一种具有自适应选择训练过程的图像显著目标检测方法与流程
本发明涉及数据处理技术领域,特别涉及一种具有可解释性的直推学习方法及系统。
背景技术:
图像显著目标检测模拟了人类视觉系统检测场景中最引人注目的物体的能力,它是图像处理的预处理部分,近年来取得了很大的研究进展。但是现有的数据集大多包含一个或多个简单的显著目标,这不能充分反映真实世界中图像的复杂性。真实场景图像中有时候并不包含显著物体,例如,天空、草地、纹理、高密度人群等。因此,现有的图像显著目标检测模型在现有的数据集上性能已趋于成熟,但在真实场景中不能达到满意的性能。
因此亟需提供一种图像显著目标检测模型,用于在真实场景中检测显著目标,既要考虑图像中包含显著物体的情况,也要考虑图像中不含有显著物体的情况。
技术实现要素:
本发明的目的在于克服现有技术存在的缺陷,提供一种具有自适应选择训练过程的图像显著目标检测方法,能够准确地对所有图像进行检测。
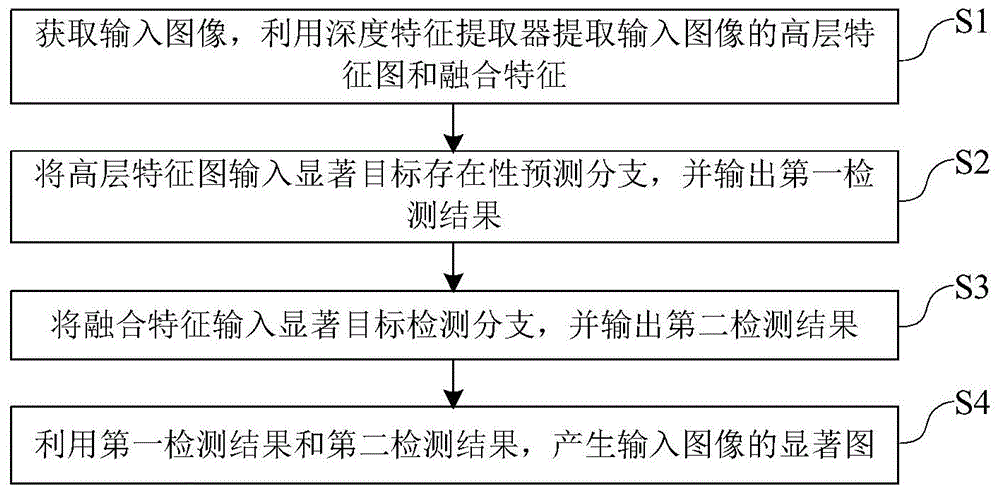
为实现以上目的,本发明采用一种具有自适应选择训练过程的图像显著目标检测方法,包括如下步骤:
获取输入图像,利用深度特征提取器提取输入图像的高层特征图和融合特征;
将高层特征图输入显著目标存在性预测分支,并输出第一检测结果;
将融合特征输入显著目标检测分支,并输出第二检测结果;
利用第一检测结果和第二检测结果,产生输入图像的显著图。
进一步地,所述利用深度特征提取器提取输入图像的高层特征图和融合特征,包括:
将所述输入图像至深度特征提取器m中,提取其高层语义特征和融合特征,其中,深度特征提取器m采用resnet101作为主体网络,高层接aspp模块,侧边连接四个上下文特征聚合模块cfam。
进一步地,所述将所述输入图像至深度特征提取器m中,提取其高层特征图和融合特征,包括:
对于所述输入图像,利用所述resnet101侧边输出四种不同分辨率的高层特征图fm(m=1,2,3,4);
利用所述aspp模块输出特征图faspp经过卷积操作产生特征图
利用所述上下文特征聚合模块cfam融合特征图faspp、高一层cfam模块输出的特征图
利用特征图
进一步地,所述利用特征图
对所述特征图
其中,
进一步地,所述将高层语义特征输入显著目标存在性预测分支,并输出第一检测结果,包括:
采用全局平均池化对所述高层特征图进行加速降维,生成1*1*2048全局特征,然后重新排列特征;
将重新排列的特征的输入自定义为两个全连接层fc5、fc6,并生成显著性存在预测结果作为所述第一检测结果。
进一步地,所述第二检测结果包括融合显著目标存在性预测结果的显著目标检测结果和不融合显著目标存在性预测结果的显著目标检测结果;所述将融合特征输入显著目标检测分支,并输出第二检测结果,包括:
将所述融合特征送入显著目标检测分支,进行融合显著目标存在性预测结果的显著目标检测,输出融合显著目标存在性预测结果的显著目标检测结果;
将所述融合特征送入显著目标检测分支,进行不融合显著目标存在性预测结果的显著目标检测,输出不融合显著目标存在性预测结果的显著目标检测结果。
进一步地,所述将所述融合特征送入显著目标检测分支,进行融合显著目标存在性预测结果的显著目标检测,输出融合显著目标存在性预测结果的显著目标检测结果,包括:
将所述融合特征与所述全连接层fc5的输出特征fsep进行融合,形成所述融合显著目标存在性预测结果的显著目标检测结果。
进一步地,所述将所述融合特征送入显著目标检测分支,进行不融合显著目标存在性预测结果的显著目标检测,输出不融合显著目标存在性预测结果的显著目标检测结果,包括:
对所述融合特征执行两个具有3*3和1*1核大小的卷积运算以及sigmoid函数,形成所述不融合显著目标存在性预测结果的显著目标检测结果。
进一步地,所述利用第一检测结果和第二检测结果,产生输入图像的显著图,包括:
根据所述显著性存在预测结果与显著目标存在性真实标签之间的损失函数lossexistence;
计算融合显著目标存在性预测结果的显著目标检测结果与显著目标真实值之间的损失函数losssaliency;
根据不融合显著目标存在性预测结果的显著目标检测结果,计算所选图像的显著目标检测结果
计算最终的损失函数lossfinal=α*losssaliency+β*lossexistence+γ*lossselect,并利用最终的损失函数对图像显著目标检测模型进行监督和约束,识别出所述输入图像的显著图。
进一步地,所述损失函数
所述损失函数
所述损失函数
与现有技术相比,本发明存在以下技术效果:本发明中具有自适应选择训练过程的图像显著目标检测模型由输入图像提取高层特征和融合特征,高层特征送入显著目标存在性预测分支进行预测,融合特征送入显著目标检测分支进行检测,并结合显著目标存在性预测分支的结果产生显著图。显著目标存在性预测和显著目标检测双任务学习建立模型,在此基础上,模型选择包含显著目标的图像,根据其产生的未融合显著目标存在性预测特征的显著目标检测结果及真值之间的损失函数的监督和约束,加强模型对包含显著目标图像及不包含显著目标图像的检测能力。其图像显著目标检测方法根据图像的显著目标真实存在性标签,选择包含显著目标的图像进行增强学习,使其适用于检测包含显著目标以及不包含显著目标的所有图像。
附图说明
下面结合附图,对本发明的具体实施方式进行详细描述:
图1是一种具有自适应选择训练过程的图像显著目标检测方法的流程示意图;
图2是模型框架示意图。
图3是上下文特征聚合模块示意图。
图4是本发明方法与现有方法的对比结果示意图。
具体实施方式
为了更进一步说明本发明的特征,请参阅以下有关本发明的详细说明与附图。所附图仅供参考与说明之用,并非用来对本发明的保护范围加以限制。
如图1-图2所示,本实施例公开了一种具有自适应选择训练过程的图像显著目标检测方法,包括如下步骤s1至s4:
s1、获取输入图像,利用深度特征提取器提取输入图像的高层特征图f4和融合特征f;
s2、将高层特征图f4输入显著目标存在性预测分支,并输出第一检测结果;
s3、将融合特征f输入显著目标检测分支,并输出第二检测结果;
s4、利用第一检测结果和第二检测结果,产生输入图像的显著图。
需要说明的是,本实施例所述自适应选择训练过程是指,根据图像的显著目标存在性真实标签,选择包含显著目标的图像进行增强学习的过程,使其适用于检测包含显著目标以及不包含显著目标的所有图像。
进一步地,上述步骤s1中,利用深度特征提取器提取输入图像的高层特征图f4和融合特征f,具体为:
将所述输入图像至深度特征提取器m中,提取其高层语义特征f4和融合特征f,其中,深度特征提取器m采用resnet101作为主体网络,高层接aspp模块,侧边连接四个上下文特征聚合模块cfam。
aspp模块来自于deeplabv3,以不同的膨胀速率从四个不同的空洞卷积层中级联特征,以及通过全局平均池化并行排列得到图像级特征,它使输出特征图中的神经元包含多个接收域大小,从而编码多尺度信息,最终提高性能。
进一步地,所述将所述输入图像至深度特征提取器m中,提取其高层特征图和融合特征,包括:
对于所述输入图像,利用所述resnet101侧边输出四种不同分辨率的高层特征图fm(m=1,2,3,4);
利用所述aspp模块输出特征图faspp经过卷积操作产生特征图
利用所述上下文特征聚合模块cfam融合特征图faspp、高一层cfam模块输出的特征图
利用特征图
这里需要说明的是,fm(m=1,2,3,4,5)表示resnet101生成的四种特征图,
具体来说,上下文特征聚合模块cfam,参见图3,融合特征图faspp、高一层cfam模块输出的特征图
所述上下文特征聚合模块cfam具体操作如下:首先对主体网络中的特征fm进行1*1的卷积运算,然后与经双线性上采样后的aspp模块的特征faspp连接。然后,使用3*3和1*1核的两个卷积来学习两个特征的融合,并保持64通道数。对较高的cfam输出特征
gm=cat(conv(fm,1),up(faspp))
其中,conv(.,x)表示x*x核大小的卷积运算,up(.)表示双上采样操作,cat(.)表示级联操作,*表示乘积,1*1的卷积运算即1×1的卷积运算。
进一步地,所述利用所述特征图
对所述特征图
其中,
进一步地,上述步骤s2:将高层语义特征输入显著目标存在性预测分支,并输出第一检测结果,包括如下细分步骤s21-s22:
s21、采用全局平均池化对所述高层特征图进行加速降维,生成1*1*2048全局特征,然后重新排列特征;
需要说明的是,采用全局平均池化对所述高层特征图f4进一步加速降维,生成1*1*2048全局特征,然后重新排列特征,得到重新排列的特征。
s22、将重新排列的特征的输入自定义为两个全连接层fc5、fc6,并生成显著性存在预测结果作为所述第一检测结果。
需要说明的是,全连接层fc5具有64个神经元,fc6具有1个神经,从而生成第一检测结果即显著性存在预测结果
fsep=τ(fc(reshape(gap(f4)),64))
其中,gap(.)表示全局平均池化操作,fc(.,n)表示具有n个神经元的全连接操作,reshape(.)表示重构操作,τ表示relu激活函数,sigmoid表示sigmoid激活函数。
进一步地,所述第二检测结果包括融合显著目标存在性预测结果的显著目标检测结果和不融合显著目标存在性预测结果的显著目标检测结果。上述步骤s3:将融合特征输入显著目标检测分支,并输出第二检测结果,具体包括如下步骤s31-s32:
s31、将所述融合特征送入显著目标检测分支,进行融合显著目标存在性预测结果的显著目标检测,输出融合显著目标存在性预测结果的显著目标检测结果;
s32、将所述融合特征送入显著目标检测分支,进行不融合显著目标存在性预测结果的显著目标检测,输出不融合显著目标存在性预测结果的显著目标检测结果。
具体来说,上述步骤s32:所述将所述融合特征送入显著目标检测分支,进行融合显著目标存在性预测结果的显著目标检测,输出融合显著目标存在性预测结果的显著目标检测结果,具体包括:
将所述融合特征与所述全连接层fc5的输出特征fsep进行融合,形成所述融合显著目标存在性预测结果的显著目标检测结果。
需要说明的是,本实施例中,将融合特征f与显著性存在预测分支的全连接层fc5的输出特征fsep进行融合,形成融合显著目标存在性预测结果的显著目标检测结果
其中,tile(.)函数表示复制操作,特征fsep和特征f的结合可以使来自非显著图像的显著图接近全黑真值图。
具体来说,上述步骤s32:将所述融合特征送入显著目标检测分支,进行不融合显著目标存在性预测结果的显著目标检测,输出不融合显著目标存在性预测结果的显著目标检测结果,具体包括:
对所述融合特征执行两个具有3*3和1*1核大小的卷积运算以及sigmoid函数,形成所述不融合显著目标存在性预测结果的显著目标检测结果。
需要说明的是,将来自深度特征提取器的特征f被执行两个具有3*3和1*1核大小的卷积运算以及sigmoid函数,形成不融合显著目标存在性预测结果的显著目标检测结果
其中,conv(conv(f,3),1)表示将来自深度特征提取器m的融合特征f先执行3*3的卷积操作再执行1*1的卷积操作,再经过sigmoid函数形成显著图
进一步地,上述步骤s4:利用第一检测结果和第二检测结果,产生输入图像的显著图,包括如下步骤s41至s44:
s41、根据所述显著性存在预测结果与显著目标存在性真实标签之间的损失函数lossexistence;
s42、计算融合显著目标存在性预测结果的显著目标检测结果与显著目标真实值之间的损失函数losssaliency;
s43、根据不融合显著目标存在性预测结果的显著目标检测结果,计算所选图像的显著目标检测结果
s44、计算最终的损失函数lossfinal=α*losssaliency+β*lossexistence+γ*lossselect,并利用最终的损失函数对图像显著目标检测模型进行监督和约束,识别出所述输入图像的显著图,参数α,β,γ分别表示三个损失在最终损失值中的权重。
具体来说,参数α,β,γ的比例定义为20:1:10。特别需要说明的是,这种取值是多次实验得出来的结果,参数的含义本领域技术人员公知,这种取值可以得到更好的实验结果。
另外,该处的图像显著目标检测模型包括深度特征提取器和自适应选择训练模型两个模型。
具体来说,假设一组输入图像i={ii|i=1,..,b},b表示一组图像的数量。y={yi|i=1,..,b}表示相对应的显著目标真实值的集合z={zi|i=1,..,b}表示显著性预测真值的集合,zi表示图像ii是否包含显著目标。
(1)显著性存在预测损失lossexistence采用交叉熵,被定义为:
其中,i表示一组图像中图像的索引,
其中,函数
其中,p可表示真值图中像素的索引也可以表示图像中像素的索引,n是图像真值图和图像中的像素的数量。
因此,融合显著目标存在性预测结果的显著目标检测的损失函数定义为:
其中,y={yi|i=1,..,b}表示相对应的显著目标真实值的集合,
(3)根据显著目标存在性标签真值选择出包含显著目标的图像,将其序号编入向量index中,通过显著性存在预测损失lossexistence的计算公式和函数
selecty=indexselect(y,index)
被选择出来的包含显著目标的图像的不融合显著目标存在性预测结果的显著目标检测的损失函数lossselect可以表示为:
需要说明的是,显著目标存在性预测和显著目标检测双任务学习建立模型,在此基础上,模型选择包含显著目标的图像,根据其产生的未融合显著目标存在性预测特征的显著目标检测结果及真值之间的损失函数的监督和约束,训练得到一个既能对包含显著目标的图像进行显著目标检测,又能准确地对不包含显著目标的图像进行识别的模型,加强模型对包含显著目标图像及不包含显著目标图像的检测能力。
在本实施例中,通过与现有的显著目标检测模型对比证明了其有效性以及在效果上明显的优势。对比的模型包括:
(1)dss17(hou,qibin,etal."deeplysupervisedsalientobjectdetectionwithshortconnections."proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2017.)
(2)bmpm18(zhang,lu,etal."abi-directionalmessagepassingmodelforsalientobjectdetection."proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2018.)
(3)r3net18(deng,zijun,etal."r3net:recurrentresidualrefinementnetworkforsaliencydetection."proceedingsofthe27thinternationaljointconferenceonartificialintelligence.aaaipress,2018.)
(4)cpd19(wu,zhe,lisu,andqingminghuang."cascadedpartialdecoderforfastandaccuratesalientobjectdetection."proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2019.)
(5)basnet19(qin,xuebin,etal."basnet:boundary-awaresalientobjectdetection."proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2019.)
所有的模型在soc数据集的训练集上进行训练的。测试集包括:soc测试集、dut-omron、hku-is、msra-b、ecssd。对比的结果显示在图4中,对于所有指标,本发明中的图像显著目标检测模型表现出良好的性能。由于对比模型的设计不考虑非显著性图像对模型的影响,训练集在添加一些非显著性图像后,模型检测显著目标的能力下降。本模型将图像级分类特征和像素级语义特征结合起来,共同训练两种任务的损失,同时自适应地选择包含显著目标的图像进行增强学习,提高了模型的检测精度。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!