一种快速时空残差注意力视频超分辨率重建方法与流程
本发明涉及视频超分辨率重建领域技术,尤其涉及一种快速时空残差注意力视频超分辨率重建方法。
背景技术:
视频超分辨率重建是一种将视频的连续低分辨率视频重建为其相应的高分辨率视频的技术。视频超分辨率重建技术在卫星成像、安防监控、以及视频传输优化有着极其重要的作用。
得益于深度学习在计算机视觉领域的快速发展,dong等人首次利用基于深度学习的3层网络从单张低分辨率图像重建出其对应的超分辨率图像,大幅超越传统的插值重建方法[1]。自此开始越来越多的基于深度学习的超分辨率方法被发明出来。视频超分辨率可以简单地一帧一帧地使用图像超分重建方法进行超分,但这忽视了视频序列中帧间连续性带来的帧与帧之间的相关性和互补信息。因此,不同于图像超分辨率,如何高效利用视频的帧间连续帧带来的更多的信息往往被看作视频超分重建的一个关键。
为了提高视频超分辨率的重建效果,深度学习的视频超分辨率方法主要使用视频前后连续帧片段重建出其对应的一张高分辨率视频帧。
近年来,视频超分辨率基本上使用二维卷积网络学习低分辨率视频连续帧的特征,但是二维卷积不能直接作用于视频四维数据(帧序列、宽、高、色彩通道),因此帧间融合技术往往被引入以用来融合多帧之间的信息。中国发明专利“基于双向循环卷积网络的视频超分辨率方法和系统”(公开号cn105072373b,公开日为2018.03.27)采用双向循环卷积网络将前后相关联的帧信息用于辅助超分重建。kappeler等人设计了基于深度卷积神经网络的视频超分辨率复原方法(videosuper-resolutionusingconvolutionalneuralnetwork,vsrcnn)[5],使用了堆叠的方式将前后关联帧图像与当前帧在颜色维度堆叠,然后放入网络进行训练以达到融合多帧信息的效果。在caballero等人设计的具有时空网络和运动补偿的实时视频超分辨率方法(videoefficientsub-pixelconvolutionalneuralnetwork,vespcn)[6]以及tao等人设计的深层细节的视频超分辨率方法(sub-pixelmotioncompensationvideosuper-resolution,spmc-videosr)[7]等都引入了运动估计来估算帧间信息,从而融合多帧信息。中国公开专利“一种基于深度学习的视频超分辨率重建方法”(公开号cn109102462a,公开日期2018.12.28)使用3d卷积构建了双向循环神经网络使用3d卷积进行时空特征融合。
尽管已有多种引入帧间信息融合的视频超分辨率复原方法,但是实际应用中,无论是运动估计还是原始的3d卷积都会消耗巨大的计算资源,这会导致重建时间过长,网络的深度不能变的更深,使其重建效果并不令人满意。本发明可以在一定程度上解决最后重建过程中丢失过多的高频信息问题。
本发明中涉及的参考文献如下:
[1]c.dong,c.c.loy,k.he,andx.tang,“learningadeepconvolutionalnetworkforimagesuper-resolution,”ineuropeanconferenceoncomputervision,2014,pp.184–199.
[2]c.ledigetal.,“photo-realisticsingleimagesuper-resolutionusingagenerativeadversarialnetwork,”incvpr,2017,vol.2,no.3,p.4.
[3]y.zhang,y.tian,y.kong,b.zhong,andy.fu,“residualdensenetworkforimagesuper-resolution,”incvpr,2018.
[4]y.huang,w.wang,andl.wang,“bidirectionalrecurrentconvolutionalnetworksformulti-framesuper-resolution,”inadvancesinneuralinformationprocessingsystems,2015,pp.235–243.
[5]a.kappeler,s.yoo,q.dai,anda.k.katsaggelos,“videosuper-resolutionwithconvolutionalneuralnetworks,”ieeetransactionsoncomputationalimaging,vol.2,no.2,pp.109–122,2016.
[6]j.caballeroetal.,“real-timevideosuper-resolutionwithspatio-temporalnetworksandmotioncompensation,”inieeeconferenceoncomputervisionandpatternrecognition(cvpr),2017.
[7]x.tao,h.gao,r.liao,j.wang,andj.jia,“detail-revealingdeepvideosuper-resolution,”inproceedingsoftheieeeinternationalconferenceoncomputervision,venice,italy,2017,pp.22–29.
技术实现要素:
为了解决上述技术问题,本发明提供了一种快速时空残差注意力视频超分辨率重建方法,通过将一个三维时空卷积拆分成两个三维时空分步卷积减少计算量,并有效结合不同层次的残差学习,不仅可以使得视频超分辨率重建的视频更加清晰,显著提高了视频显示的效果,同时也保证了较低的计算资源消耗,而且避免在最后重建过程中丢失过多的高频信息。
本发明采用的技术方案是一种快速时空残差注意力视频超分辨率重建方法,通过在神经网络模型中增加注意力上采样机制,将网络注意力集中于高频信息,从而得到更好的恢复结果;
视频超分辨率重建实现过程包括训练与测试数据准备,设置神经网络模型的网络结构,训练好神经网络模型,将测试的低分辨率视频输入到训练好的神经网络模型中,模型的输出为重建后的超分辨率视频帧,将得到的连续帧合成视频得到超分辨率视频;
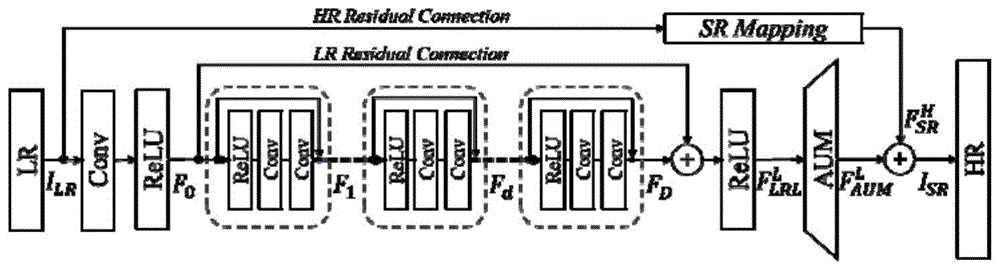
所述神经网络模型的网络结构,包括低分辨率特征提取部分、快速时空残差块部分、高分辨率重建部分和高分辨率残差学习部分,所述高分辨率重建部分包括一个用于融合特征的3d卷积,之后分为高分辨率映射分支和注意力模块分支,最后两个分支相乘并使用一个卷积融合特征。
而且,所述低分辨率特征提取部分,包括对输入的低分辨率视频lr应用3d卷积和激活函数运算进行特征提取,输出结果f0。
而且,所述快速时空残差块部分,由若干个快速时空残差块组成,第一个残差块输入为低分辨率特征提取部分输出,之后每个残差块输入为上一个残差块的输出。
而且,高分辨率重建部分的输入为快速时空残差块部分的输出,高分辨率映射分支对快速时空残差块部分输出的融合结果
而且,高分辨率残差学习部分中,引入一个映射函数,将低分视频lr映射到高分空间,然后和高分辨率重建部分的输出相加,取其结果的中间一帧作为最后的超分结果。
本发明采用以上技术方案,特点在于:第一,本发明提出使用三维卷积对低分辨率的视频进行特征提取,可以避免进行传统的光流法估计运动补偿,为了进一步减小计算资源的消耗,本发明提出快速时空残差块,使用连续的空间三维卷积和时间三维卷积替代时空三维卷积,这可以减少大量的计算消耗并能很好地学习到低分辨率视频的时空特征。第二,与最经典的基于深度学习的残差超分辨率网络相比,本发明提出在低分辨率上应用残差学习之外,将低分辨率视频直接映射到高分辨率空间以构建高分辨率空间的残差学习,这可以有效减缓视频重建部分的压力,极大地提高视频图像的重建效果。第三,增加了注意力上采样模块,这个模块可以很好地将网络注意力集中于高频信息,从而得到更好的恢复结果。
附图说明
图1是本发明实施例中快速时空残差注意力视频超分辨率重建方法的原理示意图;
图2是本发明实施例中快速时空残差块原理示意图;
图3是图1中的部分细节图。
具体实施方式
下面结合附图及实施例对本发明作进一步的详细描述。
如图1所示,本发明实施例公开了一种快速时空残差注意力视频超分辨率重建方法,其包括如下步骤:
步骤1:训练与测试数据准备:
采集连续镜头拍摄的n个视频,从中裁剪出5×sh×sw大小的视频块,即每个视频块取5帧,裁剪的高度为sh、宽度为sw;然后进行旋转(0°,90°,180°,270°),即上下左右翻转,将得到的视频块的中间帧作为高分辨率视频hr,对得到的视频块进行下采样s倍得到5×h×w低分辨率视频块lr,高度为h、宽度为w,这些高低分辨率作为视频对(lr,hr)用于网络的训练和测试。取视频对的90%作为训练视频对,10%作为测试视频对。
具体实施时,缩放比例s可预先设定,优选采用正整数。
步骤2:设置网络结构:本发明所提出的网络模型将视频对中的lr作为输入,网络输出与hr相同大小的超分结果sr。网络主要包含四个部分:
(1)低分辨率特征提取部分:对输入的低分辨率视频lr(图中记为ilr)应用一个简单的3×3×3卷积核的3d卷积conv和激活函数运算relu进行特征提取,输出结果f0,其计算公式是:
f0=max(w1*lr+b1,0)(1)
其中w1和b1分别是本发明的第一层的卷积权值参数和偏置参数;
(2)快速时空残差块部分:如图2所示本部分由d个快速时空残差块组成。具体实施时,d的取值可根据需要设置。第一个残差块输入为低分辨率特征提取部分输出,之后每个残差块输入为上一个残差块的输出。每个残差块由一个3×3×1卷积核的3d卷积(即l×k×kconv3d)和一个1×1×3卷积核的3d卷积(即k×k×lconv3d)以及一个激活函数运算relu(即图2中prelu)组成,假设残差块的输入为fd,输出为fd+1,其计算公式是:
fd+1=hd(fd)=fd+max(wd2*(wd1*fd+bd1)+bd2,0)(2)
其中hd()表示本发明快速时空残差块所代表的函数,wd1和bd1分别是本发明快速时空残差块的第一个3d卷积的卷积权值参数和偏置参数,其中wd2和bd2分别是本发明快速时空残差块的第二个3d卷积的卷积权值参数和偏置参数;
同时,本发明在这里引入低分辨率上的残差连接,将f0直接加到最后一个快速时空残差块结果上,因此快速时空残差块部分其计算公式是:
fd=f0+hd(f0)=f0+hd(hd-1(…(h2(h1(f0)))…))(3)
其中,hd()表示本发明快速时空残差块所代表的函数,d=1,2,…d。
最后应用一个激活函数relu:
(3)高分辨率重建部分(aum),详见图3:此部分的输入为快速时空残差块部分的输出,首先使用一个3d卷积conv融合特征:
其中,wp和bp分别是这个3d卷积的卷积权值参数和偏置参数。
然后分为高分辨率映射和注意力模块两部分。
参见图3中,分支upsamplingbranch:高分辨率映射部分对快速时空残差块部分输出的融合结果
其中wl1和bl1分别是本发明高分辨率重建部分3×3×3卷积核的3d反卷积卷积权值参数和偏置参数。
参见图3中,分支attentionmaskbranch:注意力模块部分对快速时空残差块部分输出fd应用一个串联连续1个下采样,然后采用n个上采样卷积,使得此处输出分辨率和高分辨率映射部分相同,其中n=s/2,s是缩放比例,输出结果为fa,其计算公式是:
其中
最后以上两部分相乘并使用一个卷积融合特征,总的输出
其中,waum和baum分别是最后一个卷积的卷积权值参数和偏置参数。
(4)高分辨率残差学习部分:由于低分辨率和高分辨率存在分辨率的区别,因此不能直接将低分辨率的视频加到高分辨率重建部分输出,本发明引入一个映射函数,将低分视频lr映射到高分空间,然后和高分辨率重建部分的输出相加,取其结果的中间一帧作为最后的超分结果,其计算公式是:
其中hs表示将低分视频lr映射到高分空间的映射函数,这可以是一个反卷积函数或者任意的插值函数,如最邻近插值、双三次插值等。
步骤3:训练:随机初始化各层的连接权值w和偏置b,使用学习速率r,可以取1e-4,采用欧氏距离计算网络输出sr和目标高分辨率帧hr之间的距离作为损失函数。
使用自适应矩估计优化器adam优化网络参数,反复迭代直到网络输出误差达到预设精度或者训练次数达到预设的最大迭代次数,训练结束,保存网络结构和参数,得到训练好的神经网络模型。
步骤4:测试:将测试的低分辨率视频输入到训练好的神经网络模型中,模型的输出即为重建后的超分辨率视频帧,将得到的连续帧合成视频便是超分辨率视频。当重建的所有高分辨率视频帧与其对应的高分辨率视频帧比较时已经获得预先设定的重建效果时,则停止优化参数,否则重复步骤3直到获得预先设定的重建效果。
本发明以上流程可采用计算机软件技术实现自动运行流程。
为了验证本发明的有效性,采用了25个yuv格式的公开视频数据集进行4倍视频超分辨率重建训练。本发明得到的重建效果与一些现有技术进行比较,例如双三次插值法、srcnn[1]、srgan[2]、rdn[3]、brcn[4]、vespcn[6],本发明较现有技术相比取得了更高的psnr和ssim值,也得到了更高质量的重建视频图像。
- 还没有人留言评论。精彩留言会获得点赞!