一种基于双流卷积网络的视频中人体行为识别方法与流程
本发明涉及计算机视觉领域,具体涉及一种基于双流卷积网络的视频中人体行为识别的方法。
背景技术:
视频中人体行为识别作为计算机视觉领域的一个重要研究方向,已经被广泛用于诸多实际应用场景中,如智能监控、智能家居、视频检索等,近年来受到了国内外学者的广泛关注,涌现出了大量的人体行为识别方法,但由于人体行为的非刚性、复杂性以及视频的视角变换、遮挡、光照变化等因素,目前的人体行为识别方法大都存在计算效率较低、识别准确率不足等问题,视频中人体行为仍是计算机视觉领域的热点和难题。
受卷积网络在图像识别领域性能卓越的启发,将卷积神经网络应用于视频人体行为识别领域已成为一种发展趋势。近年来,随着深度学习的迅猛发展,越来越多的基于卷积神经网络的模型被提出,在人体行为识别方法上也得到了广泛的应用。simonyan等人(simonyank,zissermana.two-streamconvolutionalnetworksforactionrecognitioninvideos[c]//advancesinneuralinformationprocessingsystems,2014:568-576.)提出了一种双流卷积网络的人体行为识别方法,双流卷积网络分为时间流卷积神经网络和空间流卷积神经网络两个分支,且两个分支具有同样的网络结构。时间流网络需要预先计算光流图像,输入光流图像提取时序特征,空间流网络输入rgb图像提取空间特征,最后通过分类得分融合得到最终的人体行为识别结果,实验证明了通过计算光流场来提取时序运动特征,对提高视频中的人体行为识别准确率非常有效。尽管双流卷积网络能够取得较高的识别率,但是光流图像的计算成本和存储空间成本太过昂贵,并且难以有效地对长时运动特征建模,在实际场景中无法得到有效的应用,因此设计一种更高效的光流计算方法对时序特征建模尤为重要。
技术实现要素:
本发明技术解决问题:克服现有技术的不足,提供一种基于双流卷积网络的视频中人体行为识别方法,以采用多个2d和3dinception模块堆叠组成的空间流网络作为空间流分支,提高对视频片段的高层语义信息建模能力,采用光流预测卷积网络作为时间流分支,对相邻特征向量计算梯度,预测特征残差的光流场,降低计算光流场产生的时间和空间成本,并将空间外观特征和时序运动特征信息互补,增强视频中人体行为识别方法对人体行为的表征能力。
本发明技术解决方案:一种基于双流卷积网络的视频中人体行为识别方法,本发明的目的是在视频片段人体行为识别过程中,更快速更准确地获得表示视频片段中出现的人体行为的标签。本发明包括:利用计算机视觉库opencv将视频切分成连续的视频帧,调整成固定尺寸后,采用稀疏采样的方式依次随机选取视频帧,采样的视频帧通过网络底层的卷积操作初步提取卷积特征后,分别输入到空间流分支和时间流分支中提取用来表示视频中人体行为的空间外观特征和时序运动特征,接着将两种特征在通道上进行融合,训练网络模型,确定模型参数,在模型趋于稳定后停止训练,并将测试视频相同预处理后进行输入,经过所述训练好的模型后,得到最终的识别结果。
具体步骤如下:
(1)利用计算机视觉库opencv中提取视频帧的方法,从包含人体行为的视频片段中提取连续视频帧,并将视频帧全部处理成尺寸为112*112像素的rgb图像,接着根据视频帧数量平均分成三个部分,依次从三个部分中随机选取8、9、8张图像,组成25张连续视频帧。
(2)将步骤(1)中采样到的25张连续视频帧输入到双流卷积网络模型中,由网络最先开始的卷积操作初步提取特征,其中第一个卷积层采用1*7*7的卷积核,获取较大的网络感受野,然后通过最大池化层进行下采样,接着通过1*1卷积层和3*3卷积层对卷积特征降维,然后将特征向量同时输入双流卷积网络模型的时间流分支和空间流分支。
(3)利用空间流分支对步骤(2)中初步提取的卷积特征提取空间外观特征,所述空间流分支由多个2dinception模块和3dinception模块堆叠构成,其中inception模块是图像识别领域网络结构常用的模块,空间流分支的底层采用2dinception模块,利用在imagenet上训练好的模型进行初始化,而高层采用3dinception模块则可以更好地捕捉高层语义特征信息。
(4)利用时间流分支对步骤(2)中初步提取的卷积特征提取时序运动特征,时间流分支采用1*1*1的卷积层调整输入特征向量的通道数,将相邻通道的特征向量f1,f2输入光流预测卷积层,采用sobel算子作为卷积核,预测特征残差的光流场,捕捉视频的时序运动特征,所涉及的计算方式为u=flow(f1,f2),其中
(5)将空间流分支和时间流分支提取的特征在通道上融合后输入到softmax分类器中,在避免梯度消失的基础上训练网络,使分类器获得的预测分类得分尽可能地接近真实标签值,最后将分类得分进行输出,在训练过程中采用交叉熵损失函数。
本发明与现有技术相比的优点在于:
(1)相比现有技术,本发明首先利用2d卷积层提取视频图像的外观特征,2d卷积层可以利用图像识别领域在imagenet上预训练过的模型进行初始化,可以有效地加快模型收敛,提高训练的速度,并且加入多个3dinception模块,增加了网络的深度的同时并没有带来大量的网络参数,对长时视频中的人体行为识别有较好的效果。
(2)相比现有技术,本发明利用光流预测卷积网络对特征残差计算预测光流场,经过迭代优化参数后,可以产生预测光流场,提取时序运动特征,快速地对人体行为的时序运动变化建模,不需要预先计算光流图像以及存储光流图像,节省了行为识别所需的计算时间和存储空间,提高了识别效率。
附图说明
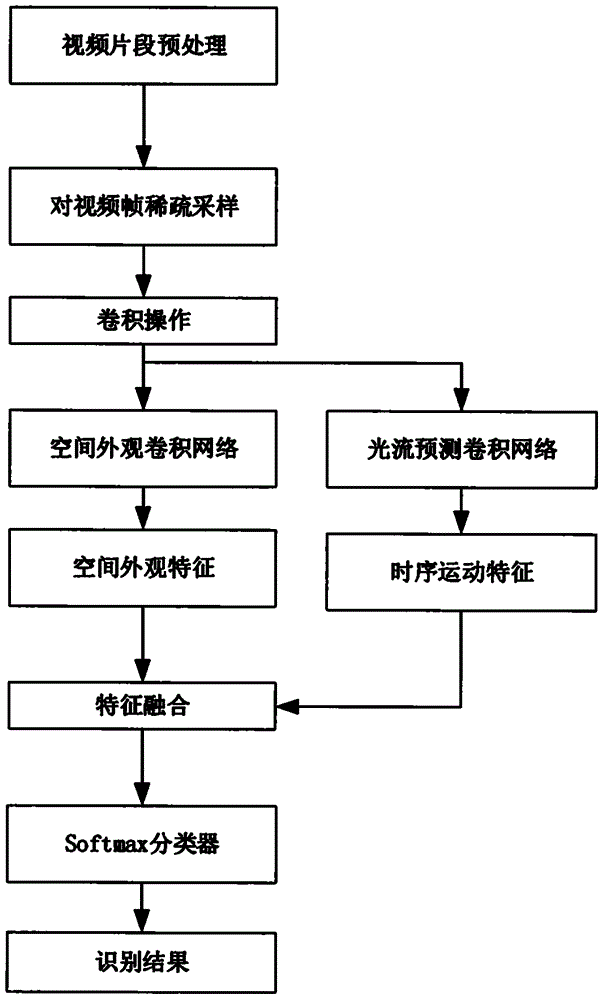
图1是根据本发明进行视频中人体行为识别的整体流程示意图;
图2是根据本发明人体行为识别方法的网络结构示意图;
图3是图2网络模型中的inception模块的结构示意图;
具体实施方式
下面结合附图和具体实施方式对本发明进行描述。其中图1描述了基于双流卷积网络的视频中人体行为识别过程。
如图1所示,本发明包括以下步骤:
(1)输入视频片段,利用计算机视觉库opencv对视频片段切帧,并将视频帧全部处理成尺寸为112*112像素的rgb图像,接着进行稀疏采样,根据视频帧数量平均分成三个部分,依次从三个部分中随机选取8、9、8张图像,组成25张连续视频帧作为网络的输入。
(2)将步骤(1)中采样到的25张连续视频帧输入到双流卷积网络模型中,利用网络最先开始的卷积操作初步提取特征,其中第一个卷积层采用1*7*7的卷积核,获取较大的网络感受野,然后通过最大池化层进行下采样,接着通过1*1卷积层和3*3卷积层对卷积特征降维,降低卷积计算成本,提高特征的鲁棒性,然后将特征向量同时输入所设计的双流卷积网络模型的时间流分支和空间流分支。
(3)利用空间流分支对步骤(2)中初步提取的卷积特征提取空间外观特征,所述空间流分支由多个2dinception模块和3dinception模块堆叠构成,其中inception模块是图像识别领域网络结构常用的模块,空间流分支的底层采用2dinception模块,利用在imagenet上训练好的模型进行初始化,而高层采用3dinception模块则可以更好地捕捉高层语义特征信息。
(4)利用时间流分支对步骤(2)中初步提取的卷积特征提取时序运动特征,时间流分支采用1*1*1的卷积层调整输入特征向量的通道数,将相邻通道的特征向量f1,f2输入光流预测卷积层,采用sobel算子作为卷积核,预测特征残差的光流场u,捕捉视频的时序运动特征,然后通过1*1*1的卷积层调整运动特征的维度,保证其能与空间流外观特征融合,光流预测所涉及的计算方式为u=flow(f1,f2),其中
初始化u=0,p=0
ρc=f2-f1
u=v+divergence(p)
其中p表示散度变量,ρ表示特征残差,λ控制输出的平滑度,θ控制权重,τ控制时间步长,λ、θ、τ均是需要学习的参数,经过网络的多次迭代优化,使得输出的张量u更接近真实光流场的分布。
(5)将空间流分支和时间流分支提取的特征在通道上融合后,所述的融合方式为:ffinal=concat(fs,ft),其中ffinal是(cs+ct)×h×w维的矩阵,为融合后的人体行为特征,fs是cs×h×w维的矩阵,表示空间外观特征,ft是ct×h×w维的矩阵,表示时序运动特征,c、h、w分别表示特征的通道数、高和宽,将ffinal输入到softmax分类器中,沿梯度下降最快的方向,在避免梯度消失的基础上训练网络,使分类器获得的预测分类得分尽可能地接近真实标签值,最后将分类得分进行输出。在训练过程中,采用交叉熵损失函数,计算方式为:
其中,c表示所有的行为类别,yi为类别i的真实标签,gj为g的第j个维度。
如图2所示,为一种基于双流卷积网络的视频中人体行为识别方法的整体网络结构示意图。网络模型通过输入连续视频帧,输出行为识别结果。其中,网络初始时利用1*7*7的卷积核获取较大的感受野,尽可能保证局部信息完整,然后通过1*1*1和1*3*3的卷积核对特征卷积,降低特征的维度,以及使用最大池化层下采样,简化网络复杂度,提高特征的鲁棒性,接着网络分成两个分支结构,连接2dinception模块的是空间流分支,分支底层采用2dinception模块,可以利用经过imagenet预训练的模型进行参数初始化,加快训练收敛速度,节省训练时间,空间流分支的高层采用3dinception模块,可以更好地捕捉高层语义信息,并且通过多个模块的堆叠,增加网络的深度,增强对长时视频的人体行为特征捕捉能力;另一个分支是时间流分支,首先通过1*1*1卷积核对特征进行卷积操作,降低特征维度的同时,也减少了光流预测的计算成本,加快产生预测光流场的速度,图2中光流预测卷积层flowlayer采用的是sobel算子作为卷积核,计算相邻特征向量之间运动残差的梯度,通过多次迭代优化其中的参数,使其产生的预测光流场更平滑,更接近真实光流场,传统的光流计算方法tv-l1需要亮度恒定和运动边界平滑两个假设作为前提,而光流预测网络则是利用可学习的参数来调整预测光流场的平滑度,不需要提前假设。然后将两个分支的特征在通道上融合,经过平均池化层下采样,再利用1*1*1卷积层将特征向量调整成一维的向量输入softmax分类器中进行分类。
如图3所示,为inception模块的结构示意图,inception模块来源于图像识别领域表现不错的googlenet,inception模块最大的特点是增加网络的深度和宽度的同时减小参数,多个分支结构能够捕捉不同尺度的信息,每个分支上都有一个1*1*1的卷积层调整通道数,用来保证不同尺度的特征能够结合。
- 还没有人留言评论。精彩留言会获得点赞!