一种实现资源高效利用的集群极速弹性伸缩方法与流程
本发明涉及一种集群极速弹性伸缩方法,更具体的说,尤其涉及一种实现资源高效利用的集群极速弹性伸缩方法,属于大数据、云计算平台技术领域。
背景技术:
目前,无论是基于资源阈值的,还是基于自定义指标的kubernetes容器集群自动伸缩方法,都需要面临解决快速弹出节点和避免集群震荡的矛盾。由于集群新建节点耗费时间较长,因此在及时响应伸缩的效率上并不能很好满足现实需求。为此,本专利提出了基于“智能伸缩补偿”过程的智能伸缩补偿技术,可以有效缩短新建节点加入集群提供服务时间,加快伸缩响应速度,来保证服务的质量。
另外,在自动伸缩弹出节点的调度放置问题上,因现有调度策略仅支持资源需求的特征维度,在宏观应用的行为特征维度上支撑不足。本专利综合考虑两个方面,提出“混合调度软切分”过程,可以实现对资源的充分利用,从而实现成本的最小化。
技术实现要素:
本发明为了克服上述技术问题的缺点,提供了一种实现资源高效利用的集群极速弹性伸缩方法。
本发明的实现资源高效利用的集群极速弹性伸缩方法,包括智能伸缩补偿过程和混合调度软切分过程;其特征在于,所述智能伸缩补偿过程通过以下步骤来实现:
步骤1:服务集群在kubernetes中创建自定义资源的智能弹性伸缩补偿模块iacm,并在智能弹性伸缩补偿模块iacm中定义一个补偿队列,补偿队列由iacm部署在每个节点上的线程daemonset维护;
步骤2:判断服务集群在未来一段时间是否需要增加节点,如果需要增加节点则创建pod,执行步骤3);如果不需要增加节点则进入下一个预测周期;pod为共享了名称空间和网络空间的容器的集合体,是集群调度的基本单位;
步骤3:把步骤2)中由预测算法预测产生的pod资源,加入到补偿队列中,执行步骤4);
步骤4:设置补偿队列的优先级,执行步骤5;
步骤5:当补偿队列长度超过设定阈值时,定期对补偿队列中pod资源执行清理回收操作,执行步骤6;
步骤6:维护pod资源的入补偿队列、出补偿队列以及从补偿队列中清理pod资源的操作,执行步骤7;
步骤7:周期性执行步骤2的判断过程。
本发明的实现资源高效利用的集群极速弹性伸缩方法,步骤2中所述的预测算法逻辑通过以下步骤来实现:
步骤2-1:对实时监控数据和历史负载数据进行拟合,判断伸缩需求,当未来需要增加节点时,新建pod资源并加入到补偿队列中,当未来无需增加节点时,则不执行新建pod资源操作;
步骤2-2:判断是否存在需要回收的pod资源,然后执行预测算法,如果算法预测未来一段时间内需要pod资源,则将需要回收的pod资源加入到补偿队列中,如果未来一段时间内需要pod资源,则将需要回收的pod资源抛弃;
步骤2-3:分析用户提交的未来一段时间pod资源需求,根据用户提交的需求新建pod资源并加入至补偿队列。
本发明的实现资源高效利用的集群极速弹性伸缩方法,步骤4中补偿队列的优先级通过以下步骤来求取:
步骤4-1:根据公式(1)求取补偿队列中pod资源的优先级:
pn=w0*fn+w1*p0+w2*cn(1)
其中,pn表示新入队列pod资源的优先级,w0、w1、w2表示权重配比,fn为拟合因子,其值代表拟合程度大小,表征未来被调度的可能性大小;p0表示服务预设置优先级,cn表示信用因子;0<w0,w1,w2<1,w0+w1+w2=1;
步骤4-2:利用公式(2)计算公式(1)中的拟合因子fn:
其中,s表示服务集群,i表示历史上集群共有i次新增pod事件,i′表示服务集群中pod资源出队列总数,oem表示第m次出补偿队列的pod资源,iem表示第m次入补偿队列的pod;fi+1表示新增pod资源的拟合因子,其根据属于同一服务集群的pod资源历史上出补偿队列和入补偿队列的比值来判定;
步骤4-3:公式(1)中信用因子cn通过以下步骤来实现:
步骤4-3-1:获取历史资源配额使用率,设服务集群历史上共有i次新增pod资源,在pod中参与计算的共有n类资源,服务集群历史上i次新增pod资源内各资源配额使用率分别表示为u1(t1,d1),...,um(tm,dm),...,ui(ti,di),其中:
um(tm,dm)=(um,1(tm,dm),...,um,k(tm,dm),...,um,n(tm,dm))
um(tm,dm)表示第m次新增pod的资源利用率,um,k(tm,dm)表示第m次新增pod内的第k类资源的资源配额使用率,k=1,2,...,n;tm表示pod开始提供服务时间,dm表示pod提供服务时长;
步骤4-3-2:计算权重;首先通过公式(3)计算新增pod内每个资源配额使用率um,k(tm,dm)所占的权重wm,k:
wm,k为新增pod内各资源配额使用率um,k(tm,dm)所占的权重,α是对dm的影响因子,0<α<1,d的大小等于周期性动态调整资源配额的周期时间t,m=1,2,...,i;
则第m次新增pod内各资源配额使用率所占权重表示为:
wm=(wm,1,...,wm,k,...,wm,m)
步骤4-3-3:计算pod所在集群的信用c;对于pod内的各类资源,同一服务集群历史上i次新增pod后,通过公式(4)计算每次新增pod资源的信用因子;
对于所有资源类型,应用i次资源配额后,第i+1次为用户分配新的资源配额时,服务集群的信用因子c:
所以第i+1次新增资源pod的信用因子cn=ci+1=c。
本发明的实现资源高效利用的集群极速弹性伸缩方法,所述的混合调度软切分过程具体通过如下步骤来实现:
a).对于智能伸缩补偿过程所建立的pod资源,将其分为在线任务资源和离线任务资源,在线任务资源比例rx、离线任务资源比例ry通过公式(6)进行求取:
其中,x,y为中间变量,其通过公式(7)进行求取:
α1、α2...αn表示在线任务的权重,α1′、α2′...αn′表示离线任务的权重,资源类型的种类共有n类,k1、k2、...、kn表示n类资源类型,αi+αi′=1,αi与αi′的比重由在线和离线任务的各类资源分别求和的比值来确定,i=1,2,...n;
b).当在线任务资源使用剩余率小于等于10%时或者任务出队速率缓慢低于设定阈值时,即判断为资源紧张,需要调节资源;如果需要调节资源,则执行步骤c),如果无需调节资源,则执行步骤f);
c).判断离线任务服务优先级py>p0是否成立,如果成立,则表示不可驱逐离线任务,执行步骤d);如果不成立,表示可驱逐离线任务,以释放资源,执行步骤i);p0为离线任务的驱逐阈值;
设在线和离线任务新的资源比例变量分别为r′x、r′y,r′x+r′y=1;则:
r′x=λ+rx(8)
rx=r′x,ry=r′y(9)
其中,λ为资源调节因子;
其中,k1′、k2′、...、kn′为离线任务新释放后的资源;
d).判断在线任务分配资源的利用率是否大于或等于100%,如果为是,则执行步骤e);如果为否,则执行步骤f);
e).判断在线任务是否只能调度到当前节点,如果为是,则执行步骤i);如果为否,则执行步骤h);
f).判断离线任务资源剩余率是否低于10%,如果为是,侵占在线任务资源但最多不超过总资源的50%,执行步骤j);如果为否,执行步骤k);
g).侵占在线任务资源,但最多不超过在线任务总资源的50%,判断侵占在线任务是否成功,如果成功,则执行步骤j);如果不成功,执行步骤k);
h).调度到其它节点或新增节点,执行步骤a);如果调度失败,执行步骤i);
i).根据离线任务优先级,强制驱除离线任务中低优先级的任务,执行步骤j);
j).根据资源配比r′x、r′y动态调节系统资源,执行步骤k);
k).资源满足需求,循环结束,否则,按照周期t,循环执行步骤b)至步骤j)。
本发明的实现资源高效利用的集群极速弹性伸缩方法,步骤c)中,在线任务优先级px、离线任务优先级py通过公式(11)进行求取:
其中,ω0、ω1表示权值,ω0+ω1+ξ=1,ω0+ω1+ξ′=1;ps为任务系统优先级,rt表示任务运行时间,et表示任务截止时间,ξ、ξ′为时段影响因子。
本发明的实现资源高效利用的集群极速弹性伸缩方法,步骤b)中所述的任务出队速率缓慢低于设定阈值用任务等待周期来表征,当任务等待周期超过阈值t0时,即判断为资源记账,需要调节资源。
本发明的实现资源高效利用的集群极速弹性伸缩方法,在触发动态资源扩容时,不直接采取新起pod资源的方式,而是先遍历补偿队列,查看是否有预准备的pod资源,如果有,则直接拉起,如果没有,则执行智能伸缩补偿过程;在触发动态缩容时,缩容后的pod,在冷却周期后不直接杀死,而是放入补偿队列中等候,再由智能补偿过程进行销毁;可以看到因智能伸缩补偿过程的加入,原冷却周期可以适当缩短,由此来实现更加快速且细粒度的动态伸缩方案。
本发明的有益效果是:本发明的集群极速弹性伸缩方法,在智能伸缩补偿过程中,根据根据历史负载和实时负载信息,来预测服务未来一段时间的资源需求,预创建pod资源并加入到补偿队列中,由于服务集群在资源需求增加时,所需要的新的副本已经存在“补偿队列”中,直接拉起就可以加入集群,节省了从零创建新副本所耗费的准备时间,实现了更加极致、快速的扩展集群节点资源的目标。在混合调度软切分过程中,首先将业务划分为在线、离线任务类型,并计算离线、在线任务的优先级,当资源满足不了需求时,首先能对资源池大小进行调节,当资源池资源匮乏时,进行资源调节,对资源占比较大致无法调节,而优先级较低,可进行驱逐或杀死任务,以实现资源调度和资源伸缩。
附图说明
图1为现有集群伸缩方法的架构体系原理图;
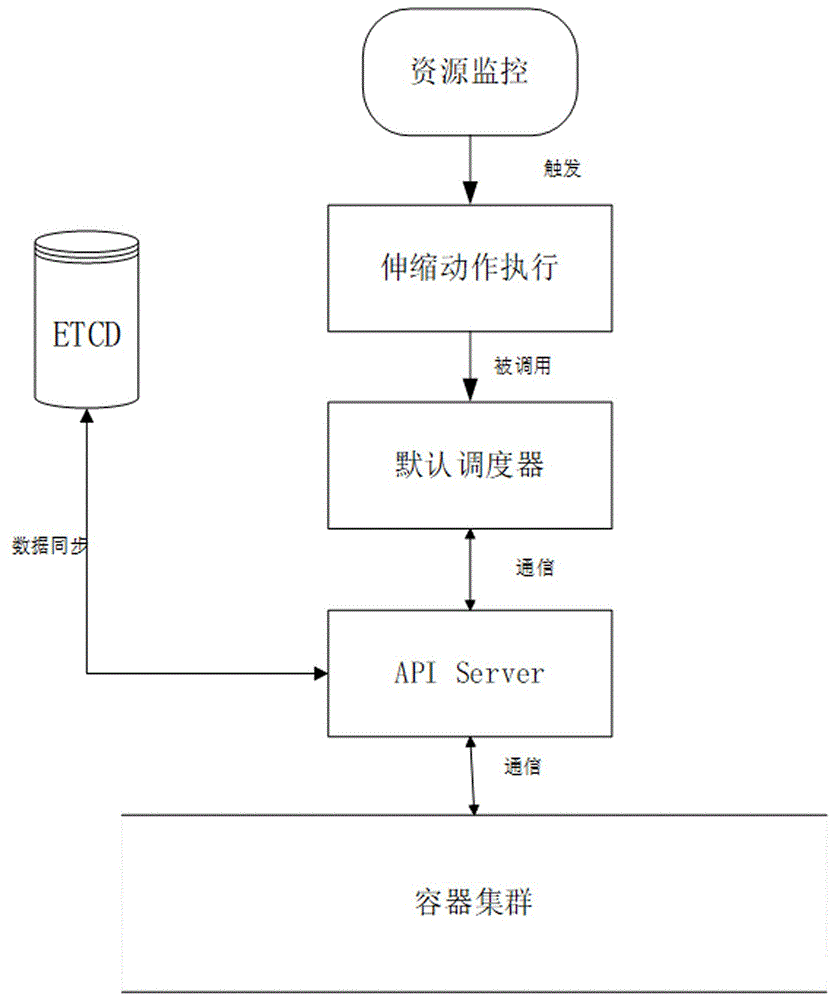
图2为本发明的集群极速弹性伸缩方法的架构体系原理图;
图3为本发明中混合调度软切分过程的流程图。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
若大致将自动伸缩架构体系分为指标获取、伸缩组件和资源调度三个部分,如图1所示,给出了现有集群伸缩方法的原理图。“智能伸缩补偿”和“混合调度软切分”过程的添加,构成了新的调度架构体系,如图2所示,给出了本发明的集群极速弹性伸缩方法的架构体系原理图,该体系构成了更加完善的自动伸缩流程,提高了伸缩节点的效率及服务的质量;并充分利用了集群资源,节约了成本。
“智能伸缩补偿过程”主要有“补偿队列”和“控制逻辑”两部分组成。其中,控制逻辑中添加了预测算法分析逻辑,该算法逻辑根据历史负载和实时负载信息,来预测服务未来一段时间的资源需求,预创建资源并加入到“补偿队列”中。因“智能伸缩”过程具有单独的控制逻辑和生命周期,本专利将它设计成控制器模式,并由kubernetes的控制管理器(controllermanager)负责管理和维护。
其中,“控制逻辑”部分的预测算法模型可根据预测所需数据的特性来建立,数据特性主要包括:时间及服务相关性、波动性、突发性(离散点)。依据这类数据特性,并结合集群的特点和应用的服务目标,来建立预测算法、自建算法或组合算法;然后对算法进行实验,最终确定出最优算法。目前效果比较好的算法有,灰度预测、指数平滑、bp神经网络和回归、自回归算法。
“智能伸缩补偿过程”面向的服务集群和主要逻辑如下所述:该算法面向的服务是由副本控制策略创建和维护的一类无状态应用集群,该算法的主要逻辑的设计依据的是队列的生命周期变化的过程,该过程主要包括入队、出队和清理队列动作。其中,入队动作执行入队的是pod(pod可以看成共享了名称空间和网络空间等的容器的集合体,是集群调度的基本单位。)资源,它是由预测算法预测并由副本控制策略创建产生。预测算法会预测服务集群在未来一段时间内资源需求量的变化情况,如果集群需要增加pod时,则新建pod资源并执行资源入队的动作。出队列:当集群需求在预测的有效时间段内,即预测产生的该集群的pod在队列中还未被清理,需要增加集群规模时;遍历队列资源,执行出队动作。清理对列:当内存资源紧张需要回收资源时或者在一个周期结束后,将队列按优先级顺序来执行清理动作。
该模算法的约束在于:它所面向的服务集群是由副本控制器控制产生的一类无状态应用集群,集群里的pod来源于同一个部署模板,并对外提供相同的服务类型;另外,对每次预测面向的无状态应用服务集群所产生的新副本约束是:一次只能创建一个并加入队列,只有当该副本被调度后或者被清理后,才能再根据预测算法执行新资源的创建和入队操作。
该算法的优势在于:由于服务集群在资源需求增加时,所需要的新的副本已经存在“补偿队列”中,直接拉起就可以加入集群,节省了从零创建新副本所耗费的准备时间,实现了更加极致、快速的扩展集群节点资源的目标。劣势在于:队列里的pod资源会消耗内存资源。其中,优势部分节省的时间存在于pod的生命周期中,如果集群资源充分且运行状态良好,则新创建副本所耗费的时间大部分存在于挂起状态中,该状态的下载镜像及准备pod的基础环境等活动耗费时间较长,该状态占整个pod生命周期中比重很大。这方法设计是以牺牲空间为代价来换取时间上的增益效果。另外,加入队列的pod状态要求是:基础环境已准备好并处于未绑定节点调度的状态,其中基础环境准备包括:基础的隔离环境、文件系统、网络、存储、容器镜像下载。由于副本控制器需要维护和控制集群节点的数量,而加入到“补偿队列”中的pod是由同一服务集群下的副本控制器产生的,资源已准备就绪却未投入使用,所以该状态的pod资源,可以在资源清单的字段中为补偿队列的pod设置特殊标志和现有状态加以区分,以方便kubernetes进行统一管理。综上所述,在集群规模需要扩展时,若能将队列中的pod直接拉起运行,将节省大量的时间。
智能伸缩补偿过程通过以下步骤来实现:
步骤1:服务集群在kubernetes中创建自定义资源的智能弹性伸缩补偿模块iacm,并在智能弹性伸缩补偿模块iacm中定义一个补偿队列,补偿队列由iacm部署在每个节点上的线程daemonset维护;
步骤2:判断服务集群在未来一段时间是否需要增加节点,如果需要增加节点则创建pod,执行步骤3);如果不需要增加节点则进入下一个预测周期;pod为共享了名称空间和网络空间的容器的集合体,是集群调度的基本单位;
步骤3:把步骤2)中由预测算法预测产生的pod资源,加入到补偿队列中,执行步骤4);
步骤4:设置补偿队列的优先级,执行步骤5;
步骤5:当补偿队列长度超过设定阈值时,定期对补偿队列中pod资源执行清理回收操作,执行步骤6;
步骤6:维护pod资源的入补偿队列、出补偿队列以及从补偿队列中清理pod资源的操作,执行步骤7;
步骤7:周期性执行步骤2的判断过程。
步骤2中所述的预测算法逻辑通过以下步骤来实现:
步骤2-1:对实时监控数据和历史负载数据进行拟合,判断伸缩需求,当未来需要增加节点时,新建pod资源并加入到补偿队列中,当未来无需增加节点时,则不执行新建pod资源操作;
步骤2-2:判断是否存在需要回收的pod资源,然后执行预测算法,如果算法预测未来一段时间内需要pod资源,则将需要回收的pod资源加入到补偿队列中,如果未来一段时间内需要pod资源,则将需要回收的pod资源抛弃;
步骤2-3:分析用户提交的未来一段时间pod资源需求,根据用户提交的需求新建pod资源并加入至补偿队列。
步骤4中补偿队列的优先级通过以下步骤来求取:
步骤4-1:根据公式(1)求取补偿队列中pod资源的优先级:
pn=w0*fn+w1*p0+w2*cn(1)
其中,pn表示新入队列pod资源的优先级,w0、w1、w2表示权重配比,fn为拟合因子,其值代表拟合程度大小,表征未来被调度的可能性大小;p0表示服务预设置优先级,cn表示信用因子;0<w0,w1,w2<1,w0+w1+w2=1;
步骤4-2:利用公式(2)计算公式(1)中的拟合因子fn:
其中,s表示服务集群,i表示历史上集群共有i次新增pod事件,i′表示服务集群中pod资源出队列总数,oem表示第m次出补偿队列的pod资源,iem表示第m次入补偿队列的pod;fi+1表示新增pod资源的拟合因子,其根据属于同一服务集群的pod资源历史上出补偿队列和入补偿队列的比值来判定;
步骤4-3:公式(1)中信用因子cn通过以下步骤来实现:
步骤4-3-1:获取历史资源配额使用率,设服务集群历史上共有i次新增pod资源,在pod中参与计算的共有n类资源,服务集群历史上i次新增pod资源内各资源配额使用率分别表示为u1(t1,d1),...,um(tm,dm),...,ui(ti,di),其中:
um(tm,dm)=(um,1(tm,dm),...,um,k(tm,dm),...,um,n(tm,dm))
um(tm,dm)表示第m次新增pod的资源利用率,um,k(tm,dm)表示第m次新增pod内的第k类资源的资源配额使用率,k=1,2,...,n;tm表示pod开始提供服务时间,dm表示pod提供服务时长;
步骤4-3-2:计算权重;首先通过公式(3)计算新增pod内每个资源配额使用率um,k(tm,dm)所占的权重wm,k:
wm,k为新增pod内各资源配额使用率um,k(tm,dm)所占的权重,α是对dm的影响因子,0<α<1,d的大小等于周期性动态调整资源配额的周期时间t,m=1,2,...,i;
则第m次新增pod内各资源配额使用率所占权重表示为:
wm=(wm,1,...,wm,k,...,wm,m)
步骤4-3-3:计算pod所在集群的信用c;对于pod内的各类资源,同一服务集群历史上i次新增pod后,通过公式(4)计算每次新增pod资源的信用因子;
对于所有资源类型,应用i次资源配额后,第i+1次为用户分配新的资源配额时,服务集群的信用因子c:
所以第i+1次新增资源pod的信用因子cn=ci+1=c。
混合调度软切分过程中,背景:kubernetes上的基本调度单位是pod,像在模型训练的场景下的参数服务集群和训练集群所需资源需要一次分配完成,如果只分配了部分资源或者是部分资源被调度成功,而资源又被其它集群占用,结果就是集群启动不完全或者完全启动不起来。所以很多开源项目提出了成组调度方案(例如:volcano),但是大块资源分配困难的问题难以解决。由此本专利提出的“混合调度软切分”过程可以针对性的解决这个问题,它的基本思想是将资源池进行划分,以pod为调度粒度的在线业务和批量作业离线任务分开放置,当批量作业有独立的资源空间的话,就会减少因小作业抢占资源而一直得不到调度的问题。当批量处理的作业释放资源时,也是整块释放,再度利用起来也会比较容易分配到资源。
另外,该模块的设计还可以对资源池进行动态分配,即当资源需求变化时对资源划分水位线进行调节。这也正是“软切分”思想的体现。定义:其中应用宏观的特征行为维度,主要包括:差异性、时段性和基本可规划性等方面。差异性主要体现在不同应用类型对pod等容器抽闲资源的需求上、时间的敏感度上和成本规划上等差异较明显;时段性主要体现在不同时段应用具有不同的表现行为;基本可规划性体现在不可预知的应用负载急性超过容量规划的所超出的部分之外,人为提前协定的部分。
如图3所示,给出了混合调度软切分过程的流程图,混合调度软切分过程具体通过如下步骤来实现:
a).对于智能伸缩补偿过程所建立的pod资源,将其分为在线任务资源和离线任务资源,在线任务资源比例rx、离线任务资源比例ry通过公式(6)进行求取:
其中,x,y为中间变量,其通过公式(7)进行求取:
α1、α2...αn表示在线任务的权重,α1′、α2′...αn′表示离线任务的权重,资源类型的种类共有n类,k1、k2、...、kn表示n类资源类型,αi+αi′=1,αi与αi′的比重由在线和离线任务的各类资源分别求和的比值来确定,i=1,2,...n;
b).当在线任务资源使用剩余率小于等于10%时或者任务出队速率缓慢低于设定阈值时,即判断为资源紧张,需要调节资源;如果需要调节资源,则执行步骤c),如果无需调节资源,则执行步骤f);
c).判断离线任务服务优先级py>p0是否成立,如果成立,则表示不可驱逐离线任务,执行步骤d);如果不成立,表示可驱逐离线任务,以释放资源,执行步骤i);p0为离线任务的驱逐阈值;
设在线和离线任务新的资源比例变量分别为r′x、r′y,r′x+r′y=1;则:
rx′=λ+rx(8)
rx=r′x,ry=r′y(9)
其中,λ为资源调节因子;
其中,k1′、k2′、...、kn′为离线任务新释放后的资源;
d).判断在线任务分配资源的利用率是否大于或等于100%,如果为是,则执行步骤e);如果为否,则执行步骤f);
e).判断在线任务是否只能调度到当前节点,如果为是,则执行步骤i);如果为否,则执行步骤h);
f).判断离线任务资源剩余率是否低于10%,如果为是,侵占在线任务资源但最多不超过总资源的50%,执行步骤j);如果为否,执行步骤k);
g).侵占在线任务资源,但最多不超过在线任务总资源的50%,判断侵占在线任务是否成功,如果成功,则执行步骤j);如果不成功,执行步骤k);
h).调度到其它节点或新增节点,执行步骤a);如果调度失败,执行步骤i);
i).根据离线任务优先级,强制驱除离线任务中低优先级的任务,执行步骤j);
j).根据资源配比r′x、r′y动态调节系统资源,执行步骤k);
k).资源满足需求,循环结束,否则,按照周期t,循环执行步骤b)至步骤j)。
步骤c)中,在线任务优先级px、离线任务优先级py通过公式(11)进行求取:
其中,ω0、ω1表示权值,ω0+ω1+ξ=1,ω0+ω1+ξ′=1;ps为任务系统优先级,rt表示任务运行时间,et表示任务截止时间,ξ、ξ′为时段影响因子。
步骤b)中所述的任务出队速率缓慢低于设定阈值用任务等待周期来表征,当任务等待周期超过阈值t0时,即判断为资源记账,需要调节资源。
在触发动态扩容时,并不直接采取新起pod的方式,而是先遍历“智能伸缩补偿”过程的“补偿队列”,查看是否有预准备的pod资源。有,则直接拉起;无,则执行原有的伸缩策略。在触发动态缩容是,缩容后的pod,在冷却周期后也并不直接杀死,而是放入“补偿队列”中等候一定的周期,再由智能补偿模块调用相应组件销毁。可以看到因智能伸缩补偿模块的加入,原冷却周期可以适当缩短,由此来实现更加快速且细粒度的动态伸缩方案。
- 还没有人留言评论。精彩留言会获得点赞!