一种基于MaskRCNN的医学图像中脊柱自动定位方法与流程
本发明涉及脊柱自动定位技术,尤其是一种基于于maskrcnn的医学图像中脊柱自动定位方法。
背景技术:
近些年ct系统凭借着优秀的图像质量,快速的成像速度,在医学领域有着越来越广泛的应用。ct系统利用精确准直的x射线与灵敏度极高的探测器接收透过人体的信号,扫描采集的数据经过图像重建算法形成断层图像。ct图像在临床上有着广泛的应用,近年来随着多层螺旋ct技术的发展,探测器的排数已经从开始的4排,64排,一直到现在的256排ct。这随之而来带来了海量的数据需要医生来解读,所以计算机辅助分析的工作就变得非常重要。比如在ct对脊柱的扫描中,通常会扫描一个脊柱的定位像,然后一般医生会手动框选每个脊柱的位置和方向,以便于ct系统对各个脊柱沿着脊柱的方向进行扫描。再比如,在脊柱整形外科中,通常需要医生辨别每个脊柱的位置,并按照每个脊柱的空间方向重新生成断层图像,进而诊断病人的脊柱的健康状况,在这个过程中通常需要人工来判读比如弯曲程度和弯曲方向等等信息。
目前的大多数系统中都是基于医生的人工阅片,手动判别每个椎体的范围,位置,和方向。由于人体一共有,33块椎骨,如果全部采用人工标注,会严重影响阅片效率,阅片医生的工作强度大,而且会由于主观的误差存在标记不一致的问题。而且人工阅片通常是通过不同方向的二维视图,很难准确全面的判别三维的空间角度。
虽然目前也有自动分割椎骨的方法,但是这些方法也仅仅是分割整个椎体的区域,还不能直接给出脊柱的和椎体的空间位置关系,最后椎体的方向和位置还需要人工来判读。比如专利201711299213.9提出一种脊柱x线影像的数据处理方法,该方法是针对多个方向的x线的平片图像进行脊柱的识别,无法实现对三维ct扫描图像的自动识别。申请201711315308.5提出一种基于主动轮廓模型的脊柱ct图像自动定位分割方法,该方法能够自动定位椎骨中心和分割初始轮廓位置,进而可以对椎骨进行自动分割,但不能提供每个脊柱的位置和方向等空间位置信息。
技术实现要素:
发明目的:为弥补现有技术的空白,本发明提出一种基于于maskrcnn的医学图像中脊柱自动定位方法,可以实现脊柱自动定位并识别每个椎体的包络框的像素坐标、椎体的中心和倾角。
技术方案:为实现上述目的,本发明提出一种基于maskrcnn的医学图像中脊柱自动定位方法,包括步骤:
(1)构建训练样本:选取脊柱椎体矢状面ct图像,为各个图像添加椎体的包络框的像素坐标、倾角、mask分类信息,得到训练样本;
(2)利用maskrcnn网络作为脊柱自动定位模型,并在fasterrcnn的最后一层增加一个用于提取倾角的卷积输出支路,即构建好的脊柱自动定位模具有三个卷积输出支路,第一个支路输出候选区域的相关参数,第二个支路输出候选区域为目标的概率值,第三个支路输出候选区域中的倾角值;
(3)利用训练样本训练脊柱自动定位模型;
(4)将新获取的脊柱椎体矢状面ct图像输入训练好的脊柱自动定位模型,得到得到椎体包络框的像素坐标和椎体的倾角。
具体的,训练好的脊柱自动定位模型包括特征提取网络、mask分支网络、区域生成网络rpn和目标检测器fast-rcnn;其中,
特征提取网络提取原始图像的卷积特征图;
mask分支网络对输入的原始图像进行骨骼粗提取,得到骨骼mask图;
卷积特征图和骨骼mask图经过一个1×1的卷积核进行卷积后,生成新的卷积特征图;
新的卷积特征图送入区域生成网络,区域生成网络生成椎体包络框候选区域;
目标检测器fast-rcnn中的roi池化层对椎体包络框候选区域和新的卷积特征图进行roi池化,得到相同大小的特征图和各个特征图的特征信息,然后将特征信息输入到三个输出全连接层进行回归、分类和倾角提取,得到椎体包络框的像素坐标和倾角。
具体的,所述maskrcnn网络的损失函数为:
lfastrcnn(imgin)=lconf+lloc
lang(angn)=(angj(n)-angpredn)2
其中,imgin表示输入图像,lfastrcnn(imgin)为输入图像imgin的定位框误差,n为网络预设的预测定位框的总数,j(n)表示某一预测定位框n所对应的真正的椎体定位框的索引,β为权重系数,lang(angn)表示第n个椎体的实际角度与预测角度之间的角度差异,式中,angj(n)表示第n个椎体的实际角度,angpredn表示第n个椎体的预测角度;
lconf为定位框的类别误差损失函数,表达式为:
lloc为定位框的坐标损失函数,表达式为:
其中,lconf(x,c)表示定位框x为真正的椎体定位框j的损失,cn,j表示softmax层的输入,
有益效果:与现有技术相比,本发明具有以下优势:
本发明通过构建一个maskrcnn神经网络,自动识别出每个椎体的包围框和空间方位角等信息,为医生的诊断提供辅助分析。由于是自动分析识别,整个过程几乎不需要医生过多干预,能够大幅度提高医生诊断的工作效率。
附图说明
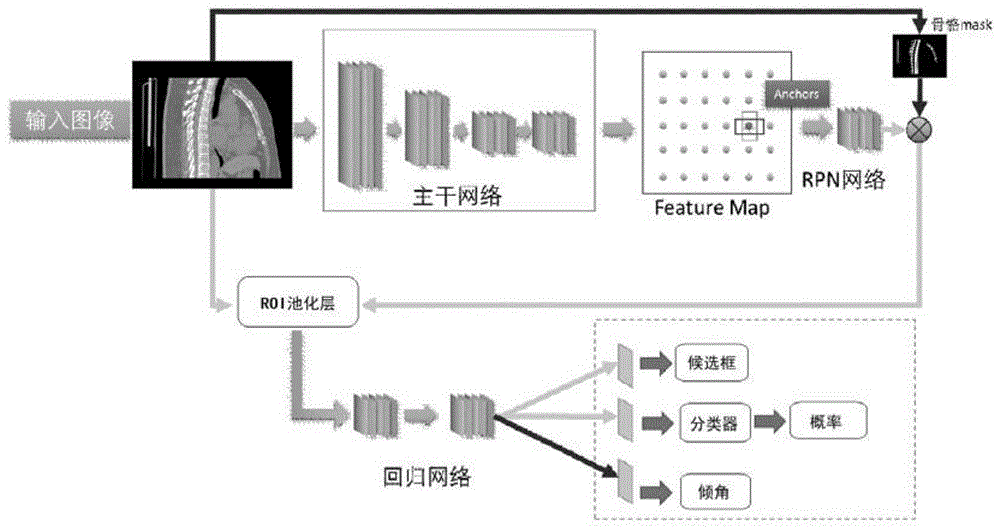
图1所示为本发明构建的脊柱自动定位模型图;
图2为本发明涉及的新的卷积特征图生成原理的示例性框图;
图3为训练好的脊柱自动定位模型的输入图像、输出图像对比图。
具体实施方式
下面结合附图和具体实施例对本发明作更进一步的说明。
本发明提出了一种基于maskrcnn的医学图像中脊柱自动定位方法,包括步骤:
(1)构建训练样本:选取脊柱椎体矢状面ct图像,为各个图像添加椎体的包络框的像素坐标、倾角、mask分类信息,得到训练样本;
(2)利用maskrcnn网络作为脊柱自动定位模型,并在fasterrcnn的最后一层增加一个用于提取倾角的卷积输出支路,即构建好的脊柱自动定位模具有三个卷积输出支路,第一个支路输出候选区域的相关参数,第二个支路输出候选区域为目标的概率值,第三个支路输出候选区域中的倾角值;
(3)利用训练样本训练脊柱自动定位模型;
(4)将新获取的脊柱椎体矢状面ct图像输入训练好的脊柱自动定位模型,得到得到椎体包络框的像素坐标和椎体的倾角。
如图1示出了根据本发明的基于maskrcnn的医学图像中脊柱自动定位方法的实施例所涉及的maskrcnn神经网络示意性框图,构建好的maskrcnn神经网络如图1所示,包括特征提取网络、mask分支网络、区域生成网络rpn和目标检测器fast-rcnn。
原始的fasterrcnn主要包括三个网络:主干网络,rpn网络(区域推荐网络)和回归网络。
主干网络完成对图像特征的提取,并降低图像的维度,通常都是由卷积层+relu激活层+卷积层+relu激活层+池化层组成一个模块。然后由几组这样的模块级联而成。主干网络把输入的图像变成卷积特征图featuremap。
featuremap输入给rpn网络(通常由几组卷积层+relu层),featuremap提取区域需要通过每个anchor点,并对每个anchor点附近的信息进行提取,通过这些信息提取出候选的物体区域(~6k个候选区域)。
这些候选区域的特性经过roip池化层提取相应的特征矩阵,送到后面的回归网络(卷积层,relu激活层,softmax层),输出特征(包括定位框,和物体的类别)。
但是,原始的fasterrcnn网络,并不是专门为椎体检测开发的。医学图像的分辨率(1024像素左右)要比普通视觉图像(400像素左右)的分辨率高得多,数据量显著提高,每个像素的颜色深度也从rgb图像的8位变成了医学图像的16位甚至32位。而且没有办法进行椎体的角度检测。此外,rpn网络的候选区域会有很大的假阳性,严重影响执行效率和准确率。因此这里对这些不足进行了如下改进。
而由于本发明所要解决的技术问题的特殊性,本方案改进了rpn网络结构,加入了骨组织区域的mask来提高rpn定位框的假阳性,只在有骨骼区域mask有效区域的rpn才有激活输出,这样可以大幅的减少处理区域降低假阳性率,可以有效的提高rpn的效率(可以减低到2百左右)。
同时为了输出倾角并在fasterrcnn的最后一层增加一个用于提取倾角的卷积输出支路,即构建好的脊柱自动定位模具有三个卷积输出支路,第一个支路输出候选区域的相关参数,第二个支路输出候选区域为目标的概率值,第三个支路输出候选区域中的倾角值。
在本实施例构建的maskrcnn神经网络中,特征提取网络提取原始图像的卷积特征图;mask分支网络对输入的原始图像进行骨骼粗提取,得到骨骼mask图;如图2所示,卷积特征图和骨骼mask图经过一个1×1的卷积核进行卷积后,生成新的卷积特征图;新的卷积特征图送入区域生成网络,区域生成网络生成椎体包络框候选区域;目标检测器fast-rcnn中的roi池化层对椎体包络框候选区域和新的卷积特征图进行roi池化,得到相同大小的特征图和各个特征图的特征信息,然后将特征信息输入到三个输出全连接层进行回归、分类和倾角提取,得到椎体包络框的像素坐标和倾角。
构建好的maskrcnn神经网络需要利用训练样本进行训练,这个训练过程主要包括区域生成网络和目标检测器fast-rcnn的训练,具体过程为:
1)将样本图像输入到rpn网络,利用随机梯度下降法,分别计算rpn网络中每一层代价函数的梯度值,然后用每一层代价函数的梯度值更新该层的权值;
2)通过反向传播,计算rpn网络中每一层的误差灵敏度,然后用每一层的误差灵敏度更细该层的权值;
3)重复执行步骤1)至2),直至rpn网络中各层的权值不变;转入步骤4);
4)将样本图像和rpn网络的anchorboxes输入到fastrcnn网络中,通过roi池化层映射出候选框的特征图,再通过全连接层对cnn层提取出的特征做非线性变换,最后通过损失函数进行联合训练;
所述maskrcnn模型的损失函数为:
lfastrcnn(imgin)=lconf+lloc
lang(angn)=(angj(n)-angpredn)2
其中,imgin表示输入图像,lfastrcnn(imgin)为输入图像imgin的定位框误差,n为网络预设的预测定位框的总数,j(n)表示某一预测定位框n所对应的真正的椎体定位框的索引,β为权重系数,lang(angn)表示第n个椎体的实际角度与预测角度之间的角度差异,式中,angj(n)表示第n个椎体的实际角度,angpredn表示第n个椎体的预测角度;
lconf为定位框的类别误差损失函数,表达式为:
lloc为定位框的坐标损失函数,表达式为:
其中,lconf(x,c)表示定位框x为真正的椎体定位框j的损失,cn,j表示softmax层的输入,
将新的脊柱椎体矢状面ct图像输入训练好的脊柱自动定位模型,即可得到椎体包络框的像素坐标和倾角,如图3所示。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!