一种适合向量处理的多核软件架构的实现方法及装置与流程
本发明涉及多核负载均衡领域,更具体涉及一种适合向量处理的多核软件架构的实现方法及装置。
背景技术:
由于温度、制程、功耗等多方面约束,处理器单核频率提升日益困难。为了提高处理器性能,多核技术逐渐成为数字信号处理器更新迭代的主流趋势。多核技术的瓶颈在于应用优化。如何将应用任务分配到处理器内部各核,充分发挥各核处理性能成为多核软件优化的重点。
将任务均衡的分配到多个处理内核,是发挥多核处理器优势的关键,多核并行处理的研究具有十分重要的应用价值与广阔的应用前景。将串行处理转并行处理常用的方法有多线程操作系统(例如linux的posixthread)和并行开发环境(例和openmp开发环境)。多线程操作系统的一个进程中可包括多个线程,每个线程并行执行不同的任务;并行开发环境一般由用户在源码中对需要并行处理部分添加并行标识符,编译器根据标识符完成并行化操作。中国专利公开号cn101631139a,公开了基于多核平台的负载均衡软件架构及方法,其主要是采用多核平台和负载均衡设备作为架构元件,并为负载均衡设备上的每个网卡初始化一个内核线程,作为该网卡的软中断例程,各自处理所对应网卡的输入和输出,同时将所有内核线程独立化;为每两个网卡线程之间的信息交换建立一个独立的通道,每个通道中建立一组双向环形队列作为多核平台和负载均衡设备的联结器;环形队列维护一个写指针和一个读指针,分别由两个线程操作,使线程间消息交换无需加锁;在网卡输入的软中断例程中实现服务器负载均衡的选路策略,并在链路层执行应用层的所有工作。该发明的优点是实现了服务器的负载均衡,它能够显著地提高负载均衡设备的性能。但是该发明采用线程操作,需要操作系统支持,采用网卡进行输入输出控制,需要额外硬件支持。依赖于操作系统与并行开发环境的并行化处理一般由芯片厂商提供底层软件支持。如果芯片厂商实力不足以提供支持或得不到相关操作系统或开发环境的授权,用户很难自主实现。
技术实现要素:
本发明所要解决的技术问题在于如何提供一种独立于操作系统与硬件之外的,用户能够自主实现的多核软件架构的实现方法及装置。
本发明通过以下技术手段实现解决上述技术问题的:一种适合向量处理的多核软件架构的实现方法,所述方法包括:将输入向量按照处理核的数量均分为若干个待处理子向量,每个处理核处理其中一个待处理子向量,当输入向量的长度无法被处理核的数量整除时,由指定的处理核处理余数部分对应的待处理子向量;
预先将形参相同,处理核间交互方式相同,输出向量切分方式相同的函数运算归为同一函数类,并建立针对所述函数类的函数模板,进而得到由函数模板构成的函数模板集,其中,所述函数运算为输入向量中包括的待处理子向量的运算;
然后每个处理核对其对应的待处理子向量进行处理时,从函数模板集中调用待处理子向量对应的函数模板,再将函数模板中的函数指针的输入参数赋值到该待处理子向量的子向量之间需要进行的函数运算。
本发明将向量型并行计算与多核芯片相结合,先进行向量任务分割,将向量均分,从而实现均衡负载,然后将具有相同处理流程的函数归为一类建立函数模板,众多函数模板再生成函数模板集,进行多核处理时,每个处理核只需要调用其对应的待处理子向量的函数模板,不需要重复编译处理流程相似的代码,减少重复性工作,提高效率,降低错误率,便于后期维护。且本发明的多核处理流程只要在c语言环境下运行函数模板集即可,不依赖于操作系统以及并行开发环境,独立于操作系统与硬件之外,可由用户自主实现。
优选的,每个所述函数模板中均包括cache优化操作。多核处理相关的cache维护,内存交互、合成优化等操作封装在函数模板中,顶层软件开发人员直接利用优化后的封装函数进行工程实现,不仅可以提高处理实时性,还有利于提升软件开发效率。
优选的,所述指定的处理核是若干个处理核中的任一个。
优选的,所述指定的处理核是若干个处理核中的物理地址处于最后一个的处理核。
本发明还提供一种适合向量处理的多核软件架构的实现装置,所述装置包括:
向量切分模块,用于将输入向量按照处理核的数量均分为若干个待处理子向量,每个处理核处理其中一个待处理子向量,当输入向量的长度无法被处理核的数量整除时,由指定的处理核处理余数部分对应的待处理子向量;
函数模板集构建模块,用于预先将形参相同,处理核间交互方式相同,输出向量切分方式相同的函数运算归为同一函数类,并建立针对所述函数类的函数模板,进而得到由函数模板构成的函数模板集,其中,函数运算为输入向量中包括的待处理子向量的运算;
处理模块,用于每个处理核对其对应的待处理子向量进行处理时,从函数模板集中调用待处理子向量对应的函数模板,再将函数模板中的函数指针的输入参数赋值到该待处理子向量的子向量之间需要进行的函数运算。
优选的,每个所述函数模板中均包括cache优化操作。
优选的,所述指定的处理核是若干个处理核中的任一个。
优选的,所述指定的处理核是若干个处理核中的物理地址处于最后一个的处理核。
本发明的优点在于:
(1)在雷达阵列信号处理、遥感图像、气象研究等领域,矩阵、傅里叶变换、滤波、偏微分方程等数学问题通常是以向量为基础进行求解,向量各元素上执行的运算操作一般是相互独立的,本发明将向量型并行计算与多核芯片相结合,提出一种适合向量处理的多核软件架构的实现方法,将具有相同处理流程的函数归为一类建立函数模板,众多函数模板再生成函数模板集,其多核处理流程只要在c语言环境下运行函数模板集即可,不依赖于操作系统以及并行开发环境,不需要多核芯片厂商提供底层软件支持,可由用户自主实现。
(2)本发明将向量型并行计算与多核芯片相结合,先进行向量任务分割,将向量均分,从而实现均衡负载,然后将具有相同处理流程的函数归为一类建立函数模板,众多函数模板再生成函数模板集,进行多核处理时,每个处理核只需要调用其对应的待处理子向量的函数模板,不需要重复编译处理流程相似的代码,减少重复性工作,提高效率,便于后期维护。
附图说明
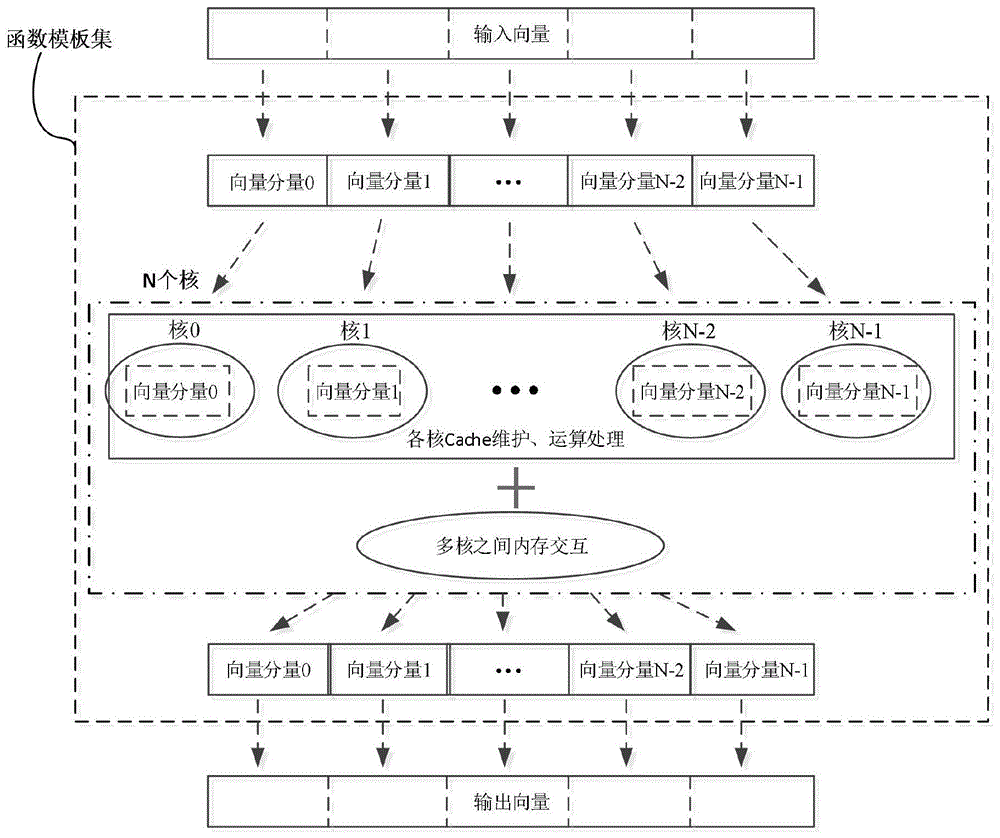
图1为本发明实施例所公开的一种适合向量处理的多核软件架构的实现方法的多核并行处理示意图;
图2为本发明实施例所公开的一种适合向量处理的多核软件架构的实现方法中函数模板集的构建示意图;
图3为本发明实施例所公开的一种适合向量处理的多核软件架构的实现方法中基于多核函数模板将单核函数扩展为多核函数的过程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
如图1所示,一种适合向量处理的多核软件架构的实现方法,所述方法包括:将输入向量按照处理核的数量均分为n个待处理子向量,即图1所示的向量分量0至向量分量n-1,每个处理核处理其中一个待处理子向量,即图1所示的,核0处理向量分量0,核n-1处理向量分量n-1,每个处理核都有一个物理地址,待处理子向量分配给每个处理核实质上是物理地址的分配,当输入向量的长度无法被处理核的数量整除时,由指定的处理核处理余数部分对应的待处理子向量;其中,所述指定的处理核是若干个处理核中的任一个。在本发明实施例中所述指定的处理核是若干个处理核中的物理地址处于最后一个的处理核,也即图1所示的核n-1。
以上阐述的是一个输入向量的情况,对于若干个输入向量的情况,各输入向量按上述同样方法划分为对应的n个待处理子向量。每个处理核处理每个输入向量对应的某一待处理子向量,共若干个待处理子向量。若干个待处理子向量之间需要进行若干种函数运算,于是预先将形参相同,处理核间交互方式相同,输出向量切分方式相同的函数运算归为同一函数类,并建立针对所述函数类的函数模板,进而得到由函数模板构成的函数模板集,其中,所述函数运算为输入向量中包括的待处理子向量的运算;例如向量a加向量b的函数运算与向量a乘以向量b的函数运算,具有相同形参,且形参个数和类型相同,处理流程相同即处理核间交互方式相同,输出向量切分方式相同,所以向量a加向量b的函数运算与向量a乘以向量b的函数运算归为同一函数类,建立函数模板。需要注意的是,形参相同在本发明中是指形参个数和形参类型相同。
然后每个处理核对其对应的待处理子向量进行处理时,根据待处理子向量的输入、输出、形参个数和类型,处理核间交互方式,输出向量切分方式、函数运算等从函数模板集中调用待处理子向量对应的函数模板,然后再将函数模板中的函数指针的输入参数赋值到该待处理子向量的子向量之间需要进行的函数运算,函数模板中包含同一函数类的多种函数运算,将函数指针的输入参数赋值到该待处理子向量的子向量之间需要进行的函数运算以在运算时利用此函数指针调用对应的函数运算,代码调用函数指针对应函数时就完成了待处理子向量之间需要进行的多种函数运算,这种调用方式,简化了多核实现代码,减少运行时间,提高处理速度,避免同一函数类的多种函数运算的代码重复执行多次,避免同一函数类的多种函数需要一一对应的多个多核实现版本。如图2所示,本发明的运行环境为c语言编译系统,多种函数运算以多段代码的形式存储在执行代码中,同一函数类的函数运算构建一个函数模板,多个函数模板组成函数模板集。以复数向量取模后乘以常数的单核函数bw_cvabsmuls、复数向量归一化后乘以常数的单核函数bw_cvnormmuls、浮点型向量乘以常数后求余弦的单核函数bw_vmulscos为例,这三个函数均可归入到同一函数类vsov。该函数类对应多核函数模板为vw_vsov。将各单核函数作为函数指针代入多核函数模板后即得到对应多核函数版本vw_cvabsmuls、vw_cvnormmuls及vw_vmulscos,如图3所示,为了便于理解,图3以代码的形式展现基于多核函数模板将单核函数扩展为多核函数的过程,其中各段代码属于本领域常规语言描述,本领域技术人员能够毫无疑义的理解该过程,在此不做赘述。
目前的处理芯片,其内核的主频非常的高,但是外存要做到较高的主频就需要付出很大的代价。为了达到高费效比,现代的芯片一般的来说是在处理核内设置一个容量很小的速度很快的存储区,这段区域称为cache,由于外存较大且速度比较慢,如果在处理中能够及时的把需要处理的数据从外存搬移到内部的cache中,那么性能将会大大提升。所以本发明还涉及cache优化操作,如图1所示,每个所述函数模板中均包括cache优化操作。本发明cache优化操作的优点在于它不用再针对每个单个的函数进行所有的这种优化操作,而是由于一个函数模板就对应了多个处理函数即多种函数运算,所以多个处理函数的cache优化操作可以一个函数模板内完成,简化优化操作的工作量。多核处理相关的cache维护,多核之间的内存交互、合成优化、运算处理等操作封装在函数模板中,顶层软件开发人员直接利用优化后的封装函数进行工程实现,不仅可以提高处理实时性,还有利于提升软件开发效率。
最后经过每个处理核处理的待处理子向量均输出,形成输出向量,至此向量的多核处理完成。
本发明的工作过程为:以单精度浮点向量加法为例,a、b为长度为n的输入向量,c为长度为n的输出向量,实现向量a加向量b等于向量c,在多核芯片上完成这一任务时,假设有m个核,每个核具有一个id作为标记(id号从0到m-1),将向量a和向量b均分为m等份以后,考虑到向量长度有可能不能被m整除,最后一个核(id号为m-1)负责处理的最后一个待处理子向量可能会多出几个子向量,除最后一个核以外的核处理平均数长度的待处理子向量,然后调用vaddv函数完成向量a的子向量与向量b的子向量相加的处理,多核处理过程中,向量a与向量b的相加转化为每个核处理一部分长度的向量a与一部分长度的向量b的相加,由于向量处理的运算量与向量长度成正比,这样原来的向量处理任务就均分到了多个核,为了能够充分发挥芯片性能,实际程序中往往还要加上cache操作等函数。
如果采用这种从单核到多核的实现方法,那么每一个单核函数均要编写对应的多核版本函数,软件开发工作量非常大。比较单精度浮点向量相乘与单精度浮点向量相加的多核版本函数,单精度浮点向量相乘调用乘法函数vmulv,单精度浮点向量相加调用加法函数vsubv,可以发现除了调用的处理函数不同外两个函数架构完全相同,如果我们能够将调用的处理函数vmulv和vsubv作为一个参数调入的话,这两个多核函数就可以统一由一个函数完成。于是得到了函数模板的初步概念。同一函数类的函数归为一个函数模板,同一函数类的函数具有相同形参、相同输入、相同输出、形参个数和类型相同,处理核间交互方式相同,输出向量切分方式相同,所以vsubv、vmulv等函数可以归为同一函数类即归为一个函数模板。将处理函数作为参数调入采用函数指针最为方便可靠,于是将上述函数模板中的函数指针的输入参数赋值到vsubv、vmulv等函数,实现两个多核函数统一由一个函数完成,这里只是以两个多核函数为例,实际中可以不止两个多核函数统一由一个函数完成,即实际中可以不止两个多核函数归为同一函数模板,最终在处理过程中的众多函数模板组成一个函数模板集,下一次进行多核处理时,只需要根据输入输出形参等信息来调用待处理子向量对应的函数模板即可。
通过以上技术方案,本发明提供一种适合向量处理的多核软件架构的实现方法将向量型并行计算与多核芯片相结合,先进行向量任务分割,将向量均分,从而实现均衡负载,然后将具有相同处理流程的函数归为一类建立函数模板,众多函数模板再生成函数模板集,进行多核处理时,每个处理核只需要调用其对应的待处理子向量的函数模板,不需要重复编译处理流程相似的代码,减少重复性工作,提高效率,降低错误率,便于后期维护。且本发明的多核处理流程只要在c语言环境下运行函数模板集即可,不依赖于操作系统以及并行开发环境,可由用户自主实现。
实施例2
与本发明实施例1相对应,本发明实施例2还提供一种适合向量处理的多核软件架构的实现装置,所述装置包括:
向量切分模块,用于将输入向量按照处理核的数量均分为若干个待处理子向量,每个处理核处理其中一个待处理子向量,当输入向量的长度无法被处理核的数量整除时,由指定的处理核处理余数部分对应的待处理子向量;
函数模板集构建模块,用于预先将形参相同,处理核间交互方式相同,输出向量切分方式相同的函数运算归为同一函数类,并建立针对所述函数类的函数模板,进而得到由函数模板构成的函数模板集,其中,所述函数运算为输入向量中包括的待处理子向量的运算;
处理模块,用于每个处理核对其对应的待处理子向量进行处理时,从函数模板集中调用待处理子向量对应的函数模板,再将函数模板中的函数指针的输入参数赋值到该待处理子向量的子向量之间需要进行的函数运算。
具体的,每个所述函数模板中均包括cache优化操作。
具体的,所述指定的处理核是若干个处理核中的任一个。
具体的,所述指定的处理核是若干个处理核中的物理地址处于最后一个的处理核。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!