一种基于差分隐私保护的集成推荐方法与流程
本发明涉及到信息安全与机器学习技术领域,具体涉及一种基于差分隐私集成用户协同过滤和矩阵分解的推荐方法。
背景技术:
随着互联网技术的快速发展,互联网上各类应用的评分信息呈现爆发式的增长,例如像电影评分信息。推荐系统技术扮演着越来越重要的角色,可以根据用户的评分信息,来预测用户的行为信息,为其提供个性化推荐服务。
推荐系统通过分析用户的历史评分信息,来预测用户的行为信息,来对其提供个性化的推荐服务,使得用户有一个非常好的服务体验。由于要对用户的评分信息进行分析,如果用户的评分信息泄露,将会导致用户的隐私泄露。如果用户信息大量的泄露,会导致用户的体验感下降,不愿意将自己的信息分享给推荐系统,导致推荐服务质量下降。所以,不但要提高推荐服务的质量,还需要保护用户的隐私信息。
目前用到的隐私推荐方法大多基于加密技术来实现的,但这些加密技术有一个缺陷,它们都是基于攻击者有一定的背景知识限制。同时加密解密技术需要大量的计算开销,也增加推荐系统的计算开销成本。
发明目的
本发明为了克服现有技术存在的不足之处,提出了一种基于差分隐私保护的集成推荐方法,以期望能有效解决现有隐私保护推荐方案中推荐效果不佳和隐私安全性差的问题,从而可以为用户提供既安全且高效的推荐。
本发明为解决技术问题所采用的技术方案是:
本发明一种基于差分隐私保护的集成推荐方法的特点是按如下步骤进行:
步骤一、从评分网站上获取用户对项目的历史评分数据集:
所述评分数据集上有n个用户,记为user={u1,u2,...,ui,...,un},其中ui表示第i个评分用户,1≤i≤n;所述评分数据集上有m个项目,记为item={v1,v2,...,vj,...,vm},其中vj表示第j个评分项目,1≤j≤m;将所述评分数据集中第i个用户ui对第j个项目vj的评分数据记为rij,从而得到所有用户对所有项目的评分数据所组成的评分矩阵rn×m;
步骤二、对评分数据集加入含隐私分配的噪声,得到预处理后的评分矩阵r~;
步骤2.1、利用式(1)计算评分矩阵rn×m加噪后的全局平均gavg:
式(1)中,|r|表示评分矩阵rn×m中有效评分值的计数,rmin表示评分矩阵rn×m中的评分最小值,rmax表示评分矩阵rn×m中的评分最大值,ε1表示第一隐私预算参数,laplace()表示拉普拉斯噪声的随机生成函数,并有:
步骤2.2、利用式(3)计算评分矩阵rn×m中第j个评分项目vj加噪后的平均评分iavg(j):
式(3)中,|rj|表示第j个评分项目vj中有效评分值的计数,rmin,j表示评分矩阵rn×m中第j个评分项目vj的评分最小值,rmax,j表示评分矩阵rn×m中第j个评分项目vj的评分最大值,β1表示添加的加噪后全局平均评分的个数,ε2表示第二隐私预算参数,并有:
步骤2.3、将评分矩阵rn×m中的所有评分数据减去加噪后相应评分项目的平均评分后,得到折扣后的评分矩阵为r′={r′ij|i=1,2,…,n;j=1,2,…,m};r′ij表示折扣后评分矩阵r′中第i个用户ui对第j个项目vj的评分值,且r′ij=rij-iavg(j);
利用式(5)计算折扣后的评分矩阵r′的加噪后全局平均评分gavg′;
式(5)中,|r′|表示折扣后的评分矩阵r′中有效评分值的计数,r′min表示折扣后的评分矩阵r′中评分最小值,r′max表示折扣后的评分矩阵r′中评分最大值,ε3表示第三隐私预算参数,并有:
步骤2.4、利用式(7)计算折扣后的评分矩阵r′中第i个评分用户ui的加噪后平均评分uavg(i):
式(7)中,|ri|表示第i个评分用户ui的有效评分值的计数,r′min,i表示折扣后的评分矩阵r′中第i个评分用户ui的评分最小值,r′max,i表示折扣后的评分矩阵r′中第i个评分用户ui的评分最大值,β2表示添加的加噪后折扣全局平均评分的个数,ε4表示第四隐私预算参数,并有:
步骤2.5、利用式(9)计算第i个评分用户ui对第j个评分项目vj的预处理后的评分
步骤三、计算评分矩阵rn×m中用户间的相似度值,构造用户相似度矩阵sim,选取与第i个评分用户ui最相似的top-k个用户;
步骤3.1、利用式(10)计算评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux的皮尔森相似度pcc(i,x):
式(10)中,gj是评分集合g的子集,gj表示第i个评分用户ui和第x个评分用户ux都对第j个评分项目vj进行过评分,g是第i个评分用户ui和第x个评分用户ux对所有同一个项目进行过评分的集合,
步骤3.2、利用式(11)计算评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux公共评分的权重weightcom(i,x):
式(11)中,|g|表示集合g中元素的个数,tot(i,x)表示评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux进行评分的项目数量总计数;
步骤3.3、利用式(12)计算评分差异值的倒数
式(12)中,dif(i,x)表示评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux的评分差异值,exp()表示以自然常数e为底的指数函数;
步骤3.4、利用式(13)计算评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux的相似度sim(i,x):
步骤3.5、根据所述相似度sim(i,x),构造用户相似度矩阵sim={sim(i,x)|i=1,2,...,n;x=1,2,...,n};
步骤3.6、从用户相似度矩阵sim中选取最高的前k个相似度值对应的用户组成当前第i个评分用户ui最相似的top-k个用户集合t(i);
步骤四、集成协同过滤和矩阵分解方法,对预处理后的评分矩阵
步骤4.1、参数定义:平衡系数为α,学习率参数为γ,规则参数为λ,潜在因子数为d,梯度下降算法的最大迭代次数为tmax,当前梯度下降算法的迭代次数为t,预测误差的上界为errormax,第五隐私预算参数为ε5;
步骤4.2、利用式(15)最小化损失函数l(pn×d,qm×d),迭代更新得到用户因子矩阵pn×d和项目因子矩阵qm×d:
式(14)中,||pi||表示用户因子矩阵pn×d的第i行元素的范数,||qi||表示项目因子矩阵qm×d的第j行元素的范数,
步骤4.3、初始化t=1,并随机初始化用户因子矩阵
步骤4.4、利用式(15)得到第t次迭代中第i个用户ui对第j个项目vj的预测评分
式(15)中,pi(t)表示第t次迭代的用户因子矩阵
步骤4.5、利用式(16)得到第t次迭代中随机生成的扰动噪声向量
式(16)中,
骤4.6、利用式(17)得到第t次迭代中第i个用户ui对第j个项目vj的加噪后的预测评分误差
步骤4.7、利用式(18)得到进行限定处理后预测误差
步骤4.8、利用式(19)对第t次迭代中的用户因子矩阵
步骤4.9、利用式(20)对第t次迭代中的项目因子矩阵
步骤4.10、重复上述步骤4.4到步骤4.9,得到第t+1次迭代用户因子矩阵
步骤4.11、将t+1赋值给t后,判断迭代次数t>tmax是否成立,如果成立,则表示梯度下降算法的迭代完成,并得到最终的用户因子矩阵pn×d和项目因子矩阵qm×d即为第tmax次迭代得到的用户因子矩阵
步骤4.12、利用式(21)计算预测评分矩阵
相对于现有的推荐系统隐私保护方案,本发明的有益效果体现在:
1、本发明所使用的推荐方法是一种基于差分隐私技术,并构建了一种新的集成推荐方法,主要在两个阶段(预处理、矩阵分解阶段)使用满足了差分隐私机制的拉普拉斯噪声扰动,根据差分隐私序列组合定理(两阶段共含五个部分的隐私预算分配),本发明提出的集成推荐方法在理论上满足ε-差分隐私,从而实现了对用户数据隐私的安全保护。
2、本发明提出的新型集成推荐方法,在满足了差分隐私加噪的基础上,通过构建平衡参数,集成了用户协同过滤方法和矩阵分解方法。该方法充分利用评分矩阵的局部信息和全局信息,同时兼顾了传统基于用户协同过滤方法所适应的稠密集和矩阵分解所适应的稀疏集,从而实现了更高精度地评分预测。
3、本发明所使用到的预处理机制,主要有全局平均、项目平均、折扣全局平均和用户平均四个阶段的预处理操作,可以有效地利用评分矩阵信息来预测空白评分,从而提高了集成推荐方法的推荐精度。
4、本发明将差分隐私技术和集成推荐方法相结合,可以在保证用户数据隐私安全的同时,还能保证有较好的推荐效果,实验表明集成推荐方法的预测精度要高于单一使用用户协同过滤推荐方法或者矩阵分解推荐方法,具有较高的实用性。本发明可以为用户提供更加安全且有效的推荐服务,也会吸引更多潜在用户来享受这一推荐服务,进一步提升相关服务产品市场推广的商业价值。
附图说明
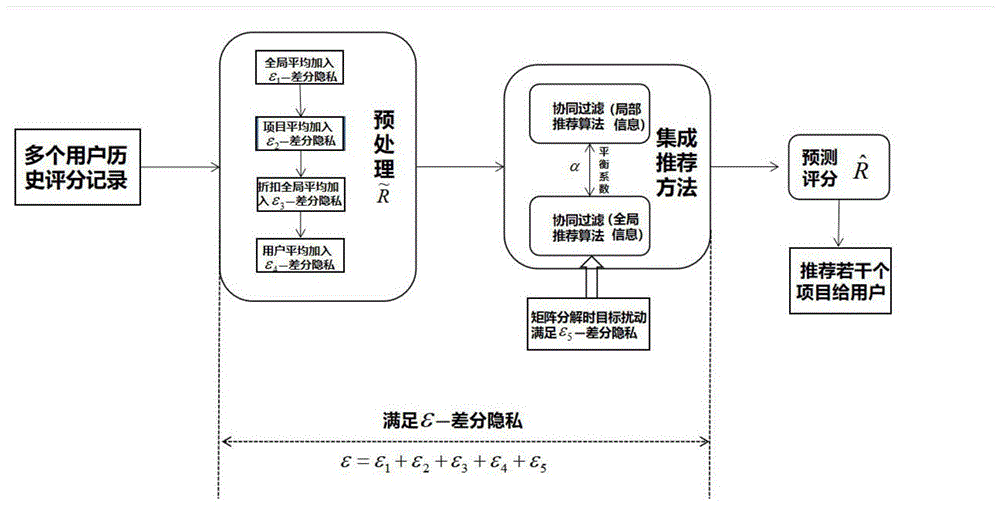
图1为本发明的模型示意图;
图2为本发明的几个主要实施步骤的流程图。
具体实施方式
本实施例中,如图1和图2所示,一种基于差分隐私保护的集成推荐方法是按如下步骤进行:
步骤一、从评分网站上获取用户对项目的历史评分数据集:
评分数据集上有n个用户,记为user={u1,u2,...,ui,...,un},其中ui表示第i个评分用户,1≤i≤n;评分数据集上有m个项目,记为item={v1,v2,...,vj,...,vm},其中vj表示第j个评分项目,1≤j≤m;将评分数据集中第i个用户ui对第j个项目vj的评分数据记为rij,从而得到所有用户对所有项目的评分数据所组成的评分矩阵rn×m;
步骤二、对评分数据集加入部分隐私预算的拉普拉斯噪声,得到预处理后的评分矩阵
步骤2.1、利用式(1)计算评分矩阵rn×m加噪后的全局平均gavg:
式(1)中,|r|表示评分矩阵rn×m中有效评分值的计数,评分矩阵rn×m包含有很多空白评分数据,即|r|的值远小于n×m,rmin表示评分矩阵rn×m中的评分最小值,rmax表示评分矩阵rn×m中的评分最大值,ε1表示第一隐私预算参数,laplace()表示拉普拉斯噪声的随机生成函数,并有:
注意:式(1)会涉及到敏感度的计算,此处用的是全局敏感度δr=rmax-rmin;
式(3)表示μ=0拉普拉斯分布的密度函数:
式(3)中b表示变量x的尺度参数,由于μ=0,上述拉普拉斯分布的方差为σ2=2b2,而b=δr/ε1得到;
隐私预算ε1的值是可以调整的,但需要控制好安全性和可用性的平衡,因为隐私预算分配过大会导致安全性降低,而隐私预算分配过小将会导致噪声过大,破坏数据的可用性;
式(2)中对加噪后的全局平均进行限定处理,可以防止噪声量添加过大超出评分范围,能提高评分数据的可用性;
步骤2.2、利用式(4)计算评分矩阵rn×m中第j个评分项目vj加噪后的平均评分iavg(j):
式(4)中,|rj|表示第j个评分项目vj中有效评分值的计数,rmin,j表示评分矩阵rn×m中第j个评分项目vj的评分最小值,rmax,j表示评分矩阵rn×m中第j个评分项目vj的评分最大值,β1表示添加的加噪后全局平均评分的个数,ε2表示第二隐私预算参数,并有:
注意:式(4)中添加了β1个加噪的全局平均值,是为了稳定项目平均值,因为有些项目可能只有极少数用户对其评分,而这些极少数用户的评分信息只能代表他们自己偏好,不能代表该项目的平均;
步骤2.3、将评分矩阵rn×m中的所有评分数据减去加噪后相应评分项目的平均评分后,得到折扣后的评分矩阵为r′={r′ij|i=1,2,…,n;j=1,2,…,m};r′ij表示折扣后评分矩阵r′中第i个用户ui对第j个项目vj的评分值,且r′ij=rij-iavg(j);
利用式(6)计算折扣后的评分矩阵r′的加噪后全局平均评分gavg′;
式(6)中,|r′|表示折扣后的评分矩阵r′中有效评分值的计数,r′min表示折扣后的评分矩阵r′中评分最小值,r′max表示折扣后的评分矩阵r′中评分最大值,ε3表示第三隐私预算参数,并有:
步骤2.4、利用式(8)计算折扣后的评分矩阵r′中第i个评分用户ui的加噪后平均评分uavg(i):
式(8)中,|ri|表示第i个评分用户ui的有效评分值的计数,r′min,i表示折扣后的评分矩阵r′中第i个评分用户ui的评分最小值,r′max,i表示折扣后的评分矩阵r′中第i个评分用户ui的评分最大值,β2表示添加的加噪后折扣全局平均评分的个数,加入β2个折扣后全局平均是为了稳定用户平均评分,ε4表示第四隐私预算参数,并有:
步骤2.5、利用式(10)计算第i个评分用户ui对第j个评分项目vj的预处理后的评分
步骤三、计算评分矩阵rn×m中用户间的相似度值,构造用户相似度矩阵sim,选取与第i个评分用户ui最相似的top-k个用户;
步骤3.1、利用式(11)计算评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux的皮尔森相似度pcc(i,x):
式(11)中,gj是评分集合g的子集,gj表示第i个评分用户ui和第x个评分用户ux都对第j个评分项目vj进行过评分,g是第i个评分用户ui和第x个评分用户ux对所有同一个项目进行过评分的集合,
注意:皮尔森相似度反映了两个变量之间的相关程度,它的取值在[-1,1]之间。当两个变量的线性关系增强时,其相关系数值趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,其相关系数值大于0;如果一个变量增大,另一个变量减小,表明它们之间是负相关的,其相关系数值小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
步骤3.2、利用式(12)计算评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux公共评分的权重weightcom(i,x):
式(12)中,|g|表示集合g中元素的个数,tot(i,x)表示评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux进行评分的项目数量总计数;本步骤考虑到公共评分对计算用户相似度的影响,两个用户的公共评分的个数越多,那么他们的相似度就越高;
步骤3.3、利用式(13)计算评分差异值的倒数
式(13)中,dif(i,x)表示评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux的评分差异值,exp()表示以自然常数e为底的指数函数;本步骤考虑到两个用户之间的评分差异性,在上式中通过减去所有评分项目的用户平均值,以减弱用户评分差异的影响,并利用用户评分差异值的倒数来表示用户之间的相似度;
步骤3.4、利用式(14)计算评分矩阵rn×m中第i个评分用户ui和第x个评分用户ux的相似度sim(i,x):
在本步骤中,通过将皮尔森相关系数pcc(i,x)、公共评分权重weightcom(i,x)和用户评分差异值dif(i,x)结合在一起来计算用户间相似度sim(i,x);
步骤3.5、利用相似度sim(i,x),构造用户相似度矩阵sim={sim(i,x)|i=1,2,...,n;x=1,2,...,n};对于基于用户的推荐系统中,皮尔森相似度比余弦相似度方法推荐效果更好,而在基于物品的推荐技术中,余弦相似度比皮尔森相似度表现要好;
步骤3.6、从用户相似度矩阵sim中选取最高的前k个相似度值对应的用户组成当前第i个评分用户ui最相似的top-k个用户集合t(i);
步骤四、利用集成推荐方法对预处理后的评分矩阵
步骤4.1、参数定义:平衡系数α,学习率参数为γ,规则参数为λ,潜在因子数为d,梯度下降算法的最大迭代次数为tmax,当前梯度下降算法的迭代次数为t,预测误差的上界为errormax,第五隐私预算参数为ε5;梯度下降算法是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。学习率参数γ是控制梯度下降幅度的参数,又称步长,学习率设置过大会阻碍收敛并导致损失函数在最小值附近波动甚至发散;学习率过小又会导致收敛速度缓慢,尤其是在迭代后期,当梯度变动很小的时候,整个收敛过程会变得很缓慢。
步骤4.2、利用式(15)最小化损失函数l(pn×d,qm×d),迭代更新得到用户因子矩阵pn×d和项目因子矩阵qm×d:
式(15)中,||pi||表示用户因子矩阵pn×d的第i行元素的范数,||qi||表示项目因子矩阵qm×d的第j行元素的范数,
步骤4.3、进行初始化处理,令t=1,并随机初始化用户因子矩阵
步骤4.4、利用式(16)得到第t次迭代中第i个用户ui对第j个项目vj的预测评分
式(16)中,
步骤4.5、利用式(17)得到第t次迭代中随机生成的扰动噪声
式(17)中,
骤4.6、利用式(18)得到第t次迭代中第i个用户ui对第j个项目vj的加噪后的预测评分误差
步骤4.7、利用式(19)得到进行限定处理后预测误差
步骤4.8、利用式(20)对第t次迭代中的用户因子矩阵
步骤4.9、利用式(21)对第t次迭代中的项目因子矩阵
步骤4.10、重复上述步骤4.4到步骤4.9,可以得到第t+1次迭代用户因子矩阵
步骤4.11、将t+1赋值给t后,判断迭代次数t>tmax是否成立,如果成立,则表示梯度下降算法的迭代完成,并得到最终的用户因子矩阵pn×d和项目因子矩阵qm×d即为第tmax次迭代得到的用户因子矩阵
步骤4.12、利用式(22)计算预测评分矩阵
- 还没有人留言评论。精彩留言会获得点赞!