一种基于字典树的中文未登录词识别方法与流程
本发明涉及中文词识别技术领域,具体来说,涉及一种基于字典树的中文未登录词识别方法。
背景技术:
随着web2.0时代的到来,互联网飞速发展,信息的产生呈现一种爆炸增长方式,而怎么样处理这些信息就成为一个很重要的问题。而自然语言处理就是对文本信息处理的一种最有效方法之一。而在自然语言处理中就不可能回避未登录词的问题。顾名思义,未登录词即没有被收录在分词词表中但必须切分出来的词,包括各类专有名词(人名、地名、企业名等)、缩写词、新增词汇等等。在当代互联网中每天产生各种各样的未登录词,所以未登录词的识别变得越来越重要。
在一般中文未登录词处理中一般的流程为预处理-分词-运用算法、模型找到新词-和词典比较将新词加入词典。在一般的流程中在分词阶段十分依赖词典的作用,当对于词典的内容不够准确、词典的数量不足时,这其中会存在很多的问题。同时,如果在一个比较新的领域还没有形成一套完备的词典时,依赖词典的分词方法会有重大问题。
且现有其他未登录词算法的有以下缺点:
1.太依赖分词来进行发现备选词语,但有时分词的过程中也会产生一定的错误;
2.用哈希表等方式来进行词频计算每有一个词语的时候就要计算一次,在语料库很大的情况下时间复杂度和空间复杂度都是一个问题;
3.对词典有一定的依赖,但在发现新词的过程中词典的作用不大。
针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
本发明的目的在于提供一种基于字典树的中文未登录词识别方法,主要是采用字典树的方法,将输入文本直接以字典树的形式将整篇文本输入电脑中,因此本方法并不需要进行分词处理,属于一种无监督学习方法。在使用字典树方法时我们只需将文本直接输入,然后计算机将会自己不需要分词的发现所有的新词,和一般的有监督学习方法依赖词典完全不同,同时字典树的时间复杂度和存储字符串的数据量无关只与查询的字符串长度有关,在一定程度上能加速算法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于字典树的中文未登录词识别方法,包括以下步骤:
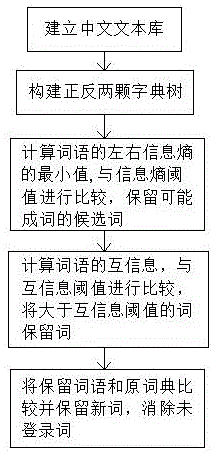
步骤一:将文本输入,将一些标点符号等问题进行去除,建立中文文本库;
步骤二:将文本库构造成字典树,在这个任务中需要构造两颗trie树,表示正向和反向两个字符字段集,为了方便接下来要进行的左右信息熵等值的计算;
步骤三:将字典树上的词提取出来,计算它的左右信息熵,公式为:h(x)=-∑p(xj)log(p(xj));计算完该词的左右熵之后取两个值中的最小值,然后将该词与信息熵阈值做比较,如果最小值小于阈值则该词被排除,反之将该词保留;
步骤四:单单使用左右熵来寻找新词不够准确,接下来计算上一步骤中保留的词语的互信息,以此来计算该词的凝固度,互信息的计算公式为:
步骤五:将之前保留的词语和词典进行比较,将原词典中没有的词加入作为词典的一部分,消除未登录词。
进一步的,所述步骤二中将文本输入后,计算机识别一些符号例如:“,”“。”等将语料分成很多句子,然后以句子的形式将一个一个词形成树的形式从上至下依次排下来,再计算每个词的频数等对之后需要计算的信息。。
进一步的,所述步骤三中h(x)是邻接字符的信息熵,p(xj)是邻接字符取xj的概率。
进一步的,所述步骤四中pmi(x,y)表示为互信息,p(x,y)表示x,y两个词(字)一起出现的概率,p(x)、p(y)表示x、y出现的概率。
与现有技术相比,本发明具有以下有益效果:
(1)本发明使用了字典树的方法,字典树的时间复杂度和存储字符串的数据量无关只与查询的字符串长度有关,在一定程度上能加速算法;
(2)本发明省去了分词这一步骤,中文分词一直是中文文本处理的一个大问题,精准度并不是那么的高,省去分词步骤可以避免在分词阶段出现的一些错误等问题;
(3)本发明为无监督学习方法,省去了分词过程,在过程中减少了对词典的依赖,在词典不够完备或者缺乏词典的情况下,一般的方法都很难使用,本方法在这种情况下得到充分利用,当然,在一般的情况下本方法也是能发挥它的特点。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的一种基于字典树的中文未登录词识别方法的步骤流程图。
具体实施方式
下面,结合附图以及具体实施方式,对发明做出进一步的描述:
请参阅图1,根据本发明实施例的一种基于字典树的中文未登录词识别方法,包括以下步骤:
步骤一:将文本输入,将一些标点符号等问题进行去除,建立中文文本库;
步骤二:将文本库构造成字典树,在这个任务中需要构造两颗trie树,表示正向和反向两个字符字段集,为了方便接下来要进行的左右信息熵等值的计算;
步骤三:将字典树上的词提取出来,计算它的左右信息熵,公式为:h(x)=-∑p(xj)log(p(xj));计算完该词的左右熵之后取两个值中的最小值,然后将该词与信息熵阈值做比较,如果最小值小于阈值则该词被排除,反之将该词保留;
步骤四:单单使用左右熵来寻找新词不够准确,接下来计算上一步骤中保留的词语的互信息,以此来计算该词的凝固度,互信息的计算公式为:
步骤五:将之前保留的词语和词典进行比较,将原词典中没有的词加入作为词典的一部分,消除未登录词。
通过本发明的上述方案,步骤二中将文本输入后,计算机识别一些符号例如:“,”“。”等将语料分成很多句子,然后以句子的形式将一个一个词形成树的形式从上至下依次排下来,再计算每个词的频数等对之后需要计算的信息,在这个方法中我们建立了正反两颗树,将更有利于计算左右信息熵将句子从正反两个方向来排列;步骤三中h(x)是邻接字符的信息熵,p(xj)是邻接字符取xj的概率。步骤四中pmi(x,y)表示为互信息,p(x,y)表示x,y两个字一起出现的概率,p(x)、p(y)表示x、y出现的概率。
综上所述,(1)本发明使用了字典树的方法,字典树的时间复杂度和存储字符串的数据量无关只与查询的字符串长度有关,在一定程度上能加速算法;(2)本发明省去了分词这一步骤,中文分词一直是中文文本处理的一个大问题,精准度并不是那么的高,省去分词步骤可以避免在分词阶段出现的一些错误等问题;(3)本发明为无监督学习方法,省去了分词过程,在过程中减少了对词典的依赖,在词典不够完备或者缺乏词典的情况下,一般的方法都很难使用,本方法在这种情况下得到充分利用,当然,在一般的情况下本方法也是能发挥它的特点。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限定本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!