一种RFID多阅读器协调方法与流程
本发明涉及物联网rfid技术应用领域,特别是一种rfid多阅读器协调方法。
背景技术:
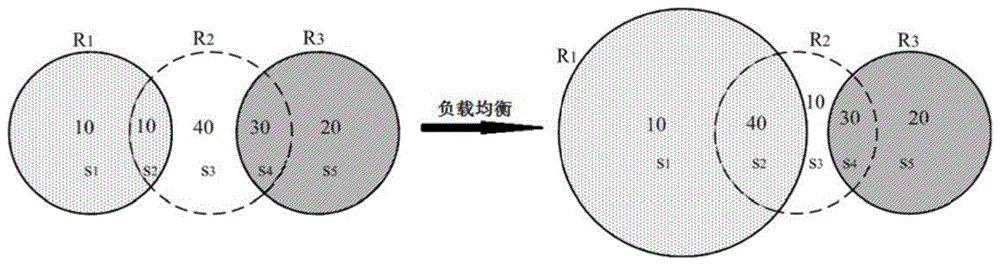
:rfid(radiofrequencyidentification,射频识别)作为一种非接触式自动识别技术,能够进行有效的信息感知和收集,是物联网的重要支撑技术。rfid技术具有非接触式自动识别、低功耗低成本、高可靠性、识别精确高效且具有一定的计算和存储能力等优点,已广泛应用于供应链监控、目标跟踪、定位、仓库管理等,rfid产品已融入人们的生活并成功地应用于各个领域。例如,ferragamo在其产品中嵌入了rfid标签,实现追踪产品以对抗假货;zara等零售商利用rfid标签来进行库存管理;村田制作所将rfid标签应用在手术器械、小物品追溯等诸多应用中来进行高效、安全的管理;瑞章用rfid实现制程管控,rfid实现自动化数据采集为生产大数据分析提供了基础。rfid技术作为物联网时代的重要支撑技术,正在发挥着它的重大作用。rfid系统一般由rfid阅读器、标签和后台服务器组成,标签由芯片和标签天线组成,每个标签芯片都含有一个唯一的识别码,即标签id,能够唯一的标识标签,标签还可计算、存储一定的数据信息,通常可将标签粘贴在物体上来标识物体,获取物体的相关信息。阅读器是用来读写标签的,通过无线信道发送射频信号来无接触自动识别标签。阅读器和标签通过无线信号传输信息,通信过程可以描述为:阅读器先通过其天线发送查询命令,标签的天线接收到无线信号后做出相应的响应,阅读器利用其天线扫描获取标签的返回信号,并传输给后台服务器处理。rfid的相关研究主要有标签识别、标签估计、信息收集、标签轮询(获取指定集合内的标签信息)、rfid定位、移动行为识别等。rfid系统的一个关键性能指标就是标签读取吞吐量,即单位时间能读取的标签数,而rfid系统中存在信号干扰问题,这会降低系统的识别效率。为了快速收集标签id并提高系统吞吐量,研究人员设计了有效的防冲突协议(也称为标签识别协议),以避免在两个或多个标签同时向阅读器传输信号时发生的标签-标签冲突,由于标签硬件条件的限制,标签之间不能通信,因此这些协议尝试安排标签在不同的时隙中响应。如经典的基于aloha的防冲突算法让标签以概率参加响应,阅读器广播帧长和随机种子,标签根据其id利用哈希函数随机选择一个时隙回复,任一时隙只有一个标签响应时阅读器才能成功识别该标签。由于射频识别的通信范围有限,单个rfid阅读器只能收集其询问区域内的标签,而大型rfid系统(如大型仓库或超市)中,为了达到监控区域的全覆盖,人们需要部署多个阅读器来协同工作以收集系统中所有的标签,多个阅读器把监控区域划分为不同的子区域,每个子区域是指被相同的阅读器集覆盖的独立物理区域。每个rfid阅读器都有一个询问区域和干扰区域,询问区域指的是在这个区域内阅读器能够与标签成功地相互通信,干扰区域是指阅读器的信号会干扰在该区域内的其他阅读器和标签。阅读器的询问区域取决于许多因素,包括天线、障碍物的存在、标签特性等。多阅读器系统中还存在阅读器引起的冲突,分为阅读器-标签冲突和阅读器-阅读器冲突。阅读器-标签冲突发生在当一个阅读器在另一个阅读器的干扰区域内时,一个阅读器的信号会干扰另一个阅读器接收标签向其发送的信号。阅读器-标签冲突可以通过安排邻近的阅读器在不同的信道工作,或者在不同的时间激活。阅读器-阅读器冲突发生在两个询问区域有重叠的阅读器同时激活时,在重叠区域的标签不能区分来自两个阅读器的信号,导致重叠区域的标签不能被成功询问。这种冲突只能通过安排有冲突的阅读器不同时激活来避免。为了提高多阅读器系统rfid系统的读取吞吐量,现有的研究考虑怎样更有效的安排调度,设计调度策略将多个阅读器分为多轮执行,每轮激活一个被选择的阅读器集,通过减少阅读器的冲突来提高读取效率。而在大型的rfid系统中,如大型仓库中,存储了各式各样的物品,每个物品附有一个标签,通常阅读器部署后位置固定,而物品的大小尺寸和分布密度各不相同,且仓库物品时进时出,所以标签的分布是变化且不均匀的;这就使得每个阅读器下覆盖的标签数目是变化的,各个阅读器的标签数可能有很大差别。因此同一轮调度的阅读器的负载(即阅读器询问区域内的标签数)可能很不均衡,导致各阅读器询问标签的时间可能有很大差别,标签数多的阅读器需要较长的执行时间,而负载少的阅读器很快就能执行结束而处于空等状态,这就使得系统总的读取效率不高。针对多阅读器系统读取吞吐量的问题,现有的研究都只考虑怎样更有效的安排调度,并没有考虑在每一轮调度时阅读器的负载不均衡对标签读取效率的影响。如何解决阅读器负载不均衡的问题,即如何设计出高效的方法来协调多个阅读器的负载使其达到均衡状态,是进一步提高多阅读器rfid系统的标签读取吞吐量的关键。技术实现要素:本发明所要解决的技术问题是,针对现有技术不足,提供一种rfid多阅读器协调方法,提高rfid标签读取吞吐量。为解决上述技术问题,本发明所采用的技术方案是:一种rfid多阅读器协调方法,包括以下步骤:1)确定每一轮次需调整的阅读器数量,即根据现有的基于图着色的阅读器调度算法,确定每一轮次需要调整的阅读器;2)对于当前轮次,获得该轮次阅读器的最大可调半径和最小可调半径,将目标负载,即目标值设置为当前轮次中阅读器的最大标签数;3)调整当前轮次任一阅读器的询问区域半径,若调整后该阅读器询问区域内的标签数,即负载仍未达到目标值,则将该阅读器的询问区域半径设置为最大调整半径,同时更新当前轮次其余阅读器半径的最大可调半径;所述最大调整半径是指阅读器在最大可调半径和最小可调半径限制下最多能调整到的半径值;4)重复步骤3),直至该轮次所有阅读器的询问区域半径都被调整一次;5)若当前轮次阅读器的最大负载和最小负载差值大于阈值,则将目标值设定为当前轮次最大标签数和次大标签数的平均值,返回步骤3),直至不平衡率不再下降,或者达到负载均衡;6)将当前轮次各阅读器的负载值调整为目标值,并更新各子区域的标签密度;7)重复步骤2)~步骤6),直至所有轮次执行完毕。步骤2)中,阅读器的最大可调半径ri_max=min{rmax,min{dij-rj}};其中,rmax是阅读器最大功率时的半径(最大功率指的是阅读器功率的极限值,是由阅读器的种类等产品信息决定的,这里认为所用的阅读器都是一样的,因此最大功率也是统一的),min{dij-rj}是同一轮次调度的其余阅读器与当前阅读器ri询问区域边界之间的最小距离,dij是ri与rj之间的距离,rj是与ri同一轮次调度的阅读器;i=1,2,......,m;j=1,2,......,m;m为阅读器的数量。阅读器的最小可调半径的确定方法包括:1)对于内部阅读器,求目标阅读器的相邻阅读器之间的交点,并保留位于目标阅读器询问区域内的交点;对于边界阅读器,求目标阅读器的相邻阅读器之间的交点,并保留位于目标阅读器询问区域内的交点,并获得边界阅读器与监控区域边界之间的交点;2)判断保留下来的交点是否有效地构成了单覆盖子区域,若构成,则目标阅读器ri的最小可调半径ri_min就是有效交点与目标阅读器ri之间的最大距离;所述有效的交点是指该交点只位于目标阅读器的询问区域内。步骤2)中,各轮次调整先后顺序的决定规则为:优先选择调整具有最多阅读器的轮次;对于阅读器数量相同的轮次,选择负载差异最小的轮次。步骤3)中,调整当前轮次任一阅读器的询问区域半径的具体实现过程包括:1)将每个子区域的标签数设为均匀分布的,为每个阅读器维护一个相邻子区域集,所述相邻子区域集由当阅读器改变询问半径时面积变化的子区域(即当阅读器改变询问半径时会产生影响的子区域,如图3(a)中,r1在扩大前的相邻子区域集为{s5,s6,s13},也就是如果r1扩大半径到临界点a之前,则会被影响的子区域就是s5,s6,s13,这些子区域的面积大小在r1扩大半径后会被改变,所含标签可能会被归入r1)组成;找到位于调整前半径和最大或最小可调半径之间的临界点,按照临界点与目标阅读器ri之间的距离,将临界点由近到远或从远至近排序,每经过一个临界点变化的子区域集就会改变,每次半径达到一个临界点时,更新其相邻子区域集;2)根据相应的相邻子区域集,计算当半径调整到各个临界点到圆心的距离时,能增加或减少的标签数{δn1,...,δnk},k为临界点数;δrk是第k个临界点到圆心的距离与调整前半径的差值;判断目标标签数ntarget与当前标签数的差值δn在哪两个临界点之间,若δnk-1<δn<δnk,则半径调整到第(k-1)个临界点和第k个临界点之间,再由得到从第k-1个临界点到第k个临界点的过程中,每变化单位距离改变的标签数,则需要调整到ntarget时的半径差(半径差指的是满足目标标签数时半径需要调整的程度(即大小))由下述公式求得:其中,加号和减号分别对应询问半径扩大或缩小的情况;δr是满足目标标签数时半径需要调整的大小;δrk-1和δrk分别是第k-1个和第k个临界点到圆心的距离与调整前半径的差值;δnk-1和δnk是当半径调整到第k-1个和第k个临界点到圆心的距离时,能增加或减少的标签数;δn是目标标签数ntarget与当前标签数,即调整前标签数的差值。步骤3)中,先调整询问半径需要缩小的阅读器,然后根据相邻标签密度由高到低将需要增大的阅读器半径扩大;阅读器的相邻标签密度定义为与该阅读器有重叠相交的阅读器的标签密度的平均值。步骤4)中,达到负载均衡的判断标准是:对于任意一轮次调度,如果当前阅读器的最大负载和最小负载的差值小于或等于阈值θ,则该轮达到负载均衡;;不平衡率ratio定义为,对于任意第1轮,不平衡率nl_max和nl_sum分别为当前轮次的最大标签数和总标签数。不平衡率不再下降指的是这一次调整后的不平衡率不小于这次调整前的不平衡率,即ratiol_af≥ratiol_bf。步骤6)中,更新子区域的标签密度的具体实现过程包括:当阅读器的半径增大到第k个临界点时,标签密度更新为:当阅读器缩小询问半径时,标签密度更新为或其中,sb是到第k个临界点时阅读器的相邻子区域集中面积不为0的任一子区域;sb是到第k个临界点时阅读器的相邻子区域集中面积不为0的任一子区域;是阅读器调整前子区域sb的标签数目;是计算得到的阅读器调整前后sb标签数的差值,即sb调整前的标签密度和调整前后变化的面积的乘积是所有sb引起的总的标签数变化;ndev=nreal-ntarget,是阅读器收到的实际标签数nreal与计算所得的目标标签数的误差ndev;是阅读器调整后sb的子区域面积;sc是初始相邻子区域集中子区域的面积变化不等于其对应内相邻子区sc_p的面积的任一子区域;sc_p是与sc由相同的两个交点构成的同一段弧构成的在目标阅读器内的子区域;sd是到第k个临界点时阅读器的相邻子区域集与初始相邻子区域集的差集中变化的面积不等于0的任一子区域,即且ndev和上述ndev的意义相同;是阅读器调整后sd的标签数,即调整后的面积和标签密度的乘积;δnsum是所有sc和sd这些子区域的标签数变化的总和。与现有技术相比,本发明所具有的有益效果为:本发明从多阅读器负载不均衡的问题出发,从负载均衡的角度提高系统读取吞吐量,通过调整阅读器的功率进而灵活控制阅读器的覆盖范围,让阅读器动态地协调均衡,实现多个阅读器对rfid标签的均匀覆盖,并且在调整过程中阅读器标签数量的变化通过数学推理而得,不需要额外估计标签的时间,即不会带来额外的时间开销。该方法对系统效率的提升的是显著的,且易于实施,有一定的通用性,很有应用前景。附图说明图1为本发明基本思想的简单示例图;图2为本发明系统示意图;图3为本发明调整询问半径、更新负载的示意图;图3(a)为阅读器扩大询问半径时的示意图;图3(b)为阅读器缩小询问半径时的示意图;图4为本发明在阅读器规则部署时,不同系统规模和标签分布下,两种方法执行时间和吞吐量的情况;图4(a)为阅读器规则分布在小型规模系统时方法的执行时间和吞吐量的情况;图4(b)为阅读器规则分布在中等规模系统时方法的执行时间和吞吐量的情况;图4(c)为阅读器规则分布在大型规模系统时方法的执行时间和吞吐量的情况;图5为本发明在阅读器随机部署时,不同系统规模和标签分布下,两种方法执行时间和吞吐量的情况。图5(a)为阅读器随机分布在小型规模系统时方法的执行时间和吞吐量的情况;图5(b)为阅读器随机分布在中等规模系统时方法的执行时间和吞吐量的情况;图5(c)为阅读器随机分布在大型规模系统时方法的执行时间和吞吐量的情况;具体实施方式本发明通过调整阅读器的功率来协调各阅读器的询问区域,以每一轮为协调的单位,在保证监控区域全覆盖和同轮调度的阅读器不发生冲突的基础上,使每轮阅读器都能实现负载均衡。对于任何一轮,首先让阅读器动态地协调一个最优目标标签数nl_target,该轮中的所有阅读器都应该调整为这个目标标签数从而实现负载均衡。在协调过程中,以及最终每个阅读器调整为目标标签数量的过程,本发明设计一种计算方法,通过计算变化的子区域面积乘以标签密度来得到变化的标签数从而满足ntarget,进而得到目标半径。本发明方法的具体步骤是:1)步骤1:根据系统部署得到系统的初始状态,包括阅读器的位置及覆盖范围,利用阅读器调度算法给定阅读器初始调度轮次,利用现有标签估计协议得到各子区域的标签数,根据子区域归属信息得到各阅读器的负载值;2)步骤2:得到各子区域的面积从而计算变化的标签数及标签密度:将多阅读器询问区域的重叠问题建模为一个多圆重叠问题,每个阅读器的询问区域用一个圆的方程表示。如ri的方程是xi2+yi2=ri2,xi和yi是ri的坐标,询问半径为ri。由于每个子区域由几段圆弧组成,所以用一个方程组表示每个子区域。对于任一子区域sv,若构成sv的有圆弧中ri的圆弧,则将ri的方程加入到sv的方程组中,若是在ri外的子区域,则方程为xi2+yi2≥ri2,反之,则为xi2+yi2≤ri2。子区域由其方程组中各方程对应区域的交集构成,则各子区域的面积就可以通过其方程组求得。对于任一子区域,先求出由子区域顶点构成的多边形的面积p是构成子区域的多边形的顶点的数量。xi和yi是顶点的坐标,可以由子区域的方程组求得。然后再加上或减去各圆弧与其对应弦之间的面积即可,该面积可由交点坐标,圆心、半径简单的求得。3)步骤3:获得各阅读器的最大可调半径:为每个阅读器定义了一个最大可调半径,来限制阅读器询问区域的最大可调范围,用r1_max,…,rm_max来表示,ri_max=min{rmax,min{dij-rj}},其中rmax是阅读器最大功率时的半径,min{dij-rj}是同一轮调度的其余阅读器与ri询问区域边界之间的最小距离,dij是ri与rj之间的距离,rj是与ri同一轮调度的阅读器。也就是说,ri_max使阅读器的询问区域只能扩展到与同时激活的阅读器的询问区域不相交的点。4)步骤4:获得各阅读器的最小可调半径:阅读器的最小可调半径被定义为该阅读器的询问半径的最小可调范围,分别表示为r1_min,...,rm_min。定义最小可调半径是用来保证负载均衡后没有盲区。也就是说,阅读器的询问半径不能小于其最小可调半径,来保证其单覆盖子区域的完全覆盖。具体方法为:i.根据阅读器的地理位置分为内部阅读器和边界阅读器。对于内部阅读器,先求目标阅读器的相邻阅读器之间的交点,并保留位于目标阅读器询问区域内的交点。ii.进一步判断保留下来的这些交点是否有效地构成了单覆盖子区域。有效的交点意味着它只位于目标阅读器的询问区域内,通过这种方法排除无效的交点,最终得到了约束单覆盖子区域的点。对于边界阅读器,除了第一步计算相邻阅读器之间的交点外,还需要得到边界阅读器与监控区域边界之间的交点。iii.在得到构成单覆盖子区域的有效交点后,ri的最小可调半径ri_min就是这些有效交点与目标阅读器ri之间的最大距离。5)步骤5:估计得到需要调整到的半径大小:将每个子区域的标签数看作是均匀分布的,而子区域之间的标签密度是不同的。各个子区域的标签密度表示为是sv的面积。由于子区域具有不同的标签密度,且半径扩大或缩小的程度不同所改变的子区域也不同,将任意阅读器ri的调整半径估计过程分为三个步骤:i.为每个阅读器维护一个相邻子区域集,它由当阅读器改变询问半径时会变化的子区域组成。并找到位于调整前半径和最大(当阅读器需要调大时)或最小(当阅读器需要缩小时)可调半径之间的临界点,然后按距离ri从近到远(扩大半径时)或从远至近(缩小半径时)排序,每经过一个临界点变化的子区域集就会改变。因此,每次半径达到一个临界点时,就要更新其相邻子区域集。ii.根据相应的相邻子区域集,计算当半径调整到各个临界点到圆心的距离时,能增加或减少的标签数{δn1,...,δnk},k为临界点数。δrk是第k个临界点到圆心的距离与调整前半径的差值。iii.判断ntarget与当前标签数的差值δn在哪两个临界点之间。若δnk-1<δn<δnk,则半径应该调整到第(k-1)个临界点和第k个临界点之间,则再由得到从第k-1个临界点到第k个临界点的过程中,每变化单位距离改变的标签数。则需要调整到ntarget时的半径差可由下述公式求得,加号和减号分别代表询问半径扩大或缩小的情况。在步骤i中,当阅读器ri需要扩大(或减少)询问半径时,临界点分别包括:在最大可调半径内,被调整圆ri在扩大过程中与其余圆的切点;落在被调整圆ri外并在最大可调范围内的其余圆之间的交点。在最小可调半径外,被调整圆ri在缩小过程中与其他圆的切点;与ri相交的各相邻阅读器之间在ri圆内的交点。在步骤i中,更新相邻子区域集的具体方法为:对于扩大半径时的情况,首先找到ri扩大前的初始相邻子区域集adj0,即子区域方程组中有xi2+yi2≥ri2构成的子区域集合;然后在扩展到第k个临界点时,相邻子区域集更新为adjk;对于adjk-1中有的子区域,更新adjk-1中各子区域的圆弧方程组中xi2+yi2≥ri2中的ri的值;如果ri与adjk-1中没有的某一子区域有交点,即ri新切入了某一子区域,则将xi2+yi2≥ri2的方程加入到该子区域的方程组中,并将该子区域添加到adjk中。对于缩小半径时的情况,首先像扩大半径时一样找到adj0,然后找到sc对应的内相邻子区域sc_p,sc_p是与sc有相同的两个交点构成的同一段弧构成的在ri内的子区域;然后将sc_p的方程组中除xi2+yi2≤ri2外的方程加入到sc的方程组中,这样来保证在ri缩小的过程中,sc的方程组能够得到完整更新。在步骤ii中,得到扩大半径时的{δn1,...,δnk}:在步骤ii中,得到ri在缩小到第k个临界点时减少了多少标签δnk:由于adj0中各子区域的区域扩大,因此密度更新为:是sc调整后的面积。6)步骤6:在上述步骤的基础上,本发明的协调均衡的方法rlb为:在调整过程中受最大可调半径和最小可调半径限制的阅读器协调均衡方法。该方法根据给定的调度以轮为单位执行,每轮只调整执行一次,在该方法中不改变阅读器的调度。最大可调半径保证同一轮调度的阅读器仍然可以同时激活,而最小可调半径保证监控区域的全覆盖。在半径可调范围的两个限制条件下,逐步协调得到最均衡的目标负载值。首先定义一个不平衡率来度量负载均衡的程度。对于第1轮不平衡率越小,负载均衡程度越高。协调均衡方法的具体步骤为:i.选择一个调度轮次进行调整:优先选择调整具有最多阅读器的轮次,其次,对于阅读器数量相同的轮次,先选择负载差异最小的轮,因为负载差异小的轮次可能更容易调整到负载均衡的状态。ii.对于被选择的该轮调度,利用步骤4获得该轮阅读器的最小可调半径,首先将目标负载设置为当前的最大标签数,根据下述阅读器的调整顺序并利用步骤5的方法依次尝试模拟调整为目标负载,在每个阅读器调整后,利用步骤3更新其余同轮阅读器的最大可调半径;阅读器调整顺序的规则:为达到更好的均衡效率,先调整询问半径需要缩小的阅读器,然后根据相邻标签密度由高到低将需要增大的阅读器半径扩大。iii.如果在第ii步的调整后不均衡,则迭代地将目标标签数设置为当前的最大和第二大负载的平均值(当前指的是在上一次调整后的值),直到不平衡率不再下降(即ratiol_af≥ratiol_bf)或者该轮达到负载均衡,则可以确定该轮的最终目标负载为当前更新后的最大负载;iv.将该轮各阅读器真实地调整为最终的目标负载值,并执行该轮阅读器,收集标签;v.利用步骤7更新剩余子区域的标签密度;vi.循环i到v,直到所有调度轮次完成;7)步骤7:更新子区域标签密度:阅读器收到的实际标签数nreal可能与我们的目标ntarget有一定的误差ndev,ndev=nreal-ntarget。因此,我们使用ndev来更新剩余的变化了的相邻子区域的标签密度。一方面,当阅读器的半径增大到第k个临界点时,密度更新为:另一方面,当阅读器缩小询问半径时,目以及且密度更新分别为:在rlb方法的基础上,本发明还提出一种不受最小可调半径限制的完全的负载均衡方法clb,该方法与rlb不同的是不存在最小可调半径的概念,即在阅读器缩小时可缩小的程度不受限制,这样就能够保证每一轮协调到最后都能达到完全的负载均衡。其基本思想是,当所有阅读器至少在不小于初始询问半径下执行一次时,系统就完成了整个识别任务,没有盲区。为了实现每一轮的完全负载均衡,clb同样逐步协调每一轮的负载直到完全均衡,为了满足监控区域的全覆盖,clb方法让阅读器在不同的询问半径下多次激活,直到所有阅读器在不小于初始半径下至少执行一次;clb仍然使用最大可调半径的限制,以满足相同调度轮次的阅读器仍然可以同时工作。整个步骤是:分为多批次调整执行,每个批次包含所有未完成的调度轮次,即存在未完成阅读器的轮次,未完成阅读器是指此前批次调整后询问半径小于初始半径的阅读器;所有未完成的阅读器的半径在新一批次的调整前均重新初始化为初始半径,每个批次均按照原始调度轮次依次按rlb的步骤调整,不同的是调整时不受最小可调半径的限制,对于任意一轮调度,在达到负载均衡之后,该方法考虑是否可以添加一些额外的阅读器,作为本轮可顺便捎带的识别,即与协调后的本轮阅读器不发生冲突的阅读器也可加入本轮执行。直到所有阅读器均在不小于初始半径下执行了一次,即系统监控区域的标签能够被完全读取,则整个调整及执行结束。图1描述了一个简单的示例来解释负载均衡的概念。为了便于说明,此图中仅显示了三个阅读器,但实际上,周围还有其他阅读器和标签。用第一轮a1={r1,r3}来展示负载均衡带来的效率提升。在左图中,r1和r3分别需要收集20个和50个标签,而r3的负载决定了本轮调度需要读取50个标签的时间。因此,询问一个标签的成本为(50+20)/50=0.71个标签时间。如果此时增加r1的询问半径,使它的负载变成50,如图2的右侧。在这种情况下,识别一个标签仅需要(50+20)/50=0.5个标签时间,这明显提高了读取吞吐量。图2描述的是由9个阅读器覆盖的监控区域,并且根据着色安排了调度。阅读器被安排为4轮,以第一轮a1={r1,r3,r7,r9}为例,其负载分别为100、500、400、200,在这一轮中需要500个标签时间才能读取1200个标签。如果调整阅读器的询问半径,假设将目标设置为平均值300,即扩大r1和r9的询问半径,同时减小r3和r7的询问区域,以使它们的负载全部变为300;则这一轮只需要300个标签时间就可以查询1200个标签,节省了200个标签时间,显著提高了标签读取吞吐量。在步骤4中所述单覆盖子区域如图2中所示,r5的单覆盖子区域是由(a,b,c,d)组成的区域,同样,r3的单覆盖子区域是由(e,f,g,h)包围的区域;对于r5,r1和r4的交点p不是r5的有效交点,因为p也位于r2的询问区域内;对于边界阅读器r3,在判断有效交点时还需要考虑交点h、g、f。图3描述的是扩大和缩小阅读器询问半径时,计算面积和负载变化的示意图,步骤2,5,7均可参考图3。步骤2中描述的子区域的方程组,如图3(a)的实线部分中,子区域s1的方程组表示为:对于步骤5中所述,如在图3(a)中,当r1扩大时,临界点是{a,b,c,d,e},当r5缩小半径时,临界点是{f,g,h,i}。r1在扩大前的adj0={s5,s6,s13},当到达第3个临界点c时adj3={s5,s6,s13,s7,s14}。图3(b)中假设在r1和r3已经结束调度的情况下,缩小r5的询问半径,对于步骤5中所述,adj0={s5,s13},s5_p为s8s13_p为s14。在实验中,使用图的着色原理来安排多个阅读器的调度,并用动态帧时隙aloha协议来识别标签。通过指定系统监控区域的大小来控制阅读器的数量,我们考虑面积分别为55×55、110×110、160×160的三种系统规模,分别对应于小型,中型和大型rfid系统。对于每种规模,考虑两种类型的阅读器部署:规则部署(以网格方式部署的阅读器)和随机部署(随机分布的阅读器)。详细参数设置如表1所示,共6种场景。表1规模阅读器规则分布个数阅读器随机分布个数标签数小(55×55)1626(平均)5000中等(110×110)6492(平均)20000大(160×160)144186(平均)48000在实验中,对于每种场景,改变标签分布,观察标签分布的不均匀程度对均衡方法的影响。考虑标签分布遵循随机均匀分布和正态分布norm(μ,σ),其中μ设置为系统大小的一半,σ的设置决定了标签不均匀的程度,这里将σ设置为监视区域大小的1/2、1/3、1/4,分别对应于低,中等和高不均匀程度。图4显示了阅读器规则部署在三种不同规模的场景下的执行时间和吞吐量。如图4(a)所示,在小型系统中规则部署了16个阅读器,可以看到,当标签相对均匀地分布在该区域时,rlb和clb能够提高时间效率和读取吞吐量,随着标签分布不均匀程度的增加,执行时间和吞吐量的性能得到明显提高。在标签分布不均匀的情况下,rlb和clb分别能减少了30%和45%的执行时间,标签读取吞吐量分别提高了44%和81%。当系统规模增加时情况类似,如图4(b)和图4(c)所示。图5描述了阅读器随机部署在三种系统规模下的性能情况,如图5(b),阅读器随机部署在110×110的中等规模的区域中。可以看出,rlb和clb算法在标签均匀和不均匀分布时均能很好地工作,标签分布的不均匀程度对性能几乎没有影响,rlb和clb方法识别标签所需的时间分别减少了17%和47%,当标签分布高度不均匀的情况下,吞吐量分别提高了20%和88%。类似地,对比图5的三个子图(a),(b)和(c)表明,这两种方法受阅读器数量影响很小。表2具体列出了四种场景下执行时间的减少程度以及系统吞吐量的提高率。此表中的四种场景分别为阅读器规则分布和随机分布、标签相对均匀分布和不均匀分布的四种组合。在这里将上述标签的均匀和低不均匀分布视为相对均匀的分布,将标签的其余两种分布视为不均匀的情况。对于每种情况,表2中的数据是不同系统规模下执行时间效率和吞吐量提高率的平均值。表2仿真结果表明本发明提出的多阅读器协调方法,可以有效地提高多阅读器rfid系统读取标签的吞吐量。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1