一种自动分析应用商店中用户评论并推荐给开发者的方法与流程
本发明属于数据挖掘技术领域,尤其是一种自动分析应用商店中用户评论并推荐给开发者的方法。
背景技术:
随着移动互联网和web2.0的繁荣发展,移动应用已经渗透到我们生活中的方方面面,我们的衣食住行都离不开移动应用。应用商店提供了大量的应用程序,应用开发者如果想保持自己的产品具有竞争力,就必须了解用户的需求和用户使用的体验以便改进应用软件。用户可以在应用商店下载、安装应用软件,同时他们也可以在应用商店提交他们对应用程序的使用反馈。
由于应用程序的开发周期相对较短,开发者可以通过用户的评论了解不同用户的不同的需求及用户在使用过程中遇到的问题,从而有针对性的对app进行更新和维护。这些反馈信息可以作为用户和开发者进行沟通的一个重要渠道。但是对于比较流行的应用程序而言,其每天会收到数万条的评论,其中有大量的信息对于开发者是没有价值的。如果这些评论全部需要人工来阅读的话,会消耗大量的人力物力。在这种情况下,如何自动地提取评论中的有效信息变得尤为重要。因此,挖掘评论中的对开发者有用的信息并将热点评论信息推荐给开发者成为软件开发中面临的一个重要问题。
经检索发现,目前现有的一些挖掘用户评论的方法是将用户评论进行分类,结合文本分析、自然语言处理等技术来实现对应用评论进行分类,或将评论分为功能性信息和非功能性信息,或将评论分为用户需求、功能缺陷、功能体验等,这些工作虽然将评论分成不同的类别,但实际都是过滤对开发者没有价值的评论,虽然这些方法能从冗余的评论中提取有效的信息,然而对于一些流行的应用来说,由于评论数较多,分类后的评论仍然是混乱的,并不能直观地为开发者提供有效的建议;另外一些工作在分类的基础上考虑时间和评论长度等因素,将评论分成不同的优先级,然而这种方法只考虑评论文本而未考虑应用商店其他的属性信息,比如评论对用户的有用数,这个指标表达了其他用户对评论的认可度,这时对用户的评论划分优先级会出现问题。
技术实现要素:
本发明的目的在于克服上述现有技术存在的不足,提供一种设计合理、准确可靠且使用方便的自动分析应用商店中用户评论并推荐给开发者的方法。
本发明解决其技术问题是采取以下技术方案实现的:
一种自动分析应用商店中用户评论并推荐给开发者的方法,包括以下步骤:
步骤1、收集用户评论数据并进行预处理;
步骤2、对用户评论进行意图分类并建立分类模型;
步骤3、对各个意图分类下的用户评论进行主题分类;
步骤4、将各个主题分类下用户评论进行句子聚类并计算聚类的中心位置;
步骤5、建立评价用户评论优先级的机制并据此计算用户评论综合得分并推荐给软件开发者。
进一步,所述步骤1采用混淆字典wordmapper对用户评论数据进行预处理。
进一步,所述步骤2首先将意图分类为和app更新与维护方面相关的如下五种类型:信息搜寻、信息给予、功能请求、问题发现和其他,然后使用bert模型对数据进行训练并得到分类模型。
进一步,所述步骤3的具体实现方法为:首先采用lda算法对评论进行主题建模,然后,取出对主题贡献率最高的前二十个词作为主题词,将其进行word2vec向量化处理,最后将这些向量进行加权求和,其权重为对主题的贡献率,进而得到每个主题的中心。
进一步,所述步骤4的具体实现方法为:首先将句子进行向量化处理,然后用dbscan聚类算法将向量化之后的句子进行聚类,将语义相似的句子聚集在一起并计算聚类中心点。
进一步,所述步骤5建立评价用户评论优先级的机制是依据如下五个方面的因素:用户意图的重要性、用户情感、用户评论时间、评论句子长度和有帮助数量。
进一步,在意图重要性的因素中,意图分类中最重要的是问题发现和功能请求,其次是信息给予和信息搜寻类别。
进一步,在用户情感的因素中,根据用户的情感变化,得到用户在使用app中的情感曲线,出现波谷的前后各一天的评论的权重设置为其他时段的2倍。
进一步,在用户评论时间的因素中,用户的评论的时间距离现在越近,推荐时占的权重越大;在评论句子长度的因素中,评论句子长度越长,推荐时占的权重越大;在有帮助数量因素中,有帮助数越多,推荐时占的权重越大。
本发明的优点和积极效果是:
本发明设计合理,其通过评论信息进行意图分类、主题分类、句子聚类并结合时序及情感分析来对评论进行处理,得到系统推荐返回的热点top-k评论,为开发者提供有参考价值的评论内容,从而对应用的开发与维护提供参考,有效地减少了开发者冗余信息的摄入,提升了用户体验,具有分析内容准确可靠、使用方便等特点。
附图说明
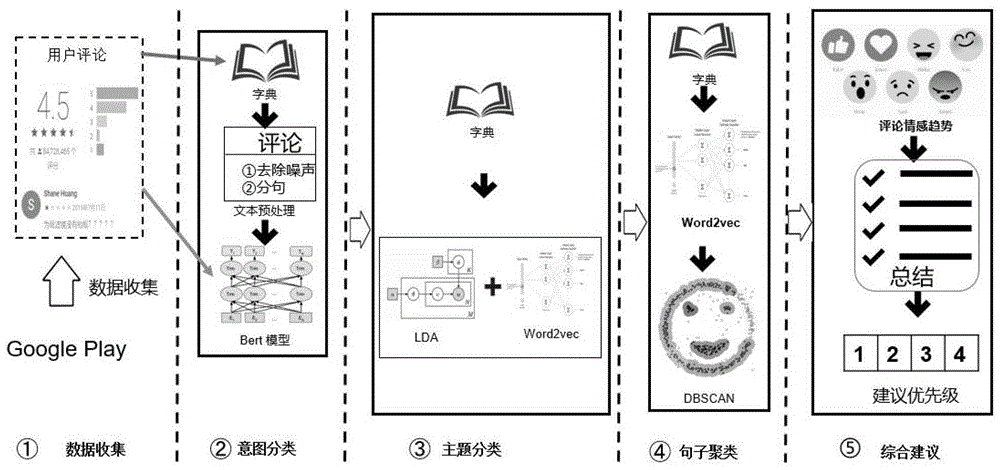
图1为本发明的总体结构图;
图2为本发明中使用的wordmapper字典的部分数据;
图3为本发明中使用的bert方法分类示意图;
图4为本发明中使用聚类后的示意图;
图5为本发明中的用户评论波动示意图。
具体实施方式
以下结合附图对本发明的实施做进一步详述。
一种自动分析应用商店中用户评论并推荐给开发者的方法,如图1所示,包括以下步骤:
步骤1、收集用户评论数据并进行预处理。
在本步骤中,由于用户通过网络提交的评论一般包含许多噪声数据,例如,拼错的单词、非英文的单词等,这些会影响对数据处理的结果,因此,需要对收集到的评论数据进行数据预处理。
在进行预处理时,创建一个混淆字典wordmapper,其中包含了在评论中常见的拼写错误的单词及其校正后的单词,利用该字典将常见的容易写错的单词进行校正。混淆字典wordmapper的部分内容如图2所示。
步骤2、对用户评论进行意图分类,分类成和app更新与维护方面相关的种类。
在本步骤中,根据用户评论的意图进行分类,在本实施例中,将评论分为信息搜寻、信息给予、功能请求、问题发现和其他五大类,然后使用bert模型对数据进行训练,得到分类模型。
步骤3、对各个意图分类下的用户评论进行主题分类,从而提高评论的内聚性。
在本步骤中,将评论分成句子粒度,将句子进行向量化表示并进行分类,如图3所示,具体方法为:首先采用lda算法对评论进行主题建模,然后,取出对主题贡献率最高的前二十个词作为主题词,将其进行word2vec向量化处理,最后将这些向量进行加权求和,其权重为对主题的贡献率,得到每个主题的中心。
进行主题分类后,当有新的句子加入时,我们通过比较该句子到哪个主题中心的距离最近,便将其划归到该主题下。
步骤4、将各个主题分类下用户评论进行句子聚类,并计算聚类的中心位置。
在本步骤中,首先将句子进行向量化处理,然后用dbscan聚类算法将向量化之后的句子进行聚类,将语义相似的句子聚集在一起并计算聚类中心点,最后计算出距离聚类中心点,最近的句子将其作为该聚类的表示。聚类结果如图4所示。
步骤5、建立评价用户评论优先级的机制并据此计算用户评论综合得分并推荐给软件开发者。
在本步骤中,需要找到一种合适方式来对挖掘得到的用户评论信息推荐给开发者。对于开发者来说,他们更希望有一种方法:(1)很容易的获取到用户评论的有用信息。(2)正确的理解需要完成的维护任务。(3)哪一个方面的内容是用户最关注的且希望修复的。
为了解决这个问题,本发明制定了一种评价用户评论优先级机制,从而为开发者推荐合理且高效的用户需求建议。建立优先级机制时,需要考虑如下五个方面的因素。
(1)用户意图的重要性:意图分类中最重要的是问题发现和功能请求,因为这更有可能是和app维护相关的内容,这对于开发者更加重要,其次是信息给予和信息搜寻类别,值得注意的是,由于开发者只关心功能性的评论,所以,意图分类中的其他类别评论我们并不考虑进行评论的优先级排序。
(2)用户情感:用户通常会及时通过评论来表达使用app的即时体验,这些评论信息可以表达用户真实的情感,比如当app出现隐私安全时,用户的情感一般为抱怨,此时表达的是负面的情绪,当app出现新功能是,用户表达的情感一般为正面的,此时的情感得分越高。情感得分越高或者越低(即情感出现波峰或者波谷时),此时更能反映用户的真实意图,如图5所示。我们根据用户的情感变化,得到用户在使用app中的情感曲线,当用户的评论在波谷(即负面情绪集中)时,我们认为此时用户所提出的反馈应该更加具有重要性,我们将出现波谷的前后各一天的评论的权重设置为其他时段的2倍。
(3)用户评论时间:用户的评论的时间距离现在越近,对开发者重要性越大。
(4)评论句子长度:评论句子长度越长,通常越能表达用户的意图信息。
(5)有帮助数量:有帮助数越多,说明越多用户认可该评论观点,推荐时占的权重越大。
最后,计算每个聚类的综合得分,根据最后的得分高低进行排序,得到top-k个热点评论并将top-k评论推荐给开发者。
本发明未述及之处适用于现有技术。
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!