一种基于新闻报道的突发事件线索提取方法与流程
本发明属于自然语言处理技术领域,尤其涉及一种基于新闻报道的突发事件线索提取方法。
背景技术:
突发事件,是指突然发生,造成或者可能造成严重社会危害,需要采取应急处置措施予以应对的自然灾害、事故灾难、公共卫生事件和社会安全事件。为预防和减少突发事件的发生,控制、减轻和消除突发事件引起的严重社会危害,人民政府及其相关部门应规范突发事件应对活动,对可能发生的突发事件进行综合性评估,最大限度地减轻重大突发事件影响。突发事件具有明显的时序特征,其逻辑顺序可以用事件的话题演化,即突发事件线索来表示。例如,“2014年第9号威马逊台风”事件一发生,同时会出现“人员伤亡”、“农作物受灾”、“通讯中断”等事件;随着时间的推进,“威马逊登陆我国”、“气象台发布预警”、“相关部门发出通告”、“转移相关人员”、“防范病菌”等一系列相关事件。这些相关事件都是与“威马逊台风”这一主题下演化或衍生出的子事件。这些事件的发生有着时序关系或因果关系。准确完整地获取突发事件线索,对了解突发事件的前因后果对事态发展趋势的掌握有着重要的作用,同时对于如何应对类似突发事件有着一定的借鉴和预测作用。
现有技术中以词或短语为基本单位,应用主题模型以得到词语在话题上的分布。以高频主题词语集合表示子话题,以文档报道时间来表示话题的演变过程,存在如下缺点:1、以词或短语为基本单位,语义孤立,忽视了词与词之间的语义关系,因而无法完整地描述话题;词语本身无时间的概念,只能借助文档报道时间来体现话题目的时序特征。现有技术中采用的方案还有以ace事件为基本单位,识别和推理事件之间的关系,从而描述话题的演变过程,其存在以下缺点:ace事件类别共分为8大类33子类,事件领域受限,抽取准确率受限;ace事件多为粗粒度的语句或篇章级事件,部分细粒度事件无法抽取;事件关系的界定无统一结构,关系判别准确率低,实现难度较大。
因此,我们设计了一种基于新闻报道的突发事件线索提取方法。事件线索以三元组原子事件(subject,predicate,object)为基本单位,利用事件间的时序关系表示线索。采用一种改进的主题模型生成与该话题强相关的事件(即主题事件)集合,在构建的事件时序关系图上应用一种改进后的拓扑排序算法输出最终的事件线索。
技术实现要素:
针对现有技术中的上述不足,本发明提供的一种基于新闻报道的突发事件线索提取方法解决了现有技术中事件线索语义表达不强以及线索获取准确率低的问题。
为了达到以上目的,本发明采用的技术方案为:
本方案提供一种基于新闻报道的突发事件线索提取方法,包括如下步骤:
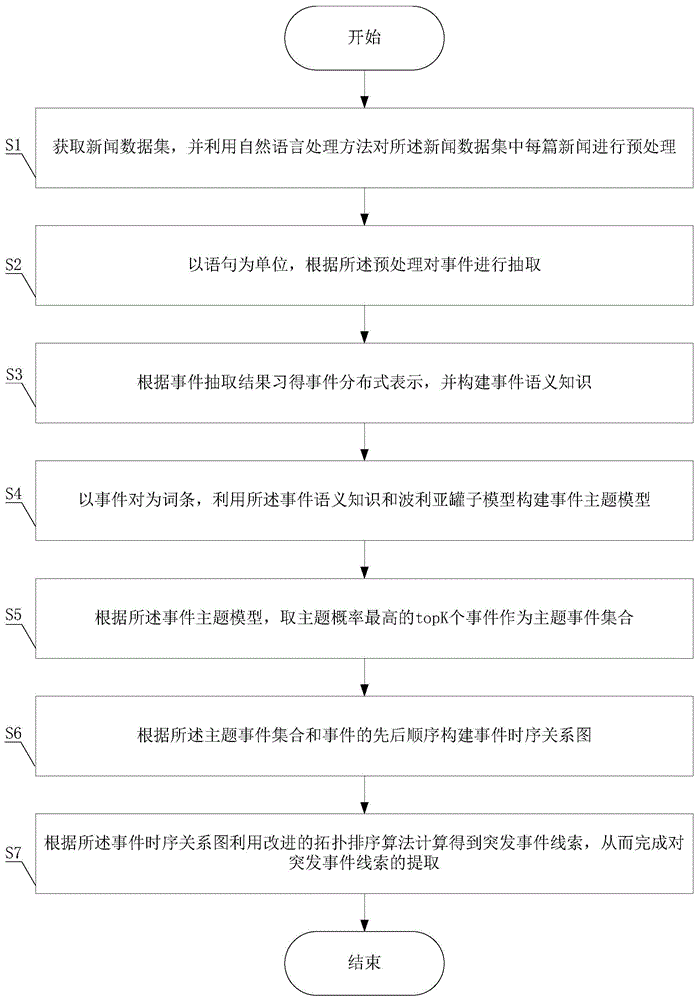
s1、获取新闻数据集,并利用自然语言处理方法对所述新闻数据集中每篇新闻进行预处理;
s2、以语句为单位,根据所述预处理结果对事件进行抽取;
s3、根据事件抽取结果得到事件分布式表示,并构建事件语义知识;
s4、以事件对为词条,利用所述事件语义知识和波利亚罐子模型构建事件主题模型;
s5、根据所述事件主题模型,取主题概率最高的topk个事件作为主题事件集合;
s6、根据所述主题事件集合和事件的先后顺序构建事件时序关系图;
s7、根据所述事件时序关系图利用改进的拓扑排序算法计算得到突发事件线索,从而完成对突发事件线索的提取。
进一步地,所述步骤s1中的预处理包括词性标、依存分析和指代消解。
再进一步地,所述步骤s2包括如下步骤:
s201、以语句为单位,并根据所述预处理结果提取事件中所有的谓语关系对;
s202、判断所述谓语关系对是否存在相同的谓语,若是,则将相同的谓语合并为一个三元组事件,并进入步骤s3,否则,将所述谓语关系对保留为二元组事件,并进入步骤s3,从而完成对事件的抽取。
再进一步地,所述步骤s3包括如下步骤:
s301、根据事件抽取结果利用word2vec算法在新闻语料上得到词向量表示;
s302、根据所述词向量表示利用组合语义算法计算得到事件分布式表示;
s303、根据所述事件分布式表示利用欧式距离算法计算得到事件间的相似度;
s304、根据所述事件间的相似度构建事件语义知识。
再进一步地,所述步骤s302中事件分布式表示包括以下任意一种情况:
第一种情况:
若事件为三元组事件,则根据事件的谓语向量以及事件的主语向量和宾语向量的克罗内外积计算得到事件分布式表示,其所述事件分布式表示
第二种情况:
若事件为二元组事件,则根据事件的谓语向量以及事件的主语或宾语的向量计算得到事件分布式表示,其所述事件分布式表示为
其中,
再进一步地,所述步骤s4包括如下步骤:
s401、以事件对为词条,设置生成事件主题的多项式分布参数
s402、设置生成文档主题的多项式公布参数θm~dir(α),其中,θm表示文档m的主题分布,dir(α)表示分布服从超参数为α的狄利克雷分布;
s403、对每篇新闻文档m中事件共现对b(ei,ej)分别采样生成主题zb~mult(θm)和采样生成事件ei~
其中,b表示文档m中出现的任一事件共现对,ei表示事件i,ej表示事件j,zb表示当前采样过程中事件共现对b的主题,mult(θm)表示服从参数为θm的多项式分布,
s404、根据所述主题采样和事件采样得到事件主题分布
再进一步地,所述步骤s6包括如下步骤:
s601、以所述主题事件集合中的每个主题事件为结点,并利用统计规则确定任意一事件对的时序关系;
s602、根据事件的先后顺序以先发生的事件为弧尾,后发生的事件为弧头,构建事件时序关系图。
再进一步地,所述步骤s601中利用统计规则确定任意一事件对的时序关系包括以下任意一种情况:
第一种情况:
若统计的两个主题事件均出现在相同文档的概率p1最大,则统计所述两个主题事件在同一文档中出现的位置先后顺序p2,且若事件ei先于事件ej,其时序关系的强度为:p=p1×p2;
第二种情况:
若统计的两个主题事件出现在不同文档的概率p3最大,则统计所述两个主题事件所在文档的报道时间的先后顺序p4,且若事件ei先于事件ej,其时序关系的强度为:p=p3×p4。
再进一步地,所述步骤s7包括如下步骤:
s701、根据所述事件时序关系图利用改进的拓扑排序算法输出事件结点序列;
s702、判断所述时序关系图中是否有未输出的事件结点,若有,则时序关系图的剩余子图中有环存在,并进入步骤s703,否则,进入步骤s704;
s703、删除所述剩余子图中的所有弧,并依次扫描已输出事件结点序列中的结点事件到剩余子图中每个未输出结点事件的弧,按时序关系的强度选择弧并输出每一个未输出结点事件,记录当前弧;
s704、由输出的事件结点序列以及所述记录的当前弧构成突发事件线索,从而完成对突发事件线索的提取。
再进一步地,所述步骤s701包括如下步骤:
s7011、根据所述事件时序关系图构建优先队列,并将时序关系图中的入度为零的结点事件作入队操作;
s7012、依次对所述优先队列中入度为零的结点事件作出队操作,输出该事件并删除以该输出事件为尾的弧;
s7013、判断是否有新的入度为零的结点事件,若是,则将该结点事件作入队操作,并记录当前删除的弧,并返回步骤s7012,否则,进入步骤s702。
本发明的有益效果:
(1)本发明以三元组事件为基本单位,其抽取算法实现简单,三元组事件在文档中出现的粒度界于词和语句之间,既能表达词与词之间的语义关系,也能避免语句中噪音词语的干扰;
(2)本发明引入事件语义知识,以主流的分布式向量表达事件语义,利用事件相似度来缓解事件稀疏性问题;
(3)本发明利用事件主题模型实现主题事件的自动聚簇,基于事件对构建主题模型,结合波利亚罐子模型并引入事件语义知识,得到事件和文档的主题分布;
(4)本发明构建事件时序关系图,在所构造的事件时序关系图中,结点代表每个主题事件,以每个事件对的时序关系为弧,利用改进的拓扑排序算法输出最终的事件线索。
附图说明
图1为本发明的方法流程图。
图2为本实施例中主题模型的结构图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
实施例
本发明提供了一种基于新闻报道的突发事件线索提取方法,采用主题模型和时序关系图算法来构建突发事件线索。在新浪网上采集专题文档(包括“今年第9号台风威马逊来袭”专题(92篇),“中国台湾客机迫降重摔起火”专题(102篇),“广东遭遇20年来最严重登革热疫情”专题(38篇),“杭州发生公交车纵火案”(54篇)等)上的实施例表明该技术实现简单有效,无监督的学习方式使得技术实施无需过多的人工干预,最终生成的事件线索以三元组事件为基本单位,采用一种改进的主题模型生成主题事件集合,在主题模型中引入事件语义知识。为以每个主题事件为结点,统计计算事件间发生的先后顺序并以此为弧,构建事件间的时序关系图,通过改进后的拓扑排序算法输出最终的事件线索,如图1所示,包括如下步骤:
s1、获取新闻数据集,并利用自然语言处理方法对所述新闻数据集中每篇新闻进行预处理,其预处理包括词性标、依存分析和指代消解;
s2、以语句为单位,根据所述预处理结果对事件进行抽取,其实现方法如下:
s201、以语句为单位,并根据所述预处理结果提取事件中所有的谓语关系对;
s202、判断所述谓语关系对是否存在相同的谓语,若是,则将相同的谓语合并为一个三元组事件,并进入步骤s3,否则,将所述谓语关系对保留为二元组事件,并进入步骤s3,从而完成对事件的抽取。
本实施例中,一条语句中可能存在多个事件,提出语句中所有可能的谓语关系对,如“nsubj”和“dobj”关系,若“nsubj”和“dobj”关系拥有相同的谓语,则合并为一个三元组事件,若依存关系无法合并,则保留为二元组事件。如给定语句“气象局发布台风预警”,存在两个依存对“nsubj(发布,气象局)”和“dobj(发布,预警)”,其谓语均为“发布”,则可合并为三元组事件“(气象局,发布,预警)”,而对于语句“飞机在公海上空失事”,则只能提取二元事件“(飞机,失事,nil)”,(“nil”表示事件论元缺失)。本发明以三元组事件为基本单位,其抽取算法实现简单,三元组事件在文档中出现的粒度界于词和语句之间,既能表达词与词之间的语义关系,也能避免语句中噪音词语的干扰。
s3、根据事件抽取结果得到事件分布式表示,并构建事件语义知识,其实现方法如下:
s301、根据事件抽取结果利用word2vec算法在新闻语料上得到词向量表示;
s302、根据所述词向量表示利用组合语义算法计算得到事件分布式表示,所述事件分布式表示包括以下任意一种情况:
第一种情况:
若事件为三元组事件,则根据事件的谓语向量以及事件的主语向量和宾语向量的克罗内外积计算得到事件分布式表示,其所述事件分布式表示
第二种情况:
若事件为二元组事件,则根据事件的谓语向量以及事件的主语或宾语的向量计算得到事件分布式表示,其所述事件分布式表示为
其中,
s303、根据所述事件分布式表示利用欧式距离算法计算得到事件间的相似度;
s304、根据所述事件间的相似度构建事件语义知识。
本实施例中,利用word2vec模型在背景语料上得到词向量表示,然后采用组合语义方式计算得到事件分布式表示,若事件为三元组,则用事件谓语向量点乘事件主语和宾语向量的克罗内克外积;若事件为二元组,则直接用谓语向量点乘论元向量(主语或宾语),在得到事件的分布式向量表示后,采用欧式距离计算事件间的相似度,以构建事件语义知识。如事件“(飞机,失事,nil)”和“(飞机,遇难,nil)”语义相似度约为0.8765。本发明引入事件语义知识,以主流的分布式向量表达事件语义,利用事件相似度来缓解事件稀疏性问题。
s4、如图2所示,以事件对为词条,利用所述事件语义知识和波利亚罐子模型构建事件主题模型,其实现方法如下:
s401、以事件对为词条,设置生成事件主题的多项式分布参数
s402、设置生成文档主题的多项式公布参数θm~dir(α),其中,θm表示文档m的主题分布,dir(α)表示分布服从超参数为α的狄利克雷分布;
s403、对每篇新闻文档m中事件共现对b(ei,ej)分别采样生成主题zb~mult(θm)和采样生成事件ei~
其中,b表示文档m中出现的任一事件共现对,ei表示事件i,ej表示事件j,zb表示当前采样过程中事件共现对b的主题,mult(θm)表示服从参数为θm的多项式分布,
s404、根据所述主题采样和事件采样得到事件主题分布
在本实施例中,因为引入了事件语义知识,使得“(人,死亡,nil)”、“(人,伤亡,nil)”、“(人,罹难,nil)”等相似事件在生成过程中被采样的概率增加,有效地解决了事件抽取后的长尾现象。
s5、根据所述事件主题模型,取主题概率最高的topk个事件作为主题事件集合。
在本实施例中,以主题“今年第9号台风威马逊来袭”为例,采用传统的以词为基本单位的主题模型,得到“台风、威马逊、登陆、沿海、广东、海南、中心、影响、暴雨、预计”等主题词(10个),而采用所述事件主题模型则可得到“(威马逊,登陆,nil)、(nil,受,影响)、(nil,损失,元)、(人,死亡,nil)、(气象台,发布,预警)、(人,受灾,nil)、(nil,启动,响应)、(通讯,中断,nil)、(nil,损坏,农房)和(农作物,受灾,nil)”等主题事件(10个)。
s6、根据所述主题事件集合和事件的先后顺序构建事件时序关系图,其实现方法如下:
s601、以所述主题事件集合中的每个主题事件为结点,并利用统计规则确定任意一事件对的时序关系,其利用统计规则确定任意一事件对的时序关系包括以下任意一种情况:
第一种情况:
若统计的两个主题事件均出现在相同文档的概率p1最大,则统计所述两个主题事件在同一文档中出现的位置先后顺序p2,且若事件ei先于事件ej,其时序关系的强度为:p=p1×p2;
第二种情况:
若统计的两个主题事件出现在不同文档的概率p3最大,则统计所述两个主题事件所在文档的报道时间的先后顺序p4,且若事件ei先于事件ej,其时序关系的强度为:p=p3×p4;
s602、根据事件的先后顺序以先发生的事件为弧尾,后发生的事件为弧头,构建事件时序关系图;
s7、根据所述事件时序关系图利用改进的拓扑排序算法计算得到突发事件线索,从而完成对突发事件线索的提取,其实现方法如下:
s701、根据所述事件时序关系图利用改进的拓扑排序算法输出事件结点序列,其实现方法如下:
s7011、根据所述事件时序关系图构建优先队列,并将时序关系图中的入度为零的结点事件作入队操作;
s7012、依次对所述优先队列中入度为零的结点事件作出队操作,输出该事件并删除以该输出事件为尾的弧;
s7013、判断是否有新的入度为零的结点事件,若是,则将该结点事件作入队操作,并记录当前删除的弧,并返回步骤s7012,否则,进入步骤s702;
s702、判断所述时序关系图中是否有未输出的事件结点,若有,则时序关系图的剩余子图中有环存在,并进入步骤s703,否则,进入步骤s704;
s703、删除所述剩余子图中的所有弧,并依次扫描已输出事件结点序列中的结点事件到剩余子图中每个未输出结点事件的弧,按时序关系的强度选择弧并输出每一个未输出结点事件,记录当前弧;
s704、由输出的事件结点序列以及所述记录的当前弧构成突发事件线索,从而完成对突发事件线索的提取。
在本实施例中,以主题“今年第9号台风威马逊来袭”为例,在构造的事件时序关系图中,“(人,死亡,nil)”,“(nil,损坏,农房)”,“(农作物,受灾,nil)”三个事件形成一个环状结构,采用传统的拓扑排序算法无法将这三个事件加入到事件线索中,采用所述的改进的拓扑排序可以直接打破环路,由于已输出事件“(威马逊,登陆,nil)”与三个事件的关系强度最大,故可直接输出此三个事件,事件线索中保留的事件时序关系为事件“(威马逊,登陆,nil)”与它们的时序关系。
与现有技术相比,本发明采用主题模型和时序关系图来构建突发事件线索。事件线索以三元组事件为基本单位,既能表达词与词之间的语义关系,也能避免语句中噪音词语的干扰;采用一种改进的主题模型生成主题事件集合,通过波利亚罐子模型和事件语义知识的引入缓解数据稀疏问题,以及有效地得到事件主题分布;构建的事件时序关系图能够直观地表达事件逻辑关系,通过改进后的拓扑排序算法能输出更为直观的事件线索,本发明通过以上设计解决了现有技术中事件线索语义表达不强以及线索获取准确率低的问题。
- 还没有人留言评论。精彩留言会获得点赞!