一种噪声模糊图像非盲复原方法、系统及存储介质与流程
本发明涉及一种噪声模糊图像非盲复原方法、系统及存储介质,属于图像处理技术领域。
背景技术:
图像在获取、传输和保持的过程中,由于光学条件、摄像技术、传输渠道、自然环境、人为破坏等各种原因难免会出现包含噪声、发生模糊等现象,使得图像质量降低,视觉效果显著下降。所以,必须对包含噪声、发生模糊的图像进行复原,提升图像质量,改善图像视觉效果。
技术实现要素:
本发明实施例的目的在于克服现有技术中的不足,提供一种噪声模糊图像非盲复原方法、系统及存储介质,能够在对噪声模糊图像去噪、去模糊的同时提升图像中纹理部分和细节部分复原效果。
为达到上述目的,本发明实施例是采用下述技术方案实现的:
第一方面,本发明实施例提供了一种噪声模糊图像非盲复原方法,所述方法包括如下步骤:
基于预建立的噪声模糊图像复原模型执行下述迭代操作:
依据xk-1、预构建的矩阵对(p,q)生成矩阵对(pk-1,qk-1);xk-1表示第k-1次迭代后数字图像x的值;p表示数字图像x中像素与其下方相邻像素之间灰度值的差值,q表示数字图像x中像素与其右方相邻像素之间灰度值的差值;pk-1表示第k-1次迭代后数字图像xk-1中像素与其下方相邻像素之间灰度值的差值,qk-1表示第k-1次迭代后数字图像xk-1中像素与其右方相邻像素之间灰度值的差值,1≤k≤n,n表示算法总迭代次数;
依据矩阵对(pk-1,qk-1)生成纵向自适应加权参数ak-1和横向自适应加权参数bk-1;
根据矩阵对(pk-1,qk-1)、ak-1和bk-1以及预构建的矩阵组(p,q,a,b),得到矩阵组(pk-1,qk-1,ak-1,bk-1);a表示数字图像x中像素的纵向自适应加权参数,b表示数字图像x中像素的横向自适应加权参数;ak-1表示数字图像xk-1中像素的纵向自适应加权参数,bk-1表示数字图像xk-1中像素的横向自适应加权参数;
依据矩阵组(pk-1,qk-1,ak-1,bk-1)利用梯度投影算法得到矩阵对(pk,qk);pk表示第k次迭代后p的值,qk表示第k次迭代后q的值;
依据矩阵对(pk,qk)生成纵向自适应加权参数ak和横向自适应加权参数bk,得到矩阵组(pk,qk,ak,bk);ak表示第k次迭代后的数字图像xk中像素的纵向自适应加权参数,bk表示第k次迭代后的数字图像xk中像素的横向自适应加权参数;
依据矩阵组(pk,qk,ak,bk)得到第k次迭代后的数字图像xk;
若迭代次数小于设定的迭代次数n,则迭代次数加1重新执行上述迭代步骤,否则,迭代结束,获得最终的复原图像xn;
其中,所述噪声模糊图像复原模型包括保真项和自适应加权全变分正则项。
进一步的,所述噪声模糊图像复原模型的建立方法包括如下步骤:
建立噪声模糊图像f的数学模型:
f=axoriginal+nadditive(1)
式(1)中,f∈rm×n为含有噪声的模糊图像,rm×n代表大小为m行n列的矩阵,xoriginal∈rm×n为清晰图像,a为模糊算子,nadditive∈rm×n为加入到模糊图像axoriginal中的加性噪声;
建立如下自适应加权全变分噪声模糊图像复原模型:
式(2)中,
建立如下自适应加权全变分正则项模型:
式(3)中,i和j分别代表矩阵中元素所在的行和列坐标,xi,j代表数字图像x中图像像素坐标(i,j)处的像素值;xi+1,j代表数字图像x中图像像素坐标(i+1,j)处的像素值;xi,j+1代表数字图像x中图像像素坐标(i,j+1)处的像素值;xi,n代表数字图像x中图像像素坐标(i,n)处的像素值;xi+1,n代表数字图像x中图像像素坐标(i+1,n)处的像素值;xm,j代表数字图像x中图像像素坐标(m,j)处的像素值;xm,j+1代表数字图像x中图像像素坐标(m,j+1)处的像素值;ai,j代表数字图像x中图像像素坐标(i,j)处纵向自适应加权参数的值;bi,j代表数字图像x中图像像素坐标(i,j)处横向自适应加权参数的值;ai,n代表数字图像x中图像像素坐标(i,n)处纵向自适应加权参数的值;bm,j代表数字图像x中图像像素坐标(m,j)处横向自适应加权参数的值;i=0,1,…,m-1,j=0,1,…,n-1;纵向自适应加权参数的取值范围是0≤ai,j≤1,横向自适应加权参数的取值范围是0≤bi,j≤1。
进一步的,所述矩阵对(p,q)的构建方法如下:
根据噪声模糊图像f的大小m×n构建大小为(m+1)×n的数字矩阵为p,p∈r(m+1)×n,构建大小为m×(n+1)的数字矩阵为q,q∈rm×(n+1);
令pi,j代表数字矩阵p中元素坐标(i,j)处的元素值,qi,j代表数字矩阵q中元素坐标(i,j)处的元素值,i和j分别代表矩阵中元素所在的行和列坐标,i=0,1,…,m,j=0,1,…,n,则满足:
根据所构建的数字矩阵p和q构建矩阵对(p,q)。
进一步的,所述矩阵组(p,q,a,b)的构建方法如下:
根据噪声模糊图像f的大小m×n构建大小为(m-1)×(n-1)的数字矩阵为a,a∈r(m-1)×(n-1),ai,j代表数字矩阵a中元素坐标(i,j)处的元素值,则:
式中:i和j分别代表矩阵中元素所在的行和列坐标,i=0,1,…,m-1,j=0,1,…,n-1;ω是大于0的常数;
构建大小为(m-1)×(n-1)的数字矩阵为b,b∈r(m-1)×(n-1),bi,j代表数字矩阵b中元素坐标(i,j)处的元素值,则:
根据所构建的数字矩阵p、q、a、b构建矩阵组(p,q,a,b)。
进一步的,所述xk-1的初始赋值公式如下:
x0=0m×n(7)
式(7)中,x0代表第1次迭代开始时xk-1的值,0m×n代表大小为m×n的零矩阵。
进一步的,纵向自适应加权参数ak-1的生成公式如下:
横向自适应加权参数bk-1的生成公式如下:
式中:ak-1∈r(m-1)×(n-1)是大小为(m-1)×(n-1)的数字矩阵,ω是大于0的常数;bk-1∈r(m-1)×(n-1)是大小为(m-1)×(n-1)的数字矩阵。
进一步的,所述矩阵对(pk,qk)的计算方法如下:
建立函数g(·),数学定义为:
求取g(x)对于x的一阶导数g'(x)公式如下所示:
g'(x)=2at(ax-f)(11)
式(11)中,at为模糊算子a的转置;
求取g(x)对于x的二阶导数g”(x)公式如下所示:
g”(x)=2ata(12)
式(10)的lipschitz常数l的数学定义为:
使用tylor公式对式(10)进行展开,式(10)在xk-1处的tylor展开式表示成如下数学形式:
式(14)中,0!代表0的阶层,1!代表1的阶层,2!代表2的阶层,t!代表t的阶层,(t+1)!代表t+1的阶层,g'(xk-1)代表g(x)在xk-1处的一阶导数值,g”(xk-1)代表g(x)在xk-1处的二阶导数值,g(t)(xk-1)代表g(x)在xk-1处的t阶导数值,g(t+1)(xk-1+θ(x-xk-1))是g(x)在xk-1+θ(x-xk-1)处的t+1阶导数值,0≤t,0<θ<1;
联合式(11)、(12)、(13)和(14),取式(14)前三项,将式(14)表示成如下的数学形式:
式(15)中,略去式(14)前三项,式(15)表示成如下的数学形式:
建立函数γ(·),数学定义为:
γ(pi,j,qi,j,ai,j,bi,j)=ai,j(pi,j-pi-1,j)+bi,j(qi,j-qi,j-1)(17)
联合式(2)、(3)、(16)和(17),将第k-1次迭代后式(2)表示成如下的数学形式:
建立函数φ(·),数学定义为:
式(19)中,m代表数字图像x像素的灰度位数,m≥1;
联合式(18)和(19),将式(18)表示成如下的数学形式:
建立函数h(·),数学定义为:
建立函数λ(·),数学定义为:
λ(x)=(p,q)(22)
式(21)在(pk-1,qk-1,ak-1,bk-1)处的一阶导数值h'(pk-1,qk-1,ak-1,bk-1)公式如下所示:
建立函数p(·),数学定义为:
联合式(23)和(24),利用梯度投影算法计算出第k次迭代后矩阵对(pk,qk)的值,计算方式如下所示:
式(25)中,
进一步的,第k次迭代后复原图像xk值的计算方式如下所示:
第二方面,本发明实施例提供了一种噪声模糊图像非盲复原系统,包括处理器及存储介质;
所述存储介质用于存储指令;
所述处理器用于根据所述指令进行操作以执行根据前述任一项所述方法的步骤。
第三方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现前述任一项所述方法的步骤。
与现有技术相比,本发明实施例所提供的一种噪声模糊图像非盲复原方法、系统及存储介质所达到的有益效果包括:
本发明实施例能够依据图像中相邻像素之间灰度值的差异自适应生成该像素横向和纵向正则化加权参数;通过本发明实施例提供的噪声模糊图像非盲复原方法能够改善图像纹理部分和细节部分的复原能力,提升噪声模糊图像的复原效果。
附图说明
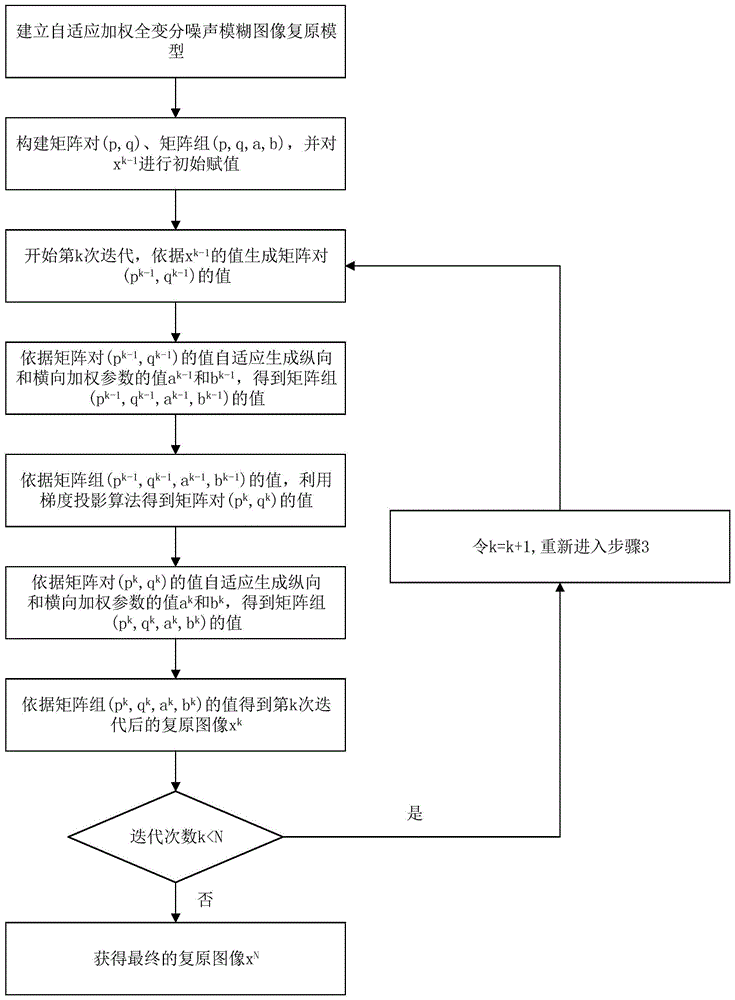
图1是根据本发明实施例提供的一种噪声模糊图像非盲复原方法的实现流程图;
图2a是“peppers”清晰图像;
图2b是“peppers”噪声运动模糊图像;
图2c是对“peppers”噪声运动模糊图像采用全变分方法得到的复原图像;
图2d是对“peppers”噪声运动模糊图像采用本发明方法得到的复原图像;
图2e是“peppers”噪声高斯模糊图像;
图2f是对“peppers”噪声高斯模糊图像采用全变分方法得到的复原图像;
图2g是对“peppers”噪声高斯模糊图像采用本发明方法得到的复原图像;
图2h是“peppers”噪声平均模糊图像;
图2i是对“peppers”噪声平均模糊图像采用全变分方法得到的复原图像;
图2j是对“peppers”噪声平均模糊图像采用本发明方法得到的复原图像;
图3a是“plane”清晰图像;
图3b是对“plane”噪声运动模糊图像;
图3c是对“plane”噪声运动模糊图像采用全变分方法得到的复原图像;
图3d是对“plane”噪声运动模糊图像采用本发明方法得到的复原图像;
图3e是“plane”噪声高斯模糊图像;
图3f是对“plane”噪声高斯模糊图像采用全变分方法得到的复原图像;
图3g是对“plane”噪声高斯模糊图像采用本发明方法得到的复原图像;
图3h是“plane”噪声平均模糊图像;
图3i是对“plane”噪声平均模糊图像采用全变分方法得到的复原图像;
图3j是对“plane”噪声平均模糊图像采用本发明方法得到的复原图像;
图4a是“milkdrop”清晰图像;
图4b是“milkdrop”噪声运动模糊图像;
图4c是对“milkdrop”噪声运动模糊图像采用全变分方法得到的复原图像;
图4d是对“milkdrop”噪声运动模糊图像采用本发明方法得到的复原图像;
图4e是“milkdrop”噪声高斯模糊图像;
图4f是对“milkdrop”噪声高斯模糊图像采用全变分方法得到的复原图像;
图4g是对“milkdrop”噪声高斯模糊图像采用本发明方法得到的复原图像;
图4h是“milkdrop”噪声平均模糊图像;
图4i是对“milkdrop”噪声平均模糊图像采用全变分方法得到的复原图像;
图4j是对“milkdrop”噪声平均模糊图像采用本发明方法得到的复原图像。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
如图1所示,是本发明实施例提供的一种噪声模糊图像非盲复原方法的实现方法流程图,包括以下步骤:
步骤1:建立自适应加权全变分噪声模糊图像复原模型,具体包括如下步骤:
建立如下所示大小为m×n的数字噪声模糊图像f的数学模型:
f=axoriginal+nadditive(1)
式(1)中,f∈rm×n为含有噪声的模糊图像,rm×n代表大小为m行n列的矩阵,xoriginal∈rm×n为清晰图像,a为模糊算子,nadditive∈rm×n为加入到模糊图像axoriginal中的加性噪声;
建立如下自适应加权全变分噪声模糊图像复原模型:
式(2)中,
建立如下自适应加权全变分正则项模型:
式(3)中,i和j分别代表矩阵中元素所在的行和列坐标(数字图像x也是一种矩阵),xi,j代表数字图像x中图像像素坐标(i,j)处的像素值,xi+1,j代表数字图像x中图像像素坐标(i+1,j)处的像素值,xi,j+1代表数字图像x中图像像素坐标(i,j+1)处的像素值,xi,n代表图像x中图像像素坐标(i,n)处的像素值,xi+1,n代表数字图像x中图像像素坐标(i+1,n)处的像素值,xm,j代表数字图像x中图像像素坐标(m,j)处的像素值,xm,j+1代表数字图像x中图像像素坐标(m,j+1)处的像素值,ai,j代表数字图像x中图像像素坐标(i,j)处纵向自适应加权参数的值,bi,j代表数字图像x中图像像素坐标(i,j)处横向自适应加权参数的值,ai,n代表数字图像x中图像像素坐标(i,n)处纵向自适应加权参数的值,bm,j代表数字图像x中图像像素坐标(m,j)处横向自适应加权参数的值,i=0,1,…,m-1,j=0,1,…,n-1,纵向自适应加权参数的取值范围是0≤ai,j≤1,横向自适应加权参数的取值范围是0≤bi,j≤1。
步骤2:构建矩阵对(p,q)、矩阵组(p,q,a,b),并对xk-1进行初始赋值,其中:xk-1表示第k-1次迭代后的数字图像;p表示数字图像x中像素与其下方相邻像素之间灰度值的差值,q表示数字图像x中像素与其右方相邻像素之间灰度值的差值;pk-1表示第k-1次迭代后数字图像xk-1中像素与其下方相邻像素之间灰度值的差值,qk-1表示第k-1次迭代后数字图像xk-1中像素与其右方相邻像素之间灰度值的差值,1≤k≤n,n表示算法总迭代次数,具体包括如下步骤:
step201:建立矩阵对(p,q),数学定义如下所示:
式(4)中,i和j分别代表矩阵中元素所在的行和列坐标,p∈r(m+1)×n是大小为(m+1)×n的数字矩阵,pi,j代表数字矩阵p中元素坐标(i,j)处的元素值,表示数字图像x中坐标(i,j)与坐标(i+1,j)处的像素之间灰度值的差值(由于图像x边界的限制,数字矩阵p中第0行与第m行无法计算,值全部赋0),q∈rm×(n+1)是大小为m×(n+1)的数字矩阵,qi,j代表数字矩阵q中元素坐标(i,j)处的元素值,表示数字图像x中坐标(i,j)与坐标(i,j+1)处的像素之间灰度值的差值(由于图像x边界的限制,数字矩阵q中第0列与第n列无法计算,值全部赋0),i=0,1,…,m,j=0,1,…,n;
step202:建立矩阵组(p,q,a,b),依据矩阵对(p,q)的值自适应生成纵向和横向加权参数的值a和b,a表示数字图像x中像素的纵向自适应加权参数,用于表征数字图像x中像素与其下方相邻像素之间灰度值的差值以及其右方相邻像素之间灰度值的差值之间的一种比较程度;b表示数字图像x中像素的横向自适应加权参数,用于表征数字图像x中像素与其右方相邻像素之间灰度值的差值以及其下方相邻像素之间灰度值的差值之间的一种比较程度,纵向自适应加权参数ai,j的值计算方式如下所示:
式(5)中,a∈r(m-1)×(n-1)是大小为(m-1)×(n-1)的数字矩阵,i和j分别代表矩阵中元素所在的行和列坐标,ai,j代表数字图像x中图像像素坐标(i,j)处纵向自适应加权参数的值(即数字矩阵a中元素坐标(i,j)处的元素值),用于表征数字图像x中坐标(i,j)与坐标(i+1,j)处的像素之间灰度值的差值与坐标(i,j)与坐标(i,j+1)处的像素之间灰度值的差值之间的一种比较程度,i=1,…,m-1,j=1,…,n-1,ω是一个略大于0的常数(避免分母为0);
step203:横向自适应加权参数bi,j的值计算方式如下所示:
式(6)中,b∈r(m-1)×(n-1)是大小为(m-1)×(n-1)的数字矩阵,i和j分别代表矩阵中元素所在的行和列坐标,bi,j代表数字图像x中图像像素坐标(i,j)处横向自适应加权参数的值(即数字矩阵b中元素坐标(i,j)处的元素值),用于表征数字图像x中坐标(i,j)与坐标(i,j+1)处的像素之间灰度值的差值与坐标(i,j)与坐标(i+1,j)处的像素之间灰度值的差值之间的一种比较程度,i=1,…,m-1,j=1,…,n-1,ω是一个略大于0的常数(避免分母为0);
对xk-1进行初始赋值,公式如下所示:
x0=0m×n(7)
式(7)中,x0代表第1次迭代开始时xk-1的值,0m×n代表大小为m×n的零矩阵。
步骤3:开始第k次迭代,依据xk-1的值生成矩阵对(pk-1,qk-1)的值。
依据式(4),第k-1次迭代后矩阵对(pk-1,qk-1)的值计算方式如下所示:
式(8)中,pk-1表示第k-1次迭代后数字图像xk-1中像素与其下方相邻像素之间灰度值的差值,qk-1表示第k-1次迭代后数字图像xk-1中像素与其右方相邻像素之间灰度值的差值,k=1,…,n,i和j分别代表矩阵中元素所在的行和列坐标,pk-1∈r(m+1)×n是大小为(m+1)×n的数字矩阵,
步骤4:依据矩阵对(pk-1,qk-1)的值自适应生成纵向和横向加权参数的值ak-1和bk-1,得到矩阵组(pk-1,qk-1,ak-1,bk-1)的值;
ak-1表示数字图像xk-1中像素的纵向自适应加权参数,用于表征数字图像xk-1中像素与其下方相邻像素之间灰度值的差值以及其右方相邻像素之间灰度值的差值之间的一种比较程度;bk-1表示数字图像xk-1中像素的横向自适应加权参数,用于表征数字图像xk-1中像素与其右方相邻像素之间灰度值的差值以及其下方相邻像素之间灰度值的差值之间的一种比较程度;
step401:联合式(5)和(8),第k-1次迭代后纵向自适应加权参数ak-1的值计算方式如下所示:
式(9)中,ak-1代表第k-1次迭代后依据矩阵对(pk-1,qk-1)的值自适应生成纵向加权参数的值,k=1,…,n,ak-1∈r(m-1)×(n-1)是大小为(m-1)×(n-1)的数字矩阵,i和j分别代表矩阵中元素所在的行和列坐标,
step402:联合式(6)和(8),第k-1次迭代后横向自适应加权参数bk-1的值计算方式如下所示:
式(10)中,bk-1代表第k-1次迭代后依据矩阵对(pk-1,qk-1)的值自适应生成横向加权参数的值,k=1,…,n,bk-1∈r(m-1)×(n-1)是大小为(m-1)×(n-1)的数字矩阵,i和j分别代表矩阵中元素所在的行和列坐标,
step403:联合式(8)、(9)和(10),可以得到第k-1次迭代后矩阵组(pk-1,qk-1,ak-1,bk-1)的值。
步骤5:依据矩阵组(pk-1,qk-1,ak-1,bk-1)的值,利用梯度投影算法得到矩阵对(pk,qk)的值;
step501:建立一个函数g(·),数学定义为:
式(11)对于x的一阶导数g'(x)公式如下所示:
g'(x)=2at(ax-f)(12)
式(12)中,at为模糊算子a的转置;
式(11)对于x的二阶导数g”(x)公式如下所示:
g”(x)=2ata(13)
式(11)的lipschitz常数l的数学定义为:
step502:使用tylor公式对式(11)进行展开,式(11)在xk-1处的tylor展开式表示成如下数学形式:
式(15)中,0!代表0的阶层,1!代表1的阶层,2!代表2的阶层,t!代表t的阶层,(t+1)!代表t+1的阶层,g'(xk-1)代表g(x)在xk-1处的一阶导数值,g”(xk-1)代表g(x)在xk-1处的二阶导数值,g(t)(xk-1)代表g(x)在xk-1处的t阶导数值,g(t+1)(xk-1+θ(x-xk-1))是g(x)在xk-1+θ(x-xk-1)处的t+1阶导数值,0≤t,0<θ<1;
step503:联合式(12)、(13)、(14)和(15),取式(15)前三项,将式(15)表示成如下的数学形式:
式(16)中,由于噪声模糊图像复原是工程问题,略去式(15)前三项之后的高阶无穷小在数字噪声模糊图像实际复原中是完全能够接受的;
式(16)可以表示成如下的数学形式:
step504:建立一个函数γ(·),数学定义为:
γ(pi,j,qi,j,ai,j,bi,j)=ai,j(pi,j-pi-1,j)+bi,j(qi,j-qi,j-1)(18)
联合式(2)、(3)、(17)和(18),可以将第k-1次迭代后式(2)表示成如下的数学形式:
step505:建立一个函数φ(·),数学定义为:
式(20)中,m代表数字图像x像素的灰度位数,m≥1;
联合式(19)和(20),可以将式(19)表示成如下的数学形式:
step506:建立一个函数h(·),数学定义为:
step507:建立一个函数λ(·),数学定义为:
λ(x)=(p,q)(23)
式(22)在(pk-1,qk-1,ak-1,bk-1)处的一阶导数值h'(pk-1,qk-1,ak-1,bk-1)公式如下所示:
step508:建立一个函数p(·),数学定义为:
联合式(24)和(25),利用梯度投影算法可以计算出第k次迭代后矩阵对(pk,qk)的值,计算方式如下所示:
式(26)中,
步骤6:依据矩阵对(pk,qk)的值自适应生成纵向和横向加权参数的值ak和bk,得到矩阵组(pk,qk,ak,bk)的值;
step601:联合式(5)和(26),第k次迭代后纵向自适应加权参数ak的值计算方式如下所示:
式(27)中,ak代表第k次迭代后依据矩阵对(pk,qk)的值自适应生成纵向加权参数的值,k=1,…,n,ak∈r(m-1)×(n-1)是大小为(m-1)×(n-1)的数字矩阵,i和j分别代表矩阵中元素所在的行和列坐标,
step602:联合式(6)和(26),第k次迭代后横向自适应加权参数bk的值计算方式如下所示:
式(28)中,bk代表第k次迭代后依据矩阵对(pk,qk)的值自适应生成横向加权参数的值,k=1,…,n,bk∈r(m-1)×(n-1)是大小为(m-1)×(n-1)的数字矩阵,i和j分别代表矩阵中元素所在的行和列坐标,
step603:联合式(26)、(27)和(28),可以得到第k次迭代后矩阵组(pk,qk,ak,bk)的值。
步骤7:依据矩阵组(pk,qk,ak,bk)的值得到第k次迭代后的复原图像xk。
联合式(19)和(pk,qk,ak,bk)的值,第k次迭代后复原图像xk值的计算方式如下所示:
步骤8:判断迭代次数k是否小于设定的迭代次数n,如果k<n,令k=k+1,并重新进入步骤3;如果k=n,迭代结束,获得最终的复原图像xn。
本发明实施例能够依据图像中相邻像素之间灰度值的差异自适应生成该像素横向和纵向正则化加权参数;通过本发明实施例提供的噪声模糊图像非盲复原方法能够改善图像纹理部分和细节部分的复原能力,提升噪声模糊图像的复原效果。
为进一步对本发明实施例所提供的一种噪声模糊图像非盲复原方法进行解释说明,下面将采用psnr(峰值信噪比)来对全变分噪声模糊图像非盲复原方法和本发明实施例提出的一种噪声模糊图像非盲复原方法的图像复原能力进行比较。应当理解,以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
psnr的数学定义如下所示:
公式(30)中,m≥1代表数字图像像素的灰度位数,2m-1是m位灰度图像灰度值取值的最大数值,图像的大小为m×n,xi,j代表清晰图像中图像像素坐标(i,j)处的像素值,yi,j代表检测图像中图像像素坐标(i,j)处的像素值。
psnr是一种在图像处理中使用最为广泛的图像客观评价指标,用来衡量清晰图像与检测图像之间的失真程度,psnr取得的值越大,表示清晰图像与检测图像之间失真程度越小。
将模糊算子a分别设置为运动模糊算子(运动位移为12个像素,运动角度为6度)、高斯模糊算子(模版尺寸为9×9,标准值为6)、平均模糊算子(模版尺寸为7×7)。通过模糊算子a将清晰图像“peppers”、“plane”、“milkdrop”分别变换为“peppers”运动模糊图像、“peppers”高斯模糊图像、“peppers”平均模糊图像、“plane”运动模糊图像、“plane”高斯模糊图像、“plane”平均模糊图像、“milkdrop”运动模糊图像、“milkdrop”高斯模糊图像、“milkdrop”平均模糊图像。
将均值为0.255且正态分布的高斯白噪声加入“peppers”运动模糊图像、“peppers”高斯模糊图像、“peppers”平均模糊图像、“plane”运动模糊图像、“plane”高斯模糊图像、“plane”平均模糊图像、“milkdrop”运动模糊图像、“milkdrop”高斯模糊图像、“milkdrop”平均模糊图像中,分别得到“peppers”噪声运动模糊图像、“peppers”噪声高斯模糊图像、“peppers”噪声平均模糊图像、“plane”噪声运动模糊图像、“plane”噪声高斯模糊图像、“plane”噪声平均模糊图像、“milkdrop”噪声运动模糊图像、“milkdrop”噪声高斯模糊图像、“milkdrop”噪声平均模糊图像。
取正则化参数λ=0.0001,lipschitz常数l=2,常数ω=0.00001,迭代次数n=3000,分别使用全变分方法和本发明方法对“peppers”噪声运动模糊图像、“peppers”噪声高斯模糊图像、“peppers”噪声平均模糊图像、“plane”噪声运动模糊图像、“plane”噪声高斯模糊图像、“plane”噪声平均模糊图像、“milkdrop”噪声运动模糊图像、“milkdrop”噪声高斯模糊图像、“milkdrop”噪声平均模糊图像进行复原。
图2a是“peppers”清晰图像;图2b是“peppers”噪声运动模糊图像;图2c是“peppers”噪声运动模糊图像采用全变分方法复原图像;图2d是“peppers”噪声运动模糊图像采用本发明方法复原图像;图2e是“peppers”噪声高斯模糊图像;图2f是“peppers”噪声高斯模糊图像采用全变分方法复原图像;图2g是“peppers”噪声高斯模糊图像采用本发明方法复原图像;图2h是“peppers”噪声平均模糊图像;图2i是“peppers”噪声平均模糊图像采用全变分方法复原图像;图2j是“peppers”噪声平均模糊图像采用本发明方法复原图像。
图3a是“plane”清晰图像;图3b是“plane”噪声运动模糊图像;图3c是“plane”噪声运动模糊图像采用全变分方法复原图像;图3d是“plane”噪声运动模糊图像采用本发明方法复原图像;图3e是“plane”噪声高斯模糊图像;图3f是“plane”噪声高斯模糊图像采用全变分方法复原图像;图3g是“plane”噪声高斯模糊图像采用本发明方法复原图像;图3h是“plane”噪声平均模糊图像;图3i是“plane”噪声平均模糊图像采用全变分方法复原图像;图3j是“plane”噪声平均模糊图像采用本发明方法复原图像。
图4a是“milkdrop”清晰图像;图4b是“milkdrop”噪声运动模糊图像;图4c是“milkdrop”噪声运动模糊图像采用全变分方法复原图像;图4d是“milkdrop”噪声运动模糊图像采用本发明方法复原图像;图4e是“milkdrop”噪声高斯模糊图像;图4f是“milkdrop”噪声高斯模糊图像采用全变分方法复原图像;图4g是“milkdrop”噪声高斯模糊图像采用本发明方法复原图像;图4h是“milkdrop”噪声平均模糊图像;图4i是“milkdrop”噪声平均模糊图像采用全变分方法复原图像;图4j是“milkdrop”噪声平均模糊图像采用本发明方法复原图像。实验结果如表1所示:
表1给出了分别采用全变分方法和本发明实施例提供的方法对“peppers”噪声运动模糊图像、“peppers”噪声高斯模糊图像、“peppers”噪声平均模糊图像、“plane”噪声运动模糊图像、“plane”噪声高斯模糊图像、“plane”噪声平均模糊图像、“milkdrop”噪声运动模糊图像、“milkdrop”噪声高斯模糊图像、“milkdrop”噪声平均模糊图像进行复原后复原图像的psnr值。可以看到在进行实验的所有图像中,本发明实施例提供的方法对于全变分方法在psnr上均有不同程度的提高,因此,本发明实施例提供的方法相比全变分方法对于噪声模糊图像有着更好的复原效果。
本发明实施例还提供了一种噪声模糊图像非盲复原系统,包括处理器及存储介质;
所述存储介质用于存储指令;
所述处理器用于根据所述指令进行操作以执行根据前述任一项所述方法的步骤。
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现前述任一项所述方法的步骤。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!