一种基于神经网络的PM2.5浓度值预测方法与流程
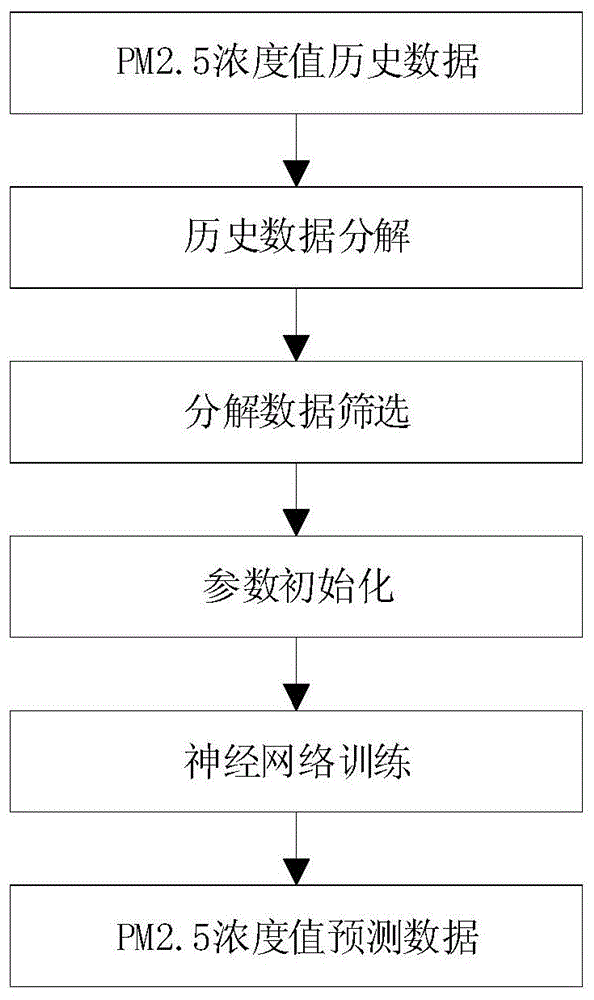
本发明涉及空气颗粒物pm2.5浓度值的预测技术领域,尤其涉及一种基于神经网络的pm2.5浓度值预测方法。
背景技术:
pm2.5微粒指环境空气中空气动力学当量直径小于等于2.5微米的微粒物质。pm2.5粒径小,面积大,活性强,容易附带有毒有害的物质,并且能够做到在空气中长时间漂浮、远距离输送,对大气环境和人体健康的影响很大。因此,对pm2.5浓度的监测和预测对于社会有着很大的意义。
为了解决上述问题,任才溶等人在论文《基于随机森林和气象参数的pm2.5浓度等级预测》中,通过选择k-means算法和随机森林方法进行pm2.5的浓度值预测。黄婕等人在论文《基于rnn-cnn集成深度学习模型的pm2.5小时浓度预测》中,将记忆能力较强的循环神经网络(rnn)和特征表达能力较强的卷积神经网络(cnn)作为基础,采取stacking集成策略对两者进行融合,提出了rnn-cnn集成深度学习预测模型。白盛楠等人在论文《基于lstm循环神经网络的pm2.5预测》中,搭建多变量的lstm循环神经网络pm2.5预测模型,实现pm2.5日值浓度的预测。李建更等人在论文《基于互补集合经验模态分解与支持向量回归的pm2.5质量浓度预测》中,建立了基于互补集合经验模态分解和支持向量回归的混合预测模型实现了pm2.5浓度值的预测。张静等人在论文《基于bp神经网络的沈阳城区pm2.5浓度预测中,使用bp神经网络对pm2.5质量浓度进行预测。陈菊芬等人在论文《基于多模态支持向量回归的pm2.5浓度预测》中,利用基于多模态支持向量回归(msvr)的混合预测模型,有效提高了pm2.5.浓度的预测精度。
经调研分析,目前pm2.5浓度值的预测均以各种神经网络为核心架构,对pm2.5等指标(如aqi,no2浓度,so2浓度,风力大小,湿度等)进行非线性回归分析,神经网络的类型包括bp神经网络、cnn、msvr、rnn、lstm等。但是,经文献调研发现,虽然采用的都是历史pm2.5浓度的数据作为模型预测的训练数据,但是在模型预测的时候,对pm2.5浓度数据的时序性并没有很好的体现,并且目前提出的神经网络模型,在模型训练时,由于不能很好的获得其相应时间段的数据特征,使得模型实现周期过长,导致训练效率低下。
技术实现要素:
为了克服已有pm2.5浓度值预测方式对pm2.5浓度历史数据的时序性体现缺失并且预测效率低下的不足,本发明在对pm2.5浓度值的历史数据进行模态分解之后,对其模态分解的数据进行主成分分析,提取出和预测pm2.5浓度值相关度较高的数据,结合有位置向量和注意力机制的变换器神经网络,提取各个时间点的数据特征,并在最后的预测结果上对其进行体现,从而达到具有较好的数据时序性体现并且在预测效率上具有较大提高的效果。
本发明解决其技术问题采用的技术方案是:
一种基于变换器神经网络的pm2.5浓度值预测方法,所述方法包括以下步骤:
步骤1、采集原始数据,以pm2.5历史浓度值为主体;
步骤2、采用模态分解方法对pm2.5的历史浓度值进行分解并且挑选其有效数据,其过程如下:
步骤2.1、将pm2.5的历史浓度值设定为时序信号a,并将a表示为{a}={a1,a2,…ai,…,an},其中,ai为第i个pm2.5的历史浓度值,i为整数且1≤i≤n,n为pm2.5历史浓度总个数;
步骤2.2、找到整段信号的所有局部极值点(最大值点和最小值点),并用bi对这些极值点进行标注,其中1<i<n,n为极值点的总个数;
步骤2.3、将所有的相邻的bi点用线段连接,并用ci标记这些线段的中点,ci中的i的取值范围为1<i<n-1,n为极值点的总个数;
步骤2.4、添加左边界中点c0和右边界的中点cn;
步骤2.5、用这些n+1个中点构造m个差值曲线l1,…,lm,并通过公式
步骤2.6、在a-l′重复上述2.2~2.5的步骤,直到|l′|≤ε,ε为可允许的最小误差,或者重复至初始设置的筛选次数k,从而得到第一个模式i1;
步骤2.7、对于a-i1的剩余值,重复上述2.2~2.6的步骤,得到i2,i3,…,ip直到最后一个残余量r,其中,1≤p≤n;
步骤2.8、在有限的整数区间[kmin,kmax]更改筛选次数k,kmin为k取值的最小值,kmax为k取值的最大值,重复上步骤2.2~2.7,计算a-r的方差σ2和a的标准差σ0,并绘制以σ/a0为纵坐标,以k的取值为纵坐标的关系图。
步骤2.9、在[kmin,kmax]上找到σ/a0最小的时候k对应的值k0,用k0代入步骤2.2~2.7,输出整个分解模式。
步骤2.8、对于已经得到的分解模式数据,对其进行主成分分析,根据需要提取出对pm2.5浓度值影响较大的几组分量数据;
步骤3、采用神经网络预测pm2.5的浓度值,过程如下:
步骤3.1、创建一个包含编码和解码两个模块的神经网络,该神经网络主要由位置信息计算层、注意力机制层、位置全连接前馈层组成;
步骤3.2、设定网络的输入和输出维度,并设定网络隐含层单元数m,该节点单元数m采用经验公式给出的估计值,如下式所述:
上式中,a为输入层神经元个数,b为输出层的神经元个数,c是取值范围为0~10之间的常数;
步骤3.3、定义位置信息计算层输出公式,偶数位置的输出pepos,2i和奇数位置的输出pepos,2i+1分别为:
其中,pos代表输入位置,i代表输入维度,dmodel为512,sin()为正弦函数,cos()为余弦函数;
步骤3.4、定义其注意力机制输出,由下式表示
attentionoutput=attention(q,k,v)
其中,上式中的q是查询向量,k是键向量,v是值向量,定义q在第i维度上面的值为qi,k在第i维度上面的值为ki,v在第i维度上面的值为vi,qi、ki、vi与输入值xi之间存在以下关系:
qi=xi*wiq
ki=xi*wik
vi=xi*wiv
上式中,wiq为xi在q层的权重,wik为xi在k层的权重,wiv为xi在v层的权重;
步骤3.5、全连接前馈层网络由一个relu激活函数和一个线性激活函数组成,定义位置全连接前馈层网络输出,若将注意力机制层输出表示为y1,则全连接前馈层网络ffn输出ffn(y)为:
ffn(y)=max(0,y1w1+b1)w2+b2
其中,y1∈r,w1为y1在relu层的权重,,w2为relu层的输出在线性函数层的权重,b1为relu层的偏置系数,b2为线性函数层的偏置系数;
步骤3.6、设定网络的期望最小误差值,最大迭代次数和学习率;
步骤3.7、将步骤2中分解后所得的数据输入到步骤3.1~3.6中所创建的神经网络中,训练神经网络;
步骤3.8、判断神经网络是否收敛,当误差小于设定的神经网络的最小误差的时候,神经网络达到收敛;
步骤3.9、将用于预测的pm2.5数据输入到已经训练完成的神经网络模型中,得到pm2.5浓度的最终预测值。
本发明的主要思路为首先对pm2.5的历史浓度值进行分解,之后筛选出对原始pm2.5数据有较大的影响的分解数据组,输入定义好的变换器神经网络中,进行模型的训练,等到模型误差小于期望误差,将用于预测的pm2.5历史数据输入网络,得到最终的预测值。
本发明的有益之处在于:本发明能有效地突出pm2.5历史浓度值的时序性,将pm2.5浓度值的在各个时间点的特征取出来,体现在最终的预测结果上,另外由于使用了变换器神经网络,使得训练模型所需时间大幅减少,提高了模型训练的效率,加快了pm2.5浓度的预测速度。
附图说明
图1是一种基于神经网络的pm2.5浓度值预测方法示意图。
图2是数据分解和筛选流程图。
图3是神经网络的训练流程图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图3,一种基于神经网络的pm2.5浓度值预测方法,所述方法包括以下步骤:
步骤1、采集原始数据,以杭州2018年1月份到2019年一月份的pm2.5历史浓度值为主体,将前11个月数据用于模型训练,将最后一个月数据用于预测:
步骤2、采用模态分解方法对pm2.5的历史浓度值进行分解并且挑选其有效数据,其过程如下:
步骤2.1、将pm2.5的历史浓度值设定为时序信号a,并将a表示为{a}={a1,a2,…ai,…,an},其中,ai为第i个pm2.5的历史浓度值,i为整数且1≤i≤n,n为pm2.5历史浓度总个数;
步骤2.2、找到整段信号的所有局部极值点(最大值点和最小值点),并用bi对这些极值点进行标注,其中1<i<n,n为极值点的总个数;
步骤2.3、将所有的相邻的bi点用线段连接,并用ci标记这些线段的中点,ci中的i的取值范围取值范围为1<i<n-1,n为极值点的总个数;
步骤2.4、添加左边界中点c0和右边界的中点cn;
步骤2.5、用这些n+1个中点构造m个差值曲线l1,…,lm,并通过公式
步骤2.6、在a-l′重复上述2.2~2.5的步骤,直到|l′|≤ε,ε为可允许的最小误差,或者重复至初始设置的筛选次数k,从而得到第一个模式i1;
步骤2.7、对于a-i1的剩余值,重复上述2.2~2.6的步骤,得到i2,i3,…,ip直到最后一个残余量r,其中,1≤p≤n;
步骤2.8、在有限的整数区间[kmin,kmax]更改筛选次数k,kmin为k取值的最小值,kmax为k取值的最大值,重复上步骤2.2~2.7,计算a-r的方差σ2和a的标准差σ0,并绘制以σ/σ0为纵坐标,以k的取值为纵坐标的关系图。
步骤2.9、在[kmin,kmax]上找到σ/σ0最小的时候k对应的值k0,用k0代入步骤2.2~2.7,输出整个分解模式。
步骤2.8、对于已经得到的分解模式数据,对其进行主成分分析,根据需要提取出对pm2.5浓度值影响较大的几组分量数据;
步骤3、采用神经网络预测pm2.5的浓度值,过程如下:
步骤3.1、创建一个包含编码和解码两个模块的神经网络,该神经网络主要由位置信息计算层、注意力机制层、位置全连接前馈层组成;
步骤3.2、设定网络的输入和输出维度,并设定网络隐含层单元数m,该节点单元数m采用经验公式给出的估计值,如下式所述:
上式中,a为输入层神经元个数,b为输出层的神经元个数,c是取值范围为0~10之间的常数;
步骤3.3、定义位置信息计算层输出公式,偶数位置的输出pepos,2i和奇数位置的输出pepos,2i+1分别为:
其中,pos代表输入位置,i代表输入维度,dmodel为512,sin()为正弦函数,cos()为余弦函数;
步骤3.4、定义其注意力机制输出,由下式表示
attentionoutput=attention(q,k,y)
其中,上式中的q是查询向量,k是键向量,v是值向量,定义q在第i维度上面的值为qi,k在第i维度上面的值为ki,v在第i维度上面的值为vi,qi、ki、vi与输入值xi之间存在以下关系:
qi=xi*wiq
ki=xi*wik
vi=xi*wiv
上式中,wiq为xi在q层的权重,wik为xi在k层的权重,wiv为xi在v层的权重;
步骤3.5、全连接前馈层网络由一个relu激活函数和一个线性激活函数组成,定义位置全连接前馈层网络输出,若将注意力机制层输出表示为y1,则全连接前馈层网络ffn输出ffn(y)为:
ffn(y)=max(0,y1w1+b1)w2+b2
其中,y1∈r,w1为y1在relu层的权重,,w2为relu层的输出在线性函数层的权重,b1为relu层的偏置系数,b2为线性函数层的偏置系数;
步骤3.6、设定网络的期望最小误差值,最大迭代次数和学习率;
步骤3.7、将步骤2中分解后所得的数据输入到步骤3.1~3.6中所创建的神经网络中,训练神经网络;
步骤3.8、判断神经网络是否收敛,当误差小于设定的神经网络的最小误差的时候,神经网络达到收敛;
步骤3.9、将用于预测的pm2.5数据输入到已经训练完成的神经网络模型中,得到pm2.5浓度的最终预测值。
- 还没有人留言评论。精彩留言会获得点赞!