基于通勤模型的最优就业岗位布局选址决策系统的制作方法
本发明属于城市规划领域,具体涉及一种基于通勤模型的最优就业岗位布局选址决策系统。
背景技术:
城市规划是一个问题导向和目标导向相结合的过程,在国内规划实践中,目标导向(goal-oriented)的地位往往更加突出。规划中往往设定一些目标愿景,通过一定的策略去实现这些愿景。但是实行的策略能否达到预期的效果是传统规划实践中规划人员难以回答的,唯有借助模型才能实现定量化地判断。而目前,国内规划实践领域很少有此类辅助规划决策的模型系统,对于未来可能出现的状况往往基于规划师等决策者的经验判断。
传统规划方法下,就业空间的规划布局大致包括两步:首先,依据城市的宏观经济发展指标确定就业岗位的大致规模;继而,依靠规划师的专业知识设计就业岗位的具体布局。这种做法实际上存在很大的主观性。规划本质上是面向未来的,规划师的知识和经验在短期内较为有效,一定程度上可以指导规划实践,但在长期内不确定性增大;同时,基于经验的定性判断在较为宏观的城市发展方向、城市空间结构方面可以取得一定效果,但是在更精细的尺度和更复杂的情境下,经验判断往往无能为力。
当前的城市规划实践中,随着大数据的普及,采用大数据进行城市研究的应用越来越普遍。但目前大数据的应用基本停留在城市的现状描述方面,进一步运用大数据进行城市空间的预测、模拟极少。具体到城市就业空间规划层面,运用大数据分析现状城市的居住地和就业地分布、居民的平均通勤时间和通勤距离、职住分离状况的判断等相关研究较多,基于这些现状分析,可以定性地感知哪些地区对就业岗位的需求更迫切。但是,就业岗位数量增加后的情况往往不得而知。事实上,就业空间布局的改变会直接导致居民通勤分布的改变,进而导致居民通勤时间和通勤距离的变化,从而对城市交通产生影响,而这些无法被计算的影响就容易使得分析人员(例如规划师和政府相关决策者等)的规划与实际效果出现误差。
技术实现要素:
为解决上述问题,提供一种精细化通勤模型系统,从而辅助分析员在城市规划中对就业岗位的布局选址决策,本发明采用了如下技术方案:
本发明提供了一种基于通勤模型的最优就业岗位布局选址决策系统,用于生成就业岗位布局建议从而帮助分析员完成城市规划中近期的就业岗位的布局选址决策,其特征在于,包括:通勤模型存储部,存储有分别对应城市中各个城市空间单元的残差通勤模型;城市数据存储部,存储有每个城市空间单元的单元信息以及相应的单元通勤数据;模拟范围获取部,用于获取被分析员输入的通勤模拟范围;模拟空间检索获取部,用于根据通勤模拟范围对城市数据存储部进行检索并根据相应的单元信息获取对应的城市空间单元作为模拟空间单元;通勤成本计算部,用于根据残差通勤模型对单元通勤数据以及预先获取的岗位模拟数值进行计算,从而得到在增加岗位模拟数值前后每一个模拟空间单元所对应的其他模拟空间单元的通勤成本;通勤数值计算部,用于依次根据每一个模拟空间单元所对应的所有通勤成本计算每个模拟空间单元在增加岗位模拟数值前后的通勤评价数值;以及规划建议生成输出部,用于根据通勤评价数值生成相应的近期就业岗位布局建议并输出给分析员。
本发明提供的基于通勤模型的最优就业岗位布局选址决策系统,还可以具有这样的技术特征,其中,残差通勤模型的公式为:lntij=κi+αilnnj+βilndij+∑kαkd_sek+εij,式中,tij为城市空间单元之间的通勤量,i表示第i个出发地单元,j表示第j个就业地单元,nj为第j个就业地单元的就业岗位数量,dij为第i个出发地单元和第j个就业地单元之间的通勤成本,αi为第i个出发地单元的就业岗位影响系数,βi为第i个出发地单元的成本衰减系数,κi为第i个出发地单元的常数项,εij为第i个出发地单元与第j个就业地单元之间的通勤量的残差,d_sek是对应第k类的聚类类型的残差虚拟变量,k取值为[0,1,2,3],d_sek的取值为[0,1],αk是相应的残差系数。
本发明还提供了一种基于通勤模型的最优就业岗位布局选址决策系统,用于生成就业岗位布局建议从而帮助分析员完成城市规划中远期的就业岗位的布局选址决策,其特征在于,包括:通勤模型存储部,存储有分别对应城市中各个城市空间单元的单元通勤模型;城市数据存储部,存储有每个城市空间单元的单元信息以及相应的单元通勤数据;模拟范围获取部,用于获取分析员输入的通勤模拟范围;模拟空间检索获取部,用于根据通勤模拟范围对城市数据存储部进行检索并根据单元信息获取相应的城市空间单元作为模拟空间单元;通勤成本计算部,用于根据单元通勤模型对单元通勤数据以及预先获取的岗位模拟数值进行计算,从而得到在增加岗位模拟数值前后每一个模拟空间单元所对应的其他模拟空间单元的通勤成本;通勤数值计算部,用于依次根据每一个模拟空间单元所对应的所有通勤成本计算每个模拟空间单元在增加岗位模拟数值前后的通勤评价数值;以及规划建议生成输出部,用于根据通勤评价数值生成相应的远期就业岗位布局建议并输出给分析员。
本发明提供的基于通勤模型的最优就业岗位布局选址决策系统,还可以具有这样的技术特征,其中,单元通勤模型的公式为:lntij=κi+αilnnj+βilndij+εij,式中,tij为城市空间单元之间的通勤量,i表示第i个出发地单元,j表示第j个就业地单元,nj为第j个就业地单元的就业岗位数量,dij为第i个出发地单元和第j个就业地单元之间的通勤成本,αi为第i个出发地单元的就业岗位影响系数,βi为第i个出发地单元的成本衰减系数,κi为第i个出发地单元的常数项,εij为第i个出发地单元与第j个就业地单元之间的通勤量的残差。
本发明提供的基于通勤模型的最优就业岗位布局选址决策系统,还可以具有这样的技术特征,还包括:信令数据存储部、分配权重存储部、通勤数据分析获取部以及通勤数据分配部,其中,信令数据存储部存储有预先获取的城市中各个手机基站的手机信令数据,分配权重存储部存储有各个手机基站与各自周边最近的预定数量个城市空间单元相对应的分配权重,通勤数据分析获取部对手机信令数据进行分析从而获取包含居民的出发地基站以及就业地基站的居民通勤数据,通勤数据分配部根据分配权重依次将居民通勤数据中的出发地基站以及就业地基站分配至周边的城市空间单元,从而得到包含居民的出发地单元以及就业地单元的单元通勤数据,城市数据存储部将单元通勤数据分别与单元信息进行对应存储。
本发明提供的基于通勤模型的最优就业岗位布局选址决策系统,还可以具有这样的技术特征,其中,通勤成本为通勤距离或是通勤时间,通勤评价数值为根据通勤成本计算的均值、标准差、分位数、峰度或偏度。
本发明提供的基于通勤模型的最优就业岗位布局选址决策系统,还可以具有这样的技术特征,其中,城市空间单元为由城市中划分的居委会范围构成的居委会单元。
发明作用与效果
根据本发明的基于通勤模型的最优就业岗位布局选址决策系统,因为通过手机信令数据实现了构建分单元的模型,并通过增加岗位模拟数值计算每个城市空间单元对应其他城市空间单元的通勤成本,进一步根据该通勤成本得到每个城市空间单元在增加岗位模拟数值的前后的通勤评价数值,也就实现了通过该通勤评价数值的变化获知分别对各个城市空间单元增加岗位数量会产生的通勤效果,从而帮助分析员在城市规划中完成就业岗位的布局选址决策,更容易比选出效用最大的就业岗位布局地。同时,由于采用的模型为残差通勤模型,因此其拟合优度更高,在短期规划中具有更高的准确率以及可靠性。
另外,本发明的基于通勤模型的最优就业岗位布局选址决策系统还可以采用单元通勤模型,虽然该模型的拟合优度相对于残差通勤模型较低,然而其在远期规划中能够提供更稳定的通勤数据计算并且同样具有一定的准确率,因此本发明还能够基于单元通勤模型实现对城市规划布局的远期规划。
附图说明
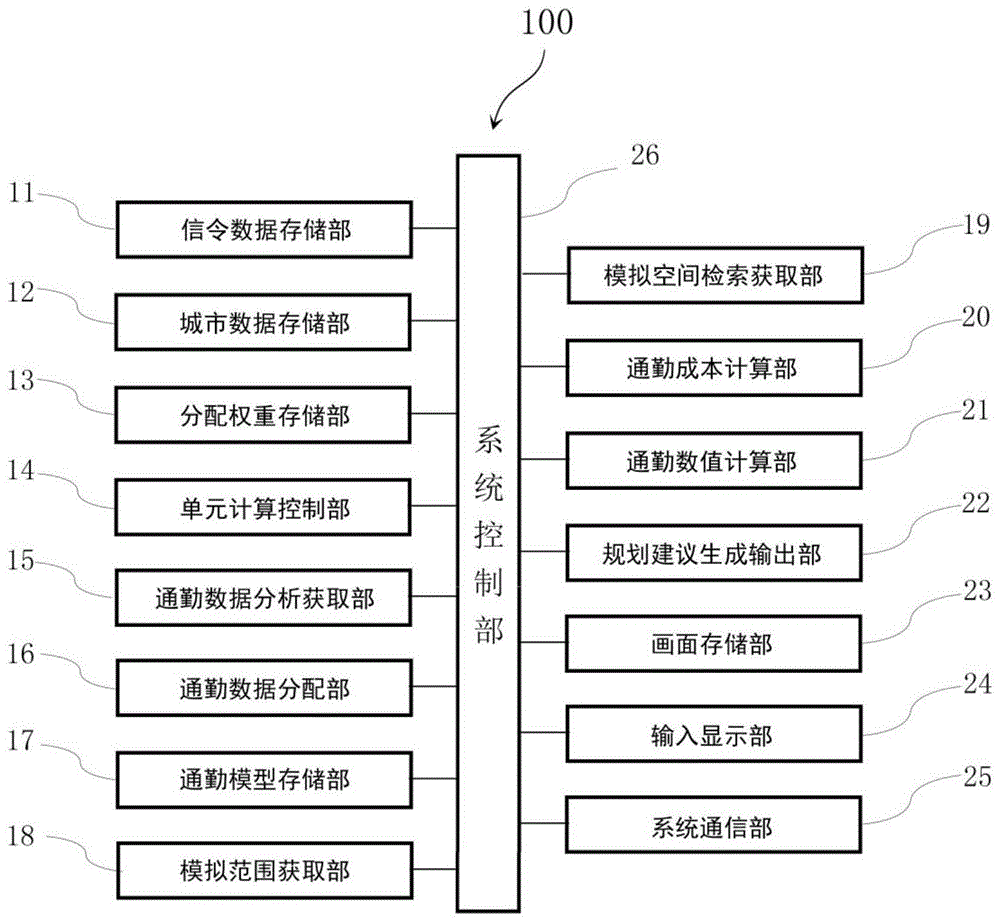
图1是本发明实施例中最优就业岗位布局选址决策系统的结构框图;
图2是本发明实施例中通勤数据集的示意图;
图3是本发明实施例中就业岗位对通勤流的影响示意图;
图4是本发明实施例中某一目标单元增加岗位后的各受影响单元平均通勤时间变化值直方图;
图5是本发明实施例中通勤距离减少最多的上海市就业岗位空间布局_近期的示意图;
图6是本发明实施例中通勤距离减少最多的上海市就业岗位空间布局_远期的示意图;以及
图7是本发明实施例中通勤模拟过程的流程图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的基于通勤模型的最优就业岗位布局选址决策系统作具体阐述。
<实施例>
图1是本发明实施例中最优就业岗位布局选址决策系统的结构框图。
如图1所示,最优就业岗位布局选址决策系统100包括信令数据存储部11、城市数据存储部12、分配权重存储部13、单元计算控制部14、通勤数据分析获取部15、通勤数据分配部16、通勤模型存储部17、模拟范围获取部18、模拟空间检索获取部19、通勤成本计算部20、通勤数值计算部21、规划建议生成输出部22、画面存储部23、输入显示部24、系统通信部25以及控制上述各部的系统控制部26。
其中,系统通信部25用于进行最优就业岗位布局选址决策系统100的各个构成部分之间以及最优就业岗位布局选址决策系统100与其他系统之间的数据交换,系统控制部26中存储有用于对最优就业岗位布局选址决策系统100的各个构成部分的工作进行控制的计算机程序。
信令数据存储部11存储有城市中各个手机基站的基站信息以及相对应的手机信令数据。基站信息为手机基站的id编号,基站信息以及手机信令数据预先通过与手机基站数据库连接获取从而存储至信令数据存储部11,或是通过用户导入并存储至信令数据存储部11。
本实施例中,手机信令数据包括手机的手机信息(例如手机编号)、时刻信息(即通信发生的时间)以及通信时的基站信息(例如基站编号)。手机信令数据为一个城市中各个手机基站与各个居民(即手机的持有者)的手机通信时产生的手机信令。当居民的手机发生开关机、收发短信、接打电话时会与基站发生“信息交换”,即手机在特定时间(行为发生的时间)被周边的特定基站(空间位置)记录一个点,获得时空信息。若居民没有任何行为,手机位置也会“周期性更新”,即每隔2个小时左右进行周期性位置更新,也就是说,即使居民的手机没有被使用,每隔2个小时也会被记录一个点。
本实施例中,信令数据存储部11中存储的基站信息以及手机信令数据由分析员事先采集并存储的。
城市数据存储部12存储有城市的城市信息、与城市对应的各个城市空间单元的单元信息、各个城市空间单元之间的通勤成本、以及各个城市空间单元的单元通勤数据。
本实施例中,城市空间单元为按城市中划分的居委会范围构成的居委会单元,城市信息、单元信息以及通勤成本为预先通过公开的城市规划数据(例如第六次全国人口普查所发布的城市信息)获取。城市信息为城市的名称,单元信息为居委会单元的名称(或id编号等识别信息)以及各个居委会单元的划分范围。通勤成本为居民在两个城市空间单元之间通勤所需要的通勤距离或是通勤时间。
本实施例中,单元通勤数据由单元计算控制部14控制相关部件根据城市中各个手机基站的手机信令数据计算得到,具体将于下文详述。
分配权重存储部13用于存储对应各个手机基站的分配权重,该分配权重为将一个手机基站的居民通勤数据分配至与其周边最近的30个居委会单元的权重比例。
本实施例中,分配权重预先根据手机基站与周边的居委会单元的相邻距离计算得到,该计算方法为:
同时满足:
式中,
本实施例中,带宽距离的取值为4km,且该带宽距离为相邻距离的最大取值(即,当相邻距离大于4km时就取值4km),通过公式(1)及(2),就能够得出每个手机基站与其对应的30个周边的居委会单元的分配权重。
单元计算控制部14用于对单元通勤数据生成过程相关的部件工作进行控制,即:在获取到信令数据时,控制通勤数据分析获取部15对手机信令数据进行分析从而依次获取与手机基站对应的居民通勤数据,进一步控制通勤数据分配部16根据分配权重将与手机基站对应的居民通勤数据分配至城市空间单元从而得到与城市空间单元对应的单元通勤数据。
本实施例中,通勤数据分析获取部15首先将手机信令数据根据手机信息进行统计,从而得到每一个居民在两周内的手机信令数据。进一步,对于各个居民的手机信令数据,依次根据手机信令数据中的时刻信息进行居民生活轨迹的分析从而识别出居民的居住地(即出发地对应的基站)以及工作地(即就业地对应的基站)。
具体地,如果居民在夜间(晚上8点至次日早上6点)被记录的点较为固定(称为“夜间高频记录点”),则可以认为这个点(即手机基站所对应的位置信息)是居民的居住地。同理,如果居民在白天(早上9点至晚上6点)被记录的点较为固定(称为“日间高频记录点”),那么这个点很有可能就是该居民的工作地。即:夜间高频记录点代表居住地,日间高频记录点代表工作地。
因此,通勤数据分析获取部15就能够根据手机信令数据分析得到出发地基站以及就业地基站,进一步生成居民通勤数据。该居民通勤数据包括对应出发地的出发地基站信息、相应的出发时刻、对应就业地的就业地基站信息、相应的就业时刻以及手机信息。
本实施例中,通勤数据分配部16在分配居民通勤数据时,同时将出发地基站以及就业地基站分配至相应的居委会单元,即得到出发地居委会单元以及就业地居委会单元。如图2所示,最终得到的单元通勤数据包括对应出发地的出发地居委会单元编号pcq_o(即出发地居委会单元的单元信息)、对应就业地的就业地居委会单元编号pcq_d(即就业地居委会单元的单元信息)、出发地居委会单元的总居住人口num_home_o(根据出发地居委会单元分配到的手机信息的数量得到)、就业地居委会单元的总就业岗位num_work_d(根据就业地居委会单元分配到的手机信息的数量得到,后文简写为nj)、出发地和工作地之间的通勤量num(根据当前的出发地居委会单元以及目的地居委会单元之间的手机信息的数量得到,后文简写为tij)、通勤距离dist(根据出发地基站以及就业地基站之间的距离得到,后文简写为dij)、汽车通勤时间(即使用汽车通勤)dura_car以及公交通勤时间dura_bus(通勤时间通过距离以及预设的通勤速度换算得到)。本实施例的残差通勤模型采用通勤距离,其他实施例中,残差通勤模型还可以采用汽车通勤时间或是公交通勤时间作为通勤成本。另外,本实施例中,上述通勤时间以及通勤距离的数据通过网络爬虫从地图服务软件(例如高德地图)中批量抓取得到。
通勤模型存储部17用于存储有对应各个城市的单元通勤模型以及残差通勤模型。
本实施例中,残差通勤模型以及单元通勤模型都可以用于进行就业岗位布局的选址决策,优选地,残差通勤模型更适合用于进行近期预测,单元通勤模型更适合用于进行远期预测。
具体地,残差通勤模型的形式如下:
lntij=κi+αilnnj+βilndij+∑kαkd_sek+εij(3)
式中,tij为城市空间单元之间的通勤量,i表示第i个出发地单元,j表示第j个就业地单元,nj为第j个就业地单元的就业岗位数量,dij为第i个出发地单元和第j个就业地单元之间的通勤成本(本实施例采用通勤距离),αi为第i个出发地单元的就业岗位影响系数,正常情况下系数为正,βi为第i个出发地单元的距离衰减系数,正常情况下系数为负,κi为第i个出发地单元的常数项,εij为第i个出发地单元与第j个就业地单元之间的通勤量的残差。d_sek是对应第k类的聚类类型的残差虚拟变量,k取值为[0,1,2,3],d_sek的取值为[0,1],αk是相应的残差系数。(其中ln这个符号表示对相应的变量取“对数”,相当于将原来的变量做了一个数值变换,公式中对通勤量、居住人口、就业岗位和通勤距离都做了一个变换。)
本实施例中,残差虚拟变量d_sek为预先通过对单元通勤模型进行多次计算从而得到的,单元通勤模型的形式如下:
lntij=κi+αilnnj+βilndij+εij(4)
式中,参数的含义与式(3)的残差通勤模型中相似。
同时,值得注意的是,由于构建了单元通勤模型以及残差通勤模型都是分单元的模型,因此每个城市空间单元在式(3)与(4)中的就业岗位系数αi和距离衰减系数βi都是不一样的,下标i分别对应了各个单元。
通过预先根据式(4)的单元通勤模型对特定城市空间单元(该特定城市空间单元可以是城市中任意一个城市空间单元)与其他各个城市空间单元间的通勤量进行计算,从而结合实际通勤量计算差值得到残差{rn,xn,yn},其中,rn代表对应第n个城市空间单元的残差的绝对数值,xn和yn代表第n个城市空间单元的平面坐标(即经纬度)。以某任意两地之间为例,a为出发地,b为目的地,两地之间首先存在一个实际的通勤量,简记为t1,其次,对于a来说,可以通过分单元基础模型计算出预测的通勤量,简记为t2,残差即(t1-t2),简记为r。对于同一个出发地a,到不同的目的地b(b1、b2、b3……bn)的残差不同,分别记为r1、r2、r3……rn,又因为每个目的地的空间位置不同,于是每个残差就有了一个空间位置属性,将残差的值和空间位置属性记为{rn,xn,yn}。
进一步,将残差{rn,xn,yn}以空间聚类模式进行聚类(具体可采用arcgis中内置的局部空间自相关计算工具,并采用python编写循环算法,对上海市5000个左右的居委会单元依次进行计算),从而根据每个城市空间单元的两个残差(即从特定城市空间单元出发的居民到一个城市空间单元就业的残差以及该城市空间单元周边各个单元的残差)的高低的得到4种类型的聚类结果,即高高聚类(hhcluster)、低低聚类(llcluster)、高低聚类(hlcluster)以及低高聚类(lhcluster)。例如,一个空间单元位于地铁沿线,那么这个空间单元中居民的就业很可能大部分都在地铁沿线,那么地铁沿线的残差可能很高,地铁沿线就是“高高聚类”。最后,将4种类型的聚类结果进行变量化处理得到残差虚拟变量d_sek。
本实施例中,通勤模型存储部17中存储的单元通勤模型以及残差通勤模型与传统的全局通勤模型相比如下:
表1传统全局模型、基础模型和残差模型比较
如表1所示,残差模型的平均拟合优度达到0.92,远远超过单元通勤模型的0.76和全局模型的0.65,拟合优度的提高意味着预测效果有了大幅度提升。但残差模型也有一定的局限性。首先,残差模型基本上可以认为是“不可解释”的,但因为这些残差在空间上分布具有一定的特征,而空间可以对应实际的事物(变量),因此结果具有一定的可靠性。其次,空间上显著集聚的残差所表征的“特殊联系”只有短期内是稳定的,但远期内会发生变化,因此残差模型的预测期限仅限于近期。反之,单元通勤模型虽然平均拟合优度较低,但在远期范围内更稳定,因此可以用作远期的预测期限。值得一提的是,近期、远期并没有确定的界线,实际应用中可根据需要进行调整。例如,1-5年可视为近期,5-15年可视为长期。
模拟范围获取部18用于获取分析员输入的通勤模拟范围。
在实际使用中,分析员在使用系统进行分析时,通常会根据实际的需要选定一定的研究区域。本实施例中,模拟范围获取部18能够获取分析员通过输入显示部24输入的通勤模拟范围并由模拟空间检索获取部19决定系统运行时的模拟范围。
模拟空间检索获取部19用于根据通勤模拟范围对城市数据存储部12进行检索,从而根据城市数据存储部12中各个城市空间单元的划分范围获取在通勤模拟范围内的所有城市空间单元作为模拟空间单元。
本实施例中,作为示例而计算的是上海市最优的就业岗位布局空间,因此通勤模拟范围选定了整个上海市域,即、模拟空间单元为整个上海市的所有居委会单元。
在其他实施例中,可由分析员依据规划层面的不同,选择不同的空间范围。例如,对于杨浦区的就业规划,可选定全杨浦区的空间单元进行模拟;对于若干个产业园区进行就业岗位选址比较时,也可以单独选定这些产业园区所在的空间单元进行模拟。
通勤成本计算部20用于根据残差通勤模型(或是单元通勤模型)对单元通勤数据以及预先获取的岗位模拟数值进行计算,从而得到在增加岗位模拟数值的前后每一个模拟空间单元(以下或称目标单元)所对应的其他模拟空间单元(以下或称受影响单元)的通勤成本。
本实施例中,通勤成本计算部20会首先根据残差通勤模型(或是单元通勤模型)对单元通勤数据进行计算从而获得原始的通勤成本(即在增加岗位模拟数值前的通勤成本,以下称原始通勤成本)。
本实施例中,岗位模拟数值为预先存储在计算机中的数值,本实施例中取值为“+10000”,即表示在某个城市空间单元中增加10000个工作岗位(同理,亦可预先设为“-10000”,即比较条件设为减少1万个就业岗位,后续原理类似)。进一步,在生成通勤成本时,每次模拟时系统仅对其中的一个模拟空间单元(即目标单元)进行操作——将该单元的岗位数增加10000,而其他单元岗位数不变,带入模型计算结果,得出该单元增加岗位后的其他各个城市空间单元(即受影响单元)的通勤成本(即在增加岗位模拟数值后的通勤成本,以下称变化通勤成本);如此,通勤成本计算部20依次对上海市的4991个模拟空间单元依次模拟一遍。
在其他实施例中,也可以由分析员根据实际需要通过输入显示部24输入岗位数值作为通勤成本计算部20所使用的岗位模拟数值。
通勤数值计算部21用于依次根据每一个模拟空间单元所对应的所有通勤成本计算每个模拟空间单元在增加岗位模拟数值前后的通勤评价数值。
通勤评价数值为根据通勤成本计算的均值、标准差、分位数、峰度或偏度。为了方便起见,本实施例的通勤评价数值取均值,即平均通勤时间,第i个模拟空间单元平均通勤时间的计算公式如下:
其中,
本实施例中,通勤数值计算部21依次根据通勤成本计算部20完成的4991次模拟得到的原始通勤成本以及变化通勤成本,从而得到4991个目标单元所对应的原始平均通勤时间以及变化平均通勤时间。
在上述通勤成本计算部20以及通勤成本计算部20计算过程中,为了解决“1万个新增岗位分布在上海哪个单元或哪些单元的绩效最好”这一问题,需要确定岗位增加后的各个单元的绩效评价标准。以平均通勤时间为例,如果新岗位分布在某些单元可以最大程度的缩短全市的平均通勤时间,那么这些单元的绩效是最好的。理论上,在任意一个单元(即目标单元)增加一定数量的就业岗位,那么现状与其有通勤联系的单元(即受影响单元)的通勤量都会发生变化,因为本实施例的残差通勤模型以及单元通勤模型是能够对应每个单元的分单元模型,所以即使相同的变化量在各单元产生的影响大小也各不相同,这便是分单元模型优于传统全局模型的关键所在。
值得注意的是,对于每一个受影响单元,其受影响的通勤流实际上只有一条,即与目标单元之间的通勤流变化,与其他单元的通勤流是不变的。例如,如图3所示,目标单元a增加岗位后,x、y、z等单元到a的通勤流改变,而到其他单元b、c、d的通勤流不变。
进一步,要比较每个目标单元增加就业岗位前后对其他单元的通勤影响大小,就需要将所有受影响单元的绩效汇总到该目标单元从而形成目标单元的“绩效”(即计算通勤评价数值)。因此,本实施例展示了一种基本的思路,即:首先根据模型计算每个单元变化前的平均通勤时间,总计4991个单元意味着共有4991个通勤时间,这个称为初始平均通勤时间。在某一单元(以下简称为目标单元a)的就业岗位数量增加后计算每个受影响单元与其“新的”通勤联系,并重新计算每个单元新的平均通勤时间,与初始值比较,就可以获得目标单元a岗位增加后,受影响的各单元平均通勤时间的变化值,这些变化值在概率上可以理解为一个分布(distribution),通过对这个变化值分布的考察,可以定量判断目标单元a岗位增加的绩效。如图4所示,图中为对目标单元增加1万个就业岗位后其他各个城市空间单元的时间变化值的分布,从图4中可以看出大部分的单元平均通勤时间变化不大,90%单元的平均通勤时间变化集中在[-0.03,0.03]区间内,意味着仅仅改变一个单元的就业岗位数量的影响是很有限的,但是不同的目标单元之间的比较是有意义的。
规划建议生成输出部22用于根据通勤评价数值(即原始平均通勤时间以及变化平均通勤时间)生成含有各个模拟空间单元(即目标空间)相应的近期(或远期)就业岗位布局建议并输出给分析员。
本实施例中,近期(或远期)就业岗位布局建议包含有各个模拟空间单元以及相应在增加就业岗位后的绩效幅度,该绩效幅度可以是平均通勤时间变化幅度、平均通勤距离变化率、岗位需求程度等能够反应通勤评价数值的变化程度的数值。
例如,本实施例的近期模拟结果(残差通勤模型)如图5所示,图中的江湾-五角场、金桥、张江-川沙和莘庄-七宝都属于城市副中心级别,川沙和莘庄同时属于新的上海市主城区范围(另有虹桥和宝山新城,称为“主城片区”),对于这部分地区,上海总规(2017-2035)的要求是加快产业转型和空间调整,适当增加就业岗位,促进产城融合。另外,罗店-顾村、金桥、南站-漕河泾、曹路、共康-大宁、高青路-御桥等都属于地区中心级别,总体规划对此的要求是根据地区人口规模与发展需求,实现公共服务与就业岗位均衡化布局,主要服务周边地区。其他地区也基本上属于现状主要的就业中心,包括闵行经开区、紫竹高新、外高桥等地区,另外,浦江和周浦等地区增加就业岗位也是可以改善全市的通勤状况的。
同时也可以看到,在内环核心地带,包括陆家嘴、南京东路、南京西路一带,现状的就业岗位非常集中,是全市最高级别的就业中心。但是模型的计算结果显示,这些地区没有再进一步增加就业岗位的必要,因为过多的就业岗位会吸引更远地区的居民前来就业,导致全市的平均通勤距离进一步增加。
同理,本实施例的远期模拟结果(单元通勤模型)如图6所示,该远期的计算结果与近期相似,优先级地区几乎一致,只是在具体数值上有所差异。
此外,上述通过模型计算得到的结果与上海市总体规划中提出的重点发展的地区吻合度较高,这可以说明模型机计算结果的合理性,也意味着构建的模型可以较好地指导城市规划实践。
综上,根据模型的计算得到的通勤评价数值,以上海市的就业岗位布局规划为例,规划建议生成输出部22在生成的上海市就业岗位布局建议如下表所示:
表2上海市就业岗位布局优化建议
从表2中可以看出,张江-川沙和金桥地区,由于其既属于城市副中心,功能较为综合,且从计算结果来看就业岗位增量需求很大,因此是未来一段时期内上海应重点发展的地区。其次,南站-漕河泾和罗店-顾村地区的就业岗位增量需求也很大,这些地区附近居民的平均通勤距离都较长,因此这增加就业岗位对于周边地区居民的通勤状况将有很大改善。
画面存储部23存储有模拟范围输入画面以及就业岗位布局建议显示画面。
模拟范围输入画面用于在分析员启动系统的分析流程时显示从而让分析员输入通勤模拟范围。
本实施例中,模拟范围输入画面根据城市数据存储部12存储的城市信息以及单元信息完成与城市相应的地图的显示,从而让分析员以在地图上框定边界的方式完成通勤模拟范围的选定。在其他实施例中,模拟范围输入画面也能显示有文本输入框,从而让分析员输入通勤模拟范围的区域名称或是范围坐标等信息作为通勤模拟范围。
同时,模拟范围输入画面还显示有规划期输入框,从而让分析员选定是进行近期还是远期的规划。在其他实施例中,分析员也能够同时选定近期以及远期规划,此时通勤成本计算部20以及通勤数值计算部21会分别采用残差通勤模型以及单元通勤模型完成计算,并由规划建议生成输出部22同时输出近期以及远期的就业岗位布局建议。
就业岗位布局建议显示画面用于在规划建议生成输出部22输出就业岗位布局建议时显示从而让分析员查看。
本实施例中,就业岗位布局建议显示画面显示有如表2所示的建议表。在其他实施例中,就业岗位布局建议显示画面还可以通过图表等形式(例如图5及图6所示的)显示相应的就业岗位布局建议。
输入显示部24用于显示上述画面,从而让分析员通过这些画面完成相应的人机交互。
本实施例中,通过一台具有输入显示设备的计算机实现上述方案,最优就业岗位布局选址决策系统100的部件为计算机的组成部分,如画面存储部23以及输入显示部为计算机的输入显示设备,其余部件作为计算机程序存储在计算机的内存并根据预设的条件完成运行。
图7是本发明实施例中通勤模拟过程的流程图。
如图7所示,在分析员通过输入显示部24输入通勤模拟范围后,开始如下步骤:
步骤s1,模拟范围获取部18获取被分析员输入的通勤模拟范围,然后进入步骤s2;
步骤s2,模拟空间检索获取部19根据步骤s1获取的通勤模拟范围对城市数据存储部12进行检索并根据相应的单元信息获取对应的城市空间单元作为模拟空间单元,然后进入步骤s3;
步骤s3,通勤成本计算部20用于根据残差通勤模型(或单元通勤模型)对城市数据存储部12中存储的单元通勤数据以及预先获取的岗位模拟数值进行计算,从而得到在增加岗位模拟数值前后每一个模拟空间单元所对应的其他模拟空间单元的通勤成本,然后进入步骤s4;
步骤s4,通勤数值计算部21根据步骤s3计算得到的每一个模拟空间单元所对应的所有通勤成本,计算每个模拟空间单元在增加岗位模拟数值前后的通勤评价数值,然后进入步骤s5;
步骤s5,规划建议生成输出部22根据步骤s4计算得到的通勤评价数值生成短期(或长期)就业岗位布局建议,并输出给输入显示部24从而通过就业岗位布局建议显示画面显示给分析员查看,然后进入结束状态。
实施例作用与效果
根据本实施例提供的基于通勤模型的最优就业岗位布局选址决策系统,因为通过手机信令数据实现了构建分单元的模型,并通过增加岗位模拟数值计算每个城市空间单元对应其他城市空间单元的通勤成本,进一步根据该通勤成本得到每个城市空间单元在增加岗位模拟数值的前后的通勤评价数值,也就实现了通过该通勤评价数值的变化获知分别对各个城市空间单元增加岗位数量会产生的通勤效果,从而帮助分析员在城市规划中完成就业岗位的布局选址决策,更容易比选出效用最大的就业岗位布局地。同时,由于采用的模型为残差通勤模型,因此其拟合优度更高,在短期规划中具有更高的准确率以及可靠性。
另外,本实施例还可以采用单元通勤模型,虽然该模型的拟合优度相对于残差通勤模型较低,然而其在远期规划中能够提供更稳定的通勤数据计算并且同样具有一定的准确率,因此本发明还能够基于单元通勤模型实现对城市规划布局的远期规划。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
- 还没有人留言评论。精彩留言会获得点赞!