有的优点为:a、以为底的指数去逼近深度神经网络中的权值,并使用短整数将指数的幂使用短整型存储起来,可以减少3倍的参数存储空间;b、在神经网络的正向反向传播过程中,通过y=sign(w)(|w|>>x)+b,近似计算y=wx+b,使用位运算中的右移操作消除了大部分的乘法,提升模型运行效率;c、在优点a的基础上,使用哈夫曼编码来进一步压缩模型参数,最终可以达到10-13倍的模型压缩率。上述实施方式并非是对本发明的限制,本发明也并不仅限于上述举例,本
技术领域:
的技术人员在本发明的技术方案范围内所做出的变化、改型、添加或替换,也均属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1