一种用于脑机接口校准的异构标签空间迁移学习方法与流程
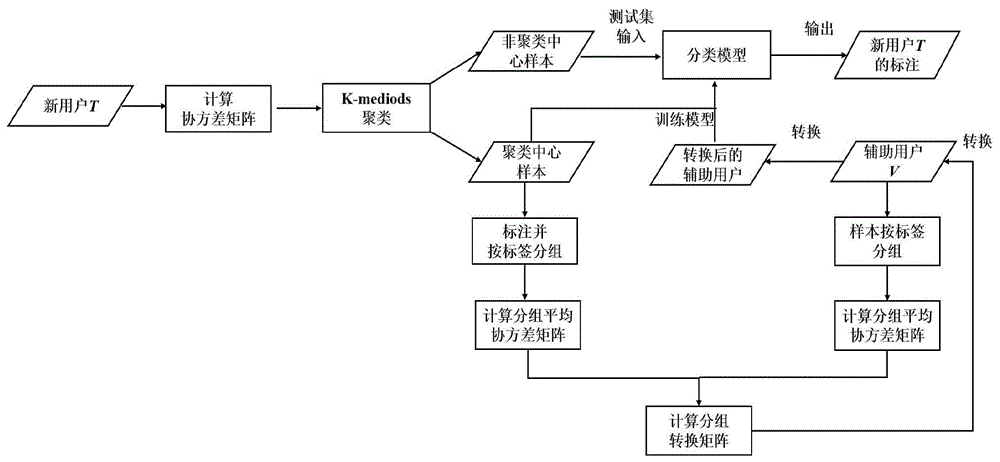
本发明属于脑机接口领域,更具体地,涉及一种用于脑机接口校准的异构标签空间迁移学习方法。
背景技术:
脑机接口是一种为大脑和外部设备(比如计算机、机器人等)提供直接交互通道的系统,被视为人机交互的终极形式。它既使得用户可以通过大脑信号直接控制外部设备的移动,比如机械外骨骼或无人机;也可以用来判断大脑当前的状态,比如睡眠状态,疲劳程度等等。脑机接口系统的输入信号有脑电图,脑磁图,功能核磁共振成像等,其中以脑电最为常见。脑电通常由头戴式的脑电帽通过电极从头皮表面采集,可以在头皮上监测到群体神经元的放电活动。然后通过解码神经元的活动,来识别用户的意图或者状态,并最终转化成对外部设备的控制信号。
目前,脑机接口技术遇到的主要挑战之一是每个新用户在使用之前都需要经过一段较长时间的个性化校准,这极大降低了人们使用脑机接口的意愿。所以,减少新用户的校准时间是使得脑机接口更加实用的关键问题。迁移学习被认为是解决这个问题的重要方法,其基本思想是利用辅助用户(源域)的数据来帮助新用户(目标域)进行校准,通常可以分为以下几个类别:(1)基于样本的迁移学习:通过一定的权重生成规则,对源域样本赋予不同的权重,使得源域数据尽可能的与目标域数据相似;(2)基于特征的迁移学习:通过特征变换的方式减少源域和目标域之间的分布差异;(3)基于模型的迁移学习:从源域和目标域中找到共享的参数信息,然后对模型的参数进行迁移。
然而,现阶段绝大多数迁移学习方法,都要求源域与目标域有相同的特征空间和标签空间,这极大地限制了迁移学习的应用范围,因为在脑机接口领域,有很多的源域数据会与目标域数据有不同的特征空间或标签空间。而现有技术只考虑了特征空间不同的情况,没有提出任何针对标签空间不同的迁移学习方法。当新用户和辅助用户的标签空间不同时,辅助用户数据无法利用,只能采集大量的新用户数据进行校准,造成校准时间大大增长。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种用于脑机接口校准的异构标签空间迁移学习方法,其目的在于解决,在脑机接口校准过程中,当新用户和辅助用户的标签空间不同时,辅助用户数据无法利用,只能采集大量新用户数据进行校准,造成校准时间大大加长的技术问题。
为实现上述目的,本发明提供了一种用于脑机接口校准的异构标签空间迁移学习方法,包括:
(1)对新用户t的部分脑电信号样本集t={xt,i}进行标注和分组,计算每个分组内的的平均协方差矩阵
(2)对辅助用户v的脑电信号样本集v={xs,i,ys,i}的所有样本按标签类别进行分组,计算每个分组内的平均协方差矩阵
(3)根据满足设定对应关系的平均协方差矩阵,对辅助用户v的样本xs,i进行变换,并将新用户t的标签按照所述对应关系赋给辅助用户样本,得到变换后的辅助用户数据;
(4)将变换后的辅助用户数据以及步骤(1)标注的新用户样本合并作为训练集,并在所述训练集上构建用于新用户未标注样本预测的机器学习模型。
进一步地,步骤(1)具体包括:
(1.1)计算新用户t的部分脑电信号样本集t={xt,i}中每个样本xt,i的协方差矩阵;
(1.2)根据两两协方差矩阵之间的黎曼距离,对所有样本的协方差矩阵进行k-mediods聚类,得到k个聚类中心,并根据对应的样本标签类别,对k个聚类中心进行标注,得到k个带标签样本;
(1.3)根据标注信息对k个带标签样本进行分组,得到m个分组
进一步地,所述样本集t={xt,i}通过对新用户t的脑电图数据进行时域带通滤波并将脑电信号切割成多个样本实例得到。
进一步地,任意两个协方差矩阵之间的黎曼距离定义为:
其中,ci、cj表示两个不同的协方差矩阵,λr表示矩阵
进一步地,步骤(1.2)具体包括:
(1.2.1)设定一个聚类的目标群体数目k;
(1.2.2)随机选择k个协方差矩阵分别作为k个群体的中心;
(1.2.3)对群体中心之外的每一个协方差矩阵,对比其到k个中心的距离,并将其分到距离最近的中心所属的群体;
(1.2.4)对每个群体,重新分配一个协方差矩阵作为该群体的中心,分配的规则是使得中心到群体内部其它协方差矩阵的距离之和最小;
(1.2.5)重复步骤(1.2.3)-(1.2.4),直到所有群体中心收敛。
进一步地,步骤(3)具体包括:
(3.1)将新用户t的m个标签类别
(3.2)根据每组对应的平均协方差矩阵,构建转换矩阵
(3.3)对辅助用户v的样本xs,i执行以下变换:当ys,i=yv,m时,
(3.4)将新用户t的标签按照如下关系赋给辅助用户样本;当ys,i=yv,m时,
进一步地,对于多个辅助用户,分别对每个辅助用户执行步骤(3)的变换,将所有变换后的辅助用户数据与新用户标注样本一起合并作为训练集。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
(1)本发明提出的异构标签空间迁移学习方法,针对标签空间不同的情形,对齐辅助用户与新用户的标签空间,使得在对齐后的辅助用户数据上构建的模型能够很好地适用于新用户,从而大幅度减少新用户所需要的校准数据,减少新用户的校准时间。
(2)当前脑机接口领域的迁移学习方法,只能使用同构标签空间的辅助用户,而采用本发明方法能够借助异构标签空间的辅助用户数据,提升新用户的模型学习能力,大大扩展了辅助用户的适用范围。
(3)本发明提出的异构标签空间迁移学习方法,并不限制后续特征提取方法和分类模型的选择,具有良好的适用性。
附图说明
图1是本发明提出的一种用于脑机接口校准的异构标签空间迁移学习方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,本发明提供的一种用于脑机接口校准的异构标签空间迁移学习方法,包括:
(1)对新用户t的部分脑电信号样本集t={xt,i}进行标注和分组,计算每个分组内的的平均协方差矩阵
具体地,步骤(1)包括:
(1.1)计算新用户t的部分脑电信号样本集t={xt,i}中每个样本xt,i的协方差矩阵;样本集t={xt,i}通过对新用户t的脑电图数据进行时域带通滤波并将脑电信号切割成多个样本实例得到,带通滤波的目的是去除数据中的背景噪声、人工伪迹等,提高信噪比。
(1.2)根据两两协方差矩阵之间的黎曼距离,对所有样本的协方差矩阵进行k-mediods聚类,得到k个聚类中心,并根据对应的样本标签类别,对k个聚类中心进行标注,得到k个带标签样本;
任意两个协方差矩阵之间的黎曼距离定义为:
其中,f代表f范数,ci、cj表示两个不同的协方差矩阵,λr表示矩阵ci-1cj的所有实特征值。
步骤(1.2)的聚类过程具体包括:(1.2.1)设定一个聚类的目标群体数目k;(1.2.2)随机选择k个协方差矩阵分别作为k个群体的中心;(1.2.3)对群体中心之外的每一个协方差矩阵,对比其到k个中心的距离,并将其分到距离最近的中心所属的群体;(1.2.4)对每个群体,重新分配一个协方差矩阵作为该群体的中心,分配的规则是使得中心到群体内部其它协方差矩阵的距离之和最小;(1.2.5)重复步骤(1.2.3)-(1.2.4),直到所有群体中心收敛。
(1.3)根据标注信息对k个带标签样本进行分组,得到m个分组
(2)对辅助用户v的脑电信号样本集v={xs,i,ys,i}的所有样本按标签类别进行分组,计算每个分组内的平均协方差矩阵
(3)根据满足设定对应关系的平均协方差矩阵,对辅助用户v的样本xs,i进行变换,并将新用户t的标签按照所述对应关系赋给辅助用户样本,得到变换后的辅助用户数据;
具体地,步骤(3)具体包括:
(3.1)将新用户t的m个标签类别
举例说明,一、假设新用户有2个标签类别:yt,1=1,yt,2=2;辅助用户也有2个类别:yv,1=1,yv,2=3,由于新用户与辅助用户有相同的标签1,则优先使相同标签相互对应,即yt,1对应yv,1,然后使yt,2对应yv,2;二、假设新用户有2个标签类别:yt,1=1,yt,2=2;辅助用户也有2个类别:yv,1=3,yv,2=4,由于新用户与辅助用户没有相同的标签,则随机使标签相互对应,既可以使yt,1对应yv,1,yt,2对应yv,2;也可以使yt,1对应yt,2,yt,2对应yv,1。
(3.2)根据每组对应的平均协方差矩阵,构建转换矩阵
(3.3)对辅助用户v的样本xs,i执行以下变换:当ys,i=yv,m时,
(3.4)将新用户t的标签按照如下关系赋给辅助用户样本;当ys,i=yv,m时,
(4)将变换后的辅助用户数据以及步骤(1)标注的新用户样本合并作为训练集,并在训练集上构建用于新用户未标注样本预测的机器学习模型。
本发明并不限制后续特征提取方法和分类模型的选择,具体地,对于运动想象范式,首先在训练集上学习共同空域模式滤波器,并对训练集进行空域滤波,再提取每个样本信号方差的对数作为特征,训练一个lda分类器;然后,将训练得到的共同空域模式滤波器和lda分类器用于新用户未标注样本的滤波和预测。替换地,可以将训练集的协方差矩阵映射到黎曼切空间,提取切空间特征,再训练一个svm分类器;然后,同样将新用户未标注样本的协方差矩阵映射到黎曼切空间,提取切空间特征;最后将训练得到的svm分类器用于新用户未标注样本的预测。若有多个辅助用户,分别对每个辅助用户执行步骤(3)的变换,将所有变换后的辅助用户数据与新用户标注样本一起合并作为训练集。
本发明以一个基于脑电的运动想象数据集进行举例,实验共采集了9个用户的实验数据,有22个脑电通道,采样频率为250hz。每个用户执行4个运动想象任务:左手、右手、双脚、舌头,分别以标签1、2、3、4表示。本发明实施例首先将数据集拆分为两个数据集,使得每个数据集包含两个标签类别且两个数据集的标签类别不同,比如“1,2”代表只含标签1,2的数据集,“3,4”代表只含标签3,4的数据集。再从“3,4”中选择一个用户作为新用户,从“1,2”中选择剩余8个用户作为辅助用户,然后在新用户和辅助用户上执行本发明提出的方法,该实验由“1,2→3,4”表示。一共有6种数据集拆分方式满足要求,每种拆分方式对应一个实验,新用户聚类目标群体数k设为2,6个实验的结果如表1所示:
表1:正确率(%)对比,其中csp-lda代表先用共同空域模式滤波,再用lda分类;ts-svm代表先提取黎曼切空间特征,再用svm分类。
从表1中可以看出,无论使用何种分类方法,使用本发明提出的方法在6个实验中均获得了更好的分类效果。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!