一种基于K-means++聚类算法的多扩展目标跟踪方法与流程
本发明涉及扩展目标跟踪技术领域,具体的说是一种基于k-means++聚类算法的多扩展目标跟踪方法。
背景技术:
多目标跟踪需要使用传感器的量测数据持续地对多个动态目标的状态和目标个数进行估计,估计的准确度直接影响到多目标跟踪的效果。近年来,随着高分辨率传感器的飞速发展以及战争环境的复杂多变性,人们在贴近实际跟踪场景的扩展目标(当目标较大或者目标距离高分辨率传感器较近时,目标至少产生一个量测)理论下完成多扩展目标跟踪的需求越来越多,尤其是在概率假设密度滤波器(probabilityhypothesisdensity,phd)框架下基于量测集划分的多扩展目标跟踪方法是该领域的一个重要研究方向。
传统的多目标跟踪算法是把目标建模为点目标(每一时刻单个目标最多只能一个量测),利用数据关联将量测数据分配给某个目标,难以应对目标个数未知、杂波密集等环境,且往往会由于复杂数据关联问题而导致“组合爆炸”和np-hard问题。对于多扩展目标,这个问题尤为突出。近年来,在众多研究算法之中,随机有限集(randomfiniteset,rfs)备受瞩目,该方法不仅能避免量测和目标之间的数据关联,而且对多目标跟踪中的目标出现、分裂、消失以及传感器漏检和虚警杂波的存在等现象进行了严格的数学描述。多目标贝叶斯滤波器基于随机有限集合统计理论递推得到多目标后验概率密度,但计算复杂度随着目标数增加急剧增长直至无法实现,仅适用于目标或量测个数较少情况。概率假设密度(phd)滤波器实时地迭代更新后验概率强度,具有计算量低、估计精度高、易于实现等优势,但只适用于点目标。由于扩展目标不同于传统点目标,扩展目标还需要对其空间扩展进行建模,通过模拟测量值的产生过程来定性地描述目标状态与测量值之间的关系,故而无法直接使用上述基于随机有限集的多目标跟踪算法。综上所述,标准的概率假设密度滤波器不再满足多扩展目标的跟踪需求。
概率假设密度(phd)是后验概率密度的一阶矩,也称为定义在单目标状态空间上的强度函数,不需要数据关联,降低计算量的同时得到精确的目标状态和目标数估计。最近,基于phd滤波器的多扩展目标跟踪算法逐渐成为研究热点,扩展目标phd滤波器(extendedtargetphdfilter,et-phd),扩展目标cphd滤波器(extendedtargetcardinalizedphdfilter,et-cphd),扩展目标高斯混合phd滤波器(extendedtargetgaussianmixturephdfilter,et-gm-phd)等滤波器被广泛应用于多扩展目标跟踪中。上述滤波器假定测量个数服从泊松分布且测量分布在目标周围,每一时刻的测量是一组点,而不是几何结构的整体。但是,在随机有限集框架下,多扩展目标滤波方法的性能受到了量测集划分、量测建模等诸多因素的制约,其中量测集划分的准确性将直接影响后续估计目标状态和个数的精确性。传统量测集划分考虑所有可能的划分,但计算量随量测个数呈指数增长。距离划分虽然减小了计算负担,但是在目标距离相近环境下目标数估计不准确,且其多扩展目标跟踪过程仍然耗时。基于k-means聚类算法的量测集划分方法受初始中心点选择的随机性影响,导致量测集划分不稳定,目标数估计存在较大误差。k-means聚类算法改良后的k-means++聚类算法虽然提高了量测集划分的稳定性,但是效果不够理想,且相较于距离划分,其目标状态和个数估计精度不高,也存在目标相近时量测集划分不准确的问题。
目前需要本领域技术人员迫切解决的一个技术问题是:如何在多扩展目标跟踪算法中提高k-means++聚类算法的稳定性以及目标距离相近环境下的目标状态和个数估计精度。
技术实现要素:
为了解决现有技术中的不足,本发明提供一种基于k-means++聚类算法的多扩展目标跟踪方法,在保证跟踪效果的同时提高了运行速度。
为了实现上述目的,本发明采用的具体方案为:一种基于k-means++聚类算法的多扩展目标跟踪方法,包括如下步骤:
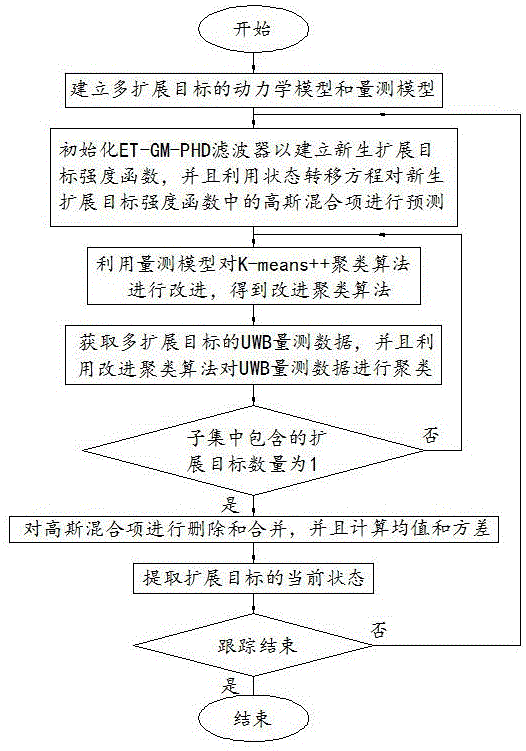
s1、建立多扩展目标的动力学模型和量测模型,其中动力学模型描述为状态转移方程,量测模型描述为线性高斯模型;
s2、初始化et-gm-phd滤波器以建立新生扩展目标强度函数,并且利用状态转移方程对新生扩展目标强度函数中的高斯混合项进行预测;
s3、利用量测模型对k-means++聚类算法进行初次改进,得到改进聚类算法;
s4、获取多扩展目标的uwb量测数据,并且利用改进聚类算法对uwb量测数据进行聚类,若聚类得到的子集中包含的扩展目标数量不为1则再次对改进聚类算法进行改进;
s5、根据聚类的结果对预测的高斯混合项进行更新和计算;
s6、对高斯混合项进行删除或者合并,并且计算均值和方差;
s7、状态提取,并且返回s2。
作为一种优选方案,s1中,状态转移方程为:
其中
线性高斯模型为:
其中
作为一种优选方案,s2中,初始化et-gm-phd滤波器过程中初始化初始状态协方差p0、过程噪声的协方差矩阵qk和量测噪声协方差矩阵rk,强度函数为
其中dk|k-1(x)为预测强度函数,jk|k-1为预测强度函数的高斯混合项个数,
作为一种优选方案,s3中初次改进的具体方法为:
s3.1、限制k-means++聚类算法中k值的取值范围为jk-1≤k≤jk-1+jbeta,k×jk-1+jgam,k,其中,jk-1是k-1时刻得到的目标数估计值,jbeta,k表示单个目标可能衍生的目标个数,jgam,k表示k时刻可能的新生目标个数;
s3.2、选择距离每个预测状态
作为一种优选方案,s4中检测和判断子集中包含的扩展目标数量是否为1的方法为:
s4.11、计算利用预测状态进行初次划分后的各子集中目标数的最大似然估计
其中
s4.12、根据各子集中目标数最大似然估计值判断是否为1。
作为一种优选方案,s4中若聚类得到的子集中包含的扩展目标数量不为1则再次对改进聚类算法进行改进的方法为:
s4.21、计算每个量测与预测状态之间的距离,并按从小到大排序,选取排序中间3位对应的量测并从中随机选择一个作为第一个初始中心点c1,该点与预测状态之间的距离记为th;
s4.22、计算剩余量测与第一个初始中心点c1之间的距离,在上述距离中选取距离1.6倍th最近的距离对应的量测作为第二个初始中心点c2;
s4.23、将上述中心点合并到初始中心点集合c;
s4.24、计算每个量测到初始中心点集合c内每个初始中心点ci的距离,依据最小距离对量测集进行划分;
s4.25、重新计算每个聚类的均值并作为中心点
s4.26、重复s4.24至s4.25直到中心点不变。
作为一种优选方案,s5的具体方法为:
s5.1、对传感器检测到扩展目标时的高斯混合项的权重进行更新
γ(j)=e-γ(γ)|w|;
其中dk|k(x)为后验强度函数,
s5.2、基于卡尔曼公式对传感器检测到扩展目标时的均值和方差进行更新
其中表示
s5.3、采用如下公式进行计算
其中p∠zk表示对量测集合zk进行的p次划分,w∈p表示每个划分中的子集单元w。
作为一种优选方案,s6的具体方法为:
s6.1、保留权重大于删除门限ηt的高斯混合项,将余下高斯混合项下标集合τk中距离小于ηm的高斯混合项合并;
s6.2、计算合并后的均值和方差
其中
作为一种优选方案,s7的具体方法为:
s7.1、进行状态提取
xk=[xk,mk];
s7.2、将更新后的高斯混合项作为下次递归的初始值,在滤波器中进行循环更新。
有益效果:本发明与基于距离划分的多扩展目标跟踪算法相比是合理限制了k值的取值范围,从而具有更快的运行速度,并且实现了与距离划分的方法相似的跟踪效果。
附图说明
图1是本发明的流程图;
图2是仿真实验中本发明的跟踪结果中多扩展目标的轨迹估计图;
图3是仿真实验中本发明的跟踪结果中多扩展目标的数量估计图;
图4是仿真实验中本发明与现有方法的目标个数跟踪结果对比图;
图5是仿真实验中本发明与现有方法的ospa误差对比图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,一种基于k-means++聚类算法的多扩展目标跟踪方法,包括s1至s7。
s1、建立多扩展目标的动力学模型和量测模型,其中动力学模型描述为状态转移方程,量测模型描述为线性高斯模型。
状态转移方程为:
其中
线性高斯模型为:
其中
s2、初始化et-gm-phd滤波器以建立新生扩展目标强度函数,并且利用状态转移方程对新生扩展目标强度函数中的高斯混合项进行预测。s2中,初始化et-gm-phd滤波器过程中初始化初始状态协方差p0、过程噪声的协方差矩阵qk和量测噪声协方差矩阵rk,强度函数为
其中dk|k-1(x)为预测强度函数,jk|k-1为预测强度函数的高斯混合项个数,
s3、利用量测模型对k-means++聚类算法进行初次改进,得到改进聚类算法,具体方法为s3.1至s3.2。
s3.1、限制k-means++聚类算法中k值的取值范围为jk-1≤k≤jk-1+jbeta,k×jk-1+jgam,k,其中,jk-1是k-1时刻得到的目标数估计值,jbeta,k表示单个目标可能衍生的目标个数,jgam,k表示k时刻可能的新生目标个数。
s3.2、选择距离每个预测状态
s4、获取多扩展目标的uwb量测数据,并且利用改进聚类算法对uwb量测数据进行聚类,若聚类得到的子集中包含的扩展目标数量不为1则再次对改进聚类算法进行改进。
检测和判断子集中包含的扩展目标数量是否为1的方法为s4.11至s4.12。
s4.11、计算利用预测状态进行初次划分后的各子集中目标数的最大似然估计
其中
s4.12、根据各子集中目标数最大似然估计值判断是否为1。
若聚类得到的子集中包含的扩展目标数量不为1则再次对改进聚类算法进行改进的方法为s4.21至s4.24。
s4.21、计算每个量测与预测状态之间的距离,并按从小到大排序,选取排序中间3位对应的量测并从中随机选择一个作为第一个初始中心点c1,该点与预测状态之间的距离记为th。
s4.22、计算剩余量测与第一个初始中心点c1之间的距离,在上述距离中选取距离1.6倍th最近的距离对应的量测作为第二个初始中心点c2。
s4.23、将上述中心点合并到初始中心点集合c。
s4.24、计算每个量测到初始中心点集合c内每个初始中心点ci的距离,依据最小距离对量测集进行划分。
s4.25、重新计算每个聚类的均值并作为中心点
s4.26、重复s4.24至s4.25直到中心点不变。
s5、根据聚类的结果对预测的高斯混合项进行更新和计算。s5的具体方法为s5.1至s5.3。
s5.1、对传感器检测到扩展目标时的高斯混合项的权重进行更新
其中dk|k(x)为后验强度函数,
s5.2、基于卡尔曼公式对传感器检测到扩展目标时的均值和方差进行更新
其中表示
s5.3、采用如下公式进行计算
其中p∠zk表示对量测集合zk进行的p次划分,w∈p表示每个划分中的子集单元w。
s6、对高斯混合项进行删除或者合并,并且计算均值和方差。s6的具体方法为s6.1至s6.2。
s6.1、保留权重大于删除门限ηt的高斯混合项,将余下高斯混合项下标集合τk中距离小于ηm的高斯混合项合并。
s6.2、计算合并后的均值和方差
其中
s7、状态提取,并且返回s2。s7的具体方法为s7.1至s7.2。
s7.1、进行状态提取
s7.2、将更新后的高斯混合项作为下次递归的初始值,在滤波器中进行循环更新。
以下通过仿真实验对本发明的效果进行验证,仿真实验中与距离划分方法和传统k-means++算法进行对比。
从图2至5可以看出,基于k-means++聚类算法的多扩展目标跟踪结果较原始k-means++聚类算法的跟踪结果更加稳定,这是由于预测状态增加了初始中心点选择的可靠性,使算法具有较强的稳定性和准确度。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!