一种基于偏差指标的混凝土侵彻深度试验数据异常点检测方法与流程
本发明涉及数据异常检测技术,具体是一种基于偏差指标的混凝土侵彻深度试验数据异常点检测方法。
背景技术:
异常检测是指通过数据挖掘手段识别数据中的“异常点”,对数据质量分析和控制具有重要意义,目前在金融领域、网络安全、电商领域和工业界等都得到了广泛应用。数据质量分析和控制主要包括缺失值的修正、异常值的发现和修正以及数据一致性处理等。
没有可信的数据,数据挖掘构建的模型将是空中楼阁。异常点的检测和清除是数据挖掘的重要工作环节,它可以识别出数据源中的故障和错误,以免他们在后续的数据处理过程中逐渐累积,以至于造成错误的挖掘结果。另外,如果元数据中存在异常点,会降低一些数据挖掘算法的效率,可能会在数据模型中引入非正态分布或其它的数据复杂性,从而难以(甚至不可能)以可行的计算方式找到准确的数学模型。因此,在进行后续分析之前,就应该对底层数据库中的数据进行异常值去除处理。
在武器毁伤效应试验中,由于试验条件差别、侧重方向不同、量测技术与标准差异、实验误差、人为因素以及记录和数据录入失误等不可避免的因素,会导致一些样本不符合数据模型的一般规则,或与其它样本存在较大偏差,这些样本即为“数据异常点”。同时,由于武器效应研究具有一定的涉密性,在出版时会对涉密数据的故意修改,特别是诸如ad报告、外军或武器研制单位所发表的文章红研究报告,处于保密需要而对数据局做的调整。另外,其它情报来源所获取的数据,可能存在对方故意加入噪声数据或者假数据,也是常见的数据异常来源之一。
武器毁伤效应数据异常检测的难度主要有几点:
(1)在大多数实际的场景中,数据本身是没有标签的,即数据本身的规律性并没有被发掘,或者一些数据集有标签但标签的可信度非常低,导致放入模型后效果很差,导致无法直接使用一些成熟的有监督学习方法。
(2)对军事演习、训练以及实战数据等,常常存在噪音和异常点混杂在一起的情况难以区分。
(3)在一些欺诈(示伪)检测的场景中,多种诈骗数据都混在一起,很难区分不同类型的诈骗,特别是现在信息化战争条件下的各种数据伪装技术,更对如何识别数据的异常提出新的挑战。
(4)对于一维或者维数较低的数据,定义异常性较为简单。但当数据对象又多个属性(多个维度)时,它很可能在一个属性上正常,另一个属性上异常,此时异常的定义比较困难。而对多数常规武器毁伤效应,其属性都是多维的,属性数越多,定义异常就越困难。
(5)一个数据对象可能全局看是异常,但局部看确实正常的,这可能会导致异常检测错误。
由于没有准确的标签,也没有对具体诈骗(示伪)类型的裂解,就导致数据异常分析中陷入“鸡生蛋”或者“蛋生鸡”的循环之中。要解决这种情况,目前比较常用的手段是将无监督学习方法和专家经验相结合,基于无监督学习得到检测结果,并让专家基于检测结果给出反馈,以此为基础,及时调整模型,反复进行选代,最终得到一个越来越准确的模型。
数据异常点检测算法包括多种,常用的有基于统计建议的方法、基于深度的方法、基于偏差的方法、基于距离的方法、基于密度的方法和深度学习方法等。根据数据类型、数据维度以及异常点特点等因素,可选择不同的算法。常用的方法有基于统计检验的方法、基于深度的方法、基于距离的方法、基于密度的方法与基于偏差的方法等。
基于统计检验的方法的不足在于均值和方差本身都对异常值很敏感,因此如果数据本身不具备正态性,就不适合使用。基于深度的数据异常模型不适用于毁伤数据的多维空间问题。对毁伤效应试验而言,受试验成本、量测条件、试验场地等因素的影响,往往以缩比试验为主,原型试验甚至大尺度缩比试验都相对较少,使用基于距离的方法会导致样本数较少,且常有原型数据被检测为异常点。
基于偏差的方法是一种比较简单的统计方法,最初是为单维异常检测设计的,给定一个数据集后,对每个点进行检测,如果一个点自身的值与整个集合的指标存在过大的偏差,则该点为异常点。对多维数据异常检测,算法核心是确定数据样本的指标,以确定将某个点从集合提出后方差所降低的值,通过设定一个阈值,将这些偏差值进行比较以确定哪些点存在异常。目前,在混凝土侵彻深度试验中,采集的毁伤试验数据存在分布规律不明确、数据多维等特点,导致确定毁伤效应的控制因素较多,而试验样本数量又足够多,且未对数据异常点进行剔除,使得数据异常点对于数据的统一性和进行数据挖掘后得到的结果不尽人意,因此,有必要设计一种基于偏差指标的数据异常检测方法,来剔除其中的数据异常点,从而完善混凝土侵彻深度试验样本数据的获取。
技术实现要素:
本发明的目的是提出一种基于偏差指标的混凝土侵彻深度试验数据异常点检测方法,通过结合毁伤数据的特点,综合分析各种算法,选择基于偏差的方法剔除毁伤数据的异常点,而基于偏差的方法核心是定义偏差函数,因此采用bp神经网络来对样本进行拟合学习,以剔除异常点。
为实现上述目的,本发明采用以下技术方案:
一种基于偏差指标的混凝土侵彻深度试验数据异常点检测方法,包括以下步骤:
步骤1、数据准备,收集混凝土侵彻深度试验样本以获得试验数据,试验数据包括:侵彻深度h、弹体直径d、弹头形状因子n、弹头质量m、靶标密度ρt、速度v,靶标单轴抗压强度σ;试验数据集样本的靶标材料均为混凝土,将全部的试验样本进行标记,每一个试验样本按序标记一个唯一的id值;
步骤2、数据预处理,采用混凝土侵彻深度无量纲公式对每个试验样本的试验数据进行无量纲处理,获取统一的属性指标,将全部试验样本按照统一的属性指标从高到低排列,均匀抽取其中的一部分样本数据作为测试样本集,剩余的试验样本作为训练样本集;所述混凝土侵彻深度无量纲公式如下:
公式(1)中,
步骤3、建立神经网络,试验样本无量纲化后,侵彻深度预测过程表示为:f:x→y,其中
f(x1,x2,x3)=y(2),
在数据异常检测阶段,不考虑弹头形状系数n,因此,函数表达式(2)简化为非线性函数
f(x1,x2)=y(3),
其输入参数为
步骤4、神经网络训练和异常点检测,以步骤2中的训练样本集和测试样本集对步骤3中建立的神经网络模型进行训练,训练完成后,保存当前的bp神经网络模型并用此模型计算出每个试验样本的无量纲侵彻深度fa*,而每个试验样本真实的无量纲侵彻深度为ya,设定每个试验样本的拟合结果相对偏差百分比为
所述步骤4中,定义异常试验样本占总试验样本数的百分比为5%。
本发明的有益效果是:本发明是现有技术中率先针对混凝土材料,建立了基于偏差指标的混凝土侵彻深度实验数据异常点检测技术;该技术可识别混凝土侵彻深度实验数据中的异常样本,提高后续数据挖掘处理精度;同时也可对混凝土结构试验数据在后续的数据挖掘中提供重要的技术支撑。
附图说明
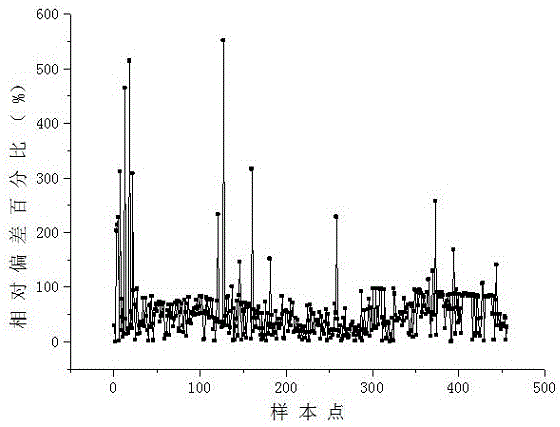
图1为实施例中各样本点相对误差百分比的二维分布图。
图2为实施例中计算机模拟的非线性模型和试验样本进行可视化图。
具体实施方式
下面结合具体实施例对本发明作进一步的详细说明。
实施例
现有混凝土侵彻深度试验样本456条,要剔除其中的数据异常点,则有如下方法:首先将所有的试验样本进行标记,每一个试验样本标记一个唯一的id值,从1到456,以便对实验样本数据进行具体操作;然后对试验样本进行无量纲处理,以降低参数维度,均匀分取训练样本集与测试样本集;接着建立bp神经网络对整个试验样本进行拟合,以求生成能够拟合大部分试验样本的非线性函数;最后按照比例判定异常样本。
其具体方法如下:
一种基于偏差指标的混凝土侵彻深度试验数据异常点检测方法,包括以下步骤:
步骤1、数据准备,收集混凝土侵彻深度试验样本以获得试验数据,试验数据包括:侵彻深度h、弹体直径d、弹头形状因子n、弹头质量m、靶标密度ρt、速度v,靶标单轴抗压强度σ;试验数据集样本的靶标材料均为混凝土,将全部的试验样本进行标记,每一个试验样本按序标记一个唯一的id值,以便对实验样本数据进行具体操作;
数据样本的着靶标速度范围从0m/s到1600m/s;样本的着靶速度主要集中在0-400m/s区间,大于1000m/s的样本较少;
试验数据的质量范围从0kg到2200kg,主要集中在0-50kg,大于50kg的样本偏少;
样本的弹头形状主要为三种形状:平头弹,钝头弹和尖头弹,其中试验样本弹头为平头弹的样本数量为156个,试验样本为钝头弹的数量为295个,试验样本为尖头弹的数量为5个,试验样本主要为钝头弹和平头弹,尖头弹的样本数量稀少;
试验样本的直径分布范围从0m到0.69m;但是试验数据主要分布在0.02-0.1m之间,大于0.01m或小于0.01m的试验数据样本偏少;
步骤2、数据预处理,对样本数据进行筛选,将其中的一部分抽取为测试数据,这时需要从样本中均匀地取出测试数据,使得测试数据样本的影响因素范围覆盖整个试验样本,因此需要有一个相对统一的属性指标,可以将样本按照此属性指标从高到低排列,从而使得之后可以均匀取出其中的测试数据。下列混凝土侵彻深度无量纲公式符合这一需求:
公式(1)中,
步骤3、建立神经网络,试验样本无量纲化后,侵彻深度预测过程可以表示为:f:x→y;实验所要做的就是建立一个x到y之间的关系,从而能够准确的预测出y的值;其中
步骤4、神经网络训练和异常点检测,将所有的456条试验样本输入设计好的bp神经网络中,训练完300个epoch后,损失函数已经几乎不再下降,保存当前的bp神经网络模型,这个模型实质上是一个拟合大量样本的非线性函数f(x1,x2),用此模型计算出试验样本的无量纲侵彻深度为fa*(a=1,2...,456),定义试验样本真实的无量纲侵彻深度为ya(a=1,2...,456),则当
计算模型对每个试验样本的拟合结果相对偏差百分比
接着将此非线性模型和试验样本进行可视化,如说明书附图2所示,其中可以用不同颜色显示偏离非线性函数的试验样本和正常样本,所呈现的曲面为拟合试验样本的非线性函数。
本发明未详述部分为现有技术。
- 还没有人留言评论。精彩留言会获得点赞!