基于分层注意力机制的跨领域情感分类系统及方法与流程
本发明涉及及情感分析和观点挖掘领域,具体涉及一种基于分层注意力机制的跨领域情感分类系统及方法。
背景技术:
跨领域情感分类是利用相关源领域的知识和丰富的标记数据来改进目标领域。然而,用户情感表达在不同的领域有不同的表现。例如,在书籍领域,可读性强、深思熟虑等词汇是被用来表达积极的情绪,而平淡、无情节等词汇则常常被表示为消极的情绪。由于领域的差异性,在源领域训练的情感分类器如果直接运用于目标领域可能不能起到很好的作用。为了解决这个问题,研究人员提出了各种跨领域情感分类的方法。
目前跨领域情感分类研究主要分为基于词典的方法、基于特征迁移的学习方法和基于神经网络的学习方法:
基于词典的方法主要是通过利用现有整理的词典资源来缩小源领域与目标领域在特征词项上存在的差异。目前有研究人员将英文情感词典应用于跨领域情感分类,虽然该词典所蕴含的情感词汇较多,覆盖面也比较广,但是随着互联网技术的不断发展,词典的更新速度远远不及网络用语等的发展,该方法在目标领域中的分类效果完全取决于情感词典的丰富程度,因此有研究人员通过源领域中的相关信息,自动从目标领域中提取出情感词及相关主题信息,在一定程度上降低了对情感词典的依赖程度。
基于特征迁移的学习方法主要是为了解决源领域和目标领域的特征空间存在差异的问题,通过将每一个领域中的数据映射到同一空间下,让源领域和目标领域具有相同的分布,因此目标领域可以通过源领域的训练数据来进行学习。研究人员提出结构对应学习模型是利用多轴预测人来来推断轴与非轴之间的相关性;而谱特征对齐方法是利用轴与非轴之间的协同效应来确定二者之间的对齐,这些方法都需要通过手动选择轴,并且是基于离散的特征表示。这些方法都是基于专家设计的规则或者n-gram对句子进行特征提取,忽略了上下文之间的关系和重要单词的情感信息,不能在跨领域大规模的数据中取得良好的效果。
基于神经网络的学习方法是将深度学习应用在跨领域场景下情感分类的共同特征和共享参数的学习方法。研究人员通过堆叠降噪自编码器来对多个领域的未标注数据进行预训练,结合源领域的标注数据和预训练模型来训练情感分类模型;而边缘降噪自动编码器则是保留了强大的特征学习能力并且解决了高昂的计算成本和sda扩展问题。这些方法缺乏了可解释性,无法充分证明网络是否充分学习到了枢轴特征,仍有很大的探索空间。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于分层注意力机制的跨领域情感分类系统及方法,提高跨领域情感分类的精度和减少人工时间精力的消耗。
为实现上述目的,本发明采用如下技术方案:
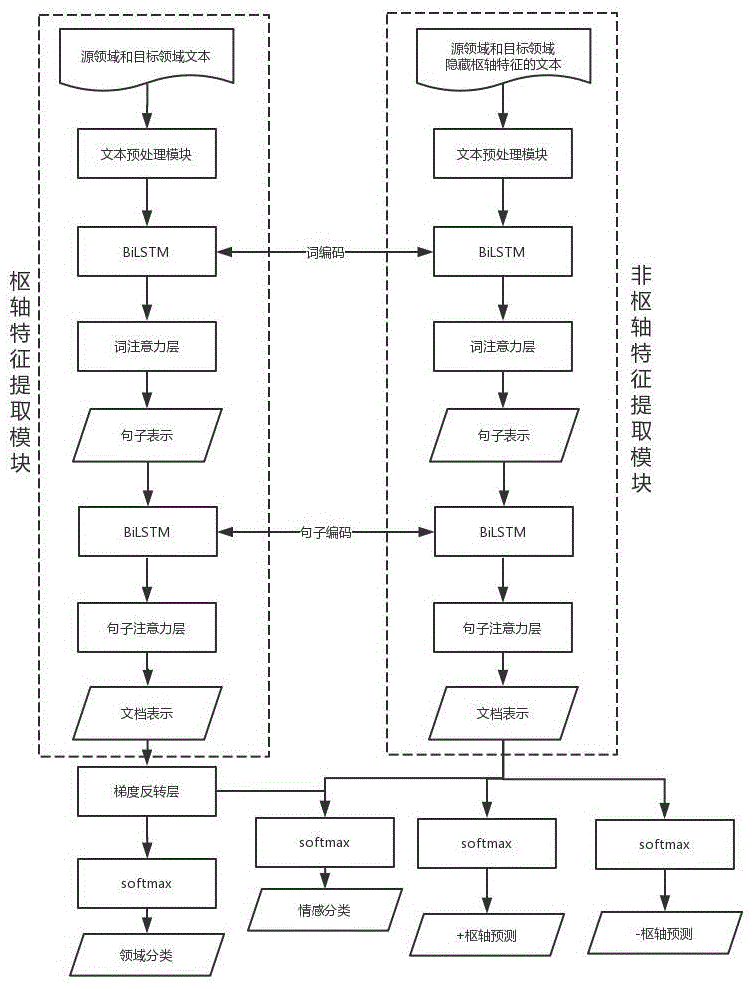
一种基于分层注意力机制的跨领域情感分类系统,其特征在于,包括:
文本预处理模块,用于对跨领域文本进行特征化处理;
枢轴特征提取模块,用于学习领域适应的特征表示空间,得到源领域与目标领域的枢轴特征文档表示;
非枢轴特征提取模块,用于获取非枢轴特征表示;
情感类别输出模块,利用softmax分类函数得到最终的情感分类结果。
进一步的,所述文本预处理模块采用word2vec提取源领域与目标领域文本的特征。
基于分层注意力机制的跨领域情感分类系统的分类方法,包括以下步骤:
步骤s1:将源数据和目标数据输入文本预处理模块,采用word2vec提取源领域与目标领域文本的特征;
步骤s2:根据得到的源领域与目标领域文本的特征,通过枢轴特征提取模块得到枢轴特征文档表示;
步骤s3:将枢轴特征提取模块获取的枢轴特征通过填充词替代的方式隐藏所有的枢轴特征,作为非枢轴特征提取模块的输入,获取非枢轴特征表示;
步骤s4:将获取的枢轴特征文档表式和非枢轴特征文档表示,通过拼接构成最终情感分类文档表示;
步骤s5:根据得到的最终情感分类文档表示,通过情感类别输出模块对所得向量逐一计算,根据设定的阈值得到该文本表示的情感类别预测值。
进一步的,所述步骤s1具体为:
步骤s11:对源领域和目标领域的文本进行分词并过滤停用词;
步骤s12:通过word2vec来将文本数据从文本形式转换成向量形式。
进一步的,所述步骤s2具体为:
步骤s21:根据源领域与目标领域文本的特征,获取的句子级文本表示;
步骤s22:根据获取的句子级文本表示,采用bilstm捕捉句子层面文本上下文语义信息;
步骤s23:采用注意机制来衡量每个句子对于情感分类任务的重要性,并最终获取枢轴特征文档表示。
进一步的,所述步骤s5具体为:
步骤s51:根据得到的最终情感分类文档表示,利用softmax分类函数对所得向量逐一计算;
步骤s52:利用源领域的文本表示进行情感类别的预测并计算其与实际情感标签的误差;
步骤s53:利用随机梯度下降法和后向传播对整个系统的参数进行迭代更新;否则,对目标领域的文本表示进行情感类别的预测,并输出预测值。
进一步的,所述softmax分类函数的权重和偏置设置具体为:
将获取的非枢轴特征表示作为softmax函数的输入,进行两个子任务预测,子任务一:预测文档表示v'd是否包含至少一个正向枢轴特征;子任务二:预测文档表示v'd是否包含至少一个负向枢轴特征;其计算公式如下:
p+=softmax(wposv'd+bpos)
p+=softmax(wnegv'd+bneg)
其中wpos和bpos分别表示计算是否至少包含一个正向枢轴概率时的softmax层对应的权重参数和偏置,其中wneg和bneg分别表示计算是否至少包含一个负向枢轴概率时的softmax层对应的权重参数和偏置。
本发明与现有技术相比具有以下有益效果:
本发明提供了一种高效的跨领域情感分类方法,提高了跨领域情感分类精度并减少人工时间精力的消耗。
附图说明
图1是本发明方法流程图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种基于分层注意力机制的跨领域情感分类系统,其特征在于,包括:
文本预处理模块,用于对跨领域文本进行特征化处理;
在本实施例中,由于神经网络的输入数据一般为向量,以便模型的端到端训练,因此需要对文本数据进行向量化表示。为了便于数据的处理和分析,在本实施例中的文本预处理模块,首先对源领域和目标领域的文本进行分词并过滤停用词;接着,通过word2vec来将文本数据从文本形式转换成向量形式。
枢轴特征提取模块,用于学习领域适应的特征表示空间,得到源领域与目标领域的枢轴特征文档表示;
在本实施例中,枢轴特征提取模块的文本语义信息获取采用的是前向lstm和后向lstm组合而成的,解决lstm无法编码从后到前的信息,从而更好的捕捉双向的语义依赖,在更细粒度的分类时起到更好的作用。
其次由于上下文词汇对句子语义的贡献是不一样的,特别是当专注于一个特定的任务时,例如情感分类。
将每个句子记忆mor和一个词级查询词qw作为词注意力层的输入,可以获得第r个词在第o个句子的隐藏表示,具体计算公式如下:
hor=tanh(wwmor+bw)
通过计算的αor可以衡量每个单词对句子的影响程度,其中mw(o,r)是一个词级的隐藏函数,用来避免受到填充向量的影响,当一个词记忆mor被占用时,mw(o,r)为1,否则为0。
然后,根据获取的句子级文本表示,再次通过双向lstm捕捉句子层面文本上下文语义信息。
最后,由于每个句子对文档的语义含义贡献程度也不相同,因此再次在句子级别应用注意机制来衡量每个句子对于情感分类任务的重要性,具体计算公式如下:
通过计算的βo可以衡量每个句子对文档的影响程度,其中mc(o)是一个句子级的隐藏函数,用来避免受到填充向量的影响,当一个句子记忆mo空闲时,mc(o)为0,否则为1。句子级查询向量qc时希望能够获得更有效的查询表示。qc是随机初始化的并通过共同学习获得的。
将上述生成的文档表示vd作为带有梯度反转层的域分类器的输入,进行域对抗训练,该子任务的目的使得域分类器无法判别输入样本属于哪个领域,从而获取领域适应的文本表示。
非枢轴特征提取模块,用于获取非枢轴特征表示;
在本实施例中,针对特定的领域,不同的单词和句子对于文本情感分析具有不同的影响,将枢轴特征提取模块获取的枢轴特征通过填充词替代的方式隐藏所有的枢轴特征,将样本x转换为g(x),作为非枢轴特征提取模块的输入,获取非枢轴特征表示v'd:
将获取的非枢轴特征表示作为softmax函数的输入,进行两个子任务预测,子任务一:预测文档表示v'd是否包含至少一个正向枢轴特征;子任务二:预测文档表示v'd是否包含至少一个负向枢轴特征。其计算公式如下:
p+=softmax(wposv'd+bpos)
p+=softmax(wnegv'd+bneg)
其中wpos和bpos分别表示计算是否至少包含一个正向枢轴概率时的softmax层对应的权重参数和偏置,其中wneg和bneg分别表示计算是否至少包含一个负向枢轴概率时的softmax层对应的权重参数和偏置。
情感类别输出模块,利用softmax分类函数得到最终的情感分类结果。
在本实施例中,由于获取的枢轴特征表示和非枢轴特征表示是互补的,因此将获取的枢轴特征文档表示vd和非枢轴特征文档表示v'd,通过拼接构成最终情感分类文档表示di,情感类别输出模块5利用softmax分类函数对所得向量逐一计算,根据设定的阈值得到该文本表示的情感类别预测值。在训练阶段,利用源领域的文本表示进行情感类别的预测并计算其与实际情感标签的误差,利用随机梯度下降法和后向传播对整个系统的参数进行迭代更新;否则,对目标领域的文本表示进行情感类别的预测,并输出预测值。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!