基于决策树的生产线生产状态预测方法及系统与流程
本发明涉及集成电路的制造领域,尤其涉及集成电路生产线的智能制造领域,具体涉及一种基于决策树的集成电路生产线生产状态预测方法及预测系统。
背景技术:
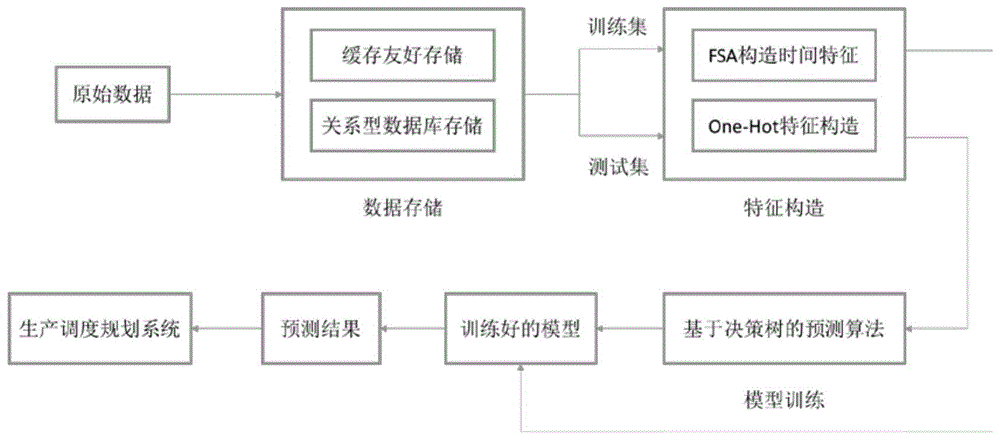
:在集成电路的生产制造过程中,随着所生产的产品的工艺条件的不同,需要对生产线的工作环境进行相应的调整设置,这在一定程度上会影响到生产线利用的效率,造成资源的浪费。因此,在客观上要求能够对生产线未来一段时间内的生产任务进行预测,并统筹规划生产任务,从而减少生产线工作环境的转换,提升生产效率。由于集成电路生产线的工序众多,流程复杂,会产生大量的相互关系复杂的生产数据。在目前由人工进行的生产线生产状态预测,一般都是基于数据的均值、方差等基本统计量,这种预测方式比较粗糙,难以发现数据之间的诸多有价值的相互关系。并且,只有大量的数据才能使得基本统计量具有意义,因此,控制人员通常需要根据较长时间范围内的历史数据,才能实现以天为单位的预测,其结果不仅时效性较差,无法应对集成电路生产线上的诸多实时状态变化,而且结果的准确度也较低,无法很好的满足生产上的需求。技术实现要素:本发明的目的在于提供一种基于决策树的生产线状态预测方法及系统,其基于机器学习技术,设计了一套完整的包含数据处理、预测算法和工程实现在内的解决方案,使得控制人员能够采用滑动窗口,利用较少量的数据,在较短的时间内,得到较高准确率的生产线预测结果。为实现上述目的,其技术方案如下:一种基于决策树的生产线生产状态预测方法,其包括如下步骤:步骤s1:在预测前,采用滑动窗口法,对产线的生产数据条目进行采样;可比较数据格式可比较数据格式所述滑动窗口的时长位于一预定时间t1范围内,所述采样到的所述生产状态数据条目用于形成训练数据集及测试数据集的数据条目,并存入数据库中;步骤s2:在预测时,依据预测所需的时间跨度t2,从所述数据库中取出相同制造步骤的相应数据并分成所述训练数据集和测试数据集,将所述训练数据集和测试数据集中的数据条目进行特征向量构造;所述预测所需的时间跨度t2的时长位于一预定时间t1范围内;步骤s3:采用所述训练数据集中的数据条目的特征向量,对所述产线生产状态预测模型进行训练,以得到训练后的产线生产状态预测模型;采用所述测试数据集的数据条目的特征向量,对所述产线生产状态预测模型进行检验,得到所述产线生产状态预测模型的运算结果准确度;判断所述运算结果准确度是否满足准确度阈值要求,如果否,继续执行步骤s3;如果是,执行步骤s4;步骤s4:基于决策树的产线生产状态预测模型,对所述产线的生产状态进行小时级或更低时间级的预测,并输出所述产线的生产状态的预测结果,以供后续产线生产调度使用。进一步地,所述步骤s1中,通过关系型数据库将采集到的所述生产状态数据条目存入数据库中。进一步地,所述关系型数据库的底层采用b树数据结构。进一步地,所述步骤s2中,如果所述生产数据条目的输出格式包括不可比较数据格式,将所述生产数据条目中的不可比较数据格式数据列合成为一个数据字典,并采用单热点编码方式构造所述不可比较数据格式数据特征向量。进一步地,所述步骤s2中,如果所述生产数据条目的输出格式包括可比较数据格式,将所述生产数据条目中的可比较数据格式数据以整数或非整数方式构造其特征向量。进一步地,所述步骤s2中,如果所述生产数据条目的输出格式包括时间数据格式,将所述生产数据条目中的时间数据以有限状态自动机构造方式构造其特征向量。所述滑动窗口的参数根据产线的运行效率和所述生产状态预测模块运算结果的准确度确定。为实现上述目的,其技术方案如下:一种基于决策树的生产线生产状态预测系统,其包括:数据存储模块,用于在预测前,采用滑动窗口法,对产线的生产数据条目进行采样;其中,所述生产数据条目的输出格式至少包括时间数据格式、可比较数据格式和/或不可比较数据格式;所述滑动窗口的时长位于一预定时间t1范围内,所述采样到的所述生产状态数据条目,用于形成训练数据集及测试数据集,并存入数据库中;数据特征构造模块,用于在预测时,依据预测所需的时间跨度t2,从所述数据库中取出相同制造步骤的所述训练数据集和测试数据集,将所述训练数据集和测试数据集中的数据条目进行特征向量构造;所述预测所需的时间跨度t2的时长位于一预定时间t1范围内;模型训练模块,基于所述的训练数据集和测试数据集中的数据条目的特征向量,对基于决策树的产线状态预测模型进行训练,包括学习和验证的循环迭代,得到用于下一阶段产线状态预测的模型;生产状态预测模块,基于决策树的产线生产状态预测模型,对所述产线的生产状态进行小时级或更低时间级别的预测,并输出所述产线的生产状态的预测结果,以供后续产线生产调度使用。从上述技术方案可以看出,本发明可以实现对集成电路产线小时级别的生产状态预测,其基于机器学习技术设计一套完整的包含数据处理、预测算法、工程实现在内的解决方案,使得控制人员能够采用滑动窗口,利用较少量的训练数据集及测试数据集,在预测前进行产线生产状态预测模型的初始化,并且在预测过程中,通过机器学习,确定和优化该产线生产状态预测模型,接下来就采用该产线生产状态预测模型进行预测,这样就可以在较短的时间内,得到较高准确率的生产线预测结果。附图说明图1所示为本发明基于决策树的集成电路生产线生产状态预测系统一较佳实施例示意图具体实施方式下面结合附图1,对本发明的具体实施方式作进一步的详细说明。需说明的是,附图均采用非常简化的形式、使用非精准的比例,且仅用以方便、清晰地达到辅助说明本实施例的目的。请参阅图1,图1所示为本发明基于决策树的集成电路生产线生产状态预测系统一较佳实施例示意图。如图所示,该集成电路产线生产状态预测系统可以包括一数据存储模块、一数据特征构造模块、一模型训练模块、一生产状态预测和结果输出模块。在本发明的实施例中,在集成电路产线的生产状态数据中,一个生产条目通常可以包含诸多格式差异明显的数据项,例如,记录时间(time)、产品编号(productid)、机器编号(machineid)、生产能力(capacityid)、优先级(priority)、激活状态(hold/activestate)、生产进程(processstate)和生产类型(productionstate)等。其中,记录时间为标准时间格式;优先级等为可进行比较的可比较数据格式数据(例如,用整数表示);产品编号、机器编号、容量编号、激活状态、生产进程和生产类型等均为不可比较数据格式数据。也就是说,在本发明的实施例中,生产数据条目的输出格式至少包括时间数据格式、可比较数据格式和/或不可比较数据格式。可比较数据格式与不可比较数据格式之间是可以互相转换的。数据存储模块用于接收并存储探测到的产线生产状态数据采样。用于机器学习的训练数据集及测试数据集的采样数据均来源于产线的生产状态数据。在本发明的实施例中,采用滑动窗口法对训练数据集及测试数据集进行采样。也即,每当测试基的范围移动一小时时,训练集的起始、结束时间节点相应地移动一小时,以获得新的训练集。滑动窗口的时长位于一预定时间t1范围内,采样到的生产状态数据条目用于形成训练数据集及测试数据集的数据条目,并存入数据库中。较佳地,滑动窗口的参数根据产线的运行效率和生产状态预测模块运算结果的准确度确定。在本发明的实施例中,训练集和测试集的选择可以采用缓存友好的算法,以避免重复采集。假定某一训练集范围为[t0,t1],而下一训练集范围为[t0+1,t1+1],则其中[t0+1,t1]可以存在缓存中,而不必重复采样。然而,上述方法不能适应时间的多样变化,例如一训练集范围从[t0,t1]变动到[t2,t3]等。因此,在构造滑动窗口时,还可以利用关系型数据库,以实现需求更为广泛的数据采集。关系型数据库在底层采用b树数据结构实现数据存储,从而能实现高效的数据插入与查询。每当生产线进行探查采样,得到生产状态数据条目时,本方法就可以便将相应的数据条目插入到数据库中。在查询时,依据训练数据集的不同时间跨度,再将生产状态数据从数据库中取出,进行特征构造并用于产线生产状态的预测。在本发明实施例中的机器学习预测任务中,数据特征构造模块负责集成电路产线的生产数据进行特征数字化,即对选择出的训练数据集和测试数据集中的生产状态数据进行特征构造。具体地,其依据预测所需的时间跨度t2,从数据库中取出训练数据集和测试数据集,将训练数据集和测试数据集中的数据条目进行特征向量构造;预测所需的时间跨度t2的时长位于一预定时间t1范围内。具体的构造方式如下几种:首先,如果生产数据条目的输出格式包括不可比较数据格式,可以将生产数据条目中的不可比较数据格式数据列合成为一个数据字典,并采用单热点编码方式构造特征向量。具体地,对于生产状态数据中的不可比较数据格式数据,可以将生产数据中的不可比较格式的数据列合成为一个数据字典,借用它们的列名进行查找。例如,假设产品编号有三种编号:p1,p2,p3,则相应的特征向量为[1,0,0]、[0,1,0]、[0,0,1]。单热点(one-hotencoding)又称为一位有效编码,主要是采用n位状态寄存器来对n个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。因此,单热点的编码方式规避了向量各位之间的关联,使不同的编码向量可以相互拼接,而不影响其特征构造。例如,某生产条目的产品编号向量为[1,0,0],而其机器编号向量为[0,1],则可以拼接二者,得到该条目的产品-机器编号特征向量:[1,0,0,0,1]。需要说明的是,在采用单热点编码方式构造特征向量时,如果出现测试集的数据不在训练集中的情况,则丢弃不可比较数据格式数据。第二,如果生产数据条目的输出格式包括可比较数据格式数据格式,将生产数据条目中的可比较数据格式数据以整数方式或非整数构造其特征向量。第三,如果生产数据条目的输出格式包括时间数据格式,采用有限状态自动机对所述生产数据条目中的时间数据构造其特征向量。也就是说,当某一产品在某一生产线机器上加工时,会在若干时间点上进行探测采样,由此会产生连贯的生产数据条目。其中,采样所得的时间作为其特征。例如,某一产品在t0时间开始加工,生产线在t1时对其进行采样,而发现其依然处于加工状态,于是便记录t1-t0作为时间。当加工结束,产品离开机器时,则将时间重置为0。该时间特征主要可以用两种方式得到:其一,直接由生产线记录;其二,通过现有的数据条目计算得到。在本发明的实施例中,对于通过现有的数据条目计算得到,较优地,可以采用有限状态自动机算法(finitestateautomata,fsa)进行构造。具体地,对利用有限状态自动机构造时间特征算法可以通过如下实现:首先,需要在数据条目中区分出相同的制造步骤。在本发明的实施例中,可以将产品编号、机器编号、容量编号和优先级四项相同的生产状态数据条目视作同一制造步骤;然后,再根据激活状态、生产进程、生产类型进行有限状态自动机的状态转移。有限自动机主要有三部分:状态转移函数、起始时间值转移函数,时间长度值转移函数。以生产进程为例,其状态转移函数为:起始时间(t0)值转移函数为:当前输入\当前状态reserve状态trackin状态trackout状态waitforreservet0不变化当前时间当前时间waitfortrackin当前时间当前时间当前时间waitfortrackout未定义(丢弃该条目)t0不变化t0不变化假定当前时间为t1,则时间长度值转移函数为:当前输入\当前状态reserve状态trackin状态trackout状态waitforreservet1–t000waitfortrackin000waitfortrackout未定义(丢弃该条目)t1–t0t1–t0通过上述的产线生产状态有限自动机,便可以高效地从现有生产数据条目中计算得到时间特征。需要说明的实施,在实际预测中,由于时间特征的计算占用一定时间,会降低特征构造的速度,因此,也可以不对时间特征进行构造。此外,由有限状态自动机得到产线数据的时间特征,由数据字典得到产品编号、机器编号、容量编号、激活状态、生产进程、生产类型等数据项的单热点特征编码,再加上整数类型的优先级,本发明便构造了生产数据的特征向量,用于接下来的预测算法。请再参阅图1,上述特征构造完成后,就可以基于决策树的集成电路产线生产状态预测的模型进行训练了。即构造好数据特征以后,便采用基于决策树的算法对训练数据集进行训练。在预测过程中,基于决策树的产线生产状态预测模型,并采用训练数据集中的数据条目的特征向量,对产线生产状态预测模型进行训练,以得到训练后的产线生产状态预测模型;以及采用测试数据集的数据条目的特征向量,对产线生产状态预测模型进行检验,得到产线生产状态预测模型的运算结果准确度。也就是说,通过机器学习,确定和优化该产线生产状态预测模型,接下来就采用该产线生产状态预测模型进行预测,这样就可以在较短的时间内,得到较高准确率的生产线预测结果。需要注意的是,上述特征向量,尤其是时间特征及单热点特征,是无法进行归一化的。因为将时间进行0-1归一化限制了时间的范围,而对单热点特征进行归一化是没有物理意义的。因此,适用于上述特征的机器学习算法不应当基于线性模型,也即不应当在模型中进行权重计算。在本发明的实施例中,可以考虑采用基于决策的算法,也即决策树算法,以实现分类与预测。决策树算法有多种变种,包括基于基尼系数的等,但它们的差异很小,因此并不影响预测的结果。对产线的生产状态进行预测所得到相应的预测结果,考虑到预测系统的实时性要求,例如要实现小时级的产线生产调度,则产线生产状态预测和调度系统必须能够在可以接受的时间内给出调度建议,给生产人员留出足够的时间进行调度规划。因此,本实例对数据选取的滑动窗口范围进行了大量的测试,对运行效率和运算结果的准确度两者进行折中,最终选定合适的滑动窗口范围。下面对本发明的一种基于决策树的集成电路生产线生产状态预测方法进行归纳总结如下,其包括步骤:步骤s1:在预测前,采用滑动窗口法,对产线的生产数据条目进行采样;其中,生产数据条目的输出格式至少包括时间数据格式、可比较数据格式和/或不可比较数据格式;滑动窗口的时长位于一预定时间t1范围内,采样到的生产状态数据条目用于形成训练数据集及测试数据集的数据条目,并存入数据库中;步骤s2:在预测时,依据预测所需的时间跨度t2,从数据库中取出相同制造步骤的相应数据并分成训练数据集和测试数据集,将训练数据集和测试数据集中的数据条目进行特征向量构造;预测所需的时间跨度t2的时长位于一预定时间t1范围内;步骤s3:采用训练数据集中的数据条目的特征向量,对产线生产状态预测模型进行训练,以得到训练后的产线生产状态预测模型;采用测试数据集的数据条目的特征向量,对产线生产状态预测模型进行验证,得到产线生产状态预测模型的运算结果准确度;判断运算结果准确度是否满足准确度阈值,如果否,继续执行步骤s3;如果是,执行步骤s4;步骤s4:基于决策树的产线生产状态预测模型,对产线的生产状态进行小时级或更低时间级的预测,并输出产线的生产状态的预测结果,以供后续产线生产调度使用。以上所述的仅为本发明的优选实施例,所述实施例并非用以限制本发明的专利保护范围,因此凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1