基于分布式估计算法的云工作流调度优化方法与流程
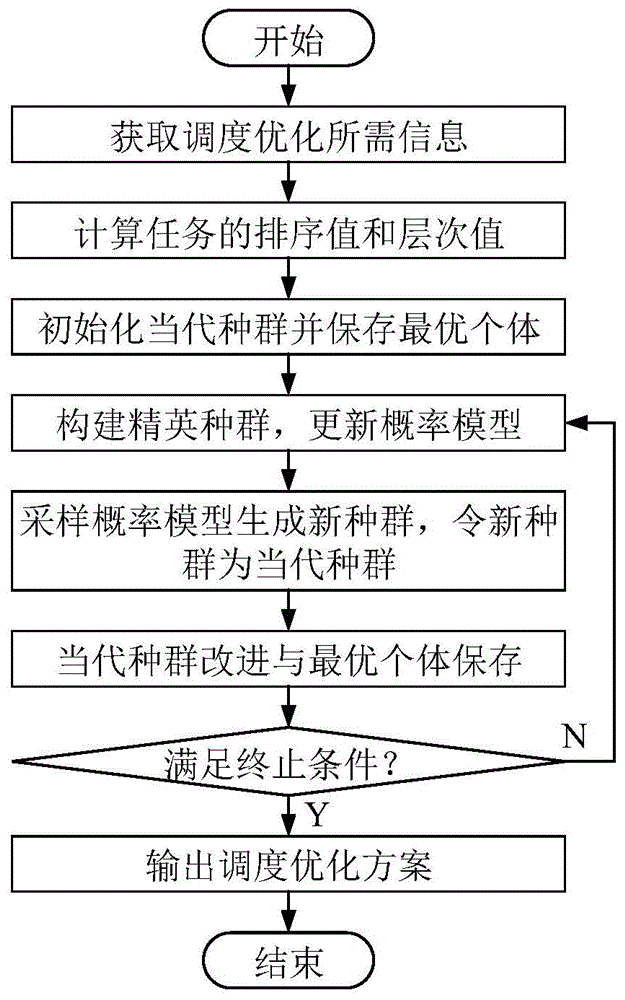
本发明涉及计算机技术、信息技术和系统工程领域,具体涉及一种云工作流调度优化方法,更具体的说,尤其涉及一种基于分布式估计算法的云工作流调度优化方法。
背景技术:
:云计算环境下的工作流,简称“云工作流”,是云计算与工作流相关技术的整合,在需要高效计算性能和大规模存储支撑的跨组织业务协作、科学计算等领域具有广泛的应用前景。在云工作流中,任务与任务之间存在着时序约束,执行时通常以虚拟机作为计算资源的最小分配单位负责接收并处理这些任务。云工作流调度是指在满足任务时序和用户需要约束下如何把云工作流中的任务分配到合适的虚拟机上,以及如何安排被分配到虚拟机上的任务的执行顺序,即要解决两个方面的问题:任务分配和任务执行顺序。云工作流调度直接决定了整个云工作流系统的性能,已成为云工作流系统的一个重要研究内容。当前云工作流调度优化方法可以分为三类:1)启发式方法,是指工作流任务分配和执行顺序都用启发式方法生成,如:heterogeneousearliestfinishtime即heft、criticalpathonaprocessors即cpop、levelizedmintime即lmt、dynamiclevelscheduling即dls、dynamiccriticalpath即dcp、longestdynamiccriticalpath即ldcp等方法;2)智能计算方法,是指工作流任务分配和执行顺序都通过智能计算方法来搜索生成;如:遗传算法ga、粒子群优化算法pso、模拟退火算法sa等方法;3)结合启发式的半智能计算方法,是指工作流任务分配通过智能计算方法来搜索生成而任务执行顺序则根据智能计算方法搜索生成的任务分配方案采用基于优先级的启发式方法生成,或工作流任务执行顺序通过智能计算方法来搜索生成而任务分配则根据智能计算方法搜索生成的任务执行顺序通过基于任务最早完成时间的启发式方法来生成。然而,现有的这些云工作流调度优化方法有着如下缺点:1)启发式方法能在较短的时间获得一个调度优化方案,但其质量通常不是很高而且依赖于工作流的类型;2)智能计算方法的算法效率依赖于编码与解码、进化迭代策略的设计及控制参数的选择等,其中,结合启发式的半智能计算方法搜索的解空间即调度方案是不完整的,因此其理论上存在搜索不到最优调度方案的可能性,同时在算法中需要不断调用启发式方法,其时间效率也不是很高;智能计算方法其理论上可以实现全域搜索,但采用全域搜索会导致搜索效率降低;因此,随着云工作流复杂性及其应用需求的增加,亟需设计一种更高效方法来解决云工作流调度优化问题。技术实现要素:为了克服启发式方法解的质量通常不是很高而且依赖于工作流的类型,结合启发式的半智能计算方法、基于分层编码的智能计算方法编码搜索空间的不完备性,基于全域的智能计算方法搜索效率不高等不足,本发明提供了一种基于分布式估计算法的云工作流调度优化方法,有效提高了求解的效率与质量。本发明解决其技术问题所采用的技术方案如下:一种基于分布式估计算法的云工作流调度优化方法,包括以下步骤:步骤1:形式化调度问题,获取调度优化所需的信息;获取任务集t={t1,t2,...,ti},其中i是任务的数量,ti表示任务i,即编号为i的任务;获取任务间的时序关系:任务i的父任务集pri,任务i的子任务集sci,其中i=1,2…,i;获取任务相关参数:任务i的长度ti.length,即任务i被虚拟机处理时需要耗费的指令数量,处理任务i时需要的输入文件列表ti.ifl,任务i被处理后产生的输出文件列表ti.ofl,及文件列表中文件file的大小file.size,其中i=1,2…,i;任务i是任务i+的父任务的充要条件为:存在一个文件file,file是任务i的输出文件同时又是任务i+的输入文件,即:获取云计算环境下的虚拟机集vm={vm1,vm2,…,vmj},其中j是虚拟机的数量,vmj表示虚拟机j,即编号为j的虚拟机;获取虚拟机相关参数:虚拟机j的计算能力vmj.ps,虚拟机j的带宽vmj.bw,其中j=1,2…,j;获取任务与虚拟机之间的支持关系:虚拟机j可以处理的任务集tj,其中j=1,2…,j;可以处理任务i的虚拟机集vmi,其中i=1,2…,i;步骤2:计算任务的排序值rank;先计算ti执行时的平均处理时间需要从共享数据库获得输入文件的平均传输时间需要从其它虚拟机获得输入文件的平均传输时间ti执行时的平均处理时间计算如下:ti执行时需要从共享数据库获得输入文件的平均传输时间为:ti执行时需要从其它虚拟机获得输入文件的平均传输时间为:其中为ti-和ti间的文件平均传输时间,其计算如下:然后,计算任务i的自下而上排序值其计算过程如下:对于没有子任务的结束任务i:其它任务的自下而上排序值采用如下递归公式进行计算:接着,计算任务i的自上而下排序值其计算过程如下:对于没有父任务的开始任务i:其它任务的自上而下排序值采用如下递归公式进行计算:最后,计算任务i的排序值ranki:其中,i=1,2…,i;步骤3:计算任务的层次值;对于没有父任务的开始任务i,其层次值为:leveli=1(10)其它任务的层次值采用如下递归公式进行计算:步骤4:初始化当代种群,进行最优个体保存;基于heft_lbt生成1个个体、对初始概率模型进行n-1次采样生成n-1个个体,形成初始当代种群,同时把初始当代种群中的最优个体保存于bestchrom中,即令bestchrom为初始当代种群中的最优个体;其中n是种群规模;所述个体采用2i位整数编码,i为任务数量,其方法如下:ch={g1,…,gi,gi+1,…,g2i},基因gi是一个非负整数;其中,{g1,…,gi}是虚拟机分配列表,gi表示给任务i分配的虚拟机编号,即把任务i分配给虚拟机gi,gi∈vmi,例如:g1=2表示1号任务是分配给2号虚拟机的;{gi+1,…,g2i}是任务调度顺序列表,是1,…,i的一个排列,且满足任务的时序约束,即任何任务都不能排在其父任务的前面,gi+i表示第i个被调度的任务的编号,即任务gi+i是第i个被调度的,例如gi+1=3,表示第1个调度的任务是3号任务;所述基于heft_lbt生成1个个体包括如下步骤:步骤a1:令所有虚拟机可得时间段列表vatlj={[0,m]},j=1,…,j,m为一个接近无穷大的数;令所有任务的就绪时间rti=0,i=1,…,i;令变量q=1;令任务集ut=t;步骤a2:从ut中找出层次值最小的任务,然后从中取出一个rank最大的任务,不妨设为ti,gi+q=i;步骤a3:令ti的可得虚拟机集avmi=vmi,计算把ti分别分配给avmi中的每个虚拟机后ti的完成时间:步骤a3.1:从avmi中取出一个虚拟机,不妨设为vmj;步骤a3.2:计算ti分配给vmj处理后的执行时间步骤a3.3:在vatlj中从早到晚找出一个空闲时段[νj,υj],满足υj-νj≥eti,j和υj-eti,j≥rti;步骤a3.4:计算ti分配给vmj处理后的开始时间si,j=max{νj,rti},完成时间fi,j=si,j+eti,j;步骤a3.5:若avmi不为空则转到步骤a3.1,否则转到步骤a4;步骤a4:按虚拟机顺序找出能最早完成ti的虚拟机,不妨设为vmj,gi=j,把ti分配给vmj:步骤a4.1:令ti的开始时间si=si,j,ti的完成时间fi=fi,j;步骤a4.2:更新ti的子任务的就绪时间步骤a4.3:在虚拟机可得时间段列表vatlj中删除[νj,υj],插入区间长度大于0的[νj,si]和[fi,υj];步骤a5:令q=q+1,若ut不为空则转到步骤a2,否则转到步骤a6;步骤a6:获得一个基于heft_lbt的个体ch={g1,…,gi;gi+1,…,g2i},计算其适应度值,操作结束;其中:ωi,j:是vmj处理ti的时间,是把ti分配给vmj处理时需要从其它的虚拟机获得输入文件的文件传输时间,是处理的虚拟机;τi,j:是把ti分配给vmj处理时需要从共享数据库获得输入文件的文件传输时间,所述概率模型包括虚拟机分配概率模型pmvm(k)和任务调度顺序概率模型pms(k);其中αi,j(k)表示在第k代任务ti分配给虚拟机vmj的概率,其中βi,i′(k)表示在第k代第i′个调度的任务是ti的概率,初始虚拟机分配概率模型为:其中:标记值初始任务调度顺序概率模型为:其中:stsρ={ti|ξi<ρ≤i-ζi}是可以安排在第ρ个调度的任务集,ζi是任务i的子孙任务的数量,ξi是任务i的祖先任务的数量;标记值所述子孙任务和祖先任务的定义描述如下:如果存在一个任务序列满足是的父任务,其中1≤k<n,那么是的祖先任务,是的子孙任务;对概率模型pmvm(k)和pms(k)进行1次采样生成1个个体包括如下步骤:步骤b1:系统状态初始化:步骤b1.1:令所有虚拟机可得时间段列表vatlj={[0,m]};m为一个接近无穷大的数;步骤b1.2:令任务就绪时间rti=0、任务集p(ti)=pri,i=1,…,i;令任务集ut=t;令变量q=0;步骤b1.3:把ut中的ti移到rt中;步骤b2:令q=q+1;根据[β1,q(k)…βi,q(k)]t采用轮盘赌法从rt中随机选择一个任务,不妨设为ti,令gi+q=i;步骤b3:根据[αi,1(k)…αi,j(k)]采用轮盘赌法随机选择一个虚拟机,不妨设为vmj,令gi=j;步骤b4:把ti分配给vmj:步骤b4.1:计算ti的执行时间步骤b4.2:在vatlj中从早到晚找出一个空闲时段[νj,υj],满足υj-νj≥eti和υj-eti≥rti;步骤b4.3:ti的开始时间si=max{νj,rti},ti的结束时间fi=si+eti;步骤b4.4:更新ti的子任务的就绪时间步骤b4.5:在虚拟机可得时间段列表vatlj中删除[νj,υj],插入区间长度大于0的[νj,si]和[fi,υj];步骤b4.6:在所有中删除ti,在rt中删除ti;步骤b4.7:把ut中的ti移到rt中;步骤b5:如果rt不为空,则转到步骤b2,否则转到步骤b6;步骤b6:获得一个个体ch={g1,…,g2i}及其所有任务的执行时间和完成时间:eti,fi,i=1,2…,i,计算其适应度值,操作结束;步骤5:构建精英种群,更新概率模型;根据适应度值从优到劣选取当代种群中的前个个体作为当代精英种群pope,ne为精英种群规模,re∈(0,1)为精英率,由当代精英种群根据公式(16)和(17)更新虚拟机分配概率模型和任务调度顺序概率模型;虚拟机分配概率模型的更新:其中:标记值θ1∈(0,1)是虚拟机分配概率模型的更新速率;任务调度顺序概率模型的更新:其中:标记值θ2∈(0,1)是任务调度顺序概率模型的更新速率;步骤6:采样概率模型生成新种群,令新种群为当代种群;对当前概率模型pmvm(k)和pms(k)进行n次采样生成n个个体,形成的新种群,令新种群当代种群;步骤7:当代种群改进与最优个体保存;采用fbi&d和ldi对当代种群进行改进,如果改进后的当代种群中的最优个体优于bestchrom中保存的个体,则用最优个体替换保存在bestchrom中的个体;所述fbi&d方法包括如下步骤:步骤c1:把个体ch中的任务调度顺序列表根据任务完成时间fi从大到小重新排列,即把ch中的基因gi+i设置为倒数第i个完成的任务,i=1,…,i,形成反向个体步骤c2:对采用基于插入模式的串行反向个体解码方法进行解码获得所有任务反向完成时间及其反向工作流响应时间若小于rs,则转到步骤c3,否则,转到步骤c5;步骤c3:把反向个体中的任务调度顺序列表根据任务反向完成时间从大到小重新排列,即把中的基因gi+i设置为倒数第i个完成的任务,i=1,…,i,形成个体ch;步骤c4:采用基于插入模式的串行个体解码方法对个体ch进行解码,获得所有任务的完成时间f1,…,fi及其工作流响应时间rs;如果rs小于则转到步骤c1,否则,转到步骤c5;步骤c5:输出个体ch及其适应度值即工作流响应时间rs,操作结束;所述ldi方法包括如下步骤:步骤d1:计算各虚拟机负载步骤d2:找出负载最小的虚拟机j′;如果ldj′>0,转到步骤d3,否则转到步骤d4;步骤d3:令任务集转到步骤d5;步骤d4:令任务集stj′=tj′,转到步骤d5;步骤d5:如果stj′不为空,则从stj′中按顺序取出一个其所在虚拟机的负载是最高的任务i′,转到步骤d6;否则转到步骤d7;步骤d6:令gi′=j′,形成新的个体采用fbi&d方法对进行解码与改进,如果相对于原个体有改进,则用此改进的个体替换原个体,转到步骤d7;否则转到步骤d5;步骤d7:ldi操作结束;步骤8:判断是否满足终止条件,如果不满足,转到步骤5;否则输出bestchrom中保存的个体,其对应的调度方案作为优化方案;所述终止条件为迭代到指定的代数tg或连续迭代gg代最优个体没有改进。进一步的,所述适应度值为工作流响应时间rs,其计算方法如下:其中:rfi是任务i的响应时间,sfli是任务i输出给共享数据库的输出文件集,即适应度值越小,个体越优。进一步的,所述步骤b2中根据[β1,q(k)…βi,q(k)]t采用轮盘赌法从rt中随机选择一个任务的具体步骤如下:步骤b2.1:计算rt中每个ti被选中的概率步骤b2.2:计算累计概率:步骤b2.3:产生一个随机数λ∈[0,1),如果那么选择ti,操作结束。进一步的,所述步骤b3中根据[αi,1(k)…αi,j(k)]采用轮盘赌法随机选择一个虚拟机的具体步骤如下:步骤b3.1:计算vmj被选中的概率aj=αi,j(k),j=1,…,j;步骤b3.2:计算累计概率:步骤b3.3:产生一个随机数λ∈[0,1),如果那么选择vmj,操作结束。进一步的,所述步骤c2中对采用基于插入模式的串行反向个体解码方法进行解码的具体步骤如下:步骤e1:令所有任务的反向就绪时间令变量ε=1;令所有虚拟机可得时间段列表vatlj={[0,m]},j=1,…,j,其中m为一个接近无穷大的数;步骤e2:选取编号为i=gi+ε的任务;步骤e3:基于插入模式把任务i分配给虚拟机gi,不妨设j=gi;步骤e3.1:在vatlj中从早到晚找出一个空闲时段[νj,υj],满足υj-νj≥eti和步骤e3.2:计算任务i的反向开始时间反向完成时间更新任务i的父任务的就绪时间步骤e3.3:在虚拟机可得时间段列表vatlj中删除[νj,υj],插入区间长度大于0的和步骤e4:令ε=ε+1,如果ε≤i,则转到步骤e2,否则步骤e5;步骤e5:获得所有任务的反向完成时间i=1,…,i;计算反向工作流响应时间操作结束。进一步的,所述步骤c4中基于插入模式的串行个体解码方法对个体ch进行解码的具体步骤如下:步骤f1:令所有任务的就绪时间rti=0,i=1,…,i;令所有虚拟机可得时间段列表vatlj={[0,m]},j=1,…,j,m为一个接近无穷大的数;令变量ε=1;步骤f2:选取编号为i=gi+ε的任务;步骤f3:基于插入模式把任务i分配给虚拟机gi,不妨设j=gi;步骤f3.1:在vatlj中从早到晚找出一个空闲时段[νj,υj],满足υj-νj≥eti和υj-eti≥rti;步骤f3.2:计算任务i的开始时间和完成时间:si=max{νj,rti},fi=si+eti;更新任务i的子任务的就绪时间步骤f3.3:在虚拟机可得时间段列表vatlj中删除[νj,υj],插入区间长度大于0的[νj,si]和[fi,υj];步骤f4:令ε=ε+1,如果ε≤i则转到步骤f2,否则步骤f5;步骤f5:获得所有任务的完成时间fi,计算其适应度值即工作流响应时间rs,操作结束。本发明的有益效果在于:(1)相对于启发式方法、结合启发式的半智能计算方法及现有的基于分层编码的智能计算方法,本发明设计采用整数编码方法,任何一个调度方案都可以有一个个体与之对应,因此其搜索空间是完备的,可以实现全域搜索。(2)相对于一般的基于优先级的编码方式,本发明的任务调度顺序采用基于拓扑排序的整数编码方法,考虑了任务之间的时序关系,有效减少了编码的空间,进而提高了算法的效率。(3)相对于普通智能计算方法,本发明设计增加了基于向前向后个体解码的启发式改进方法fbi&d和基于负载均衡的启发式改进方法ldi,从而提高整个算法寻优能力和搜索效率。(4)本发明采用最优个体保存策略,可以保证最优个体不被破坏,使算法单调收敛。(5)相对于传统智能计算方法如ga等,本发明设计的算法使用采样替换了遗传操作来生成新的个体,算法更简洁。(6)本发明在初始种群中播入了一个基于heft_lbt的个体,可以使算法在一个比较高的起点上开始搜索,从而缩短搜索时间。附图说明图1是本发明一种基于分布式估计算法的云工作流调度优化方法的流程示意图。图2是本发明实施例中montage工作流任务间的时序关系图。具体实施方式下面结合图1、图2及实施例对本发明做进一步详细说明,但本发明并不仅限于以下的实施例。假设一个云计算中心有编号为1至6的6台虚拟机可供使用,vm1、vm2、…、vm6的处理能力和带宽如表1所示;一个montage工作流任务间的时序关系如图2所示,由编号为1至15的15个任务组成,t1、t2、…、t15的执行长度,处理所需要的输入文件和处理后的输出文件的名称、长度以及可以被处理的虚拟机如表2所示。虚拟机处理能力(mi/s)带宽(mbit/s)虚拟机处理能力(mi/s)带宽(mbit/s)vm11000200vm42000300vm21000200vm53000400vm32000300vm63000400表1表2针对上述案例,如图1所示,一种基于分布式估计算法的云工作流调度优化方法,包括以下实施步骤:执行步骤1:形式化调度问题,获取调度优化所需的信息;获取任务集t={t1,t2,t3,t4,t5,t6,t7,t8,t9,t10,t11,t12,t13,t14,t15};获取任务间的时序关系,即任务i的父任务集pri和子任务集sci:pr4={t1},pr5={t1,t2},pr6={t1,t3},pr7={t4,t5,t6},pr8={t7},pr9={t1,t8},pr10={t2,t8},pr11={t3,t8},pr12={t9,t10,t11},pr13={t12},pr14={t13},pr15={t14};sc1={t4,t5,t6,t9},sc2={t5,t10},sc3={t6,t11},sc4={t7},sc5={t7},sc6={t7},sc7={t8},sc8={t9,t10,t11},sc9={t12},sc10={t12},sc11={t12},sc12={t13},sc13={t14},sc14={t15},获取任务的相关参数:t1.length=126000mi,t1.ifl={fd1,fd2},t1.ofl={f1-1,f1-2};t2.length=138000mi,t2.ifl={fd1,fd3},t2.ofl={f2-1,f2-2};t3.length=132000mi,t3.ifl={fd1,fd4},t3.ofl={f3-1,f3-2};t4.length=102000mi,t4.ifl={fd1,f1-1,f1-2},t4.ofl={f4-1,f4-2};……;t15.length=7800mi,t15.ifl={f14-1},t15.ofl={f15-1};fd1.size=36mb,fd2.size=4320mb,f1-1.size=3960mb,f1-2.size=3960mb,……,f14-1.size=1560mb,f15-1.size=420mb;获取云计算环境下的虚拟机集:vm={vm1,vm2,vm3,vm4,vm5,vm6};获取虚拟机相关参数:vm1.ps=1000mi/s,vm1.bw=200mbit/s;vm2.ps=1000mi/s,vm2.bw=200mbit/s;vm3.ps=2000mi/s,vm3.bw=300mbit/s;vm4.ps=2000mi/s,vm4.bw=300mbit/s;vm5.ps=3000mi/s,vm5.bw=400mbit/s;vm6.ps=3000mi/s,vm6.bw=400mbit/s;获取任务与虚拟机之间的支持关系:t1={t1,t2,t3,t4,t5,t6,t9,t13,t15},t2={t3,t5,t7,t9,t10,t11,t14},t3={t2,t3,t4,t6,t9,t11,t12},t4={t1,t2,t4,t6,t7,t8,t9,t10,t11,t12,t14},t5={t1,t2,t3,t4,t6,t7,t8,t9,t12,t14},t6={t1,t4,t5,t8,t11,t13,t14,t15};vm1={vm1,vm4,vm5,vm6},vm2={vm1,vm3,vm4,vm5},vm3={vm1,vm2,vm3,vm5},vm4={vm1,vm3,vm4,vm5,vm6},vm5={vm1,vm2,vm6},vm6={vm1,vm3,vm4,vm5},vm7={vm2,vm4,vm5},vm8={vm4,vm5,vm6},vm9={vm1,vm2,vm3,vm4,vm5},vm10={vm2,vm4},vm11={vm2,vm3,vm4,vm6},vm12={vm3,vm4,vm5},vm13={vm1,vm6},vm14={vm2,vm4,vm5,vm6},vm15={vm1,vm6}。执行步骤2:计算任务的排序值rank;首先,计算ti执行时的平均处理时间同理可得结果如表3所示:表3计算ti执行时需要从共享数据库获得输入文件的平均传输时间同理可得结果如表4所示:表4计算和ti间的文件平均传输时间:同理可得其它任务间的文件平均传输时间,结果如表5所示:表5计算ti执行时需要从其它虚拟机获得输入文件的平均传输时间同理可得结果如表6所示:表6然后,计算任务i的同理可得其它任务的结果如表7所示;接着,计算任务i的同理可得其它任务的结果如表7所示;最后,计算任务i的ranki:同理可得其它任务的ranki,结果如表7所示:表7执行步骤3:计算任务的层次值;任务1、任务2和任务3均没有父任务,则level1=level2=level3=1;任务4只有一个父任务1,则同理,可以获得其它任务的层次值:level5=level6=2;level7=3;level8=4;level9=level10=level11=5;level12=6;level13=7;level14=8;level15=9。执行步骤4:初始化种群,进行最优个体保存;取种群规模n=10;基于heft_lbt生成1个个体、对初始概率模型进行9次采样生成9个个体,形成初始当代种群。基于heft_lbt生成一个个体的具体实施过程如下:执行步骤a1:初始化所有虚拟机的可得时间段列表vatl1={[0,m]},vatl2={[0,m]},…,vatl6={[0,m]},m为一个接近无穷大的数;初始化所有任务的就绪时间:rt1=0,rt2=0,…,rt15=0;q=1;ut=t=t={t1,t2,t3,t4,t5,t6,t7,t8,t9,t10,t11,t12,t13,t14,t15};执行步骤a2:任务集ut中层次最小的任务为t1,t2,t3,由于rank1=4095.28,rank2=4114.79,rank3=4047.06,从中取出一个rank最大的任务,其为t2,则gi+q=g15+1=g16=2,ut={t1,t3,…,t15};执行步骤a3:令avm2=vm2={vm1,vm3,vm4,vm5},计算把t2分配给avm2中的每个虚拟机后t2的完成时间;即执行步骤a3.1:从avm2中取出vm1;执行步骤a3.2:计算t2分配给vm1处理后的执行时间:ω2,1=138000/1000=138,则执行步骤a3.3:在vatl1中从早到晚找出一个空闲时间段[0,m],满足m-0≥et2,1=312.24和m-312.24≥rt2=0;执行步骤a3.4:计算t2分配给vm1处理后的开始时间s2,1=max{v1,rt2}=max{0,0}=0,完成时间f2,1=s2,1+et2,1=0+312.24=312.24;执行步骤a3.5:由于avm2={vm3,vm4,vm5}不为空,转到步骤a3.1;……;这样不断重复执行步骤a3.1至步骤a3.5,直至avm2为空,得到s2,3=0,s2,4=0,s2,5=0,f2,3=185.16,f2,4=185.16,f2,5=133.12,转至步骤a4;执行步骤a4:按虚拟机顺序找出能最早完成t2的虚拟机,其为vm5,g2=5,把t2分配给vm5;即执行步骤a4.1:令t2的开始时间s2=s2,5=0,完成时间f2=f2,5=133.12;执行步骤a4.2:更新t2的子任务的就绪时间rt5=max{rt5,f2}=max{0,133.12}=133.12,rt10=133.12;执行步骤a4.3:在虚拟机可得时间段列表vatl5中删除[0,m],插入区间长度大于0的[133.12,m],即vatl5={[133.12,m]};执行步骤a5:q=q+1=1+1=2,任务集ut={t1,t3,…,t15}不为空,转到步骤a2;执行步骤a2:任务集ut={t1,t3,…,t15}中层次最小的任务为t1,t3,由于rank1=4095.28,rank3=4047.06,从中取出一个rank最大的任务,其为t1,则g17=1;执行步骤a3:令avm1=vm1={vm1,vm4,vm5,vm6},计算把t1分配给avm1中的每个虚拟机后t1的完成时间;即执行步骤a3.1:从avm1中取出vm1;执行步骤a3.2:计算t1分配给vm1处理后的执行时间:ω1,1=126,τ1,1=174.24,则et1,1=300.24;执行步骤a3.3:在vatl1中从早到晚找出一个空闲时间段[0,m],满足m-0≥300.24和m-300.24≥0;执行步骤a3.4:计算t1分配给vm1处理后的开始时间s1,1=max{0,0}=0,完成时间f1,1=300.24;执行步骤a3.5:avm1={vm4,vm5,vm6}不为空,转到步骤a3.1;……;这样不断重复执行步骤a3.1至步骤a3.5,直至avm1为空,得到s1,4=0,s1,5=133.12,s1,6=0,f1,4=179.16,f1,5=262.24,f1,6=129.12,转至步骤a4;执行步骤a4:按虚拟机顺序找出能最早完成t1的虚拟机,其为vm6,g1=6,把t1分配给vm6;即执行步骤a4.1:令t1的开始时间s1=s1,6=0,完成时间f1=f1,6=129.12;执行步骤a4.2:更新t1的子任务的就绪时间rt4=max{rt4,f1}=max{0,129.12}=129.12,rt5=max{rt5,f1}=max{133.12,129.12}=133.12,rt6=129.12,rt9=129.12;执行步骤a4.3:在虚拟机可得时间段列表vatl6中删除[0,m],插入区间长度大于0的[129.12,m],即vatl6={[129.12,m]};执行步骤a5:q=2+1=3,任务集ut={t3,…,t15}不为空,转到步骤a2;……这样不断重复执行步骤a2至步骤a5,直至ut为空集,确定所有的基因值,转至步骤a6;执行步骤a6:获得一个基于heft_lbt生成的个体ch1={6,5,3,5,6,3,5,5,5,4,3,4,6,6,6;2,1,3,5,6,4,7,8,10,9,11,12,13,14,15},计算其适应度值即工作流响应时间rs1:由于而sfl15={f15-1},故操作结束。初始化虚拟机分配概率模型pmvm(1)的过程如下:由于vm1={vm1,vm4,vm5,vm6},则α1,1(1)=δ1,1/|vm1|=1/4=0.25,α1,2(1)=δ1,2/|vm1|=0/4=0.00,α1,3(1)=0.00,α1,4(1)=0.25,α1,5(1)=0.25,α1,6(1)=0.25,同理,可得其它αi,j(1),最终可以得到:初始化任务调度顺序概率模型pms(1)如下:根据任务间的时序关系可知:t1没有祖先任务,其子孙任务为t4,t5,t6,t7,t8,t9,t10,t11,t12,t13,t14,t15,故有ξ1=0,ζ1=12,同理可得:ξ2=0,ζ2=10,ξ3=0,ζ3=10,ξ4=1,ζ4=9,ξ5=2,ζ5=9,ξ6=2,ζ6=9,ξ7=6,ζ7=8,ξ8=7,ζ8=7,ξ9=8,ζ9=4,ξ10=8,ζ10=4,ξ11=8,ζ11=4,ξ12=11,ζ12=3,ξ13=12,ζ13=2,ξ14=13,ζ14=1,ξ15=14,ζ15=0;由ξi,ζi可得sts1={t1,t2,t3},则β1,1(1)=γ1,1/|sts1|=1/3=0.33,β2,1(1)=γ2,1/|sts1|=1/3=0.33,β3,1(1)=1/3=0.33,β4,1(1)=γ4,1/|sts1|=0/3=0.00,β5,1(1)=0/3,……;由ξi,ζi可得sts2={t1,t2,t3,t4},则β1,2(1)=γ1,2/|sts2|=1/4=0.25,β2,2(1)=γ2,2/|sts2|=1/4=0.25,β3,2(1)=0.25,β4,2(1)=0.25,β5,2(1)=0.00,β6,2(1)=0.00,……;由ξi,ζi可得sts3={t1,t2,t3,t4,t5,t6},则β1,3(1)=γ1,3/|sts3|=1/6=0.17,β2,3(1)=1/6=0.17,β3,3(1)=1/6=0.17,β4,3(1)=0.17,β5,3(1)=0.17,β6,3(1)=0.17,β7,3(1)=0.00,β8,3(1)=0.00,……;同理,可得剩余的βi,i′(1),i=1,…,15,i′=4,…,15,最终可以得到:对初始虚拟机分配概率模型pmvm(1)和初始任务调度顺序概率模型pms(1)进行1次采样生成一个个体的具体实施过程如下:执行步骤b1:系统状态初始化;即执行步骤b1.1:令所有虚拟机的可得时间段列表:vatl1={[0,m]},vatl2={[0,m]},…,vatl6={[0,m]},m为一个接近无穷大的数;执行步骤b1.2:令所有任务的就绪时间:rt1=0,rt2=0,…,rt15=0;p(t4)={t1},p(t5)={t1,t2},p(t6)={t1,t3},p(t7)={t4,t5,t6},p(t8)={t7},p(t9)={t1,t8},p(t10)={t2,t8},p(t11)={t3,t8},p(t12)={t9,t10,t11},p(t13)={t12},p(t14)={t13},p(t15)={t14};ut=t={t1,t2,t3,t4,t5,t6,t7,t8,t9,t10,t11,t12,t13,t14,t15};q=0;执行步骤b1.3:把ut中的任务,即t1,t2,t3移到rt中,则rt={t1,t2,t3},ut={t4,t5,t6,t7,t8,t9,t10,t11,t12,t13,t14,t15};执行步骤b2:q=q+1=0+1=1;根据[β1,1(1)…β15,1(1)]t采用轮盘赌法从rt={t1,t2,t3}中随机选择一个任务,即:执行步骤b2.1:计算rt={t1,t2,t3}中每个任务被选中的概率:a2=0.33,a3=0.33;执行步骤b2.2:计算累计概率:执行步骤b2.3:产生一个[0,1)之间的随机数,其为0.97,由于因此选择t3;gi+q=g15+1=g16=3;执行步骤b3:根据[α3,1(1)…α3,6(1)]采用轮盘赌法随机选择一个虚拟机,执行步骤b3.1:计算每个虚拟机被选中的概率:a1=α3,1(1)=0.25,a2=0.25,a3=0.25,a4=0.00,a5=0.25,a6=0.00;执行步骤b3.2:计算累计概率执行步骤b3.3:产生一个[0,1)之间的随机数,其为0.56,由于因此选择vm3;g3=3;执行步骤b4:把t3分配给vm3;即执行步骤b4.1:计算t3的执行时间,ω3,3=132000/2000=66,τ3,3=8×(36+4320)/300=116.16,则执行步骤b4.2:在vatl3中从早到晚找出一个空闲时间段[0,m],满足m-0≥et3=182.16和m-182.16≥rt3=0;执行步骤b4.3:计算t3的开始时间s3=max{v3,rt3}=max{0,0}=0,完成时间f3=s3+et3=0+182.16=182.16;执行步骤b4.4:更新t3的子任务的就绪时间rt6=max{rt6,f3}=max{0,182.16}=182.16,rt11=max{0,182.16}=182.16;执行步骤b4.5:在虚拟机可得时间段列表vatl3中删除[0,m],插入区间长度大于0的[182.16,m],则vatl3={[182.16,m]};执行步骤b4.6:在p(t6)、p(t11)中删除t3,则p(t6)={t1}、p(t11)={t8},在rt中删除t3,则rt={t1,t2};执行步骤b4.7:由于ut中不存在则rt,ut均不变;执行步骤b5:由于rt={t1,t2}不为空,转到步骤b2;执行步骤b2:q=1+1=2;根据[β1,2(1)…β15,2(1)]t采用轮盘赌法从rt={t1,t2}中随机选择一个任务,其为t2,g17=2;执行步骤b3:根据[α2,1(1)…α2,6(1)]采用轮盘赌法随机选择一个虚拟机,其为vm1,g2=1;执行步骤b4:把t2分配给vm1;即执行步骤b4.1:计算t2的执行时间:ω2,1=138,τ2,1=174.24,则et2=312.24;执行步骤b4.2:在vatl1中从早到晚找出一个空闲时间段[0,m],满足m-0≥312.24和m-312.24≥0;执行步骤b4.3:计算t2的开始时间s2=0,完成时间f2=312.24;执行步骤b4.4:更新t2的子任务的就绪时间rt5=max{rt5,f2}=max{0,312.24}=312.24,rt10=312.24;执行步骤b4.5:在虚拟机可得时间段列表vatl1中删除[0,m],插入区间长度大于0的[312.24,m],则vatl1={[312.24,m]};执行步骤b4.6:在p(t5)、p(t10)中删除t2,则p(t5)={t1}、p(t10)={t8},在rt中删除t2,则rt={t1};执行步骤b4.7:由于ut中不存在的任务,则rt,ut均不变;执行步骤b5:由于rt={t1}不为空,转到步骤b2;……这样不断重复执行步骤b2至步骤b5,直至rt为空,确定所有的基因值,转至步骤b6;执行步骤b6:获得个体ch2={4,1,3,4,6,5,4,6,5,2,4,4,6,4,6;3,2,1,4,6,5,7,8,11,10,9,12,13,14,15},及其所有任务执行时间为:et1=179.16,et2=312.24,et3=182.16,et4=51.96,et5=574.32,et6=454.72,et7=14.00,et8=4.56,et9=249.68,et10=447.36,et11=259.44,et12=537.68,et13=9.28,et14=1935.00,et15=44.20;所有任务完成时间:f1=179.16,f2=312.24,f3=182.16,f4=231.12,f5=886.56,f6=636.88,f7=900.56,f8=905.12,f9=1154.80,f10=1352.48,f11=1164.56,f12=1890.16,f13=1899.44,f14=3834.44,f15=3878.64,计算其适应度值即工作流响应时间rs2:由于而sfl15={f15-1},故操作结束。同理,通过对初始概率模型进行采样生成种群中的其它个体如下:ch3={1,1,3,5,2,5,5,4,3,4,3,3,1,6,1;3,1,4,2,5,6,7,8,9,10,11,12,13,14,15};ch4={4,1,2,1,2,4,5,5,4,2,2,5,1,6,1;3,2,1,6,5,4,7,8,9,10,11,12,13,14,15};ch5={5,1,3,5,2,1,5,4,4,2,3,5,1,2,6;3,1,6,2,5,4,7,8,10,9,11,12,13,14,15};ch6={5,5,2,1,6,4,4,6,4,4,4,5,1,2,1;3,1,6,2,5,4,7,8,9,10,11,12,13,14,15};ch7={1,3,3,5,2,4,5,6,2,2,6,5,6,4,1;2,1,3,5,4,6,7,8,10,9,11,12,13,14,15};ch8={1,1,1,3,2,5,2,4,1,2,6,3,6,2,6;2,3,1,5,4,6,7,8,10,9,11,12,13,14,15};ch9={4,4,2,6,6,4,4,5,2,4,6,5,6,6,1;1,3,2,4,5,6,7,8,9,10,11,12,13,14,15};ch10={5,5,3,4,2,4,4,5,3,2,4,5,6,2,1;3,2,1,5,4,6,7,8,11,9,10,12,13,14,15};其适应度值即工作流响应时间分别为:rs3=5045.64,rs4=5489.00,rs5=6199.12,rs6=5461.24,rs7=4763.20,rs8=5976.56,rs9=2118.72,rs10=5217.48;这样最终生成的初始种群为{ch1,ch2,ch3,ch4,ch5,ch6,ch7,ch8,ch9,ch10},并令其为当代种群cp;当代种群cp={ch1,ch2,ch3,ch4,ch5,ch6,ch7,ch8,ch9,ch10}中最好的个体为ch1,把其保存到bestchrom中,则bestchrom={6,5,3,5,6,3,5,5,5,4,3,4,6,6,6;2,1,3,5,6,4,7,8,10,9,11,12,13,14,15},rsbestchrom=1174.64。执行步骤5:构建精英种群,更新概率模型;取精英率re=0.2,根据适应度值从优到劣选取2个个体:ch1={6,5,3,5,6,3,5,5,5,4,3,4,6,6,6;2,1,3,5,6,4,7,8,10,9,11,12,13,14,15}和ch9={4,4,2,6,6,4,4,5,2,4,6,5,6,6,1;1,3,2,4,5,6,7,8,9,10,11,12,13,14,15}作为当代精英种群,即pope={ch1,ch9};取虚拟机分配概率模型的更新速率θ1=0.2;虚拟机分配概率模型更新的具体实施过程如下:在当代精英种群pope中,t1一次也没有被分配给vm1、vm2、vm3、vm5,而分配给vm4、vm6的则各有一次,即则根据公式(16)有:α1,5(2)=0.20,α1,6(2)=0.30;同理,可以得到其它ti的αi,j(2),i=2,…,15,j=1,…,6,最终得到更新后的虚拟机分配概率模型为:取任务调度顺序概率模型的更新速率θ2=0.2;任务调度顺序概率模型更新的具体实施过程如下:在当代精英种群pope中,第一个调度的任务是t2和t1的各有1次,因此有则根据公式(17)有:……β15,1(2)=0.00;同理,可以得到其它第i′个调度位置的βi,i′(2),i′=2,…,15,i=1,…,15,最终得到更新后的任务调度顺序概率模型为:执行步骤6:采样概率模型生成新种群,令新种群为当代种群;对当前概率模型pmvm(2)和pms(2)进行10次采样生成10个个体如下:ch′1={6,1,2,1,6,1,4,5,1,4,2,5,6,6,1;1,2,3,4,5,6,7,8,10,11,9,12,13,14,15};ch′2={4,1,5,6,6,3,5,6,2,4,4,4,1,5,1;3,1,2,6,5,4,7,8,9,10,11,12,13,14,15};ch′3={5,4,2,4,1,1,4,5,2,4,6,4,6,6,6;3,1,4,2,5,6,7,8,10,11,9,12,13,14,15};ch′4={5,5,1,3,2,4,2,6,1,2,3,4,6,6,1;1,2,5,4,3,6,7,8,10,11,9,12,13,14,15};ch′5={1,1,2,4,2,3,5,5,2,2,3,4,6,6,1;1,2,5,4,3,6,7,8,9,11,10,12,13,14,15};ch′6={4,5,5,3,6,1,5,6,2,2,3,5,6,6,1;1,2,3,6,4,5,7,8,10,9,11,12,13,14,15};ch′7={1,3,3,4,6,5,4,4,1,2,3,5,6,4,6;1,4,3,2,6,5,7,8,9,11,10,12,13,14,15};ch′8={5,5,1,6,6,4,5,5,5,2,6,5,6,4,6;3,2,1,4,5,6,7,8,11,10,9,12,13,14,15};ch′9={4,1,3,3,6,4,2,5,5,2,6,5,6,2,1;3,1,2,5,4,6,7,8,9,10,11,12,13,14,15};ch′10={4,1,3,5,1,4,5,5,3,4,2,3,6,5,1;2,3,1,4,5,6,7,8,10,9,11,12,13,14,15};形成了新种群np={ch′1,ch′2,ch′3,ch′4,ch′5,ch′6,ch′7,ch′8,ch′9,ch′10};令新种群为当代种群,即cp=np。执行步骤7:当代种群改进与最优个体保存;首先,采用fbi&d对当代种群中的所有个体进行改进;通过采样概率模型已获得了个体的所有任务执行时间、任务完成时间,及其适应度值即工作流响应时间,例如对于通过采样概率模型获得的当代种群中的个体ch3={5,4,2,4,1,1,4,5,2,4,6,4,6,6,6;3,1,4,2,5,6,7,8,10,11,9,12,13,14,15},其所有任务执行时间为:et1=129.12,et2=185.16,et3=306.24,et4=263.16,et5=752.64,et6=739.44,et7=20.24,et8=4.56,et9=431.76,et10=60.64,et11=343.68,et12=496.08,et13=9.28,et14=10.00,et15=2.60;所有任务完成时间:f1=129.12,f2=577.44,f3=306.24,f4=392.28,f5=1330.08,f6=2069.52,f7=2089.76,f8=2094.32,f9=2526.08,f10=2154.96,f11=2438.00,f12=3022.16,f13=3031.44,f14=3041.44,f15=3044.04,及其工作流响应时间rs3=3052.44,因此对ch3={5,4,2,4,1,1,4,5,2,4,6,4,6,6,6;3,1,4,2,5,6,7,8,10,11,9,12,13,14,15}采用fbi&d改进的具体实施过程如下:执行步骤c1:把个体ch3中的任务调度顺序列表根据任务完成时间fi从大到小重新排列,即把ch3中的基因gi+i设置为倒数第i个完成的任务,i=1,…,15,形成反向个体执行步骤c2:对采用基于插入模式的串行反向个体解码方法进行解码获得所有任务反向完成时间:及其反向工作流响应时间由于小于rs3=3052.44,则转到步骤c3;执行步骤c3:把反向个体中的任务调度顺序列表根据任务反向完成时间从大到小重新排列,即把中的基因gi+i设置为倒数第i个完成的任务,i=1,…,15,形成个体ch3={5,4,2,4,1,1,4,5,2,4,6,4,6,6,6;2,1,5,3,6,4,7,8,9,11,10,12,13,14,15};执行步骤c4:采用基于插入模式的串行个体解码方法对个体ch3进行解码,获得所有任务的完成时间:f1=129.12,f2=185.16,f3=306.24,f4=448.32,f5=937.80,f6=1677.24,f7=1697.48,f8=1702.04,f9=2133.80,f10=1762.68,f11=2045.72,f12=2629.88,f13=2639.16,f14=2649.16,f15=2651.76,及其工作流响应时间rs3=2660.16;由于rs3=2660.16等于则转到步骤c5;执行步骤c5:输出个体ch3={5,4,2,4,1,1,4,5,2,4,6,4,6,6,6;2,1,5,3,6,4,7,8,9,11,10,12,13,14,15},及其适应度值即工作流响应时间rs3=2660.16,操作结束;以上述个体为例,基于插入模式的串行反向个体解码方法的具体实施过程如下:执行步骤e1:由于而sfl15={f15-1},故令任务的反向就绪时间:令ε=1;令虚拟机可得时间段列表:vatl1={[0,m]},vatl2={[0,m]},……,vatl6={[0,m]},其中m为一个接近无穷大的数;执行步骤e2:选取编号为i=gi+1=g16的任务,其为任务15;执行步骤e3:基于插入模式把任务15分配给虚拟机j=g15=6;即执行步骤e3.1:在vatl6中从早到晚找出一个空闲时段[0,m],满足m-0≥et15=2.60和执行步骤e3.2:计算任务15的反向开始时间反向完成时间更新任务15的父任务的就绪时间执行步骤e3.3:在虚拟机可得时间段列表vatl6中删除[0,m],插入区间长度大于0的[0,8.40]和[11.00,m],则vatl6={[0,8.40],[11.00,m]};执行步骤e4:ε=1+1=2,由于ε=2≤i=15,则转到步骤e2;执行步骤e2:选取编号为i=gi+2=g17的任务,其为任务14;执行步骤e3:基于插入模式把任务14分配给虚拟机j=g14=6;即执行步骤e3.1:在vatl6中从早到晚找出一个空闲时段[11.00,m],满足m-11.00≥et14=10.00和执行步骤e3.2:计算任务14的反向开始时间反向完成时间更新任务14的父任务的就绪时间执行步骤e3.3:在虚拟机可得时间段列表vatl6中删除[11.00,m],插入区间长度大于0的[21.00,m],则vatl6={[0,8.40],[21.00,m]};执行步骤e4:ε=2+1=3,由于ε=3≤i=15,则转到步骤e2;……这样不断重复执行步骤e2至步骤e4,直到ε=16>i=15为空,转到步骤e5;执行步骤e5:获得所有任务的反向完成时间:计算反向工作流响应时间操作结束。以上述对个体ch3={5,4,2,4,1,1,4,5,2,4,6,4,6,6,6;3,1,4,2,5,6,7,8,10,11,9,12,13,14,15}进行解码为例,其中基于插入模式的串行个体解码的具体实施过程如下:执行步骤f1:令所有任务的就绪时间:rt1=0,rt2=0,…,rt15=0,令虚拟机可得时间段列表:vatl1={[0,m]},vatl2={[0,m]},…,vatl6={[0,m]},m为一个接近无穷大的数;令ε=1;执行步骤f2:选取编号为g15+1=g16的任务,其为任务3;执行步骤f3:基于插入模式把任务3分配给虚拟机g3=2;即执行步骤f3.1:在vatl2中从早到晚找出一个空闲时间段[0,m],满足m-0≥et3=306.24和m-306.24≥rt3=0;执行步骤f3.2:计算任务3的开始时间s3=max{v2,rt3}=max{0,0}=0,完成时间f3=s3+et3=0+306.24=306.24,更新任务3的子任务的就绪时间:rt6=max{rt6,f3}=max{0,306.24}=306.24,rt11=max{rt11,f3}=max{0,306.24}=306.24;执行步骤f3.3:在虚拟机可得时间段列表vatl2中删除[0,m],插入区间长度大于0的[306.24,m],则vatl2={[306.24,m]};执行步骤f4:ε=1+1=2,由于ε=2≤i=15,故转至步骤f2;执行步骤f2:选取编号为g17的任务,其为任务1;执行步骤f3:基于插入模式把任务1分配给虚拟机g1=5;即执行步骤f3.1:在vatl5中从早到晚找出一个空闲时间段[0,m],满足m-0≥129.12和m-129.12≥0;执行步骤f3.2:计算任务1的开始时间s1=max{0,0}=0,完成时间f1=0+129.12=129.12,更新任务1的子任务的就绪时间:rt4=max{rt4,f1}=max{0,129.12}=129.12,rt5=129.12,rt6=max{306.24,129.12}=306.24,rt9=129.12;执行步骤f3.3:在虚拟机可得时间段列表vatl5中删除[0,m],插入区间长度大于0的[129.12,m],vatl5={[129.12,m]};执行步骤f4:ε=2+1=3,由于ε=3≤i=15,故转至步骤f2;执行步骤f2:选取编号为g18的任务,其为任务4;执行步骤f3:基于插入模式把任务4分配给虚拟机g4=4;即执行步骤f3.1:在vatl4中从早到晚找出一个空闲时间段[0,m],满足m-0≥263.16和m-263.16≥129.12;执行步骤f3.2:计算任务4的开始时间s4=max{0,129.12}=129.12,完成时间f4=129.12+263.16=392.28,更新任务4的子任务的就绪时间rt7=max{0,392.28}=392.28;执行步骤f3.3:在虚拟机可得时间段列表vatl4中删除[0,m],插入区间长度大于0的[0,129.12]和[392.28,m],vatl4={[0,129.12],[392.28,m]};执行步骤f4:ε=3+1=4,由于ε=4≤i=15,故转至步骤f2;……这样不断重复执行步骤f2至步骤f4,直到ε=16>i=15,获得所有任务的开始时间si和完成时间fi,转至步骤f5;执行步骤f5:获得所有任务的完成时间:f1=129.12,f2=577.44,f3=306.24,f4=392.28,f5=1330.08,f6=2069.52,f7=2089.76,f8=2094.32,f9=2526.08,f10=2154.96,f11=2438.00,f12=3022.16,f13=3031.44,f14=3041.44,f15=3044.04;计算其适应度值即工作流响应时间rs3:由于而sfl15={f15-1},故操作结束。同理,种群中的其它个体经fbi&d改进后变为:ch1={6,1,2,1,6,1,4,5,1,4,2,5,6,6,1;1,2,3,4,5,6,7,8,10,11,9,12,13,14,15};ch2={4,1,5,6,6,3,5,6,2,4,4,4,1,5,1;3,1,2,6,5,4,7,8,9,10,11,12,13,14,15};ch4={5,5,1,3,2,4,2,6,1,2,3,4,6,6,1;1,2,5,4,3,6,7,8,10,11,9,12,13,14,15};ch5={1,1,2,4,2,3,5,5,2,2,3,4,6,6,1;1,2,5,4,3,6,7,8,9,11,10,12,13,14,15};ch6={4,5,5,3,6,1,5,6,2,2,3,5,6,6,1;1,3,6,2,5,4,7,8,10,9,11,12,13,14,15};ch7={1,3,3,4,6,5,4,4,1,2,3,5,6,4,6;1,4,3,2,6,5,7,8,9,11,10,12,13,14,15};ch8={5,5,1,6,6,4,5,5,5,2,6,5,6,4,6;3,2,1,4,5,6,7,8,11,10,9,12,13,14,15};ch9={4,1,3,3,6,4,2,5,5,2,6,5,6,2,1;3,1,2,5,4,6,7,8,9,10,11,12,13,14,15};ch10={4,1,3,5,1,4,5,5,3,4,2,3,6,5,1;2,3,1,4,5,6,7,8,10,9,11,12,13,14,15};其适应度值即工作流响应时间分别为:rs1=2862.12,rs2=5100.52,rs4=2432.36,rs4=5024.20,rs5=3212.84,rs6=2761.20,rs7=4229.28,rs8=3839.96,rs9=4873.24,rs10=3252.20;然后,采用ldi方法对当代种群中的所有个体进行改进;例如对种群中的第10个个体ch10={4,1,3,5,1,4,5,5,3,4,2,3,6,5,1;2,3,1,4,5,6,7,8,10,9,11,12,13,14,15}采用ldi改进的具体实施过程如下:执行步骤d1:计算各虚拟机的负载,同理可求得其它虚拟机的负载ld2=108,ld3=131.4,ld4=180,ld5=46.8,ld6=6;执行步骤d2:找出负载最小的虚拟机,其为vm6,j′=6,由于ld6=6>0,故转到步骤d3;执行步骤d3:令转到步骤d5;执行步骤d5:st6={t14}不为空,则按顺序从st6中找出一个其所在虚拟机负载是最高的任务,其为t14,i′=14,转到步骤d6;执行步骤d6:g14=6,形成新个体用fbi&d方法对新个体进行改进,新个体变为其工作流响应时间相对于原方案3252.20有改进,则用此改进的个体替换原个体,转到步骤d7;执行步骤d7:ldi操作结束;同理,种群中的其它个体经ldi改进后变为:ch1={6,3,2,1,6,1,4,5,1,4,2,5,6,6,1;1,2,3,4,5,6,7,8,10,11,9,12,13,14,15};ch2={4,1,5,5,6,3,5,6,2,4,4,4,1,5,1;3,1,2,6,5,4,7,8,9,10,11,12,13,14,15};ch3={5,4,2,4,1,1,4,5,3,4,6,4,6,6,6;2,1,5,3,6,4,7,8,9,11,10,12,13,14,15};ch4={5,5,1,3,2,4,2,6,1,2,3,4,6,6,6;1,2,5,4,3,6,7,8,10,11,9,12,13,14,15};ch5={1,1,2,4,2,3,5,5,5,2,3,4,6,6,1;1,2,5,4,3,6,7,8,9,11,10,12,13,14,15};ch6={4,5,5,3,6,1,5,6,2,2,3,5,6,6,6;1,3,6,2,5,4,7,8,10,9,11,12,13,14,15};ch7={5,3,3,4,6,5,4,4,1,2,3,5,6,4,6;1,4,3,2,6,5,7,8,9,11,10,12,13,14,15};ch8={5,5,3,6,6,4,5,5,5,2,6,5,6,4,6;1,3,4,2,6,5,7,8,10,11,9,12,13,14,15};ch9={4,1,3,3,6,4,5,5,5,2,6,5,6,2,1;3,1,2,5,4,6,7,8,9,10,11,12,13,14,15};其适应度值即工作流响应时间分别为:rs1=2679.00,rs2=4846.92,rs3=2476.08,rs4=2356.36,rs5=2685.08,rs6=2685.20,rs7=4070.88,rs8=3637.92,rs9=4855.88;由于改进后的种群中的最优个体并不优于bestchrom中保存的个体,因此无需更新保存在bestchrom中的个体。执行步骤8:判断是否满足终止条件,如果不满足,转到步骤5;否则输出bestchrom中保存的个体,其对应的调度方案作为优化方案;终止条件设为连续迭代20代最优个体没有改进;由于当前迭代进化了两代,不满足终止条件,因此转到步骤5。……这样不断重复执行步骤5至步骤8,直至bestchrom连续迭代20代都没有改进,当代种群变为:ch1={6,4,5,5,6,5,4,6,3,4,4,4,6,6,6;2,3,1,5,4,6,7,8,10,9,11,12,13,14,15};ch2={6,4,3,6,6,3,4,6,3,4,4,4,6,6,1;2,3,1,5,6,4,7,8,9,11,10,12,13,14,15};ch3={6,4,2,5,6,3,4,4,3,4,4,4,6,6,6;2,3,1,4,6,5,7,8,10,9,11,12,13,14,15};ch4={6,4,3,6,6,5,4,4,3,4,4,4,6,6,1;2,3,1,5,6,4,7,8,10,9,11,12,13,14,15};ch5={6,4,3,6,6,3,4,6,3,4,4,4,6,6,1;2,3,1,4,6,5,7,8,10,9,11,12,13,14,15};ch6={6,4,3,6,6,3,4,6,3,4,4,4,6,6,6;2,3,1,5,6,4,7,8,10,11,9,12,13,14,15};ch7={6,4,5,6,6,3,4,4,3,4,4,4,6,6,6;2,3,1,5,6,4,7,8,10,9,11,12,13,14,15};ch8={6,4,3,6,6,5,4,6,3,4,4,4,6,6,6;2,3,1,5,4,6,7,8,10,11,9,12,13,14,15};ch9={6,4,5,5,6,5,4,6,3,4,4,4,6,6,6;2,3,1,5,6,4,7,8,10,11,9,12,13,14,15};ch10={6,4,5,6,6,5,4,6,3,4,4,4,6,6,1;2,3,1,5,4,6,7,8,10,9,11,12,13,14,15};其适应度值即工作流响应时间分别为:rs1=1102.20,rs2=1108.16,rs3=1564.28,rs4=1239.36,rs5=1108.16,rs6=1032.16,rs7=1184.36,rs8=1164.92,rs9=1102.20,rs10=1096.32;bestchrom={6,4,3,6,6,3,4,6,3,4,4,4,6,6,6;2,3,1,5,6,4,7,8,10,11,9,12,13,14,15},rsbestchrom=1032.16,其对应的调度方案如表8所示。表8上述实施例只是本发明的较佳实施例,并不是对本发明技术方案的限制,只要是不经过创造性劳动即可在上述实施例的基础上实现的技术方案,均应视为落入本发明专利的权利保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1