半导体装置的制作方法
相关申请的交叉引用
本专利申请要求于2018年12月3日在韩国知识产权局提交的韩国专利申请no.10-2018-0153279的优先权,通过引用将该申请的全部公开内容并入本文。
本公开涉及半导体装置,更具体地,涉及具有提高的处理速度和准确性的半导体装置。
背景技术:
与基于规则的智能系统不同,人工智能(ai)系统是能够执行通常需要人类智力的任务的计算机系统。ai系统可以更精确地理解用户偏好。机器学习是一种使分析模型构建自动化的数据分析方法。机器学习是ai的一个基于系统能够从数据中学习、识别图案并且以最少的人为干预做出决策的观点的分支。因此,基于规则的智能系统逐渐被基于机器学习的ai系统所取代。
诸如语言理解、视觉理解、推断/预测、知识表达和运动控制的技术领域可以利用基于机器学习的ai系统。
机器学习算法需要能够处理大量数据的操作。当在同一操作中能够处理的数据越多时,由机器学习算法计算出的结果的精度越高。
利用深度学习的人工神经网络使用大量数据进行训练,并通过多个运营商执行并行操作以提高运算速度。
技术实现要素:
本发明构思的至少一个示例性实施例提供了包括存储器和处理器的半导体装置,其通过在存储器之间执行数据发送和接收而具有提高的处理速度和精度。
根据本发明构思的一个示例性实施例,提供了半导体装置,包括第一存储部件,所述第一存储部件包括第一存储区域和电连接到所述第一存储区域的第一逻辑区域。所述第一逻辑区域包括用于执行数据发送和接收操作的高速缓冲存储器和接口端口。所述第一存储部件使用所述高速缓冲存储器经由所述接口端口与和所述第一存储部件相邻的存储部件执行所述数据发送和接收操作。
根据本发明构思的一个示例性实施例,提供了半导体装置,包括:多个第一存储部件,所述多个第一存储部件均包括高速缓冲存储器和接口端口;和第一处理单元,所述第一处理单元电连接到所述多个第一存储部件,并且基于存储在所述多个第一存储部件中的数据执行操作。所述多个第一存储部件使用所述高速缓冲存储器和所述接口端口在所述多个第一存储部件之间执行数据发送和接收操作。
根据本发明构思的一个示例性实施例,提供了半导体装置,包括:第一处理单元、第二处理单元、多个第一存储部件、多个第二存储部件和调度器。所述多个第一存储部件电连接到所述第一处理单元,并且所述多个第一存储部件均包括第一存储区域和第一高速缓存区域。所述第一存储区域和所述第一高速缓存区域共享逻辑地址。所述多个第二存储部件电连接到所述第二处理单元,并且所述多个第二存储部件均包括第二存储区域和第二高速缓存区域。所述第二存储区域和所述第二高速缓存区域共享所述逻辑地址。所述调度器调度存储在所述第一存储区域或所述第二存储区域中的目标数据在所述第一存储部件和所述第二存储部件之间的发送和接收路径。所述调度器基于存储在所述第一高速缓存区域或所述第二高速缓存区域中的路径信息来调度所述发送和接收路径。
根据本发明构思的一个示例性实施例,提供了半导体装置,包括第一处理器和编译器。所述第一处理器电连接到包括至少一个存储器的第一存储部件,并且对训练数据集执行操作。所述编译器生成要在训练数据的操作过程中移动的数据的路径的调度代码。所述调度代码包括关于数据在所述第一处理器与所述第一存储部件之间移动的第一路径和数据在所述第一存储部件中所包括的存储器之间移动的第二路径的信息。所述第一处理器基于所述调度代码执行对所述训练数据集的操作。
附图说明
通过参照附图详细描述本发明构思的示例性实施例,本发明构思将变得更加明显,在附图中:
图1是用于说明根据本发明构思的一个示例性实施例的存储部件的配置的示意性框图;
图2是用于说明根据本发明构思的一个示例性实施例的经由接口端口连接的两个存储部件的配置的框图;
图3是用于说明根据本发明构思的一个示例性实施例的设置在逻辑区域中的高速缓冲存储器和接口端口的存储部件的截面图;
图4是用于说明根据本发明构思的一个示例性实施例的经由接口端口连接的三个存储部件的配置的框图;
图5是用于说明根据本发明构思的一个示例性实施例的处理单元和连接到该处理单元的两个存储部件的配置的框图;
图6是处理单元和存储部件的截面图,用于说明根据本发明构思的一个示例性实施例的处理单元与两个存储部件之间的连接;
图7和图8是用于说明根据本发明构思的一个示例性实施例的经由连接到存储部件的接口实现的存储部件与服务器之间的通信的框图;
图9是用于说明根据本发明构思的一个示例性实施例的包括多个处理单元的半导体装置的框图;
图10是用于说明根据本发明构思的一个示例性实施例的两个处理单元之间的通信的框图;
图11a是用于说明根据本发明构思的一个示例性实施例训练的数据集的示图;
图11b是用于说明处理单元处理图11a的数据集中所包括的数据的过程的流程图;
图11c是用于详细说明多个处理单元共享和处理所计算出的数据的过程的示图;
图12是用于说明存储在逻辑区域中的数据的配置的框图;
图13是用于说明存储区域和逻辑区域中每一者的物理地址与逻辑地址之间的映射的映射表;
图14a是用于说明作为示例的存储在高速缓存控制区域中的存储部件id信息的示图;
图14b是用于说明作为示例的存储在高速缓存控制区域中的状态信息的示图;
图14c是用于说明作为示例的存储在高速缓存控制区域中的指令的示图;
图15至图18是用于说明根据本发明构思的一个示例性实施例的包括调度器的半导体装置的框图;
图19至图21是用于说明根据本发明构思的一个示例性实施例的基于调度器的调度将存储在源存储部件中的目标数据传送到目的地存储部件的过程的示图。
具体实施方式
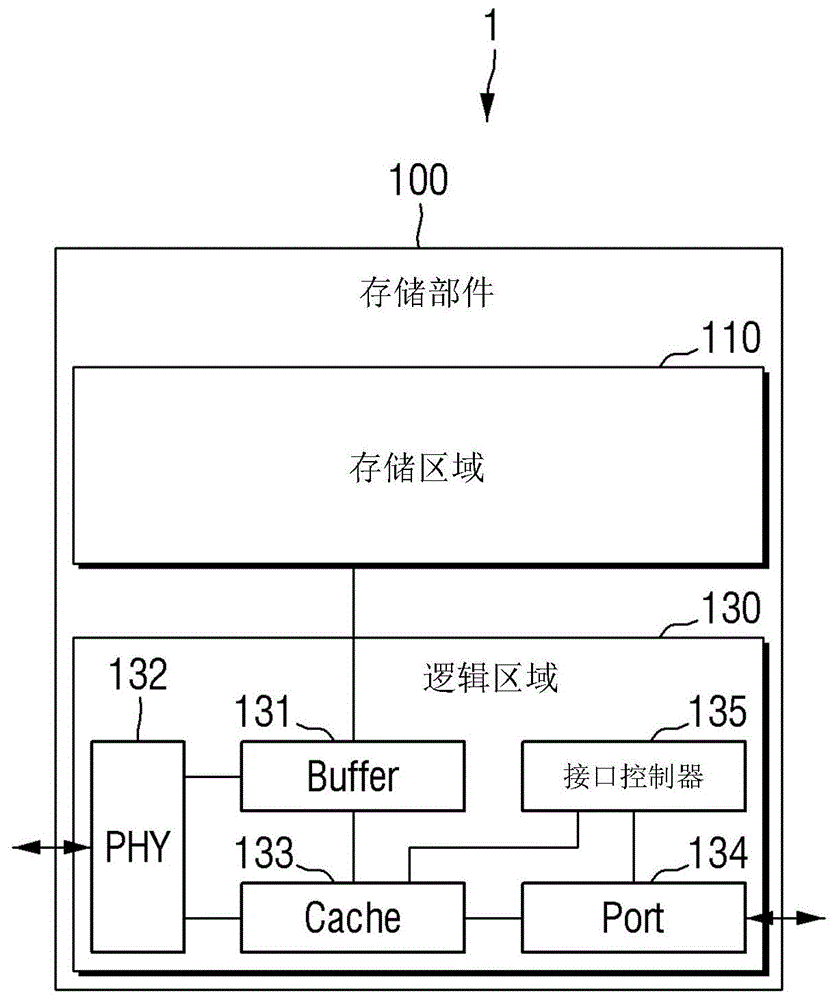
图1是用于说明根据本发明构思的一个示例性实施例的存储部件(例如,存储器件)的配置的示意性框图。
参照图1,根据本发明构思的一个实施例的半导体装置1包括存储部件100,存储部件100包括存储区域110和逻辑区域130。在一个示例性实施例中,存储区域110由非易失性存储器实现。
用户请求的用户数据、处理单元处理的数据或要处理的数据可以存储在存储区域110中。
逻辑区域130可以包括存储缓冲器(buffer)131、端口物理层(phy)132、高速缓冲存储器(cache)133、接口端口(port)134和接口控制器135(例如,控制电路)。在一个实施例中,phy132是实现物理层功能所需的电路。phy132可以将链路层设备连接到诸如光纤或铜线的物理介质。接口端口134可以用作半导体装置1与半导体装置1外部的设备之间的接口。
存储缓冲器131可以读取并缓冲存储在存储区域110中的数据,并将数据发送到高速缓冲存储器133或phy132。此外,存储缓冲器131可以经由phy132从处理单元(图5中的10)接收命令、地址、数据等。
phy132可以将存储在存储缓冲器131或高速缓冲存储器133中的数据输出到处理单元(图5中的10)。也就是说,处理单元和存储部件100可以经由phy132彼此连接。下面将参照图5描述存储部件100与连接到存储部件100的处理单元之间的数据发送和接收。
高速缓冲存储器133可以在接口控制器135的控制下临时存储存储在存储区域110中的数据或者要存储在存储区域110中的数据。根据一个实施例,存储在存储区域110中的用于数据转移到相邻存储部件100的数据被存储在存储缓冲器131中,高速缓冲存储器133接收并存储来自存储缓冲器131的数据。根据一个实施例,高速缓冲存储器133临时存储从相邻存储部件100接收的数据。
接口端口134可以向与存储部件100相邻的相邻存储部件发送数据和从其接收数据。根据一个实施例,接口端口134在接口控制器135的控制下将存储在高速缓冲存储器133中的数据发送到相邻存储部件。根据一个实施例,接口端口134在接口控制器135的控制下将从相邻存储部件接收的数据发送到高速缓冲存储器133。
根据一个实施例,接口端口134使用串行接口与相邻存储部件执行数据发送和接收操作。例如,接口端口134可以应用其自己的标准串行接口,或者可以采用诸如以下串行接口规则中的至少一种:pcie(高速外围组件互连)、nvme(高速非易失性存储器)、ufs(通用闪存)、usb(通用串行总线)、scsi(小型计算机系统接口)、sata(串行高级技术附件)、sas(串行连接scsi)、sd(安全数字)卡和emmc(嵌入式多媒体)卡,这些都是标准的串行接口规则。
接口控制器135可以控制与相邻存储部件的数据发送和接收操作。例如,接口控制器135可以控制存储区域110、存储缓冲器131、高速缓冲存储器133和接口端口134,以从相邻存储部件接收数据并将数据存储在存储部件100的高速缓冲存储器133或存储区域110中。在一个示例性实施例中,接口控制器135执行控制,使得在将经由接口端口134从相邻存储部件接收的数据存储在高速缓冲存储器133中之后,经由存储缓冲器131将数据存储在存储区域110的特定区域中。
根据一个示例性实施例,接口控制器135控制接口端口134和高速缓冲存储器133在从相邻存储部件接收数据之后将接收到的数据发送到另一个相邻存储部件。具体地,在将经由接口端口134接收到的数据存储在高速缓冲存储器133中之后,接口控制器135可以控制高速缓冲存储器133和接口端口134将存储在高速缓冲存储器133中的数据发送到另一个相邻存储部件。例如,第一存储部件的接口控制器可以从第二存储部件接收数据,将接收到的数据临时存储在第一存储部件的高速缓冲存储器中,然后将存储在第一存储部件的高速缓冲存储器中的数据发送到第三存储部件,可以绕过将数据存储到第一存储部件的存储区域中。在一个示例性实施例中,逻辑区域130还包括用于与另一个相邻存储部件通信的接口端口。例如,接口端口134可以包括用于与第二存储部件通信的第一接口端口和用于与第三存储部件通信的第二接口端口,或者接口端口134可以是能够与多个外部存储部件通信的单个端口。根据该实施例,接口端口134可以用于执行与彼此不同的相邻存储部件的通信。也就是说,可以使用一个接口端口134与彼此不同的相邻存储部件执行数据发送和接收。
根据一个示例性实施例,可以控制存储区域110、存储缓冲器131、高速缓冲存储器133和接口端口134将存储在存储区域110中的数据发送到相邻存储部件。具体地,将存储在存储区域110中的特定地址处的数据读取并存储在存储缓冲器131中,将数据高速缓存在高速缓冲存储器133中,然后将存储在高速缓冲存储器133中的数据经由接口端口134发送到相邻存储部件。
为了便于说明,接口控制器135被例示为位于存储部件100的逻辑区域130中,但不限于此,接口控制器135可以被设置在存储部件100的外部区域中。
图2是用于说明根据本发明构思的一个示例性实施例的经由接口端口连接的两个存储部件的配置的框图。
参照图2,根据本发明构思的实施例的半导体装置1包括第一存储部件100和第二存储部件200,第一存储部件100包括第一存储区域110和第一逻辑区域130,第二存储部件200包括第二存储区域210和第二逻辑区域230。第一存储部件100以与图1的存储部件100相同的方式配置。此外,第二存储部件200的第二存储区域210和第二逻辑区域230的配置可以执行与第一存储部件100的第一存储区域110和第一逻辑区域130的配置相同的操作。第二逻辑区域230包括第二存储缓冲器(buffer)231、第二phy232、第二高速缓冲存储器(cache)233、第二接口端口(port)234和第二接口控制器235。
根据本发明构思的实施例的半导体装置1可以在相邻存储部件之间执行数据发送和接收操作。第一存储部件100和第二存储部件200彼此相邻地设置,并且经由第一接口端口134和第二接口端口234执行数据发送和接收。第一接口控制器135控制在第一接口端口134接收数据的输入操作或者从第一接口端口134发送数据的输出操作,第二接口控制器235控制在第二接口端口234接收数据的输入操作或者从第二接口端口234发送数据的输出操作。
图3是存储部件的截面图,用于说明根据本发明构思的一个示例性实施例的设置在逻辑区域中的高速缓冲存储器和接口端口。为了便于说明,示出了堆叠型存储部件作为可以应用本发明构思的实施例的示例,但是本发明构思不限于此,并且本发明构思的实施例可以应用于具有与图3所例示的布置不同的布置的单层型存储器或堆叠式存储器。
参照图3,根据本发明构思的一个示例性实施例的半导体装置1包括衬底5、堆叠在衬底5上的内插件(interposer)3以及均设置在内插件3上的第一存储部件100和第二存储部件200。
第一存储部件100可以包括第一逻辑区域130和第一存储区域110,第一存储区域110包括沿垂直方向堆叠在第一逻辑区域130上的多个存储芯片111、113、115和117。第一存储区域110可以包括至少一个第一存储芯片111、113、115和117,每个第一存储芯片包括存储有数据的多个存储单元。存储芯片111、113、115和117中的每一个存储芯片和第一逻辑区域130可以经由tsv(硅通路)彼此连接。为了便于说明,第一存储区域110被例示为包括四个芯片111、113、115和117,但是不限于此,并且可以包括少于四个存储芯片或多于四个存储芯片。另外,图3例示了存储部件的可能配置的示例性截面图,但是也可以应用其他形式的存储器。
第二存储部件200可以具有与第一存储部件100相同的配置。也就是说,第二存储部件200可以包括第二逻辑区域230和第二存储区域210,第二存储区域210包括沿垂直方向堆叠在第二逻辑区域230上的多个存储芯片211、213、215和217,并且存储芯片211、213、215和217中的每一个存储芯片和第一逻辑区域130经由tsv彼此连接,并且可以发送和接收数据。第二存储区域210可以包括至少一个第二存储芯片211、213、215和217,第二存储芯片包括存储有数据的多个存储单元。
根据本发明构思的至少一个实施例的半导体装置1可以通过将高速缓冲存储器133和接口端口134设置在逻辑区域130中以及将高速缓冲存储器233和接口端口234设置在逻辑区域230中,来执行相邻存储部件之间的数据发送和接收操作。通过将高速缓冲存储器133和233以及接口端口134和234设置在不包括存储用户数据或将被处理单元处理的数据的存储单元的逻辑区域130和230中,能够在不显著增加半导体装置1的面积的情况下,实现相邻存储部件之间的直接数据发送和接收。另外,如上所述,可以使用串行接口执行相邻存储部件之间的数据发送和接收。
图4是用于说明根据本发明构思的一个示例性实施例的经由接口端口连接的三个存储部件的配置的框图。例如,半导体装置1可以另外包括第三存储部件300,第三存储部件300包括第三存储区域310和第三逻辑区域330。例如,第三逻辑区域330可以包括第三存储缓冲器331、第三phy332、第三高速缓冲存储器333和第三接口端口334。假设图4的第一存储部件100具有与图1的存储部件100相同的配置。而且,为了便于说明,例示了第一逻辑区域130、第二逻辑区域230和第三逻辑区域330不包括接口控制器,但是第一逻辑区域130、第二逻辑区域230和第三逻辑区域330均可以包括控制与相邻存储部件的数据发送和接收的接口控制器。另外,假设第一存储部件100和第二存储部件200彼此相邻地设置,第二存储部件200和第三存储部件300彼此相邻地设置,第一存储部件100和第三存储部件300彼此不相邻地设置。
参照图4,根据本发明构思的实施例的半导体装置1包括拥有多个接口端口234_0和234_1的存储部件200。如图所例示,第二存储部件200的第二逻辑区域230包括两个第二接口端口234_0和234_1。也就是说,第二逻辑区域230可以包括分别用于执行与作为相邻存储部件的第一存储部件100和第三存储部件300的数据发送和接收的第二接口端口234_0和234_1。可以使用第一存储部件100的第一接口端口134和第二存储部件200的第二接口端口234_0来执行第一存储部件100与第二存储部件200之间的数据发送和接收,可以使用第三存储部件300的第三接口端口334和第二存储部件200的第二接口端口234_1来执行第二存储部件200与第三存储部件300之间的数据发送和接收。作为另一个示例,可以共享用于与不同的相邻存储部件的数据发送和接收的接口端口。也就是说,第二存储部件200可以使用第二接口端口234_0来执行与第一存储部件100和第三存储部件300的数据发送和接收,或者可以使用第二接口端口234_1来执行与第一存储部件100和第三存储部件300的数据发送和接收。
根据本发明构思的至少一个实施例,从相邻存储部件接收的数据不被存储在存储区域中,而是被发送到另一个相邻存储部件。换句话说,当存储部件不是数据最终到达的目的地存储部件时,从相邻存储部件接收数据并将其存储在高速缓冲存储器中,然后再将存储在高速缓冲存储器中的数据发送到另一个相邻存储部件。在下文中,将描述将存储在第一存储区域110中的数据存储在第三存储区域310中的过程。
当作为存储部件之间的数据发送和接收的目标的目标数据被存储在作为源存储部件的第一存储部件100中所包括的第一存储区域110的特定地址中并且该目标数据将要被存储在第三存储区域310中时,第二存储部件200可以经由第二接口端口234_0从第一接口端口134接收目标数据。由于第二存储部件200不是数据最终到达的目的地存储部件,因此第二存储部件200不将目标数据存储在第二存储区域210中,而是通过第二接口端口234_1将目标数据发送到第三存储部件300。在一个实施例中,使用第二接口端口234_1与第三接口端口334之间的串行接口发送目标数据。经由第三接口端口334发送到第三存储部件300的目标数据被存储在第三高速缓冲存储器333中,然后,可以依次被存储在第三存储缓冲器331以及第三存储区域310的特定地址中。
根据一个实施例,半导体装置1还可以包括调度器(图15中的30),其调度连接到第二存储部件200的多个存储部件之间的发送和接收路径。下面将参照图15至图19来描述基于调度器的调度而移动数据的过程。
图5是用于说明根据本发明构思的一个示例性实施例的处理单元和连接到该处理单元的两个存储部件的配置的框图。将不提供使用图1和图4描述了的存储部件的配置和操作的重复描述。
参照图5,根据本发明构思的实施例的半导体装置1包括电连接到多个存储部件100和200的处理单元10。处理单元10可以是基于存储在多个存储部件100和200中的数据执行操作的图形处理单元(gpu),但是本发明构思不限于此,因为可以应用不同类型的处理器。
根据实施例,处理单元10包括处理器内核11、接口控制器13和缓冲器15。
处理器内核11基于存储在电连接到处理单元10的存储部件100和200中的数据来执行操作。例如,处理器内核11可以基于存储在第一存储部件100的第一存储区域110中的数据和存储在第二存储部件200的第二存储区域210中的数据来执行处理操作。
接口控制器13可以控制电连接到处理单元10的存储部件100和200之间的数据发送和接收操作。也就是说,如图1和图2所示,接口控制器13可以被布置在存储部件100所包括的逻辑区域130中和存储部件200所包括的逻辑区域230中,或者可以被包括在处理单元10中,存储部件100和200通过处理单元10彼此电连接。
缓冲器15可以存储从电连接到处理单元10的存储部件100和200接收到的数据或者要发送到存储部件100和200的数据。缓冲器15可以经由phy132和phy17_0从第一存储部件100接收数据,可以经由第二phy232和phy17_1从第二存储部件200接收数据。
电连接到处理单元10的多个存储部件100和200可以执行与彼此的数据发送和接收操作。也就是说,连接到处理单元10的第一存储部件100和第二存储部件200可以分别包括第一接口端口134和第二接口端口234,并且可以使用相应的接口端口134和234与彼此直接发送和接收数据。
根据一些实施例,处理单元10可以包括例如gpu模块、tpu(张量处理单元)模块、dpu(数据处理单元)模块、mpu(主处理单元)模块等。在包括gpu模块和tpu模块的情况下,处理单元可以分别包括gpu或tpu,并且可以包括多个支持芯片。tpu可以例如在专用集成电路(asic)上实现,并且可以被配置或被优化以用于机器学习。根据至少一个示例性实施例,dpu可以类似于诸如tpu或gpu的其他加速器那样操作。
图6是处理单元和存储部件的截面图,用于说明根据本发明构思的示例性实施例的处理单元与两个存储部件之间的连接。为了便于说明,将不再说明使用图3说明了的内容。
参照图6,根据本发明构思的示例性实施例的半导体装置1包括处理单元10以及连接到处理单元10的多个存储部件100和200。在示例性实施例中,处理单元10设置有phy17_0和17_1,第一存储部件100设置有phy132,第二存储部件200设置有phy232,phy17_0、phy17_1、phy132和phy232经由内插件3彼此电连接。例如,phy132可以经由内插件3电连接到phy17_0,phy232可以经由内插件3电连接到phy17_1。
如图所示,phy132布置在第一存储部件100的第一逻辑区域130中,处理单元10包括多个phy17_0和17_1,phy232布置在第二逻辑单元230的第二逻辑区域230中。处理单元10可以经由phy17_0和phy132连接到第一存储部件100,可以经由phy17_1和phy232连接到第二存储部件200,以发送和接收数据、命令等。
图7和图8是用于说明根据本发明构思的一个示例性实施例的经由连接到存储部件的接口来实现存储部件与服务器之间的通信的框图。
参照图7,根据本发明构思的一个示例性实施例的半导体装置1包括处理单元10、系统存储器50、cpu60、第一接口70和数据总线90。此外,半导体装置1可以包括连接到处理单元10的第一存储部件100、第二存储部件200、第三存储部件300和第四存储部件400,还可以包括电连接到第一存储部件100、第二存储部件200、第三存储部件300和第四存储部件400的第二接口80。
当向服务器2(例如,数据存储服务器)发送存储在电连接到处理单元10的存储部件中的用户数据、由处理单元10处理的数据等或者从服务器2接收数据时,处理单元10经由cpu60的控制从存储有数据的存储部件接收数据,将接收到的数据经由数据总线90存储在系统存储器50中,并且需要基于所接收的数据经由第一接口70与服务器2通信。此外,当需要在连接到处理单元10的多个存储部件(mu)100、200、300和400之间移动数据时,可以经由处理单元10传输数据。然而,使用处理单元10执行传输效率不高。
当使用多个处理单元(例如,gpu)执行并行操作时,可以提高通过处理单元之间的数据交换而训练的人工神经网络的精度。然而,处理单元之间的数据加载和处理单元之间的数据交换的频繁发生可能降低处理单元的利用率。因此,通过经由直接通信在存储部件之间共享数据而不经由与存储部件连接的处理单元发送和接收数据,可以提高处理单元的利用率。
当需要在连接到处理单元10的多个存储部件100、200、300和400之间交换数据时,根据本发明构思的一个示例性实施例,能够通过在存储部件100、200、300和400之间直接交换数据而不受诸如处理器和数据总线90的中间路径的干预,来实现多个存储部件100、200、300和400之间的直接通信,从而提高了系统的效率。
此外,由于能够经由连接到各个存储部件100、200、300和400的第二接口80实现与服务器2的通信,并且能够在不受cpu60等干预的情况下实现与服务器2的数据发送和接收,所以可以提高系统的效率。
根据一个示例性实施例,在处理单元10中所包括的接口控制器13的控制下,执行电连接到处理单元10的多个存储部件100、200、300和400之间的数据发送和接收、多个存储部件100、200、300和400与第二接口80之间的数据发送和接收以及第二接口80与服务器2之间的通信。
例如,当存储在第一存储部件100中的第一目标数据dt_t0被发送到服务器2时,在接口控制器13的控制下,存储在第一存储部件100中的第一目标数据dt_t0经由第二接口80被发送到服务器2。
参照图8,接口可以连接到与处理单元10电连接的多个存储部件100、200、300和400中的一个存储部件。如图所示,第一存储部件100和第二接口80可以彼此连接。
在将存储在第二存储部件200中的第一目标数据dt_t0发送到服务器2的情况下,第二存储部件200通过串行接口将第一目标数据dt_t0发送到第一存储部件100,第一存储部件100经由连接到第一存储部件100的第二接口80将第一目标数据dt_t0发送到服务器2。当第二接口80不连接到多个存储部件100、200、300和400中的所有存储部件时,布置在每个存储部件100、200、300和400中的端口的数目减少,从而可以简化电路。
图9是用于说明根据本发明构思的一个示例性实施例的包括多个处理单元的半导体装置的框图。
参照图9,根据本发明构思的实施例的半导体装置1包括多个处理单元10和20。作为示例,假设半导体装置1包括第一处理单元10和第二处理单元20。此外,第一处理单元10电连接到第一存储部件100、第二存储部件200、第三存储部件300和第四存储部件400,第二处理单元20电连接到第五存储部件500、第六存储部件600、第七存储部件700和第八存储部件800。
根据实施例,能够实现连接到第一处理单元10的第二存储部件200与连接到第二处理单元20的第五存储部件500之间的数据发送和接收,并且能够实现连接到第一处理单元10的第四存储部件400与连接到第二处理单元20的第七存储部件700之间的直接通信。也就是说,能够实现连接到彼此不同的处理单元的存储部件之间的数据发送和接收。
当执行深度学习或机器学习时,需要大容量存储部件和多个处理单元(例如,gpu)。当频繁请求多个处理单元之间的数据发送和接收而无法实现处理单元之间的数据发送和接收时,经由数据总线的通信可能发生暂时性损坏(temporaldamage)。即使当能够实现处理单元之间的数据发送和接收时,处理单元也从电连接到处理单元的存储部件读取数据,并且在将数据发送到另一个处理单元的过程中,存储部件的i/o操作停止。
根据本发明构思的一个实施例,可以通过相邻存储部件之间的数据发送和接收来减少所使用的处理单元的资源,以降低功耗。此外,即使在存储部件之间的数据发送和接收过程中,也可以提高处理单元的利用率。
图10是用于说明根据本发明构思的一个实施例的两个处理单元之间的通信的框图。
参照图10,根据本发明构思的实施例的半导体装置1在多个处理单元之间发送和接收数据。如图所示,第一处理单元10和第二处理单元20可以直接发送和接收数据。在能够实现彼此不同的处理单元之间的直接通信的情况下,与使用诸如数据总线的中间路径的情况相比,通过用更少的路径发送和接收数据,可以缩短操作所需的时间并且最小化系统中消耗的资源。例如,在第一处理单元10与第二处理单元20之间可以存在专用和直接信道,使得它们能够彼此交换数据。
图11a是用于说明根据本发明构思的一个示例性实施例训练的数据集的示图,图11b是用于说明由处理单元处理图11a的数据集中所包括的数据的过程的流程图。图11c是用于详细说明在图11b的处理期间在多个处理单元之间处理和共享所计算出的数据的过程的示图。
在诸如深度学习的操作中,使用大量数据执行训练,并且用于单个操作的数据大小越大,训练速度越快。
参照图11a,可以将多个子集包括在作为使用人工神经网络的训练对象的数据集中。每个子集可以包括关于多个层l1至lm的数据。数据集中可以包括三个以上的子集,但是为了便于说明,下面假设数据集包括两个子集(sub-set1,sub-set2)。如本文所使用的,数据集可以表示为训练数据集,并且子集可以表示为子数据集。而且,“第n层”的传输/处理可以表示“第n层上的数据的传输/处理”。
参照图11b,根据本发明构思的一个实施例的第一处理单元10和第二处理单元20可以从包括在数据集中的数据中学习,并且能够通过相互的数据交换来提高推断精度。在图11b的说明中,例示了第一处理单元10和第二处理单元20通过数据共享来处理数据,但是本发明构思不限于此,可以通过数据共享实现三个以上的处理单元。
在步骤s1100中,第一处理单元10加载包括在第一子集(sub-set1)中的至少一些数据。在下文中,假设加载第一层l1至第m层lm上的数据以成为训练目标。
在步骤s2100中,第二处理单元20加载包括在第二子集(sub-set2)中的至少一些数据。同样,可以加载第一层l1至第m层lm上的数据以成为训练目标。
在步骤s1200中,第一处理单元10按照第一层l1至第m层lm的顺序执行操作。在步骤s2200中,第二处理单元20按照第一层l1至第m层lm的顺序执行操作。
在步骤s1300中,第一处理单元10基于所执行的操作,按照第m层lm至第一层l1的顺序计算第一层l1至第m层lm的中间结果。在步骤s2300中,第二处理单元20基于所执行的操作,按照第m层lm至第一层l1的顺序计算第一层l1至第m层lm的中间结果。在一个示例性实施例中,由第一处理单元10计算出的中间结果和由第二处理单元20计算出的中间结果包括关于由它们各自计算出的数据的梯度的信息。
在步骤s1400和s2400中,由第一处理单元10计算出的中间结果被发送到第二处理单元20,并且由第二处理单元20计算出的中间结果被发送到第一处理单元10。也就是说,可以共享由第一处理单元10和第二处理单元20中的每一个计算出的中间结果。
在步骤s1500中,第一处理单元10基于由第一处理单元10计算出的中间结果和从第二处理单元20接收到的中间结果,对第一层l1至第m层lm执行数据的更新操作。
在步骤s2500中,第二处理单元20基于由第二处理单元20计算出的中间结果和从第一处理单元10接收到的中间结果,对第一层l1至第m层lm执行数据的更新操作。
在步骤s1600中,第一处理单元10确定是否加载了第一子集(sub-set1)中的所有数据。如果确定第一子集(sub-set1)中的所有数据都被加载并且已经对这些数据进行了操作,则处理操作的操作结束;如果确定在第一子集(sub-set1)中的数据中存在未加载的数据,则可以加载未加载的数据并且可以重复执行根据步骤s1100至s1500的操作处理。
在步骤s2600中,第二处理单元20确定是否加载了第二子集(sub-set2)中的所有数据。如果确定第二子集(sub-set2)中的所有数据都被加载并且已经对这些数据进行了操作,则处理操作的操作结束;如果确定在第二子集(sub-set2)中的数据中存在未加载的数据,则可以加载未加载的数据并且可以重复执行根据步骤s2100至s2500的操作处理。
参照图11b和图11c,步骤s1300可以包括步骤s1310至s1370,步骤s1400可以包括步骤s1410至s1450。此外,步骤s2300可以包括步骤s2310至s2370,步骤s2400可以包括步骤s2410至s2450。
如上所述,在步骤s1200和s2200中,第一处理单元10和第二处理单元20分别按照第一层l1至第m层lm的顺序对包括在第一子集和第二子集(sub-set1和sub-set2)中的数据执行操作。此时执行的操作可以是针对每个层的模型评估操作。在步骤s1300和s2300中,第一处理单元10和第二处理单元20分别对在步骤s1200和s2200中执行的操作的中间结果执行计算。在一个实施例中,中间结果可以包括评估出的数据的梯度信息,并且梯度计算操作可以以在步骤s1200和s2200中执行的评估操作的相反的顺序执行。也就是说,可以按照从第m层lm至第一层l1的顺序执行操作。
在步骤s1310和s2310中,第一处理单元10和第二处理单元20分别对第一子集和第二子集(sub-set1和sub-set2)的第m层lm执行梯度计算操作。在步骤s1410和s2410中,第一处理单元10和第二处理单元20共享计算出的第m层lm的梯度信息。
在步骤s1330和s2330中,第一处理单元10和第二处理单元20分别对第一子集和第二子集(sub-set1和sub-set2)的第m-1层(lm-1)执行梯度计算操作。在一个实施例中,针对第m-1层(lm-1)评估出的数据和关于第m层lm的梯度信息可以用在对第m-1层(lm-1)的梯度计算操作中。也就是说,除了s1200和s2200中评估出的信息之外,可以使用针对第m层lm计算出的梯度信息,并且可以使用在另一个处理单元中计算出的梯度信息。例如,在第m-1层(lm-1)的梯度计算中,除了针对第一子集(sub-set1)的第m-1层(lm-1)评估出的信息和针对第一子集(sub-set1)的第m层lm计算出的梯度信息之外,第一处理单元10还可以使用在第二处理单元20中针对第二子集(sub-set2)的第m层lm计算出的梯度信息。可以重复这些操作,直到执行了对所有层lm至l1的梯度计算操作。
根据一些实施例,对特定层的梯度计算操作和共享计算出的上一层的梯度的操作可以由相应处理单元10和20同时执行。例如,当由第一处理单元10和第二处理单元20执行对第m-1层(lm-1)的梯度计算操作时,可以在电连接到第一处理单元10和第二处理单元20的存储部件之间发送和接收计算出的第m层lm的梯度。也就是说,根据本发明构思的一个实施例,当处理单元经由存储部件之间的接口执行操作时,通过在存储部件之间共享当前操作或下一操作所需的数据,可以提高处理单元执行操作的效率。
根据本发明构思的至少一个示例性实施例,可以共享由多个处理单元中的每一个处理单元计算出的中间结果,并且可以通过基于共享信息的更新操作来提高所训练的人工神经网络的推理精度。
当根据本发明构思的至少一个示例性实施例执行相邻存储部件之间的数据发送和接收时,在操作过程中频繁发生的所需的中间结果(例如,计算出的数据)的交换过程中,由于数据的发送和接收在多个存储部件之间直接执行而不经过多个处理单元,所以可以提高处理单元的利用率。另外,当处理单元之间共享的数据大小小于存储部件与处理单元之间发送和接收的数据大小并且不需要高传输速度时,多个存储部件之间的数据发送和接收不需要高速。此外,由于训练顺序或训练形式(例如,执行操作的过程、执行操作的数据的顺序等)是相对恒定的,所以可以容易地预测存储部件之间的数据发送和接收的定时和顺序。
图12是用于说明存储在逻辑区域中的数据的配置的框图。
参照图12,根据本发明构思的一个实施例的存储部件100包括存储区域110和逻辑区域130。根据实施例,逻辑区域130包括高速缓冲存储区域138和高速缓存控制区域139。在一个实施例中,高速缓冲存储区域138是用于临时存储要发送到相邻存储部件的数据或从相邻存储部件接收的数据的区域。在一个实施例中,高速缓存控制区域139是用于存储存储部件100与相邻存储部件通信所需的信息和指令1300的区域。根据一个实施例,高速缓冲存储区域138和高速缓存控制区域139是包括在单个高速缓冲存储器(图1的130)中的区域。
根据一个实施例,存储部件id信息(inf_id(mu))1100、存储部件状态信息(inf_status(mu))1200、指令1300和控制id状态信息(inf_status(ctrlid))1400被存储在高速缓存控制区域139中。
参照图10和图12,根据本发明构思的一个实施例的半导体装置1包括编译器,该编译器生成在由处理单元10和20执行的数据的操作处理中移动的数据路径的调度代码。例如,调度代码可以包括关于第一路径和第二路径的信息,在第一路径中,数据在处理单元(例如,10)与连接到处理单元10的存储部件100、200、300和400之间移动;在第二路径中,数据在连接到同一处理单元(例如,20)的多个存储部件500、600、700和800之间移动。根据一些实施例,调度代码可以包括关于第三路径的信息,在第三路径中,数据在分别连接到彼此不同的处理单元10和20的存储部件(例如,400和700)之间移动。根据一些实施例,调度代码可以包括关于第四路径的信息,在第四路径中,数据在彼此不同的多个处理单元10和20之间移动。
处理单元10可以基于由编译器生成的调度代码来执行对数据的操作。例如,当用于操作的少量数据以队列为单位发送到存储部件时,可以调度输入队列以便以fifo(先入先出)的形式将数据发送到处理单元。根据一些实施例,输入队列可以存储在存储部件100的逻辑区域130中。根据一些实施例,输入队列可以存储在逻辑区域130的高速缓冲存储区域138中。根据一些实施例,调度代码可以包括这样的信息:该信息适用于将存储在逻辑区域130中的队列经由第二路径传送到处理单元10并且将操作所需的数据(例如,梯度数据)通过第一路径从存储区域110传送到处理单元10。另外,调度代码可以包括这样的信息:该信息适用于将处理单元10处理的数据存储在逻辑区域130中并且将处理后的数据通过第三路径发送到电连接到另一个处理单元20的存储部件(例如,500)。
图13是用于说明存储区域和逻辑区域中每一者的物理地址与逻辑地址之间的映射的映射表。
参照图12和图13,根据本发明构思的一个实施例的存储部件100包括存储区域110和逻辑区域130。在一个实施例中,存储区域110和逻辑区域130共享相同的逻辑地址。换句话说,存储区域110和逻辑区域130均具有唯一的物理地址,并且每个物理地址可以与具有彼此不同的索引的逻辑地址映射。如图所示,假设存储部件100的存储区域110具有物理地址mpa_0至物理地址mpa_999的存储区域物理地址值mpa,逻辑区域130具有物理地址lpa_0至物理地址lpa_499的逻辑区域物理地址lpa。具体地,假设包括在逻辑区域130中的高速缓冲存储区域138和高速缓存控制区域139分别具有物理地址lpa_0至物理地址lpa_399的逻辑区域物理地址lpa和物理地址lpa_400至物理地址lpa_499的逻辑区域物理地址lpa。
存储区域110的物理地址mpa_0至物理地址mpa_999可以分别映射到逻辑地址la_0至逻辑地址la_999。例如,具有物理地址mpa_1的存储区域110的位置具有逻辑地址la_1。此外,高速缓冲存储区域138的物理地址lpa_0至物理地址lpa_399可以分别映射到逻辑地址la_1000至逻辑地址la_1399。例如,具有物理地址lpa_399的高速缓冲存储区域138的位置具有逻辑地址la_1399。此外,可以将高速缓存控制区域139的物理地址lpa_400至物理地址lpa_499分别映射到逻辑地址la_1400至逻辑地址la_1499。例如,具有物理地址lpa_400的高速缓存控制区域139的位置具有逻辑地址la_1400。
由于存储区域110和逻辑区域130共享相同的逻辑地址,因此处理单元(图5的10)不需要单独的用于发送和接收彼此不同的地址的硬件。
根据一个实施例,映射表可以存储在存储部件100的存储区域110、高速缓冲存储区域138或高速缓存控制区域139中。根据另一个实施例,映射表可以存储在处理单元10的其他存储区域中。
此外,图14a是用于说明作为示例的存储在高速缓存控制区域139中的存储部件id信息(inf_id(mu))1100的示图。下面将参照图12和图14a描述存储在高速缓存控制区域139中的存储部件id信息(inf_id(mu))1100。如图所示,假设多个存储部件分别位于n+1行m+1列中。
存储部件id信息(inf_id(mu))1100可以包括关于多个存储部件的位置的信息。也就是说,它可以包括标识特定存储部件所在的行和列的信息。例如,位于第i行第j列的存储部件1110可以以(i,j)的形式表示。
根据一个实施例,存储部件id信息(inf_id(mu))1100包括关于与每个存储部件相邻的相邻存储部件的信息。例如,当存储部件1110的存储部件id信息1100中的位置是(i,j)(其意味着第i行第j列),位于第i-1行第j列的存储部件(i-1,j)、位于第i行第j+1列的存储部件(i,j+1)、位于第i行第j-1列的存储部件(i,j-1)和位于第i+1行第j列的存储部件(i+1,j)对应于相邻存储部件,作为存储部件1110的相邻存储部件的存储部件(i-1,j)、存储部件(i,j+1)、存储部件(i,j-1)和存储部件(i+1,j)的id信息可以存储在存储部件id信息(inf_id(mu))1100中。此时,相邻存储部件可以被定义为能够在它们之间直接发送和接收数据的存储部件。也就是说,存储部件1110可以直接与存储部件(i-1,j)、存储部件(i,j+1)、存储部件(i,j-1)和存储部件(i+1,j)执行数据发送和接收。例如,存储部件1110可以从存储部件(i-1,j)接收数据并将该数据转发到存储部件(i,j+1)。
根据另一个实施例,通过将与每个存储部件不相邻的存储部件的id信息存储在该存储部件的高速缓存控制区域中,还可以将数据传送到非相邻存储部件。参照图4,当第一存储部件100、第二存储部件200和第三存储部件300是分别位于(i,j-1)、(i,j)和(i,j+1)的存储部件时,第一存储部件100与第三存储部件300不相邻,但是由于与第一存储部件100相邻的第二存储部件200存储了包括第三存储部件300在内的其他存储部件的id信息,因此包括在第一存储部件100中的数据可以被传送到第三存储部件300而无需其他处理单元等的介入。在一个实施例中,存储在第一存储部件100中的数据按照第一存储部件100、第二存储部件200和第三存储部件300的顺序传送,并且可以被存储在第三存储部件300的第三存储区域310、第三存储缓冲器331或高速缓冲存储器333中。
图14b是例示了作为示例的存储在高速缓存控制区域139中的状态信息的示图。在下文中,将参照图12、图13、图14a和图14b描述存储在高速缓存控制区域139中的存储部件状态信息(inf_status(mu))1200。
如上所述,存储部件1110的相邻存储部件被定义为存储部件(i-1,j)、存储部件(i,j+1)、存储部件(i,j-1)和存储部件(i+1,j),并且它们的信息可以存储在存储部件id信息(inf_id(mu))1100中。在一个实施例中,存储在高速缓存控制区域139中的存储部件状态信息(inf_status(mu))1200指示相邻存储部件的状态是就绪状态还是忙碌状态。在一个实施例中,就绪状态意味着相邻存储部件处于能够进行数据发送和接收的状态,忙碌状态意味着相邻存储部件处于不能进行数据发送和接收的状态。
如图所示,存储部件1110的相邻存储部件中的存储部件(i-1,j)、存储部件(i,j+1)和存储部件(i+1,j)处于就绪状态,存储部件(i,j-1)处于忙碌状态。也就是说,存储部件(i-1,j)、存储部件(i,j+1)和存储部件(i+1,j)处于能够与存储部件1110进行数据发送和接收的状态,存储部件(i,j-1)处于不能与存储部件1110进行数据发送和接收的状态。
图14c是用于说明作为示例的存储在高速缓存控制区域139中的指令1300的示图。下面将参照图5、图12、图13和图14a至图14c描述包含在指令1300中的信息。
指令1300可以由处理单元存储在高速缓存控制区域139中,或者可以经由串行接口在存储部件之间传输和存储。
控制指令(ctrlinstruction)可以包括关于在与相邻存储部件的数据发送和接收操作时执行的操作的信息。例如,当从第二存储部件200接收并存储在第一高速缓冲存储器133中的数据被发送到第一存储区域110时,存储有要发送的数据的第一高速缓冲存储器133的起始地址、数据的大小(或长度)以及存储数据的第一存储区域110的起始地址可以被包括在第一存储部件的控制指令(ctrlinstruction)中。
作为另一个示例,当存储在第一存储区域110中的数据被发送到第二存储部件200时,存储有要发送的数据的第一存储区域110的起始地址、要发送的数据的大小(或长度)以及存储数据的第一高速缓冲存储器133的起始地址可以被包括在第一存储部件的控制指令(ctrlinstruction)中。
活动信息(active)可以定义用于根据控制指令(ctrlinstruction)执行操作的模式。例如,活动信息(active)可以包括关于第一模式或第二模式的信息,在第一模式下,当处理单元将指令1300存储在高速缓存控制区域139中时根据控制指令(ctrlinstruction)在存储部件之间发送和接收数据;在第二模式下,当接收到处理单元的启动命令时根据控制指令(ctrlinstruction)在处理单元之间发送和接收数据。
源存储部件id信息(id_mu(src))可以是源存储部件的存储部件id信息,在该源存储部件中存储了作为根据控制指令(ctrlinstruction)的操作的目标的目标数据。另外,目的地存储部件id信息(id_mu((dst))可以是目标数据最终到达的目的地存储部件的存储部件id信息。
起始地址信息(add_mu(start))可以表示源存储部件的地址信息,并且大小信息(length)可以表示目标数据的大小或存储有目标数据的源存储部件的地址长度。
根据一个实施例,指令1300还包括关于源存储部件和目的地存储部件的优先级顺序信息,并且调度器(图15的30)可以基于优先级顺序信息确定存储部件之间的发送和接收路径。
根据一个实施例,调度器基于存储在高速缓存控制区域139中的存储部件id信息(inf_id(mu))1100、存储部件状态信息(inf_status(mu))1200和指令1300来调度目标数据的路径。稍后将描述调度器的调度操作。
图15至图18是用于说明根据本发明构思的一个示例性实施例的包括调度器的半导体装置的框图。为了便于说明,将不提供参照图1至图10说明了的对配置和操作的描述。
参照图12至图15,根据本发明构思的实施例的半导体装置1还包括调度器30。调度器30可以基于路径信息调度存储部件之间的发送和接收路径。例如,路径信息可以包括存储部件id信息、存储部件状态信息和指令中的至少一种。
参照图16,调度器19和29分别被包括在第一处理单元10和第二处理单元20中。在这种情况下,第一调度器19调度连接到第一处理单元10的第一存储部件100、第二存储部件200、第三存储部件300和第四存储部件400中的目标数据的发送和接收路径。此外,第二调度器29调度连接到第二处理单元20的第五存储部件500、第六存储部件600、第七存储部件700和第八存储部件800中的目标数据的发送和接收路径。
参照图17,调度器190、290、390、490、590、690、790和890分别被包括在每个存储部件中。例如,第一存储部件100、第二存储部件200、第三存储部件300、第四存储部件400、第五存储部件500、第六存储部件600、第七存储部件700和第八存储部件800可以分别包括调度器190、调度器290、调度器390、调度器490、调度器590、调度器690、调度器790和调度器890。每个调度器可以调度包括该调度器的存储部件中的目标数据的发送和接收路径。
参照图18,根据本发明构思的一个示例性实施例的半导体装置1还包括调度器31。调度器31基于路径信息调度存储部件之间的发送和接收路径。例如,路径信息可以包括存储部件id信息(图12的1100)、存储部件状态信息(图12的1200)和指令(图12的1300)中的至少一种。如图所示,调度器31可以连接到包括在半导体装置1中的每个存储部件100至800。在这种情况下,调度器31可以直接从各个存储部件100到800接收路径信息,并且可以基于路径信息调度存储部件之间的数据发送和接收路径。在一个示例性实施例中,在第一处理单元10与第二处理单元20之间存在使得它们能够彼此交换数据的直接信道。在一个示例性实施例中,在第一操作模式期间,存储部件彼此交换数据而不经过该信道,而在第二其他操作模式下,使用该信道将连接到一个处理单元的存储部件的数据传送到连接到其他处理单元的存储部件。
图19至图21是用于说明根据本发明构思的一个实施例的基于调度器的调度将存储在源存储部件中的目标数据发送到目的地存储部件的过程的示图。
在图19和图21的描述中,假设布置了连接到第一存储部件3100、第二存储部件3200、第三处理单元3300和第四存储部件3400的第三处理单元3000,连接到第五存储部件4100、第六存储部件4200、第七存储部件4300和第八存储部件4400的第四处理单元4000,连接到第九存储部件5100、第十存储部件5200、第十一存储部件5300和第十二存储部件5400的第五处理单元5000以及连接到第十三存储部件6100、第十四存储部件6200、第十五存储部件6300和第十六存储部件6400的第六处理单元6000,并且连接到同一处理单元的每个存储部件能够经由串行接口执行数据发送和接收。而且,能够在连接到彼此不同的处理单元的相邻存储部件之间实现数据发送和接收,由图中的双向箭头指示。此外,假设第一目标数据dt_t1存储在第七存储部件4300中,第二目标数据dt_t2存储在第十四存储部件6200中。
根据一个示例性实施例,图19至图21的第一存储部件3100、第二存储部件3200、第三存储部件3300、第四存储部件3400、第五存储部件4100、第六存储部件4200、第七存储部件4300、第八存储部件4400、第九存储部件5100、第十存储部件5200、第十一存储部件5300、第十二存储部件5400、第十三存储部件6100、第十四存储部件6200、第十五存储部件6300和第十六存储部件6400中的每一个存储部件对应于图5的第一存储部件100或第二存储部件200,并且可以具有与第一存储部件100或第二存储部件200相同的配置。另外,图19至图21的第三处理单元3000、第四处理单元4000、第五处理单元5000和第六处理单元6000对应于图5的处理单元10,并且可以包括与图5中所例示的配置相同的配置。此外,图19至图21的存储部件之间的串行接口可以对应于图5的第一存储部件100的第一接口端口134或第二存储部件200的第二接口端口234。
参照图19,执行将第一目标数据dt_t1发送到第一存储部件3100的操作。此时,作为存储有第一目标数据dt_t1的存储部件的第七存储部件4300被定义为源存储部件,作为第一目标数据dt_t1最终到达的存储部件的存储部件3100被定义为目的地存储部件。
根据实施例,调度器调度发送第一目标数据dt_t1的路径。在一个实施例中,可以基于包括指令、存储部件id信息和存储部件状态信息的路径信息来确定路径。指令可以包括相邻存储部件之间的优先级顺序信息。下面将描述基于优先级顺序信息选择路径的实施例。
首先,调度器可以通过参照存储部件id信息来确定相邻存储部件。作为源存储部件的第七存储部件4300的相邻存储部件可以被确定为第四存储部件3400、第五存储部件4100、第八存储部件4400和第十三存储部件6100。
此后,基于相邻存储部件之间的优先级顺序信息来选择路径。如图所示,选择第五存储部件4100,并且相应地沿第一路径p1发送第一目标数据dt_t1。例如,由于优先级顺序信息指示第五存储部件4100具有高于第四存储部件3400、第八存储部件4400和第十三存储部件6100的优先级,所以可以选择第五存储部件4100。
此后,调度器可以通过相同的过程选择路径,并且第一目标数据dt_t1通过第二路径p2到达第一存储部件3100并且可以被存储。
在另一个实施例中,存储在第十四存储部件6200中的第二目标数据dt_t2可以通过调度器的调度,通过第三路径p3和第四路径p4到达作为目的地存储部件的第一存储部件3100,并且可以被存储。
为了说明方便起见,例示了执行彼此相邻的存储部件之间的数据发送和接收,但是本发明构思不限于此,并且可以实现非相邻存储部件之间的数据发送和接收。例如,能够在连接到第三处理单元3000的第一存储部件3100与连接到第四处理单元4000的第八存储部件4400之间实现数据发送和接收。
参照图20,根据本发明构思的一个实施例的半导体装置可以执行处理单元之间的数据发送和接收。如图所示,能够在作为相邻存储部件的第三处理单元3000与第四处理单元4000之间、第四处理单元4000与第六处理单元6000之间、第五处理单元5000与第六处理单元6000之间以及第三处理单元3000与第五处理单元5000之间实现数据发送和接收。
参照图20,执行将第一目标数据dt_t1发送到第一存储部件3100的操作。此时,作为存储有第一目标数据dt_t1的存储部件的第七存储部件4300被定义为源存储部件,作为第一目标数据dt_t1最终到达的存储部件的第一存储部件3100被定义为目的地存储部件。第一目标数据dt_t1通过调度器的路径调度,通过第一路径p1和第二路径p2到达作为目的地存储部件的第一存储部件3100,并且可以被存储。
在第二目标数据dt_t2的路径的情况下,选择与图19中确定的路径不同的路径。根据本发明构思的一个实施例,能够在处理单元之间实现数据发送和接收,并且调度器可以基于路径信息将处理单元之间的数据发送和接收路径确定为第二目标数据dt_t2的路径。如图所示,数据沿着第五路径p5从作为源存储部件的第十四存储部件6200被发送到第六处理单元6000,并且第二目标数据dt_t2沿着第六路径p6被发送到作为与第六处理单元6000相邻的处理单元的第五处理单元5000。此后,第二目标数据dt_t2沿着第七路径p7从第五处理单元5000被发送到第三处理单元3000,并且沿着第八路径p8被发送到并被存储在连接到第三处理单元3000的第一存储部件3100,即,目的地存储部件。
参照图21,可以基于存储部件状态信息来调度目标数据的路径。如图所示,假设第二存储部件3200和第九存储部件5100的状态信息包括忙碌状态。
在第一目标数据dt_t1的情况下,调度器可以将第十三路径p13和第十四路径p14确定为第一目标数据dt_t1的传输路径。也就是说,在图19和图20的实施例中描述的第二路径p2的情况下,它包括处于忙碌状态的第二存储部件3200,因此调度器选择不包括处于忙碌状态的存储部件的路径。
类似地,在第二目标数据dt_t2的情况下,第二目标数据dt_t2从作为源存储部件的第十四存储部件6200经由第九路径p9被发送到第十存储部件5200,从第十存储部件5200经由第十路径p10被发送到第四存储部件3400,经由第十一路径p11被发送到第三存储部件3300,并且通过第十二路径p12到达作为目的地存储部件的第一存储部件3100,并且被存储在其中。
在结束详细描述时,本领域技术人员将理解,在基本上不脱离本发明构思的原理的情况下,可以对示例性实施例进行许多变化和修改。
- 还没有人留言评论。精彩留言会获得点赞!