一种基于同义词词林语义相似度的文本聚类方法与流程
本发明涉及一种基于同义词词林语义相似度的文本聚类方法。
背景技术:
文本挖掘是提取并挖掘分布在文本数据集中所需、有价值、有用的知识,并且利用这些知识更好地组织信息的过程。文本挖掘利用智能算法,结合文字处理技术,分析大量的无规则的文本集(文本源),将蕴含在文本集中有用的信息提取出来,并按照提取出来的信息对文本集进行分类,通过这一过程,能方便我们更好的组织、获取这些有用的信息。文本挖掘是应用于我们生活的方方面面,为我们提取信息提供了一种高效快捷的方法。目前文本挖掘的主要研究内容包括关联分析、文本分类、文本聚类(textclustering)等。
文本聚类可以对文本的信息进行有效的组织、分类等处理能够帮助用户快速、准确获取所需信息。由于其不需要训练,不需要手动的对文档进行分类与标注,因此文本聚类的灵活性较强,目前成为对一个文本集进行有效的分类、组织主要工具。
目前绝大多数的聚类算法对词层面进行简单处理,如空间向量模型,在进行相似度计算时,没有充分挖掘文本的语义信息,忽略了特征项间的语义联系,它假定特征项之间是相互独立的,因此造成文本语义信息丢失,无法挖掘蕴含在文本中的语义信息,同时空间向量模型表示文本存在高维稀疏问题,最终导致聚类的准确度较低。
技术实现要素:
(一)要解决的技术问题
为了解决现有技术的上述问题,本发明提供一种基于同义词词林语义相似度的文本聚类方法。
(二)技术方案
为了达到上述目的,本发明提供一种基于同义词词林语义相似度的文本聚类方法,包括步骤:
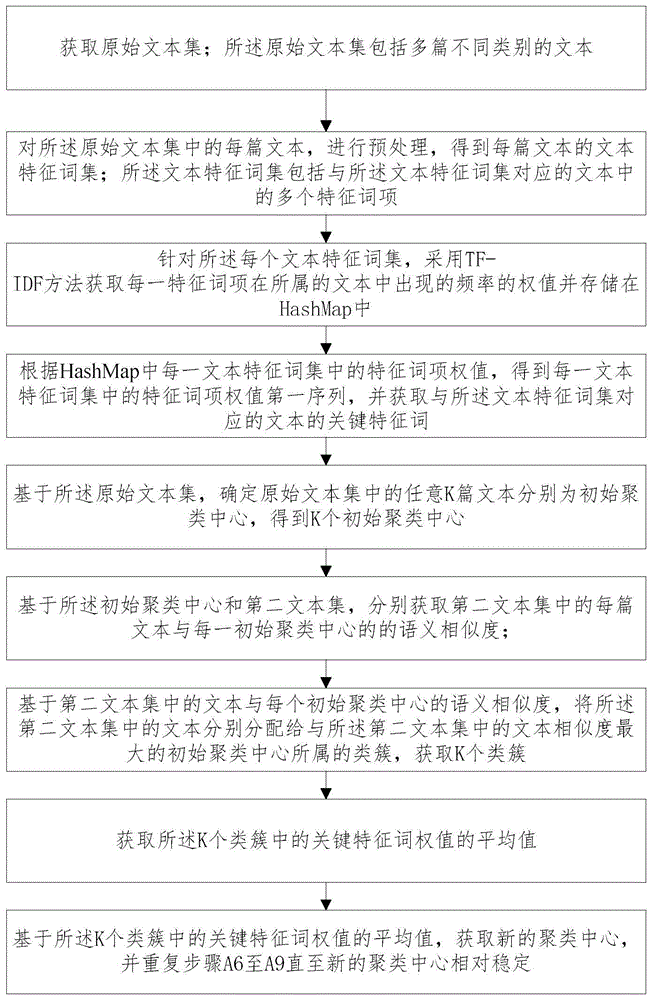
a1、获取原始文本集;所述原始文本集包括多篇不同类别的文本;
a2、对所述原始文本集中的每篇文本,进行预处理,得到每篇文本的文本特征词集;所述文本特征词集包括与所述文本特征词集对应的文本中的多个特征词项;
a3、针对所述每个文本特征词集,采用tf-idf方法获取每一特征词项在所属的文本中出现的频率的权值并存储在hashmap中;
a4、根据hashmap中每一文本特征词集中的特征词项权值,得到每一文本特征词集中的特征词项权值由高到低排列的第一序列,并获取与所述文本特征词集对应的文本的关键特征词;
所述文本的关键特征词:为所述第一序列中的前n个特征词项权重值所对应的特征词项;
其中,n为预先设定的第一序列中特征词项权值数量的百分比;
a5、基于所述原始文本集,获取k个初始聚类中心;其中,k为预先设定值;所述每个初始聚类中心均包括:所述原始文本集中的任意一篇文本;
a6、基于所述初始聚类中心和第二文本集,分别获取第二文本集中的每篇文本与每一初始聚类中心的的语义相似度;
其中,所述第二文本集中的文本包括:所述原始文本集中的k个初始聚类中心所对应k篇文本的其余文本;
a7、基于第二文本集中的文本与每个初始聚类中心的语义相似度,将所述第二文本集中的文本分别分配给与所述第二文本集中的文本相似度最大的初始聚类中心所属的类簇,获取k个类簇;
a8、获取所述k个类簇中的关键特征词权值的平均值;
a9、基于所述k个类簇中的关键特征词权值的平均值,获取新的聚类中心,并重复步骤a6至a9直至新的聚类中心相对稳定。
优选的,所述预处理包括:分词、去除停用词、歧义消除。
优选的,所述步骤a6包括:
a6-1、根据每一文本的文本特征词集,获取所述第二文本集中的每篇文本中的特征词项和初始聚类中心的特征词项;
a6-2、基于所述第二文本集中的每篇文本中的特征词项和初始聚类中心的特征词项以及预先设定的同义词词林树状结构,分别获取所述同义词词林树状结构中与所述第二文本集中的每篇文本中的特征词项所对应的编码和所述同义词词林树状结构中与所述初始聚类中心的特征词项所对应的编码;
其中,所述同义词词林树状结构包括具有多个分支层的多层结构和多个树状结构;
所述每层结构中均具有多个词语项;
所述多个词语项包括:多个特征词项;
所述词语项均具有编码;
所述编码为识别具有编码的词语项在所述同义词词林树状结构中分支层位置和树状位置的编码;
a6-3、基于所述第二文本集中的文本中的特征词项和初始聚类中心的的特征词项在所述同义词词林结构中所对应的编码,获取所述特征词项在所述同义词词林中的分支层位置或树状位置;
a6-4、基于所述词语项在同义词词林中的分支层位置和/或树状位置或编码,获取所述所述第二文本集中的文本中的特征词项和初始聚类中心的的特征词项的相似度值;
a6-5、判断所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度是否满足预先设定阈值;
a6-6、若满足,则利用tf-idf方法获取所述满足预先设定阈值的词语项在所述特征词项所属的文本中的权值;
a6-7、根据公式(1)和(2),分别获取所述第二文本集中的每一篇文本中满足预先设定的阈值的特征值数据和初始聚类中心满足预先设定的阈值的特征值数据;
其中,|ai|,|aj|分别表示这两个集合中满足阈值条件的特征值数据;
a6-8、基于公式(3)获取第二文本集中的文本和初始聚类中心的相似度;
tsim(di,dj)=tf×sim(di,dj)(3);
其中tf为权值因子;
且
其中,di=[(ti1,wi1),(ti2,wi2),…,(tim,wim)代表第二文本集中的第i个文本的向量;dj=[(tj1,wj1),(tj2,wj2),…,(tjm,wjm)代表k个初始聚类中心中的第j个初始聚类中心的向量;
sim(di,dj)表示di,dj两个文本的余弦相似度。
优选的,所述步骤a6-4步骤具体包括:
若文本中的特征词项和初始聚类中心的特征词项不在同义词词林相同树状位置上,则根据公式(4)获取所述所述第二文本集中的文本中的特征词项和初始聚类中心的的特征词项的相似度值;
wsim(w1,w2)=g(4);
其中g为常数;
若文本中的特征词项和初始聚类中心的特征词项在同义词词林相同树状位置上,并位于第二层分支,则根据公式(5)获取所述所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值;
其中,
其中,freq(w)=∑count(w),w为从特征词项w1所在的分支层到特征词项w2所在的分支层之间包含的词语项,∑count(w)为词语项的总数,n为w1和w2所在分支的全部词语项总数;b为第一系数;n代表分支层的节点总数;
若文本中的特征词项和初始聚类中心的特征词项在同义词词林相同树状位置上,并位于第三层分支,则根据公式(6)获取所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值;
其中,c为第二系数;
若文本中的特征词项和初始聚类中心的特征词项在同义词词林相同树状位置上,并位于第四层分支,则根据公式(7)获取所述所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值;
其中,d为第三系数;
若文本中的特征词项和初始聚类中心的特征词语项在同义词词林相同树状位置上,并位于第五层分支,则根据公式(8)获取所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值;
其中,e为第四系数;
若文本中的特征词项和初始聚类中心的特征词语项在同义词词林中所对应的编码相同,且所述编码具有第一预设标签时,则所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值为1;
若文本中的词语项和初始聚类中心的的特征词项在同义词词林中所对应的编码相同,且所述编码具有第二预先标签时,则所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值为f。
优选的,
所述b为0.54,c为0.77,d为0.84,e为0.89,g为0.001,f为0.42。
优选的,所述步骤a6-4中预先设定的阈值为0.7。
(三)有益效果
本发明的有益效果是:本发明在文本聚类过程中,考虑了词语间的语义信息,从而提升了聚类的准确度。
进一步的,本发明通过同义词词林充分考虑了文本之间的语义信息,有效提高文本聚类的精度。
附图说明
图1为本发明中基于同义词词林语义相似度的文本聚类方法流程图;
图2为使用本发明方法和使用余弦相似度聚类方法实验的f值对比图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
《同义词词林》是由梅家驹等人编撰的可用于计算汉语词库,共有约9万多个词语。《同义词词林》把词条分成大、中、小三类,小类下方根据词义的远近和相关性进一步划分为词群和原子词群两级,按照树状的层次结构把所有收录的词条组织到一起。其中大类有12个,中类有97个,小类有1400个左右。这样《同义词词林》就具备了5层结构。同义词词林中上面四层的节点都代表抽象的类别,随着级别的递增,词义刻画越来越细,只有最底层(第五层)的叶子节点,已经不可再分,对应词库中每一个单词。
参见附图1,本实施例中,包括步骤:
a1、获取原始文本集;所述原始文本集包括多篇不同类别的文本。
a2、对所述原始文本集中的每篇文本,进行预处理,得到每篇文本的文本特征词集;所述文本特征词集包括与所述文本特征词集对应的文本中的多个特征词项。
a3、针对所述每个文本特征词集,采用tf-idf方法获取每一特征词项在所属的文本中出现的频率的权值并存储在hashmap中。
a4、根据hashmap中每一文本特征词集中的特征词项权值,得到每一文本特征词集中的特征词项权值由高到低排列的第一序列,并获取与所述文本特征词集对应的文本的关键特征词。
所述文本的关键特征词:为所述第一序列中的前n个特征词项权重值所对应的特征词项。
其中,n为预先设定的第一序列中特征词项权值数量的百分比。
a5、基于所述原始文本集,获取k个初始聚类中心;其中,k为预先设定值;所述每个初始聚类中心均包括:所述原始文本集中的任意一篇文本。
a6、基于所述初始聚类中心和第二文本集,分别获取第二文本集中的每篇文本与每一初始聚类中心的的语义相似度。
其中,所述第二文本集中的文本包括:所述原始文本集中的k个初始聚类中心所对应k篇文本的其余文本。
a7、基于第二文本集中的文本与每个初始聚类中心的语义相似度,将所述第二文本集中的文本分别分配给与所述第二文本集中的文本相似度最大的初始聚类中心所属的类簇,获取k个类簇。
a8、获取所述k个类簇中的关键特征词权值的平均值。
a9、基于所述k个类簇中的关键特征词权值的平均值,获取新的聚类中心,并重复步骤a6至a9直至新的聚类中心相对稳定。
具体的本实施例中,所述步骤a9中新的聚类中心相对稳定,具体包括目标p函数收敛;
其中,p表示每个类的与聚类中心的距离之和;cj是第j个类簇;x是cj中的文本;aj是对应j类的聚类中心;k为类簇。
本实施例中,所述预处理包括:分词、去除停用词、歧义消除。
本实施例中,歧义消除为仅保留反应文本类别信息具有语义实意的词语。
本实施例中,所述步骤a6包括:
a6-1、根据每一文本的文本特征词集,获取所述第二文本集中的每篇文本中的特征词项和初始聚类中心的特征词项。
a6-2、基于所述第二文本集中的每篇文本中的特征词项和初始聚类中心的特征词项以及预先设定的同义词词林树状结构,分别获取所述同义词词林树状结构中与所述第二文本集中的每篇文本中的特征词项所对应的编码和所述同义词词林树状结构中与所述初始聚类中心的特征词项所对应的编码。
其中,所述同义词词林树状结构包括具有多个分支层的多层结构和多个树状结构。
所述每层结构中均具有多个词语项。
所述多个词语项包括:多个特征词项。
所述词语项均具有编码。
所述编码为识别具有编码的词语项在所述同义词词林树状结构中分支层位置和树状位置的编码。
a6-3、基于所述第二文本集中的文本中的特征词项和初始聚类中心的的特征词项在所述同义词词林结构中所对应的编码,获取所述特征词项在所述同义词词林中的分支层位置或树状位置。
a6-4、基于所述词语项在同义词词林中的分支层位置和/或树状位置或编码,获取所述所述第二文本集中的文本中的特征词项和初始聚类中心的的特征词项的相似度值。
a6-5、判断所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度是否满足预先设定阈值。
a6-6、若满足,则利用tf-idf方法获取所述满足预先设定阈值的词语项在所述特征词项所属的文本中的权值。
a6-7、根据公式(1)和(2),分别获取所述第二文本集中的每一篇文本中满足预先设定的阈值的特征值数据和初始聚类中心满足预先设定的阈值的特征值数据。
其中,|ai|,|aj|分别表示这两个集合中满足阈值条件的特征值数据。
a6-8、基于公式(3)获取第二文本集中的文本和初始聚类中心的相似度;
tsim(di,dj)=tf×sim(di,dj)(3);
其中tf为权值因子;
且
其中,di=[(ti1,wi1),(ti2,wi2),…,(tim,wim)代表第二文本集中的第i个文本的向量;dj=[(tj1,wj1),(tj2,wj2),…,(tjm,wjm)代表k个初始聚类中心中的第j个初始聚类中心的向量。
sim(di,dj)表示di,dj两个文本的余弦相似度。
优选的,所述步骤a6-4步骤具体包括:
若文本中的特征词项和初始聚类中心的特征词项不在同义词词林相同树状位置上,则根据公式(4)获取所述所述第二文本集中的文本中的特征词项和初始聚类中心的的特征词项的相似度值;
wsim(w1,w2)=g(4);
其中g为常数。
若文本中的特征词项和初始聚类中心的特征词项在同义词词林相同树状位置上,并位于第二层分支,则根据公式(5)获取所述所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值;
其中,
其中,freq(w)=∑count(w),w为从特征词项w1所在的分支层到特征词项w2所在的分支层之间包含的词语项,∑count(w)为词语项的总数,n为w1和w2所在分支的全部词语项总数;b为第一系数;n代表分支层的节点总数。
若文本中的特征词项和初始聚类中心的特征词项在同义词词林相同树状位置上,并位于第三层分支,则根据公式(6)获取所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值;
其中,c为第二系数。
若文本中的特征词项和初始聚类中心的特征词项在同义词词林相同树状位置上,并位于第四层分支,则根据公式(7)获取所述所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值;
其中,d为第三系数。
若文本中的特征词项和初始聚类中心的特征词语项在同义词词林相同树状位置上,并位于第五层分支,则根据公式(8)获取所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值;
其中,e为第四系数。
若文本中的特征词项和初始聚类中心的特征词语项在同义词词林中所对应的编码相同,且所述编码具有第一预设标签时,则所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值为1。
若文本中的词语项和初始聚类中心的的特征词项在同义词词林中所对应的编码相同,且所述编码具有第二预先标签时,则所述第二文本集中的文本中的特征词项和初始聚类中心的特征词项的相似度值为f。
本实施例中,通过实验对词语相似度测试,将参数设定b为0.54,c为0.77,d为0.84,e为0.89,g为0.001,f为0.42。
本实施例中,所述步骤a6-4中预先设定的阈值为0.7。
本实施中在文本聚类过程中,考虑了词语间的语义信息,从而提升了聚类的准确度。
进一步的,本实施例中通过同义词词林充分考虑了文本之间的语义信息,有效提高文本聚类的精度。
对本发明方法进行实验对比
本发明实验数据来自搜狗实验室语料库,从中选取了含有6大特定主题的600篇文档。该数据集分为6类:经济、体育、教育、旅游、政治、计算机各100篇。本轮实验分两组进行:实验一使用基于向量空间的余弦相似度进行文本聚类算法;实验二采用本发明提出文本聚类算法。每组实验进行8次,选取聚类效果最好的一次作为最终结果。实验结果见表5.2所示。
本发明采取信息检索领域最常用的评估方法:正确率precision(p)、召回率recall(r)、f-measure值(f)。具体解释如下:
表1两组文本聚类实验结果表
从图2中可以看出,使用本发明提出基于同义词词林语义相似度的文本聚类算法与使用余弦相似度聚类方法相比,在聚类效果上有比较明显的提高,平均f值提高5%。其原因是在文本聚类过程中,考虑了词语间的语义信息,从而提升了聚类的准确度。
以上结合具体实施例描述了本发明的技术原理,这些描述只是为了解释本发明的原理,不能以任何方式解释为对本发明保护范围的限制。基于此处解释,本领域的技术人员不需要付出创造性的劳动即可联想到本发明的其它具体实施方式,这些方式都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!