一种对话生成系统及对话实现方法与流程
本发明涉及计算机
技术领域:
,特别涉及一种对话生成系统及对话实现方法。
背景技术:
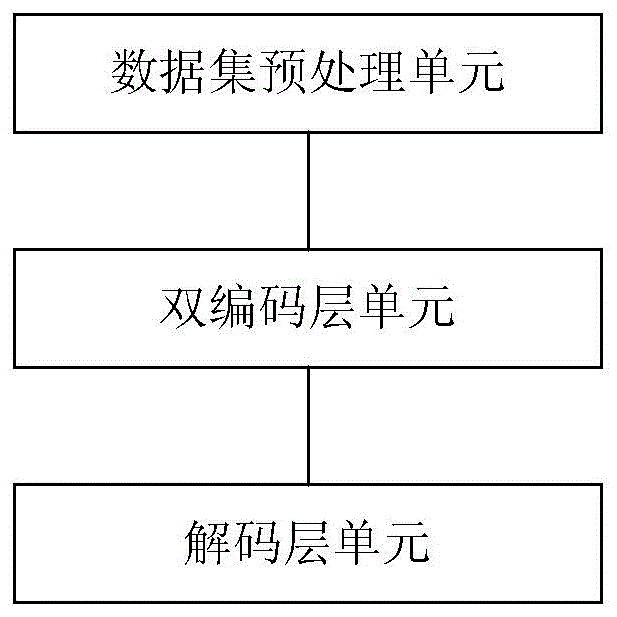
:人机对话技术还处于初级阶段,整个交互流程大多是用户进行主导,机器被动回复,即机器的回复是用于响应用户的输入,无法像人一样进行自我主导的对话交互。为了使得由机器主导对话交互,设置了基于知识图谱的主动聊天任务,机器根据构建的知识图谱进行主动聊天,使得机器具备模拟人类用语言进行信息传递的能力。在对话过程中,机器处于主动状态,引导用户从一个话题聊到另一个话题。对话系统为机器设定了一个对话目标,对话目标为“start→topic_a→topic_b”,表示从冷启动状态主动聊到话题a,然后进一步聊到话题b,提供的相关知识信息包括:话题a的知识信息,话题b的知识信息,话题a和话题b之间的关联信息。要求所设置的对话系统输出适用于对话序列h=u1,u2,…,ut-1的机器回复ut,使得对话自然流畅、信息丰富而且符合对话目标的规划。为了达成上一目的,目前的对话系统采用编码层-解码层(encoder-decoder)结构的神经网络,该神经网络中,在编码层分别对对话目标、相关知识信息及对话序列进行编码;在解码层,使用注意力机制结合对话目标及对话序列中的信息尽可能得到最恰当的相应对话回复。但是,目前的对话系统实际上采用的是基线模型结构的神经网络,其存在以下不足:1)编码层在进行编码时相互独立,忽略了历史对话序列可以融入以使得对话序列的语义更丰富的可能性;2)解码层在确定相应对话回复时的过程缺乏深度交互,同时显得过于单薄,可能导致推理不足或信息损失。综上,采用目前对话系统处理对话时,存在得到的相应对话回复准确性不高及不流畅的问题。技术实现要素:有鉴于此,本发明实施例提供一种对话生成系统,该系统能够在处理对话时,提高生成相应对话回复的准确性及流畅性。本发明实施例还提供一种对话生成方法,该方法能够在处理对话时,提高生成相应对话回复的准确性及流畅性。本发明实施例是这样实现的:一种对话生成系统,包括:数据集预处理单元、双编码层单元及解码层单元,其中,数据集预处理单元,用于对包含对话目标、相关知识信息及对话序列的数据集分别针对字符级的编码层及针对词语级的编码层进行重构,输出给双编码层单元;双编码层单元,包括字符级的编码层及词语级的编码层,用于字符级的编码层对接收的经过重构的字符级的数据集进行编码,词语级的编码层对接收的经过重构的词语级的数据集进行编码后,将经过编码后的字符级的数据集和词语级的数据集联合后,输入给解码单元;解码层单元,用于接收联合后的数据集,进行解码,得到目的、知识以及历史对话信息,生成相应回复。所述双编码层单元,还用于所述数据集分别针对字符级的编码层及针对词语级的编码层进行重构为:将数据集包含的对话目标、相关知识信息及对话序列分别进行知识转化,以三元组主谓宾spo表示;将其中的对话目标替换为目标标记字符分别拼接在从对话目标得到的共性知识左右;对于词语级的编码层将相关知识信息中的宾语替换为知识替代字符,对于字符及的编码层将相关知识信息中的宾语不做处理,将主语采用设置的位置信息标识,对相关知识信息进行扩展、拆分为单元知识及抽取规则知识;将繁体中文转化为简体中文。所述双编码层单元采用transformer模型的神经网络,所述字符级的编码层使用bert中文模型进行初始化,包含12层transformer模块;所述词语级的编码层采用随机初始化,包含6层transformer模块;所述解码层单元采用transformer模型的神经网络,采用随机初始化,包含6层transformer模块。所述解码层单元,还用于在得到目的、知识及历史对话信息,生成相应回复之前,进行预测优化。所述预测优化采用波束搜索。一种对话实现方法,该方法包括:对包含对话目标、相关知识信息及对话序列的数据集分别针对字符级的编码层及针对词语级的编码层进行重构;对经过重构的字符级的数据集进行编码,对经过重构的词语级的数据集进行编码后,将经过编码后的字符级的数据集和词语级的数据集进行联合;对联合后的经过编码后的字符级的数据集和词语级的数据集,进行解码,得到目的、知识以及历史对话信息,并生成相应回复。所述数据集分别针对字符级的编码层及针对词语级的编码层进行重构为:将数据集包含的对话目标、相关知识信息及对话序列分别进行知识转化,以三元组主谓宾spo表示;将其中的对话目标替换为目标标记字符分别拼接在从对话目标得到的共性知识左右;对于词语级的编码层将相关知识信息中的宾语替换为知识替代字符,对于字符及的编码层将相关知识信息中的宾语不做处理,将主语采用设置的位置信息标识,对相关知识信息进行扩展、拆分为单元知识及抽取规则知识;将繁体中文转化为简体中文。所述对经过重构的字符级的数据集进行编码采用transformer模型的神经网络,使用bert中文模型进行初始化,包含12层transformer模块;所述对经过重构的词语级的数据集进行编码采用transformer模型的神经网络,采用随机初始化,包含6层transformer模块。所述解码采用transformer模型的神经网络,采用随机初始化,包含6层transformer模块,在每个transformer模块中的self-attention后外接一层vanillaattention。在得到目的、知识以及历史对话信息,生成相应回复之前,进行预测优化,所述预测优化采用波束搜索。在得到目的、知识以及历史对话信息,生成相应回复之后,该方法还包括:进行输出后处理,去掉重复片段及对没有标点符号的句子做补全。如上所见,本发明实施例设置的对话生成系统采用encoder-decoder结构的神经网络,在编码层中采用分别针对字符级及词语级的双编码层,且将经过该双编码层编码后的信息进行联合。在编码层对包含对话目标、相关知识信息及对话序列的数据集进行编码之前,分别针对字符级的编码层及针对词语级的编码层进行数据集的重构后,再输入到对话生成系统中的双编码层分别编码及联合后,再输入给解码层,由解码层使用transformer模型根据联合后的数据集信息得到目的、知识以及历史对话信息,生成相应回复。这样,由于本发明实施例对数据集进行重构及采用双编码层联合的结构,所以使得数据集中融入更多的知识信息及相关知识信息之间有深度的交互,从而使得最终生成的相应对话回复更准确,提高生成的相应对话回复的准确性及流畅性。附图说明图1为本发明实施例提供的对话生成系统结构示意图;图2为本发明实施例提供的对话实现方法流程图;图3为本发明实施例提供的对话生成系统采用的模型框架图;图4为本发明实施例提供的双编码层采用的模型框架图;图5为本发明实施例提供的解码层采用的模型框架图、具体实施方式为使本发明的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本发明进一步详细说明。为了提高机器在对话过程中生成的相应对话回复的准确性及流畅性,本发明实施例设置的对话生成系统采用encoder-decoder结构的神经网络,在编码层中采用分别针对字符级及词语级的双编码层,且将经过该双编码层编码后的信息进行联合。在编码层对包含对话目标、相关知识信息及对话序列的数据集进行编码之前,分别针对字符级的编码层及针对词语级的编码层进行数据集的重构后,再输入到对话生成系统中的双编码层分别编码及联合后,再输入给解码层,由解码层使用transformer模型根据联合后的数据集信息得到目的、知识以及历史对话信息,生成相应回复。这样,由于本发明实施例对数据集进行重构及采用双编码层联合的结构,所以使得数据集中融入更多的知识信息及相关知识信息之间有深度的交互,从而使得最终生成的相应对话回复更准确,提高生成的相应对话回复的准确性及流畅性。图1为本发明实施例提供的对话生成系统结构示意图,包括:数据集预处理单元、双编码层单元及解码层单元,其中,数据集预处理单元,用于对包含对话目标、相关知识信息及对话序列的数据集分别针对字符级的编码层及针对词语级的编码层进行重构,输出给双编码层单元;双编码层单元,包括字符级的编码层及词语级的编码层,用于字符级的编码层对接收的经过重构的字符级的数据集进行编码,词语级的编码层对接收的经过重构的词语级的数据集进行编码后,将经过编码后的字符级的数据集和词语级的数据集联合后,输入给解码单元;解码层单元,用于接收联合后的数据集,进行解码,得到目的、知识以及历史对话信息,生成相应回复。在本发明实施例中,所述数据集分别针对字符级的编码层及针对词语级的编码层进行重构为:将数据集包含的对话目标、相关知识信息及对话序列分别进行知识转化,以三元组主谓宾spo表示;将其中的对话目标替换为目标标记字符分别拼接在从对话目标得到的共性知识左右;对于词语级的编码层将相关知识信息中的宾语替换为知识替代字符,对于字符及的编码层将相关知识信息中的宾语不做处理,将主语采用设置的位置信息标识,对相关知识信息进行扩展、拆分为单元知识及抽取规则知识;将繁体中文转化为简体中文。在该结构中,所述双编码层单元采用transformer模型的神经网络,所述字符级的编码层使用bert中文模型进行初始化,包含12层transformer模块,文本长度设为512字节;所述词语级的编码层采用随机初始化,包含6层transformer模块,文本长度设置为384字节。在该结构中,所述解码层单元采用transformer模型的神经网络,采用随机初始化,包含6层transformer模块,在每个transformer模块中的每次自注意机制(self-attention)后外接一层vanilla注意力机制(vanillaattention),以获得目的、知识以及历史对话信息,生成相应回复。在该系统中,在得到目的、知识以及历史对话信息,生成相应回复之前,进行预测优化。所述预测优化采用波束搜索,波束搜索的宽度设置为2。图2为本发明实施例提供的对话实现方法流程图,其具体步骤为:步骤201、对包含对话目标、相关知识信息及对话序列的数据集分别针对字符级的编码层及针对词语级的编码层进行重构;步骤202、对经过重构的字符级的数据集进行编码,对经过重构的词语级的数据集进行编码后,将经过编码后的字符级的数据集和词语级的数据集进行联合;步骤203、对联合后的经过编码后的字符级的数据集和词语级的数据集,进行解码,得到目的、知识以及历史对话信息,生成相应回复。在该方法中,所述数据集分别针对字符级的编码层及针对词语级的编码层进行重构为:将数据集包含的对话目标、相关知识信息及对话序列分别进行知识转化,以三元组主谓宾spo表示;将其中的对话目标替换为目标标记字符分别拼接在从对话目标得到的共性知识左右;对于词语级的编码层将相关知识信息中的宾语替换为知识替代字符,对于字符及的编码层将相关知识信息中的宾语不做处理,将主语采用设置的位置信息标识,对相关知识信息进行扩展、拆分为单元知识及抽取规则知识;将繁体中文转化为简体中文。在该方法中,对经过重构的字符级的数据集进行编码采用transformer模型的神经网络,使用bert中文模型进行初始化,包含12层transformer模块,文本长度设为512字节。在该方法中,对经过重构的词语级的数据集进行编码采用transformer模型的神经网络,采用随机初始化,包含6层transformer模块,文本长度设置为384字节。在该方法中,所述解码采用transformer模型的神经网络,采用随机初始化,包含6层transformer模块,在每个transformer模块中的self-attention后外接一层vanillaattention,以获得目的、知识以及历史对话信息,生成相应回复。在该方法中,在得到目的、知识以及历史对话信息,生成相应回复之前,进行预测优化。所述预测优化采用波束搜索,波束搜索的宽度设置为2。以下对如何对包含对话目标、相关知识信息及对话序列的数据集分别针对字符级的编码层及针对词语级的编码层进行重构的过程详细说明。在进行重构时,采用所设置的特殊分隔符将对话目标、相关知识信息及对话序列拼接在一起,通过字符级及词语级两种粒度进行重构。具体的重构思路为:1)由于相关知识信息经常变化,其中很多词语的词频极少,所设置的对话生成系统难以学习到这些词语的信息,本发明实施例使用设置的特殊字符替换掉固定类型的知识信息,这不仅仅强化学习能力,还缩减了词汇表,提高了训练和预测的速度。针对词语级的编码层,本发明实施例将对话目标(包括topic_a和topic_b)替换为目标实体字符,同时相关知识信息三元组spo中的o替换成不同的知识替代字符,对话序列中有仅使用部分相关知识信息的情况,对话生成系统无法通过强制匹配得出对话是否使用了某条知识,因此基于匹配率(f1)值将对话目标及对话序列涉及到的相关知识信息替换为知识替代字符,具体当对话目标及对话序列的片段与相关知识信息中的o的f1值大于设置的第一阈值(比如0.8)时,则将该片段替换为知识替代字符。知识替代字符的替换同时,必然引起信息损失,考虑到这一点,字符级的编码层中则不将相关知识信息替换掉。2)对话序列中不仅仅是记录了对话历史及用户特性的上下文,还蕴含目标进度和潜藏下轮对话方向。如果对话序列恰好谈论到对话目标a,那么下轮对话方向将是结合知识更深层次地描述对话目标a或尝试从对话目标a引导到对话目标b。为了使得对话生成系统获取更丰富的上文信息,对话序列采用各部相同的特殊标记字符进行拼接,这将有助对话生成系统识别每一轮对话的主导方及对话目标达成进度。举一个例子说明,如:对话序列为:知道外国有个明星长得很萌吗?<conversation1>这个还真不知道呢,请问是谁呀?<conversation2>是托马斯·桑斯特,颜值太高了。<conversation3>哦,没听说过呢,你能给大体说说么?<conversation4>。3)繁体中文转换为简体中文。在本发明实施例的数据集中的相关知识信息来源于对话过程中诸如电影和娱乐人物领域有聊天价值的知识信息,以三元组spo形式组织。但是,三元组spo形式组织的相关知识信息之间缺乏链接信息,如票房、家人、评价和上映时间等。为了获得更好的知识表示,采用了知识转换方式。在逻辑学中,亚里士多德在范畴篇规定并讨论了十大基本概念,包括:实体、数量、关系、性质、活动、遭受、姿态、时间、地点及状态,并称他们为范畴。同时,亚里士多德对各种形式的存在做了定义:一个存在是任何一个可以用“是”或“有”来描述对象。本发明实施例受到启发,可以通过特定的链接词将相关知识信息映射为句子型知识,同时使得知识信息尽可能不会损失和改变。在逻辑学的理论基础下,本发明实施例将数据集给出的44种不同知识类型,划分为出以下六种链接方式:1)‘是’,如:托马斯·桑斯特的血型是a型;2)‘有’,如:托马斯·桑斯特的代表作有神秘博士第三季;3)‘在’,如:夜惊魂在五年前上映;4)逗号链接,如:儿童法案,口碑很差;5)特殊字符拼接,如:托马斯·桑斯特<split1>评论<split2>第一次看到这孩子是在《真爱至上》,萌翻了,现在长大了气质不错;6)s和o直接拼接,如:夜惊魂已上映。对于给出的对话目标,本发明实施例首先在对话目标中删除第一个三元spo的开始节点,然后将包括对话目标共性知识映射为句子型知识,再将对话目标采用目标标记符拼接在句子型知识的左右。本发明实施例通过这种方式实现对相关知识信息的知识转化,有助于对话生成系统的理解和使用。本发明实施例在将相关知识信息映射为句子型知识时,考虑到知识三元组spo中的s节点是对话目标topic_a和topic_b两者之一,为了缩短文本长度,避免不必要的资源开销,在映射过程中删去了s信息,取而代之的是,通过位置信息区分知识主体。具体来说,对话目标中已经包含了topic_a和topic_b,因此,将topic_a的句子型知识放在对话目标的左边,topic_b的句子型知识放在对话目标的右边,然后再通过“知识-目标”标记符拼接起来。特别注意的是,知识与知识之间分别采用topic_a知识拼接符、topic_b进行知识拼接符完成拼接,以强化知识融入到对应实体的能力。针对一些较复杂的特殊知识字符,进行以下处理:1)针对知识有多种用法的情况进行知识拓展。如:[s,血型,a型]的拓展知识为[s,血型,a]和[s,血型,a型血]。2)将多元知识拆分为单元知识。如:[s,获奖,1956年第9届戛纳电影节主竞赛单元金棕榈奖(提名)],该知识可能在对话序列被使用为“1956年s提名了第9届戛纳电影节的主竞赛单元金棕榈奖”。为了降低使用此类知识的难度,将“获奖”类型当作一种包含多类知识的多元知识,并通过规则将其拆分为时间、影片名、奖项名、届信息、奖项细节、以及获奖结果这六类单元知识。3)从不规则的知识中抽取出规则知识。如:[s,出生日期,1978-1-12],本发明实施例抽取出以下几类规则信息:1、出生年:1978年;2、生日:1月12日;3、出生年月日:1978年1月12日。人机对话技术目前主要有两种实现方式:检索式对话和生成式对话,本发明实施例采用的是生成式方案。即在对话目标、相关知识信息及对话序列的基础下,生成自然流畅、信息丰富而且符合对话目标的语句。图3为本发明实施例提供的对话生成系统采用的模型框架图,整个模型主要分为:1)词嵌入层,将词语映射到对应的词向量上,通过位移区分知识及会话序列;2)双编码层,包括基于bert中文模型的字符级编码层和基于transformer的词语级编码层,旨在获得不同粒度的差异化信息;3)解码层,基于transformer的词语级解码层,该层将通过自注意力机制对目标输入(targetinput)进行编码,形成上文信息,并通过vanillaattention获取双解码层的最终输出信息,旨在预测下一个词语。词嵌入层该层中,词向量表由随机初始化得出,字向量表使用了bert中文模型,它们都是768伪的向量。此外,为了得到有辨识度的语义标识,采用了键入式(typewise)层来区分对话目标、相关知识信息及对话序列,即对话目标、相关知识信息及对话序列的向量分别进行空间位移,以映射到不同的空间域中,最终达到语义区分的效果。双编码层考虑到循环神经网络对序列顺序的依赖性或将影响知识平等性,如后出现的知识信息可能更容易受到关注,本发明实施例未使用几下模型的rnn类的神经来进行编码。取而待之,如图4所示,图4为本发明实施例提供的双编码层采用的模型框架图,使用了transformer模型对两种粒度输入进行编码,字符级编码层使用了bert中文模型进行初始化,包含12层的transformer模块,文本长度设为512字节;词语级编码层为参数随机初始化的6层transformer模块,文本长度设为384字节。transformer模型完成通过self-attention对字与字、词语与词语进行信息交互,这在一定程度上保障了知识信息的平等性。上一层的typewise操作很好地划分开对话目标、相关知识信息及对话序列,使得三者可以互相有选择地挑选其他信息来源以丰富自身语义表征。bert中文模型有很强的语境化编码能力,而解码时输出的是词语,扩充知识替换后的词语级编码更能有效扩充信息和提高解码精确度。在12层和6层这样的深度交互下,transformer模型很好地捕捉到了当前目标进度和会话历史。解码层在本发明实施例中,所采用的自动评估方式需要对机器输出回复进行分词,为了减少分词误差,采用了词语级解码层。如图5所示,图5为本发明实施例提供的解码层采用的模型框架图。与词语级编码层一样,本发明实施例的解码层采用参数随机初始化的6层transformer模块,但是其中每次self-attention后额外接一层vanillaattention,用以获取编码层信息。本发明实施例以编码层的机器回复作为解码层的上文输入,并加以右向遮掩,使得每个目标输入(targetinput)的词语在self-attention时仅能交互上文。对双编码层的输出,本发明实施例做了简单拼接操作,双编码层的长度分为512字节和384字节,由此得出解码时输入的编码结果长度为896字节。解码层的主要任务是根据targetinput和编码信息预测下一个词语是什么,如:输入为“[start]喜欢看剧情电影吗?”,预测输出“喜欢看剧情电影吗?[end]”。其中,targetinput为给定数据的下轮回复。本发明实施例在得到目的、知识以及历史对话信息,生成相应回复之前,进行预测优化。在进行预测优化时,相比于贪婪搜索,本发明实施例选择更容易达到全局优化的波束搜索,宽度设置为2。本发明实施例还采用了长度罚数,超参数设置为0.6。本发明实施例在得到目的、知识以及历史对话信息,生成相应回复之后,还包括:进行输出后处理,即去掉重复片段及对没有标点符号的句子进行补全。采用本发明实施例进行了实验,以下具体对实验进行说明。本实验使用了2019语言与智能技术竞赛知识驱动对话赛道的数据集,共有3万会话,约12万轮对话,其中10万训练集,1万开发集,1万测试集。数据本身已经分好词,所以本实验不需要做分词处理。本实验环境及硬件条件如表1所示。表1本实验参数如表2所示。值得注意的是,由于bert中文模型是已经设置好的模型,为了避免过大的梯度导致打破、覆盖bert中文模型的知识,本发明实施例采用了学习率分层的方式来训练模型。char-level编码层的参数采用了bert中文模型的参数设置,这里不再赘述。超参设置learningrate1e-4learningrate(char-levelencoder)1e-5optimadamembedingsize768hiddensize768batchsize16numlayers6numheads(word-levelencoder)12numheads(word-leveldecoder)8epoch15表2由于模型参数较多以至batchsize偏小,而transformer模型对batchsize比较敏感,本实验采用了梯度累加的策略,模拟较大batchsize来训练模型。最后,通过验证集的得分找出最佳的checkpoint作为最终模型。得到的实验结果最终得到的实验结果如表3所示,采用本发明实施例进行的实验,得到的自动评估结果比第三名高出3个百分点,在人工评估阶段本实验的连贯性排名第二,比排第三的连贯性要高0.9。可见本发明实施例提供的模型在对话自然流畅上具有较大的优势。表3以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1