基于知识重组的语义图像压缩方法与流程
本发明属于数字图像压缩领域,针对终端设备性能有限、模型训练代价过大的问题,提出的一种利用现有的图像压缩模型以及语义分割模型进行知识重组,从而得到多任务模型的方法。
背景技术:
神经网络剪枝是一类通过减少网络参数来缩减网络规模的技术。通常手工设计的神经网络是过参数化的,大量的参数冗余不利于在低功耗设备上的部署。剪枝可以使得网络规模减少到一个可接受的规模,对整体性能影响较小。
基于深度学习的图像压缩是为解决数字图像中的信息冗余的一类方法。图像压缩系统由编码器、量化器、解码器组成。编码器将数字图像的像素信息转换为紧凑的中间表达,量化器将连续的编码值转换到离散的值,而解码器则从图像压缩码中重建出原始图像。由于神经网络易于设计,计算规模可控性强,因此适合部署到不同的终端设备。
语义压缩是图像解析问题的一种,通过对逐个像素点进行分类,获得输入图像的逐像素语义类别。全卷积编解码器是一类常见的语义分割结构,编码器对图像进行解析,获得空间尺寸更小的编码,解码器将编码扩展到原图像尺寸,并对每个像素生成不同类的概率值。该结构能够端到端地进行训练。
知识重组是一类利用预训练的模型来构建新模型的算法,其核心是将现有网络的知识转移到另一个网络中。通过知识重组可以最大化利用预训练模型,减少训练代价,并取得更好的性能。
由于存储需要,设备上的图像一般以压缩编码的形式存在,当对图像进行语义分割时,编码首先需要经过图像解码,获得原图像后再利用常规的语义分割方法获得语义信息,设备频繁解码造成了大量计算资源耗费。
技术实现要素:
本发明针对现有技术条件下模型训练代价较大、终端设备性能有限的问题,提出了一种结合语义分割和图像压缩的方法。本方法通过重组现有的预训练模型来获得新模型,训练过程中不需要人工的数据标注。
一种基于知识重组的语义图像压缩方法,包括如下步骤:
1)获得预训练的编解码器结构模型以及无标签数据;
分别选取用于图像压缩和语义分割任务的同构编解码器模型。语义分割模型对输入图像进行逐像素分类,图像压缩模型对数字图像进行压缩和解压。本方法使用无标签数据进行训练,即使用预训练模型对输入图像进行预测,将预测结果作为学习目标。
2)模型重组;
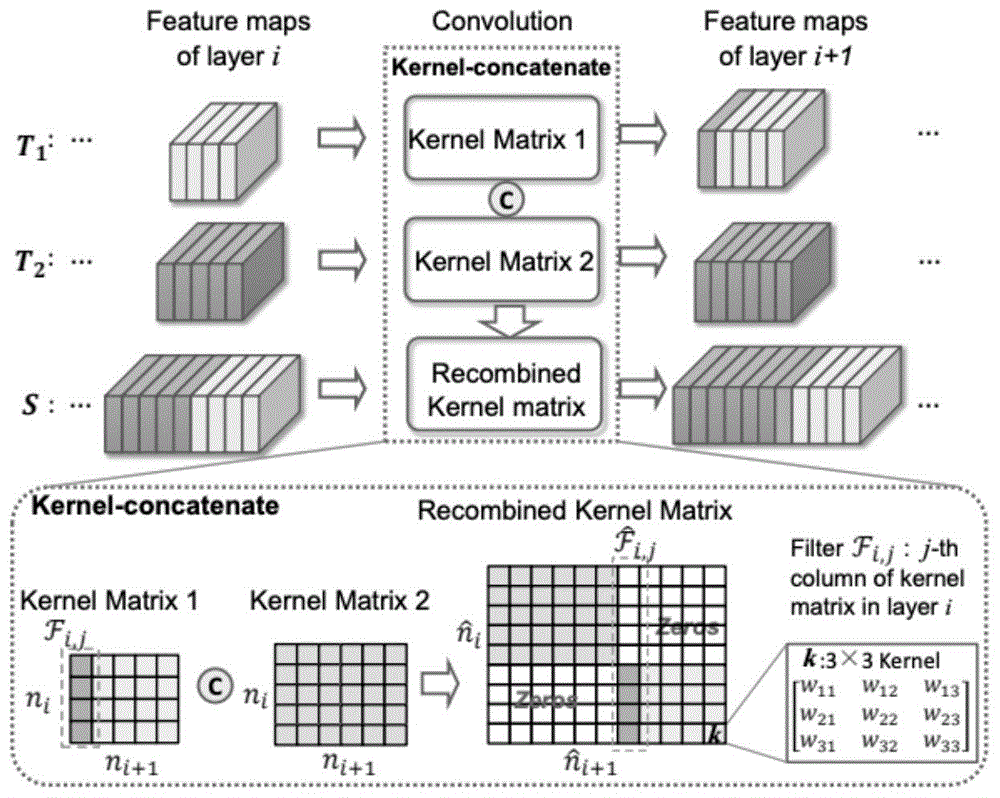
为获得功能等价的新模型,首先对现有模型的编码器的参数进行零填充,解码器不做改变,连接在重组的编码器上形成多路输出分支。重组参数能够作用于原模型的所有输入,并且不改变输出结果。考虑分别属于模型a和模型b并且大小为oa×ia×h×w和ob×ib×h×w的卷积层参数,该参数以通道数为i的特征图作为输入,得到通道数为o的输出。通过零填充使其能够接收通道数为(ia+ib)的输入,即填充至为oa×(ia+ib)×h×w和ob×(ib+ia)×h×w。最后组合两者获得到大小(oa+ob)×(ia+ib)×h×w的重组参数。由于零填充不影响模型的输出,重组模型与预训练模型功能上等价。
3)迭代剪枝减小模型规模;
本方法使用神经网络剪枝减少参数规模。对大小为o×i×h×w的卷积参数,计算o个卷积核之间两两相似度。度量标准为余弦相似度
利用无标签数据以及预训练模型预测结果作为训练数据和目标,进行多任务训练,压缩分支损失函数为均方误差
相比于现有的多任务训练、蒸馏训练方法,本方法完整地利用了现有模型的参数,通过零填充合并算法最大程度地保留了模型的功能。同时本方法通过剪枝算法降低模型计算量,并融合来自不同任务的参数,提供更完备的图像特征抽象能力。结合语义分割的压缩算法性能优于传统jpeg算法,并且不需要解码原图像即可进行语义分割,有利于在终端设备上进行部署。本算法在各种压缩率下都能够保证较高的分割精度,稳定性更强。由于语义分割不需要获得原图像,因此该方法提供了隐私方面的保障。
附图说明
图1是本发明中模型重组示意图
图2是本发明的语义图像压缩训练过程示意图
具体实施方式
下面结合附图进一步说明本发明的技术方案。
本发明的一种基于知识重组的语义图像压缩方法,包括如下步骤:
1)获得预训练的编解码器结构模型以及无标签数据;
首先收集分割模型适用的无标签数据,数据为rgb格式的三通道图片,分割模型能够在这类无标签数据上进行预测,从而获得用于训练的软目标(softtarget),软目标的尺寸与图像相同,描述了原图像每个像素属于各个类别的概率,其通道数等于类别的数量。该软标签作为语义分割的学习目标,用于后续训练。由于压缩模型的学习目标为原图像,因此可以直接使用无标签数据进行训练。
2)模型重组;
重组模型的整体结构如图2所示,包含一个共享的编码器和两个不同任务的解码器,其支分别对应图像压缩的重建模型,以及语义分割的预测模型。为获得过参数化的重组模型,需要重组编码器的参数得到等价的表达形式。如图1所示,令来自预训练模型的参数核成对角线排布,无参数的位置使用0进行填充。虑分别属于模型a和模型b、大小分别为oa×ia×h×w和ob×ib×h×w的卷积层参数,该参数以通道数为ia和ib的特征图作为输入,分别得到通道数为oa和ob的输出。通过零填充扩展参数,使其能够接收通道数为(ia+ib)的输入,即填充至oa×(ia+ib)×h×w和ob×(ib+ia)×h×w。最后组合两者获得到大小(oa+ob)×(ia+ib)×h×w的重组参数,其排布如图1中recombinedkernelmatrix所示,重组参数位于对角线上(深色部分),其余为零填充(浅色部分)。
经过重组的参数能够同时接收预训练模型的所有输入。如图2所示,各个解码器输入是共享编码器的输出。由于填充0不会改变输出结果,该重组模型与多个预训练模型等价。
3)迭代剪枝减小模型规模;
由于零填充会引入多余参数,重组模型存在过参数化、计算量大的问题。本方法通过神经网剪枝减少参数规模,并进一步融合来自不同模型的参数。对大小为o×i×h×w的重组参数,计算o个卷积核之间两两相似度。相似度的度量标准为余弦相似度
剪枝分为整体剪枝和逐层剪枝两种方式,整体剪枝每一轮同时对模型的各层参数进行剪枝。逐层剪枝一轮仅对模型的其中一层进行剪枝。整体剪枝耗时更短,精度略低,而逐层剪枝训练时间较长,但精度较高。如图2所示,在每轮剪枝后,利用预训练模型在无标签数据上的预测对剪纸模型进行训练。使经过剪枝的模型去学习软标签。在训练过程中,零填充的卷积核参数也参与训练,使得模型性能具有更大的提升空间。训练收敛后,继续进行剪枝、训练的过程直至性能、参数规模达到部署要求。
结束迭代的剪枝训练后,得到的重组模型规模较小,且精度通常能够持平甚至优于预训练模型。该重组模型能够对图像进行压缩,解码端的两个解码器能够分别解码图像和语义。编码端部署于终端设备,对图像进行采集并压缩,传输给解码端。解码端在不需要获得原始图像的情况下即可对图像进行语义分割。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围的不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!