一种基于卷积神经网络的匣钵筛分检测方法与流程
本发明涉及一种基于卷积神经网络的匣钵筛分检测方法,属于匣钵缺陷检测技术领域。
背景技术:
电子窑炉对电子粉体材料烧结时需要将电子粉体装入匣钵,由匣钵连同电子粉体材料进入电子窑炉烧成,烧成后由匣钵载着电子粉体材料一起出窑炉,在解碎工位对匣钵内的电子粉体材料解碎,而后倒出匣钵,倒出电子粉体材料后的空的匣钵经过清扫工位清扫后进入装料工位装料,之后再次引入电子窑炉烧成。由此可知,匣钵属于循环使用的周转容器,由于匣钵频繁受到骤热骤冷,随着使用次数的增加,匣钵底部会出现起皮,掉渣,匣钵四角会出现掉角,四壁会出现裂纹,这些细小的缺陷会不断的扩大直至使匣钵整体破碎。因此如果不能将形成由细微的匣钵提前筛分出来并剔除,那么在窑炉中一旦出现爆裂会产生以下技术问题:
1、由于破碎的匣钵会影响匣钵输送棍的正常运行,并还会滞留于电子窑炉的炉膛内,因而造成电子窑炉运行故障。
2、由于匣钵破碎,先前装入匣钵内的电子粉体材料无法引出炉膛,一方面会造成浪费,另一方面造成电子窑炉的运行故障。
3、由于匣钵碎裂而淤积在炉膛内的电子粉体材料清除麻烦,因而对工人炉膛清洁作业强度大,并且难以获得期望的清洁效果。
目前国内在辊道炉使用中匣钵外观的检测主要依靠人工用眼去观察匣钵外观,辊道炉周边的环境温度较高且每天24小时不停的运转,单纯依靠人工长时间待在高温环境去检测匣钵好坏,容易造成误判和漏判,且成本高,效率低,易造成不良品的产生和材料的浪费。
技术实现要素:
针对上述问题,本发明提出来一种基于卷积神经网络的匣钵筛分检测方法,其技术方案如下所述:
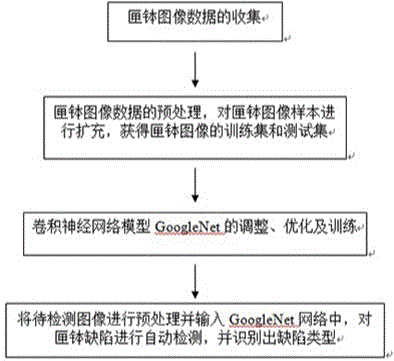
一种基于卷积神经网络的匣钵筛分检测方法,包括以下步骤:
步骤1:获取匣钵表面灰度图像,包括有缺陷和没有缺陷的匣钵的4个侧面图像和底面图像;
步骤2:对采集的匣钵图像进行预处理获得有缺陷和没有缺陷的匣钵图像样本,然后对匣钵图像样本进行扩充,获得若干匣钵图像的训练集和若干匣钵图像的测试集;
步骤3:预处理后的训练集和测试集输入到卷积神经网络模型googlenet中,调整卷积神经网络模型googlenet的参数,得到优化的卷积神经网络模型googlenet,构建googlenet网络;
步骤4:获取待识别的匣钵图像并进行步骤2所述的预处理,并输入步骤3构建的googlenet网络中进行,计算图像存在某个缺陷的概率,判断属于某类缺陷,完成匣钵缺陷检测。
进一步的,所述步骤2对采集的匣钵图像进行预处理,具体过程包括如下步骤:
步骤2-1:获取匣钵图像,对采集的匣钵图像进行裁剪,以提取有效区域,所述有效区域为匣钵测试图像中非边界区域;
步骤2-2:对步骤2-1处理后的匣钵图像进行亮度和对比度的调整;
步骤2-3:对步骤2-2处理后的匣钵图像进行缺陷标记,对有缺陷图像以缺陷为中心对有效区域内进行分割;
步骤2-4;对步骤2-3处理后的匣钵图像,进行样本扩充,获得若干匣钵图像的训练集和若干匣钵图像的测试集。
进一步的,
所述步骤2-2对亮度和对比度进行调整的具体过程为:
设f(c,v)表示调整前的图像像素,g(c,v)表示调整后的图像像素,a为用于控制图像对比度的增益,b为用于控制图像亮度的偏置,a,b在每次调整中随机取值,采用函数g(c,v)对匣钵图像的亮度和对比度进行调整:g(c,v)=a*f(c,v)+b,其中c,v表示像素点的坐标位置;
所述步骤2-3中所述缺陷标记分为正常、缺角、裂缝和龟裂,其中分割后图片的像素为512*512;
所述步骤2-4对样本扩充后,根据缺陷类型,进行分类,获取包括有缺陷与无缺陷若干张匣钵图像的训练集和若干匣钵图像的测试集。
进一步的,所述卷积神经网络模型googlenet的训练采用9个inception模块,所述inception模块包括多个卷积层和最大池化层。
进一步的,所述卷积神经网络模型googlenet采用relu激活函数加速网络训练,所述relu激活函数为relu(q)=max(0,q),其中q为单个神经元的加权求和值;
所述卷积神经网络googlenet采用sgd算法对卷积神经网络训练进行最优化求解。
进一步的,所述卷积神经网络模型googlenet的初始学习率为0.001,所述卷积神经网络模型googlenet的迭代次数间隔为2000。
进一步的,所述卷积神经网络模型googlenet使用的池化方式为:均值池化和最大池化。
进一步的,所述步骤1和步骤4中均采用工业相机对匣钵图像进行采集。
本发明的有益效果:
与现有的只检测匣钵底部龟裂缺陷相比,本发明充分考虑匣钵易出现的缺陷类型,即侧面出现裂缝、缺角、底部龟裂;利用深度学习技术得到的数据模型,可以实现对三种缺陷实时的检测;如果出现新的缺陷类型,调整数据模型的参数,重新训练得到新的数据模型,方便工作人员的操作,利用深度学习技术对带有缺陷的匣钵进行筛分,可以节约开支,提高生产的效率。
附图说明
图1为一种基于卷积神经网络的匣钵筛分检测方法的流程图;
图2为inception模块的结构图。
具体实施例
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
一种基于卷积神经网络的匣钵筛分检测方法,包括以下步骤:
步骤1:通过ccd工业相机采集有缺陷和无缺陷的匣钵的表面灰度图像,包括4个侧面图像,1个底面图像,有缺陷图像的类型可分为缺角、裂缝,龟裂。
步骤2:对采集的匣钵图像进行预处理获得有缺陷和没有缺陷的匣钵图像样本,然后对匣钵图像样本进行扩充,获得若干匣钵图像的训练集和若干匣钵图像的测试集,具体过程如下:
步骤2-1:对采集的匣钵图像进行裁剪,以提取有效区域,所述有效区域为匣钵测试图像中非边界区域;
步骤2-2:对步骤2-1处理后的匣钵图像进行亮度和对比度的调整,对裁剪后的图像进行亮度和对比度的随机调整,依据公式g(c,v)=a*f(c,v)+b调整亮度和对比度,其中c,v表示像素点的坐标位置,f(c,v)表示调整前的图像像素,g(c,v)表示调整后的图像像素,a为用于控制图像对比度的增益,b为用于控制图像亮度的偏置,a,b在每次调整中随机取值,本实施例中a的取值范围为[0.5,1.5],b的取值范围为[-30,30];
步骤2-3:对步骤2-2处理后的匣钵图像进行缺陷标记,对有缺陷图像以缺陷为中心对有效区域内进行分割,原始匣钵图片的像素为2048*2448,分割后图片的像素为512*512,图片格式为jpeg,这样能够使模型提取到更多的带有缺陷的图像,并且可以在训练阶段减少过拟合现象的发生,从而实现样本扩充;
步骤2-4;对步骤2-3处理后的匣钵图像,根据缺陷类型进行分类,样本扩充后形成一个数据集,数据集包括20000张匣钵图片,包括缺角图片5000张、裂缝图片5000张,龟裂图片5000张,正常图片5000张,将预处理后包括有缺陷与无缺陷的数据集的80%用于卷积神经网络模型googlenet的训练集,剩余的20%的数据集用于卷积神经网络模型googlenet的测试集。
步骤3:预处理后的训练集和测试集输入到卷积神经网络模型googlenet中,调整卷积神经网络模型googlenet的参数,得到优化的卷积神经网络模型googlenet,构建googlenet网络;
研究表明,增加网络深度和宽度可以增强模型的识别能力,但是为了减少过拟合,也要减少自由参数。为此,googlenet对网络中的传统卷积层进行了修改,提出了被称为inception的结构,用于增加网络深度和宽度,提高深度神经网络性能。“inception”模块的主要思路是怎样用密集成分来近似最优的局部稀疏结构。本实施例中所述卷积神经网络模型googlenet包含22层,采用改进后的inception模块如图2所示,该inception模块包括多个平行的卷积核大小为1×1、3×3、5×5的卷积层与一个最大池化层组成,用于同时捕获不同的特征。其中1x1卷积的主要目的是为了减少维度,还用于修正线性激活(relu),原始googlenet模型的初始学习率为0.001,使用“step”方法变化学习率,在经过100000次迭代并经三个分类器分类后,“top-1”的测试准确率分别为89.8%,85.6%,88.2%;“top-5”测试准确率分别为92.6%,89.6%,90.6%;系统损失是15.8%。经过40000次迭代后,“top-1”的测试准确率和系统损失曲线逐渐趋于收敛。由此可知,原始模型的训练时间和收敛时间较长,参数也较多。由于学习率是一个非常重要的参数,可以直接影响模型的收敛与否。不同的学习率变更策略也会影响最终的迭代结果,“step”方法变化学习率是等间隔调整学习率,是非常常用的一个学习率迭代策略,每次将学习率降低为原来的一定倍数,属于非连续型的变换,使用简单,而且效果通常较好。“top-1”测试准确率和“top-5”测试准确率是一种图片检测准确率的标准,“top-1”测试准确率即排名第一的类别与实际结果相符的准确率,“top-5”测试准确率即指排名前五的类别包含实际结果的准确率。
对googlenet模型进行优化
将归一化后512*512像素的训练集输入googlenet模型并对其进行改进,用googlenet模型的第一个分类器对匣钵图像数据集中的4类样本进行10000次迭代,并且每进行200次迭代后就对“top-1”精确度以及模型损失进行一次测量,本发明中,googlenet模型初始学习率为0.001,采用“step”的方法每迭代2000次变化一次学习率,学习率变化的比率为0.96。经实验,利用改进后的googlenet模型对匣钵图像数据进行训练及测试后,得到的“top-1”精确度平均值为89.9%,系统的损失平均值为2.6%。可见,改进后模型的识别精确度与损失较原始模型均有提升。
卷积神经网络模型的训练
使用预处理后的训练集来初步训练构造的googlenet模型,将初步训练后模型中的所有或者部分参数值用作最终模型参数的初始值,使用测试集中若干带有缺陷的图像对已初步训练的googlenet模型进行微调,进一步优化googlenet模型的参数,完成对googlenet模型的最终训练。
在googlenet模型训练者中,采用relu激活函数防止梯度弥散,加速网络训练。该函数能够自适应地学习整流器的参数,在不额外增加成本的同时提高精确度,并且能够使梯度在进行反向传播的同时能很好地传递到前面的网络层,防止梯度弥散的问题,同时加速网络训练。
relu激活函数定义为式:relu(q)=max(0,q)(1)
其中q为单个神经元的加权求和值。
googlenet模型中所涉及的池化方式为:均值池化,最大池化。其中最大池化是通过在特征图的k*k邻域内取最大值的方法来计算每个卷积内核输出的非重叠矩形区域的最大值,用于分离非常稀疏的特征,且能够减小卷积层参数误差造成估计均值的偏移误差,更多的保留纹理信息。定义为式(2)-(3):
其中,zi表示为激活值为i的激活数值,k表示类别的索引,m表示偏移误差,xi表示训练样本神经元的真实值,
均值池化是利用局部接受域内的所有采样点求平均,能够减小由于邻域大小受限造成的估计值方差增大的误差,更多的保留图像的背景信息,采用了均值池化来代替全连接层,该想法来自nin(networkinnetwork),事实证明这样可以将准确率提高0.56%。均值池化定义为式(4)-(5):
其中,z表示为激活值,zi表示为激活值为i的激活数值,qi为加权和,l为检索结果,k表示类别的索引,d为卷积核维度,
系统的损失函数用来测量预测结果与输入的标签之间的差异,定义见式(6),
其中w表示卷积和完全连接的层的权重矩阵,n表示训练样本的数量,xi为训练样本神经元的真实值,ytk表示为类别的结果,t是训练样本的索引,并且k是类别的索引。如果第t个样本属于第k类,ytk=1,则表示t属于k类别;否则,ytk=0,则表示t不属于k这个类别。p(xi=k)是模型预测的属于第k类的输入概率,它是参数w的函数。所以损失函数以w为参数。网络训练的目的是为了找到最小化损失函数e的w值;在本发明中,我们使用随机梯度下降算法(sgd)对w进行更新,更新方式见公式(7);
其中
步骤4:工业相机获取待识别的匣钵图像并进行步骤2所述的预处理,将预处理后的图像输入步骤3构建的googlenet网络中,计算图像存在某个缺陷的概率,判断属于某类缺陷,完成匣钵缺陷检测。
工业相机又俗称摄像机,相比于传统的民用相机(摄像机)而言,它具有高的图像稳定性、高传输能力和高抗干扰能力等,市面上工业相机大多是基于ccd(chargecoupleddevice)或cmos(complementarymetaloxidesemiconductor)芯片的相机。本发明所述ccd工业相机是采用基于ccd芯片的工业相机。
与现有的只检测匣钵底部龟裂缺陷相比,本发明充分考虑匣钵易出现的缺陷类型,即侧面出现裂缝、缺角、底部龟裂;利用深度学习技术得到的数据模型,可以实现对三种缺陷实时的检测。如果出现新的缺陷类型,调整数据模型的参数,重新训练得到新的数据模型。方便工作人员的操作,提高产品的生产效率。
另外,说明书中所出现的公式均为公知常识或常用基础的函数。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!