对语句情感分析的方法、装置、服务器及存储介质与流程
本申请涉及自然语言处理技术领域,特别涉及一种对语句情感分析的方法、装置、服务器及存储介质。
背景技术:
情感分析是自然语言处理中常见的场景,可以用于指导产品的迭代更新或者提高服务的水平等。例如对于日常生活中的用餐评价,通过对评价内容进行实体识别并分析实体对应的情感类型,可以得到用户对菜品口味、上菜时间、服务态度以及用餐环境等多个维度的情感信息,基于上述情感信息可以确定现阶段在各方面(aspect-level)的优劣程度,从而明确如何进行改进。
相关技术中,存在基于深度学习的情感分析方法。具体的实现步骤如下:首先对待分析的语句包括的各词汇进行词向量编码,再基于卷积神经网络进行特征提取,最后输出词各词汇属于实体词汇的概率,从而得到各实体词汇所属情感类别的概率。
上述相关技术中存在的问题是,在待分析的语句较长时,会导致语句中具有关联关系的词汇之间的间距较大,从而影响分析结果的精度。
技术实现要素:
本申请实施例提供了一种对语句情感分析的方法、装置、服务器及存储介质,用于解决在待分析的语句较长时,会导致语句中具有关联关系的词汇之间的间距较大,从而影响分析结果的精度的问题。所述技术方案如下:
一方面,提供了对语句情感分析的方法,包括:
确定待分析的语句中包括的多个词汇对应的第一词向量;
基于图卷积网络对所述多个词汇对应的第一词向量、所述多个词汇之间的依赖关系以及各依赖关系所属的类型进行处理,得到所述多个词汇对应的第二词向量;
基于所述多个词汇对应的第二词向量,确定所述多个词汇中至少一个第一目标词汇所属的情感类型。
另一方面,提供了一种对语句情感分析的装置,包括:
确定模块,用于确定待分析的语句中包括的多个词汇对应的第一词向量;
处理模块,用于基于图卷积网络对所述多个词汇对应的第一词向量、所述多个词汇之间的依赖关系以及各依赖关系所属的类型进行处理,得到所述多个词汇对应的第二词向量;
所述确定模块,还用于基于所述多个词汇对应的第二词向量,确定所述多个词汇中至少一个第一目标词汇所属的情感类型。
在一种可能的实现方式中,所述确定模块,还用于对待分析的语句进行分词,得到多个词汇;对于任一词汇,将所述词汇的第一含义对应的词向量和所述词汇的第二含义对应的词向量进行拼接,得到所述词汇对应的第一词向量。
在另一种可能的实现方式中,其特征在于,所述处理模块,还用于获取所述多个词汇之间的依赖关系;根据所述依赖关系,确定关系矩阵,所述关系矩阵中的元素用于表示各词汇之间是否存在依赖关系;对于任一依赖关系,根据所述依赖关系所属的类型,获取所述依赖关系对应的关系向量;基于所述图卷积网络对所述关系矩阵和多个关系向量进行处理,得到所述多个词汇对应的第二词向量。
在另一种可能的实现方式中,所述处理模块,还用于对于所述多个词汇中的任一词汇,获取与所述词汇具有依赖关系的至少一个词汇对应的第一词向量;将所述关系矩阵、所述多个关系向量以及所述至少一个词汇对应的第一词向量输入所述图卷积网络,得到所述词汇对应的第二词向量。
在另一种可能的实现方式中,所述确定模块,还用于基于第一卷积神经网络对所述多个词汇对应的第一词向量进行处理,得到所述多个词汇对应的第三词向量,所述第三词向量与所述第二词向量一一对应;将相对应的第二词向量和第三词向量进行拼接,得到所述多个词汇对应的第四词向量;基于所述多个词汇对应的第四词向量,确定所述多个词汇中至少一个第一目标词汇所属的情感类型。
在另一种可能的实现方式中,所述确定模块,还用于根据所述多个词汇对应的第二词向量,确定所述多个词汇对应的第一信息向量和所述多个词汇对应的第二信息向量,所述第一信息向量用于指示所述多个词汇中的任一词汇是否为第一目标词汇,所述第二信息向量用于指示所述多个词汇中每个词汇所属的情感类型;对于每个词汇,当根据所述词汇对应的第一信息向量,确定所述词汇属于第一目标词汇的概率大于目标概率阈值时,根据所述词汇对应的第二信息向量,确定所述词汇属于每个情感类型的概率。
在另一种可能的实现方式中,所述确定模块,还用于基于第二卷积神经网络对所述多个词汇对应的第二词向量进行重新编码,得到所述多个词汇对应的第一信息向量;基于第三卷积神经网络对所述多个词汇对应的第二词向量进行重新编码,得到所述多个词汇对应的第二信息向量;将所述第一信息向量和所述第二信息向量进行拼接,得到第三信息向量;基于所述第二卷积神经网络和所述第三卷积神经网络分别对所述第三信息向量进行重新编码,得到更新后的第一信息向量和第二信息向量。
在另一种可能的实现方式中,所述装置还包括:
拼接模块,用于将更新后的第一信息向量和更新后的第二信息向量进行拼接得到更新后的第三信息向量;
编码模块,用于基于所述第二卷积神经网络和所述第三卷积神经网络再次分别对更新后的第三信息向量进行重新编码;
更新模块,用于重复上述拼接和重新编码的过程,直到达到停止更新条件。
在另一种可能的实现方式中,所述确定模块,还用于获取所述第二卷积神经网络根据所述多个词汇对应的第二词向量得到的交互传递信息,所述交互传递信息用于指示所述多个词汇中属于第二目标词汇的词汇;基于所述第三卷积神经网络和所述交互传递信息对所述第三信息向量进行重新编码,得到更新后的第二信息向量;基于所述第二卷积神经网络对所述第三信息向量进行重新编码,得到更新后的第一信息向量。
另一方面,提供了一种服务器,所述服务器包括处理器和存储器,所述存储器用于存储至少一段程序代码,所述至少一段程序代码由所述处理器加载并执行以实现本申请实施例中的对语句情感分析的方法中所执行的操作。
另一方面,提供了一种存储介质,所述存储介质中存储有至少一段程序代码,所述至少一段程序代码用于被处理器执行并实现本申请实施例中的对语句情感分析的方法。
本申请实施例提供的技术方案带来的有益效果是:
在本申请实施例中,由于基于图卷积网络对多个词汇对应的第一词向量确定多个词汇对应的第二词向量时,还考虑了多个词汇之间的依赖关系和各依赖关系所属的类型,使得即使待分析的语句较长,也可以通过各词汇之间的依赖关系加强词汇之间的联系,从而提高对各实体词汇所属的情感类型的分析结果的精度。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
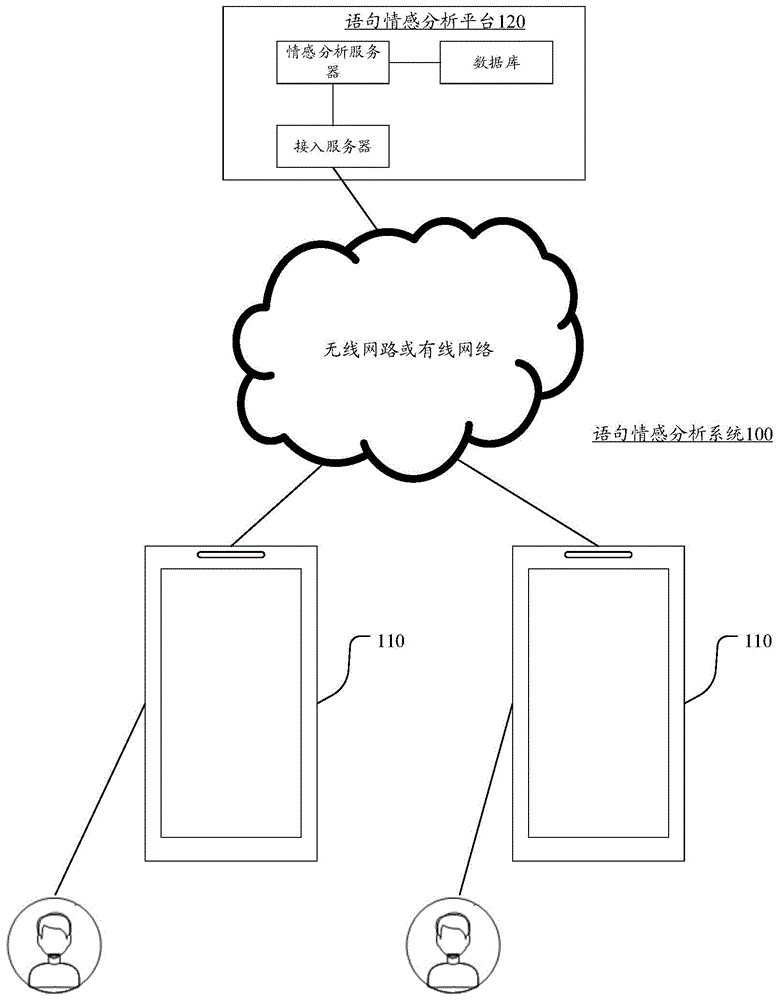
图1是本申请实施例提供的一种语句情感分析系统的结构框图;
图2是本申请实施例提供的一种对语句情感分析的方法的流程图;
图3是本申请实施例示出的一种词汇依赖关系的示意图;
图4是本申请实施例提供的一种对语句情感分析的方法的架构示意图;
图5是本申请实施例提供的一种对语句情感分析的装置的框图;
图6是本申请实施例提供的一种服务器的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
本申请实施例涉及需要对语句进行情感分析的场景。相应的,可以应用于日常生活中的场景,例如顾客用餐后可以发表用餐评价,顾客收到外卖后可以发表送餐评价,顾客购买商品后可以发表商品评价。这些评价有积极的评价,如用餐很愉快、环境很好、送餐很快或者商品很好用等,也有消极的评价,如菜难吃、价格贵、上菜慢、外卖凉了或者商品做工粗糙等,还有中性的评价,如还行、还可以等。通过对上述评价中的语句进行情感分析,可以帮助餐厅改进菜品和服务,或者可以帮助外卖服务提供商改进送餐服务,或者可以帮助商品进行升级换代。相应的,还可以应用于互联网中的场景,例如用户可以对电影或电视剧进行评论,通过对评论内容的分析,可以了解用户对电影或者电视剧的喜爱程度,从而指定播放时间;用户还可以对热门事件发表看法,通过对看法内容的分析,可以帮助有关部门了解公民对热门事件的看法;用户还可以在分享自己的心情,通过对心情内容的分析,可以了解用户的情绪。相应的,还可以用应用于其他场景中,在此不再一一列举。为此,本申请实施例提供了一种对语句情感分析的方法。
下面简单介绍一下本申请实施例提供的对语句情感分析的方法的主要流程。首先确定待分析的语句中包括的多个词汇对应的第一词向量,然后基于图卷积网络对上述第一词向量、上述多个词汇之间的依赖关系以及各依赖关系所属的类型进行处理,从而得到上述多个词汇对应的第二词向量。最后基于上述多个词汇对应的第二词向量,即可确定多个词汇中至少一个第一目标词汇的情感类型,实现对待分析的语句的各方面的情感分析。
图1是本申请实施例提供的一种语句情感分析系统100的结构框图,该语句情感分析系统100可以用于实现对语句的情感分析,包括:多个终端110和语句情感分析平台120。
终端110可以通过无线网络或有线网络与语句情感分析平台120相连。终端110可以是智能手机、摄像机、台式计算机、平板电脑、mp4播放器和膝上型便携计算机中的至少一种。终端110安装和运行有包括语句上传功能的应用程序,例如外卖程序、购物程序、点评程序等。示意性的,终端110可以是用户使用的终端,终端运行的应用程序内登录有该用户的账号。
语句情感分析平台120包括一台服务器、多台服务器和云计算平台中的至少一种。语句情感分析平台120用于提供上述包括语句上传功能的应用程序的后台服务,如语句分词、词汇抽取以及语句情感分析等。一种可能的方式中,语句情感分析平台120包括:接入服务器、情感分析服务器和数据库。接入服务器用于提供终端110的接入服务。情感分析服务器用于语句分词、词汇抽取以及语句情感分析等。情感分析服务器可以是一台或多台,当情感分析服务器是多台时,存在至少两台情感分析服务器用于提供不同的服务,和/或,存在至少两台情感分析服务器用于提供相同的服务,比如以负载均衡方式提供同一种服务或者以主服务器和镜像服务器的方式提供同一种服务,本申请实施例对此不加以限定。数据库用于存储与词汇含义对应的词向量以及情感类型等。上述待分析语句为用户已授权采集的数据信息。
终端110可以泛指多个终端中的一个,本实施例仅以终端110来举例说明。本领域技术人员可以知晓,上述终端的数量可以更多或更少。比如上述终端可以仅为一个,或者上述终端为几十个或几百个,或者更多数量,此时上述程序服务系统还包括其他终端。本申请实施例对终端的数量和类型不加以限定。
图2是本申请实施例提供的一种对语句情感分析的方法的流程图,如图2所示。该方法包括以下步骤:
201、服务器确定待分析的语句中包括的多个词汇对应的第一词向量。
在本申请实施例中,服务器可以从至少一个用于语句上传的应用程序中获取至少一个待分析的语句。对于任一待分析的语句,如果该语句需要进行分词,如中文语句,则服务器可以对该语句进行分词,得到多个词汇;如果该语句不需要进行分词,如英文语句,则服务器可以直接获取该语句中包括的多个词汇。其中,服务器中可以存储有各词汇与词向量的对应关系,服务器可以根据该对应关系,确定多个词汇对应的第一词向量。
在一种可能的实现方式中,由于词汇在不同领域可以有不同的含义,因此服务器可以根据词汇的基本含义以及词汇在目标领域的特殊含义,来确定上述多个词汇对应的第一词向量。相应的,本步骤可以为:服务器可以对待分析的语句进行分词,得到多个词汇。对于任一词汇,服务器可以获取该词汇的第一含义对应的词向量以及该词汇的第二含义对应的词向量,将该词汇的第一含义对应的词向量和该词汇的第二含义对应的词向量进行拼接,得到该词汇对应的第一词向量,从而得到多个词汇对应的第一词向量。由于服务器对词汇的不同含义对应的词向量进行拼接,从而得到的词汇对应的第一词向量与该词汇的含义更贴切。
其中,词汇的第一含义指的是词汇的基本含义,例如“淡”这个词的基本含义是成分稀薄,与“浓”相对应。词汇的第二含义是指词汇在目标领域的特殊含义,该目标领域可以为语句所应用的场景所属的领域,如出行领域、购物领域、餐饮领域、艺术领域等。以餐饮领域为例,上述“淡”在餐饮领域的特殊含义是口味轻,与“成”相对应。服务器可以存储有各词汇的不同含义对应的词向量,每个词汇对应至少一个词向量。
需要说明的是,上述包括语句上传功能的应用程序还可以根据其应用的场景包括其他功能。例如,该应用程序为应用于购物场景的应用程序时,该应用程序还可以包括搜索商品、添加购物车、订单支付以及订单评价等功能。又如,该应用程序为应用于餐饮场景的应用程序时,该应用程序还可以包括菜单展示、显示送餐员位置以及用餐评价等功能。
202、服务器基于图卷积网络对多个词汇对应的第一词向量、多个词汇之间的依赖关系以及各依赖关系所属的类型进行处理,得到多个词汇对应的第二词向量。
在本申请实施例中,服务器可以基于图卷积网络得到上述多个词汇对应的第二词向量。该图卷积网络可以为dregcn(dependencyrelationembeddedgraphconvolutionalnetworks,依存关系嵌入的图卷积网络),相较于传统的gcn(graphconvolutionalnetworks,图卷积网络),dregcn中添加了各词汇之间的依赖关系所对应的关系向量。
在介绍本申请实施例中的dregcn之前,我们先来介绍一下传统的gcn。传统的gcn是gnn(graphneuralnetworks,图神经网络)的一种,任一词汇在t时刻对应的词向量可以通过以下公式(1)计算得到。
其中,n表示词汇数量,relu表示激活函数,aij表示关系矩阵,wg表示线性变换参数,
本申请实施例中的dregcn在传统gcn上进行了改进,任一词汇在t时刻对应的词向量可以通过以下公式(2)计算得到。
其中,n表示词汇数量,n表示词汇之间依赖关系的类型数量,relu表示激活函数,aij表示关系矩阵,wr表示线性变换参数,
需要说明的是,上述wr和br可以通过模型训练得到,模型训练的方式本申请实施例不进行限制。
在一种可能的实现方式中,服务器可以根据多个词汇之间的依赖关系确定关系矩阵,根据依赖关系所属的类型,确定依赖关系对应的关系向量,然后将上述多个词汇对应的第一词向量、关系矩阵以及各依赖关系对应的关系向量输入图卷积网络中,得到上述多个词汇对应的第二词向量。相应的,本步骤可以通过以下子步骤2021至子步骤2024实现:
2021、服务器可以获取多个词汇之间的依赖关系;
一个语句可以包括多个词汇,每个词汇有各自的词性,如名词、代词、形容词以及介词等,每个词汇还有各自的作用,如主语、谓语、宾语以及定语等。语句中各词汇之间的依赖关系可以构成一个多层的树状结构,各词汇之间根据依赖关系相连。
例如,以“咖啡是一种比高价的火腿三明治便宜的东西”这一语句为例。对其分词后可以得到“咖啡”、“是”、“一种”、“比”、“高价的”、“火腿”、“三明治”、“便宜的”以及“东西”这些词汇。上述词汇之间的依赖关系可以参见图3所示。图3是本申请实施例示出的一种词汇依赖关系的示意图。具有依赖关系的词汇之间通过线段连接,如“是”和“咖啡”、“东西”具有依赖关系,“东西”和“是”、“一种”、“便宜的”、“比”具有依赖关系,“比”和“三明治”、“东西”具有依赖关系,“三明治”和“比”、“高价的”、“火腿”具有依赖关系。
2022、服务器根据上述依赖关系,确定关系矩阵,该关系矩阵中的元素用于表示各词汇之间是否存在依赖关系。
服务器在获取到上述依赖关系后,可以根据该依赖关系,构造关系矩阵,该关系矩阵的行数和列数相等,均等于词汇的个数。当任意两个词汇具有依赖关系时,服务器可以在关系矩阵中将表示上述两个词汇之间是否存在依赖关系的元素设为1;当任意两个词汇不具有依赖关系时,服务器可以在关系矩阵中将表示上述两个词汇之间是否存在依赖关系的元素设为0。
例如,继续以上述“咖啡是一种比高价的火腿三明治便宜的东西”这一语句为例进行说明。服务器在获取各词汇的依赖关系后,可以确定以下关系矩阵a。
其中,关系矩阵a的第一行第一列的元素值为1,表示“咖啡”与自身有依赖关系;第一行第二列的元素值为1,表示“咖啡”与“是”有依赖关系;第四行第七列的元素值为1,表示“比”与“三明治”有依赖关系;第四行第九列的元素值为1,表示“比”与“东西”有依赖关系。以此类推。
2023、对于任一依赖关系,服务器可以根据该依赖关系所属的类型,获取该依赖关系对应的关系向量。
对于上述确定的至少一种依赖关系中的任一依赖关系,服务器可以确定该依赖关系所属的类型,例如“咖啡”是“是”的名词主语,相应的,“是”是“咖啡”的谓语,“火腿”是“三明治”的复合词,共同组成了“火腿三明治”,“高价的”是“三明治”的形容词,“三明治”是“比”的介词的宾语。每种类型的依赖关系对应一个关系向量,服务器可以根据依赖关系的类型来确定该依赖关系对应的关系向量。
在一种可能的实现方式中,服务器中可以存储有依赖关系的类型与关系向量的对应关系。服务器可以根据该对应关系,确定依赖关系所属的类型后,获取对应的关系向量。
需要说明的是,词汇之间依赖关系的类型是成对的,即词汇a对词汇b的依赖关系的类型是a,而词汇b对词汇a的依赖关系的类型是b,例如“咖啡”是“是”的名词主语,相应的,“是”是“咖啡”的谓语。
2024、服务器基于该图卷积网络对关系矩阵和多个关系向量进行处理,得到多个词汇对应的第二词向量。
服务器在获取上述关系矩阵和多个关系向量后,对于多个词汇中的任一词汇,可以获取与该词汇具有依赖关系的至少一个词汇对应的第一词向量。服务器可以将关系矩阵、多个关系向量以及该至少一个词汇对应的第一词向量输入图卷积网络,得到该词汇对应的第二词向量。由于在基于图卷积网络进行处理时,考虑了词汇之间的依赖关系,使得得到的词汇对应的第二词向量与其他词汇对应的第二词向量联系更紧密,从而提高分析结果的精度。
203、服务器根据多个词汇对应的第二词向量,确定多个词汇对应的第一信息向量和多个词汇对应的第二信息向量,该第一信息向量用于指示多个词汇中的任一词汇是否为第一目标词汇,该第二信息向量用于指示多个词汇中每个词汇所属的情感类型。
在本申请实施例中,服务器在得到上述多个词汇对应的第二词向量后,可以基于aspect词汇抽取任务和aspect-level情感分类任务分别对上述多个词汇对应的第二词向量进行处理,来确定上述第一信息向量和第二信息向量。其中,aspect词汇抽取任务用于识别上述多个词汇中包括的第一目标词汇和第二目标词汇,该第一目标词汇可以为实体词汇,如名词、代词等,该第二目标词汇可以为情感词词汇,如形容词等。aspect-level情感分类任务可以包括aspect实体识别、情感分类以及情感词识别。
在一种可能的实现方式中,上述aspect词汇抽取任务可以由第二卷积神经网络来完成,上述aspect-level情感分类任务可以由第三卷积神经网络来完成。相应的,本步骤的实现方式可以为:服务器可以基于第二卷积神经网络对多个词汇对应的第二词向量进行重新编码,得到多个词汇对应的第一信息向量。服务器还可以基于第三卷积神经网络对多个词汇对应的第二词向量进行重新编码,得到多个词汇对应的第二信息向量。服务器可以将该第一信息向量和该第二信息向量进行拼接,得到第三信息向量。服务器可以基于上述第二卷积神经网络和上述第三卷积神经网络分别对第三信息向量进行重新编码,得到更新后的第一信息向量和第二信息向量。由于服务器将得到的第一信息向量和第二信息向量拼接后,再次分别输入第二卷积神经网络和第三卷积神经网络进行重新编码,使得不同任务之间实现了信息共享,即将aspect词汇抽取任务得到的第一目标词汇的信息共享给aspect-level情感分类任务,将aspect-level情感分类任务得到的每个词汇所属的情感类型的信息共享给aspect词汇抽取任务。
在一种可能的实现方式中,服务器可以多次进行信息共享,也即多次对第一信息向量和第二信息向量进行更新。相应的步骤可以为:服务器可以将更新后的第一信息向量和更新后的第二信息向量进行拼接得到更新后的第三信息向量。服务器可以基于上述第二卷积神经网络和上述第三卷积神经网络再次分别对更新后的第三信息向量进行重新编码。重复上述拼接和重新编码的过程,直到达到停止更新条件。其中,该停止更新条件可以为达到目标迭代次数,如2次,或者第一信息向量和第二信息向量收敛,本申请实施例对此不进行限制。
在一种可能的实现方式中,服务器还可以将aspect词汇抽取任务中得到的形容词词汇的信息发送给aspect-level情感分析任务,使得服务器在执行情感分析任务时,根据该形容词词汇的信息对第二信息向量更新。相应的,服务器得到更新后的第一信息向量和第二信息向量步骤可以为:服务器可以获取第二卷积神经网络根据多个词汇对应的第二词向量得到的交互传递信息,该交互传递信息用于指示多个词汇中属于第二目标词汇的词汇。服务器可以基于第三卷积神经网络和该交互传递信息对第三信息向量进行重新编码,得到更新后的第二信息向量。服务器可以基于第二卷积神经网络对所述第三信息向量进行重新编码,得到更新后的第一信息向量。由于服务器将指示多个词汇中属于第二目标词汇的信息,即形容词词汇的信息共享给aspect-level情感分析任务,使得基于第三卷积神经网络更新得到的第二信息向量更准确。从而提高了结果的精确度。
需要说明的是,服务器在上述不同任务之间进行信息共享时,可以通过以下公式(3)来实现。服务器可以将上次输入的第三信息向量和得到的第一信息向量以及第二信息向量进行拼接后重新编码,得到更新后的第三信息向量。
其中,
204、服务器对于每个词汇,当根据该词汇对应的第一信息向量,确定该词汇属于第一目标词汇的概率大于目标概率阈值时,根据该词汇对应的第二信息向量,确定该词汇属于每个情感类型的概率。
在本申请实施例中,服务器对于每个词汇,可以对该词汇对应的第一信息向量进行全连接处理,得到该词汇属于第一目标词汇或者第二目标词汇的概率。当该词汇属于第一目标词汇的概率大于目标概率阈值时,服务器根据该词汇对应的第二信息向量进行情感预测,得到该词汇属于每个情感类型的概率,从而得到该词汇的情感类型。其中,任一词汇属于各情感类型的概率的和为1。
例如,“咖啡”这个实体词的情感类型可能有“积极”、“中性”和“消极”三个情感类型,在上述语句中,“便宜的”表示的是“咖啡”比“三明治”便宜,这是“咖啡”的优点,因此服务器对“咖啡”这个词进行情感预测后属于“积极”这一情感类型的概率较高,从而“咖啡”这一实体词汇的情感类型为“积极”。
需要说明的是,上述步骤203和步骤204是服务器基于多个词汇对应的第二词向量,确定多个词汇中至少一个第一目标词汇所属的情感类型的一种可能的实现方式。
在一种可能的实现方式中,服务器还可以基于第一卷积神经网络获取多个词汇对应的第三词向量,基于该第三词向量与第二词向量进行拼接后得到的第四词向量,确定多个词汇中至少一个第一目标词汇所属的情感类型。相应的实现步骤可以为:服务器可以基于第一卷积神经网络对多个词汇对应的第一词向量进行处理,得到多个词汇对应的第三词向量,该第三词向量与第二词向量一一对应。服务器可以将相对应的第二词向量和第三词向量进行拼接,得到多个词汇对应的第四词向量,服务器可以基于多个词汇对应的第四词向量,确定多个词汇中至少一个第一目标词汇所属的情感类型。其中,服务器基于多个词汇对应的第四词向量,确定多个词汇中至少一个第一目标词汇所属的情感类型的步骤可以参照服务器基于多个词汇对应的第二词向量,确定多个词汇中至少一个第一目标词汇所属的情感类型的实现方式,本申请实施例不再赘述。
另外,为了更清楚的展示本申请实施例提供的对语句情感分析的方法的架构,可以参见图4所示,图4是本申请实施例提供的一种对语句情感分析的方法的架构示意图。图4中输入的是对待分析的语句分词后得到的多个词汇。编码层包括两部分,第一部分是将每个词汇的第一含义对应的词向量和该词汇的第二含义对应的词向量进行拼接,得到该词汇对应的第一词向量。第二部分是基于图卷积网络对多个词汇对应的第一词向量、多个词汇之间的依赖关系以及各依赖关系所属的类型进行处理,得到多个词汇对应的第二词向量,当然第二部分还可以基于第一卷积神经网络对多个词汇对应的第一词向量进行处理,得到多个词汇对应的第三词向量。服务器可以将相对应的第二词向量和第三词向量进行拼接,得到多个词汇对应的第四词向量。面向任务层包括第二卷积神经网络
在本申请实施例中,由于基于图卷积网络对多个词汇对应的第一词向量确定多个词汇对应的第二词向量时,还考虑了多个词汇之间的依赖关系和各依赖关系所属的类型,使得即使待分析的语句较长,也可以通过各词汇之间的依赖关系加强词汇之间的联系,从而提高对各实体词汇所属的情感类型的分析结果的精度。
本申请实施例提供的对语句情感分析的方法,相较于相关技术在f1分数和精确度等指标都有较大提升。为了更清楚的展示本申请的有益效果,对本申请和相关技术进行了对比实验。对比实验中,以相关技术为基准,通过本申请和相关技术分别对三个通用数据集进行处理。对比实验的指标为识别实体的f1值、识别情感词的f1值、aspect-level情感分类的正确率、aspect-level情感分类的f1值以及实体抽取正确且情感分类正确的f1值。对比实验的结果可以参见表1所示。
表1
由表1可知,本申请提供的对语句情感分析的方法,在各个指标上相较于相关技术都具有显著的提升。
另外,本申请还对比了普通的gcn、本申请提供的dregcn、dregcn结合信息共享以及dregcn结合信息共享和外部知识的区别。采用的对比指标为实体抽取正确且情感分类正确的f1值。其中对比时采用的数据集仍旧是上述三个通用数据集。对比结果可以参见表2所示。
表2
由表2可知,通过采用本申请实施例提供的dregcn,相较于普通的gcn来说,实体抽取正确且情感分类正确的f1值具有明显的提升,而再将dregcn和信息共享以及外部知识结合后,相较于普通的gcn具有显著的提升。其中该外部知识指的是本申请实施例中词汇的向量表示。
图5是本申请实施例提供的一种对语句情感分析的装置的框图。该装置用于执行上述对虚拟对象交互的方法执行时的步骤,参见图5,装置包括:确定模块501和处理模块502。
确定模块,用于确定待分析的语句中包括的多个词汇对应的第一词向量;
处理模块,用于基于图卷积网络对多个词汇对应的第一词向量、多个词汇之间的依赖关系以及各依赖关系所属的类型进行处理,得到多个词汇对应的第二词向量;
确定模块,还用于基于多个词汇对应的第二词向量,确定多个词汇中至少一个第一目标词汇所属的情感类型。
在一种可能的实现方式中,确定模块,还用于对待分析的语句进行分词,得到多个词汇;对于任一词汇,将词汇的第一含义对应的词向量和词汇的第二含义对应的词向量进行拼接,得到词汇对应的第一词向量。
在另一种可能的实现方式中,其特征在于,处理模块,还用于获取多个词汇之间的依赖关系;根据依赖关系,确定关系矩阵,关系矩阵中的元素用于表示各词汇之间是否存在依赖关系;对于任一依赖关系,根据依赖关系所属的类型,获取依赖关系对应的关系向量;基于图卷积网络对关系矩阵和多个关系向量进行处理,得到多个词汇对应的第二词向量。
在另一种可能的实现方式中,处理模块,还用于对于多个词汇中的任一词汇,获取与词汇具有依赖关系的至少一个词汇对应的第一词向量;将关系矩阵、多个关系向量以及至少一个词汇对应的第一词向量输入图卷积网络,得到词汇对应的第二词向量。
在另一种可能的实现方式中,确定模块,还用于基于第一卷积神经网络对多个词汇对应的第一词向量进行处理,得到多个词汇对应的第三词向量,第三词向量与第二词向量一一对应;将相对应的第二词向量和第三词向量进行拼接,得到多个词汇对应的第四词向量;基于多个词汇对应的第四词向量,确定多个词汇中至少一个第一目标词汇所属的情感类型。
在另一种可能的实现方式中,确定模块,还用于根据多个词汇对应的第二词向量,确定多个词汇对应的第一信息向量和多个词汇对应的第二信息向量,第一信息向量用于指示多个词汇中的任一词汇是否为第一目标词汇,第二信息向量用于指示多个词汇中每个词汇所属的情感类型;对于每个词汇,当根据词汇对应的第一信息向量,确定词汇属于第一目标词汇的概率大于目标概率阈值时,根据词汇对应的第二信息向量,确定词汇属于每个情感类型的概率。
在另一种可能的实现方式中,确定模块,还用于基于第二卷积神经网络对多个词汇对应的第二词向量进行重新编码,得到多个词汇对应的第一信息向量;基于第三卷积神经网络对多个词汇对应的第二词向量进行重新编码,得到多个词汇对应的第二信息向量;将第一信息向量和第二信息向量进行拼接,得到第三信息向量;基于第二卷积神经网络和第三卷积神经网络分别对第三信息向量进行重新编码,得到更新后的第一信息向量和第二信息向量。
在另一种可能的实现方式中,装置还包括:
拼接模块,用于将更新后的第一信息向量和更新后的第二信息向量进行拼接得到更新后的第三信息向量;
编码模块,用于基于第二卷积神经网络和第三卷积神经网络再次分别对更新后的第三信息向量进行重新编码;
更新模块,用于重复上述拼接和重新编码的过程,直到达到停止更新条件。
在另一种可能的实现方式中,确定模块,还用于获取第二卷积神经网络根据多个词汇对应的第二词向量得到的交互传递信息,交互传递信息用于指示多个词汇中属于第二目标词汇的词汇;基于第三卷积神经网络和交互传递信息对第三信息向量进行重新编码,得到更新后的第二信息向量;基于第二卷积神经网络对第三信息向量进行重新编码,得到更新后的第一信息向量。
在本申请实施例中,由于基于图卷积网络对多个词汇对应的第一词向量确定多个词汇对应的第二词向量时,还考虑了多个词汇之间的依赖关系和各依赖关系所属的类型,使得即使待分析的语句较长,也可以通过各词汇之间的依赖关系加强词汇之间的联系,从而提高对各词汇所属的情感类型的分析结果的精度。
图6是本申请实施例提供的一种服务器600的结构示意图。该服务器600可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(centralprocessingunits,cpu)601和一个或一个以上的存储器602,其中,所述存储器602中存储有至少一条指令,所述至少一条指令由所述处理器601加载并执行以实现上述各个方法实施例提供的方法。当然,该服务器还可以具有有线或无线网络接口、键盘以及输入输出接口等部件,以便进行输入输出,该服务器还可以包括其他用于实现设备功能的部件,在此不做赘述。
本申请实施例还提供了一种存储介质,该存储介质应用于服务器,该存储介质中存储有至少一条程序代码,该至少一条程序代码用于被处理器执行并实现本申请实施例中的对语句情感分析的方法。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,程序可以存储于一种存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上仅为本申请的可选实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!