一种基于长短期记忆模型与目标检测算法的图像描述方法与流程
本发明属于深度学习中图像描述生成领域,具体涉及一种基于长短期记忆模型与目标检测算法的图像描述方法。
背景技术:
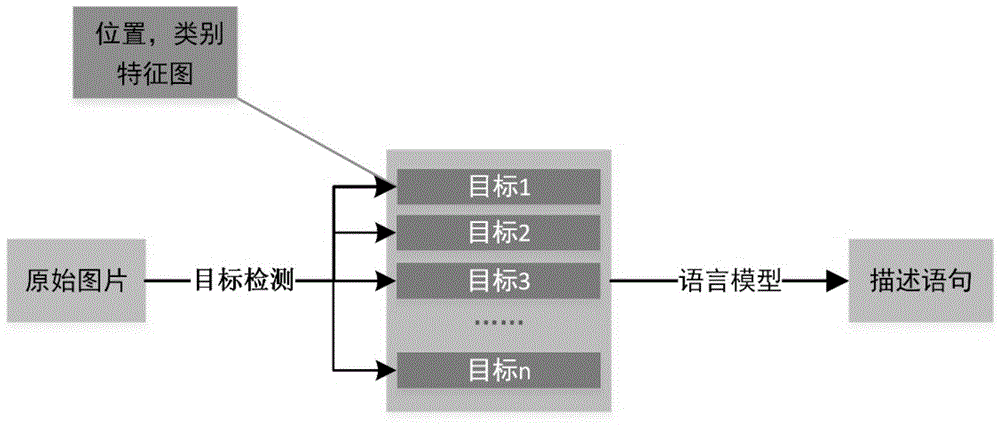
:图像是人类社会活动中最常用的信息载体,其中蕴含了丰富的信息。随着互联网技术的发展及数码设备的普及,图像数据增长迅速,使用纯人工手段对图像内容鉴别已成为一项艰难的工作。因此,如何通过计算机自动提取图像所表达的信息,已成为图像理解领域的研究热点。图像描述生成是融合了自然语言处理和计算机视觉的一项较为综合的任务,目的是将视觉图像和语言文字联系起来,通过对所输入的图像进行特征提取分析,自动生成一段关于图像内容的文字描述,图像描述生成能够完成从图像到文本信息的转换,可以应用到图像检索,机器人问答,辅助儿童教育及导盲等多个领域,对图像描述生成的研究具有重要的现实意义。所谓图像描述技术,其核心是在图像处理分析的基础上,结合计算机视觉和自然语言处理等相关理论,进而分析、理解图像内容,并以文本语义信息的形式反馈给人类。因此计算机对图像内容理解的完成不仅需要图像标注,还需要图像描述。图像描述的任务是使用自然语言处理技术分析并产生标注词,进而将生成的标注词组合为自然语言的描述语句。近年来,图像描述得到了研究界的极大兴趣,比起传统的图像标注工作,它具有更广阔的应用前景。图像描述生成克服了人类主观认识的固有限制,借助计算机软件从一幅或多幅图像序列中生成与图像内容相关的文字描述。图像描述的质量主要取决于以下两个方面:一是对图像中所包含物体及场景的识别能力;二是对物体间相互联系等信息的认知程度。按照图像描述模型的不同,图像描述的方法可以分为三类:基于模板的方法,该方法生成的图像描述依赖于模板类型,形式也较为单一;基于检索的方法,依赖于数据集中现存的描述语句,无法生成较为新颖的图像描述;基于神经网络的方法,将卷积神经网络(convolutionalneuralnetwork,cnn)与循环神经网络(recurrentneuralnetwork,rnn)相结合,使用端对端的方法训练模型,利用cnn提取特征的优势和rnn处理文字序列的优势,共同指导图像文字描述的生成。此类方法是目前比较先进的图像描述生成方法,该方法克服了图像描述生成过程中生成的句式过于简单,输出严重依赖现存语句模板的问题,可以生成语法流畅,句式复杂多变的描述语句,但与此同时,却带来了新的问题:图像描述生成的描述语句与图片的关联度有所下降。所以本发明设计了一种新的图像描述模型,在之前端对端的encoder-decoder结构的基础上融合了图像目标检测算法,使生成的描述中所有的名词均依赖于目标检测结果,从而提高了生成描述与原图像的关联度。技术实现要素:本发明的研究内容为:设计一种结合了编码器-解码器结构和图像目标检测算法的图像描述模型,并训练此模型使其可以用来生成相应的语言描述。具体结构如图1所示。模型主要通过目标检测算法提取图像中各目标区域的特征和全图的特征,然后通过循环神经网络在目标检测算法生成的所有目标区域中选择一个或多个目标区域作为描述中下一个词汇生成的依据,然后将其输入到相关语言模型中,生成相应的词汇。本发明构建的图像中文描述模型主要由以下几个部分构成:1.基于深度学习图像目标检测的编码模块;本发明选择faster-rcnn作为目标检测模型,在结构上,faster-rcnn已经将特征提取(featureextraction),候选目标区域(proposalregion)提取整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。本发明取目标检测模型faster-rcnn中roipooling层输出的各目标候选区域特征图vi及其对应的类别标签li作为对图片中含有的数据的初步提取,在下文的解码模块中,将会对提取到的数据进行解码,生成描述语句;2.基于lstm的图像目标区域选择及目标词汇生成的解码模块;模型解码模块中大量使用到了lstm(longshort-termmemory)模型。lstm是一种特殊的rnn,常见的lstm结构如图3所示,共包括3种门(gate):遗忘门f、输入门i和输出门o。在t时刻,lstm中的状态通过下列公式计算:遗忘门:ft=σ(wf[ht-1,xt]+bf)(1)输入门:it=σ(wi[ht-1,xt]+bi)(2)细胞状态:隐含层:ht=ot×tanh(ct)(5)输出层:ot=σ(wo[ht-1,xt]+bo)(6)其中ht,ht-1,ct,ct-1分别表示t时刻与t-1时刻的隐含层h与细胞状态c的值,ft,ft-1,it,it-1,ot,ot-1分别表示t时刻与t-1时刻的遗忘门f、输入门i和输出门o的值,wf,wi,wo分别表示遗忘门f、输入门i和输出门o需要利用反向传播算法来的权重(weight),wf,wi,wo分别表示遗忘门f、输入门i和输出门o需要利用反向传播算法来更新的权重,bf,bi,bo为遗忘门f、输入门i和输出门o需要利用反向传播算法来更新的偏置(bias),为更新细胞状态ct的过程中产生的中间变量,其权重wc与偏置bc同样需要使用反向传播算法来进行学习。在每一个时刻,三种门都由上一时刻的隐藏层ht-1和当前层xt通过非线性变换得到。根据遗忘门ft和输入门it,可以确定当前的细胞状态ct,进而利用输出门ot来更新隐藏层ht。解码模块主要结构如图4所示,模块主要由两个lstm模块和两个attention模块构成,两个lstm模型分别为attentionlstm和languagelstm。attentionlstm的输入包含了目标特征的平均值上一次输出的单词的编码∏t及上次languagelstm的隐含层,其具体计算过程如式7,8,9所示。其中k表示目标检测产生的所有目标候选区域特征图的数目,vi表示第i个目标的特征向量,表示目标特征的平均值,∏t为模型输出的前一时刻单词的编码,为languagelstm在t-1时刻的隐藏层值,we为该阶段反向传播算法与要学习的权重。表示本模型用到的第一个attention机制的输入。经过attentionlstm处理后,将attentionlstm的隐含层作为输入第一个attention模块中,利用调整并融合每个目标特征vi生成第一个attention模块的具体计算过程如式9,10,11,12所示。αt=softmax(at)(11)其中vi表示第i个目标的特征向量,表示attentionlstm在t时刻的隐含层向量,wva,wha是用于调整vi与的权重矩阵,需要在反向传播算法中学习得出,ai,t表示每个目标的特征向量在本次预测中对预测结果产生影响的程度,经过softmax运算后,得到一组向量αt用于融合各个目标的权重,利用αt生成t时刻模型关注的特征将attention模块中,对生成词汇影响最大的目标特征(即最大的αi,t)对应的目标类别lab作为候选名词将其进行编码,编码结果为y1,计算过程如式13,14,15所示。lab=li_max(14)y1=wordembedding(lab)(15)其中i_max为αt向量中最大值的角标,li_max为各目标特征图的类别标签中角标值为i_max的标签,y1表示li_max标签的编码。语言lstm的输入包含前面attention模块的输出和attentionlstm的隐含层计算过程如式15所示。将语言模块的输出结果输入softmax层,得到一个对应的词汇编码y2。使用模型中的第二个attention模块,利用对y1与y2进行融合,得到最终输出词汇y。具体过程如图4所示。1.损失函数本发明在训练过程中,采用的损失函数形式如式16所示。其中t表示训练集或测试集内模型输入的图片对应的描述语句的长度,表示描述语句中第1个单词到第t-1个单词的单词序列。表示训练集中的第t个单词,是解码模块的在前t-1个单词为的情况下,输出的第t个单词为的概率。通过最小化公式中的lxe(θ)函数来训练模型,模型整体流程如图5所示。附图说明图1为本发明方法的结构图。图2为本发明方法中依附的faster-rcnn结构图。图3为本发明方法所依附的lstm结构图。图4为解码器结构图。图5为整体流程图。图6为模型预测效果。具体实施方式本发明主要的内容为基于深度学习的目标检测算法在图像描述中的应用。主要内容是构建一个结合了attention机制的神经网络模型来进行图像描述,为了避免生成的描述语句与原图像关联度较低,将基于深度学习的目标检测算法与模型相结合,来提高生成的描述语句与原图像的关联度。本发明的实施主要分为以下三个步骤来进行:1.数据集的收集。本发明英文数据集选取通用图像理解/描述生成的竞赛数据集mscoco数据集,数据集中有20g左右的图片和500m左右的标签文件。标签文件标记了每个图片中个目标的精确坐标,及其英文描述,其位置精度均为小数点后两位。2.数据预处理。本发明的图片数据在预处理过程中将所有的图片缩放并裁剪为512x512大小的图片,并且使用faster-rcnn对coco数据集中的所有的图片进行目标检测;将faster-rcnn在目标检测过程中产生的roi-pooling层对图片中各目标的候选区域特征图及各目标对应的类别储存起来,作为后续训练解码器时的输入使用。本发明所采用的英文语料因为语言特征,单词有空格作为间隔,不需要进行分词处理。可以直接将文本语料进行数据建模处理,将语料字符串转换成数据向量。3.模型的实现与训练本发明采用基于python语言的深度学习框架pytorch来完成模型的构建。训练模型采用的硬件环境及软件环境如表1,表2所示。表1实验硬件环境表2实验软件环境操作系统版本ubuntu18.04.3lts内核版本linux4.15.0nvidia(r)cuda版本v9.0.176pyttorch版本0.4python版本3.6.4在解码模块训练前,神经网络中所有的偏置(bias)均初始化为0,权重(weight)均按照xavier初始化方式进行初始化。具体公式如式17所示。其中wi表示神经网络第i层的权重,ni表示第i层的神经元个数,ni+1表示第i+1层的神经元个数,u表示变量wi服从到的均匀分布。本发明采取增强学习的方法进行训练模型,首先依据解码模块中languagelstm输出的y2进行预训练,预训练采用的batch-size的范围在16-128之间,推荐使用32;epoch为20次。经过预训练,模型languagelstm的输出在测试集中的bleu-4(bilingualevaluationunderstudy)为0.307。预训练结束后,开始对整个模型进行训练,整个训练的batch-size的范围在16-128之间,推荐使用64,epoch为80次。模型的训练速率γ的范围为0.001-0.04之间,推荐使用0.02。本模型在训练过程中采取dropout方法来避免出现模型的过拟合现象,dropout率推荐使用0.5。训练完成后图像描述模型预测效果如图6所示。本发明分别采用bleu(bilingualevaluationunderstudy),rouge-l(recall-orientedunderstudyforgistingevaluation),meteor,cider(consensus-basedimagedescriptionevaluation)算法对图像描述生成的结果进行评价,在训练结束后,模型预测的准确率与其他模型的对比如表3所示。由表3可以看出,相对于其他模型,本模型在各项评价标准下均有不同程度的提升。表3各图像描述模型描述能力对比算法bleu-1bleu-4rouge_lmeteorcidermrnn0.6700.240---googlenic-0.2770.237-0.855deepvs0.6250.2300.195-0.660top-down0.8000.3660.2680.5691.158本文算法0.8270.3940.2710.5821.174当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1