基于信用大数据标签的行业发展趋势分析模型及构建方法与流程
本发明涉及评分卡模型技术领域,具体为基于信用大数据标签的行业发展趋势分析模型及构建方法。
背景技术:
随着社会诚信体系的建设,如何评估行业整体信用趋势是有着必要性的,通过了解行业整体信用发展趋势,对不同行业进行分类监管,可进一步引导各行业依法、诚信、规范经营,构建和完善各行业长效治理机制,促进各行业持续健康发展,对行业内的企业,通过和行业平均线进行对比,了解企业信用在行业内的排名,对排名尾部的企业加强监管,对排名头部企业实施一定的奖励,引导企业良性的发展,但是,现有技术中并不能有效的对行业整体信用趋势进行评估,存在着一定的局限性。
技术实现要素:
(一)解决的技术问题
针对现有技术的不足,本发明提供了基于信用大数据标签的行业发展趋势分析模型及构建方法,解决了现有技术中并不能有效的对行业整体信用趋势进行评估,存在着一定局限性的问题。
(二)技术方案
为实现以上目的,本发明通过以下技术方案予以实现:基于信用大数据标签的行业发展趋势分析模型及构建方法,包括以下实现步骤:
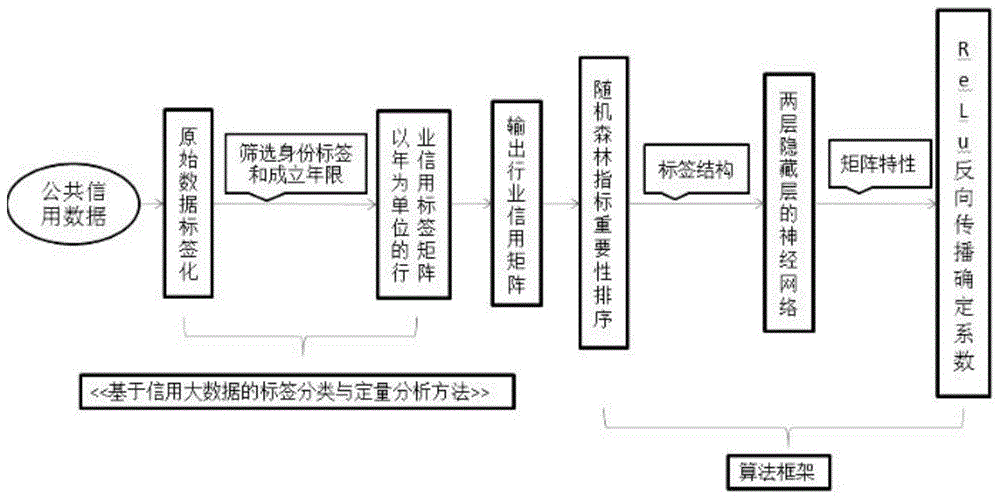
s1、构建随机森林算法,基于信用大数据标签,将原始数据标签化;
s2、使用随机森林算法对企业信用数据的历史样本数据进行指标筛选,初步构建一套针对行业发展趋势分析的模型;
s3、构建具有两层隐藏层的神经网络模型;
s4、用relu的反向传播法确定各个维度的系数;
s5、计算各层次指标的权重值并通过已计算出的权重系数量化企业发展趋势。
优选的,所述步骤1中构建随机森林算法包括以下具体内容:
1)基于信用大数据的标签分类与定量分析方法,将原始数据标签化;
2)通过身份标签进行行业筛选,获取行业内企业的信用能力和信用意愿标签;
3)按照企业成立年限进行排序,获得行业每一年的信用标签矩阵。
优选的,所述步骤2包括以下具体内容:
1)以当年限倒闭企业作为坏样本,当年限续存作为好样本拟合随机森林模型;
2)获得各项指标的重要性结果后,去掉重要性占比小于0.1%的指标,初步得到了的数据指标。
优选的,所述历史样本数据主要来自于监管部门的历史信息信用数据、公共信用信息平台数据与信用互联网数据。
优选的,所述步骤2中构建的一套针对行业发展趋势分析的模型中,考虑了公共信用和行业历史信用相结合,结合了行业生命周期理论。
优选的,所述步骤3中构建神经网络模型具体内容如下:
1)神经网络输入层为经过随机森林选取后的信用标签数据;
2)基于信用大数据的标签分类与定量分析方法,第一隐藏层设置六个节点,分别为代表社会口碑、风险信息、社会责任、荣誉表彰、经营状况和发展前景六个维度,设置偏差项,调整各次级维度对上级维度的误差;
3)基于信用大数据的标签分类与定量分析方法,第一隐藏层设置二个节点,分别为代表信用能力和信用意愿两个维度,设置偏差项,调整各次级维度对上级维度的误差;
4)输入层的各个维度初始权重设置相同。
优选的,所述步骤4中利用搭建好的神经网络设定relu为神经网络激活函数,通过反向传播方法计算各个节点的权重。
优选的,所述步骤4中还包括运用批量梯度下降的方式确定各个节点的最优参数。
优选的,所述步骤5中还包括通过从神经网络中获得的维度权重参数,结合该维度的woe值,运用评分卡模型给行业内所有企业进行评分,结合行业生命周期曲线,运用折线图展示行业在不同时期的信用发展趋势。
(三)有益效果
本发明提供了基于信用大数据标签的行业发展趋势分析模型及构建方法。具备以下有益效果:
本发明,可以计算出行业内所有企业潜力得分,通过成立年限对企业进行排序,计算出每一年度企业潜力得分的平均值,完成基于信用标签数据的行业信用发展趋势分析模型构建,通过客观与主观的结合,且根据实际数据给出了一个可供参考的分析模型,从而能够有效的对行业整体信用趋势进行评估。
附图说明
图1为本发明中步骤1-4的流程图;
图2为本发明中步骤5的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例:
如图1-2所示,本发明实施例提供基于信用大数据标签的行业发展趋势分析模型及构建方法,包括以下具体内容:
一:数据归集和预处理。
以所在地区的由市场监管等登记管理部门登记,获得获得营业资格的续存企业和曾经获得营业资格的倒闭企业作为样本,收集所有可得到的近两年的公共信用记录和行业信用记录数据,信用信息数据来源于市场监管等登记管理部门的信息数据,公共信用信息平台数据、信用互联网数据。
在搜集了企业近两年的历史数据的基础上,通过对所有的指标数据量化,进行数据清洗后,用随机森林得到指标的相对权重,按比重的从大到小排列,去掉重要性小于0.1%的指标,同时发现是否有资产负债率、纳税信用等级和成立年限这三个指标,对判断企业是否续存的影响最大。
二:由筛选出来的数据,通过神经网络确定各维度的权重。
神经网络由一层输入层,两层隐藏层和一层输出层构成,其两层隐藏层分别对应企业信用标签中二级维度和一级维度,所以设置第一隐藏层节点个数为8个,第二隐藏层节点个数为2个。
神经网络中各维度初始权重设置相同,将修正线性单元(relu)设置为神经网络激活函数,其公式为:
其函数图像如下:
其优势在于,相对于传统的激活函数(sigmod),relu激活函数主要变化有三点:
1)单侧抑制;
2)相对宽阔的兴奋边界;
3)稀疏激活性。
其中,对于本模型,稀疏激活性是及其重要的特征。对于信用原始数据,通常缠绕着高度密集的特征,一个关键因子可能牵扰着许多特征,而基于数学原理的传统机器学习手段在解离这些关联特征方面具有致命弱点。因此,稀疏激活性能够解开特征间缠绕的复杂关系,使得特征具有了鲁棒性,去掉了无关的噪声。其次,稀疏特征有更大可能线性可分,或者对非线性映射机制有更小的依赖。从流形学习观点来看,因为稀疏特征在高维的特征空间上被自动映射到一个较为纯净的低维流形面上,使得特征能更加好的分离。
三:基于反向传播算法和小批量梯度下降的方式确定最优参数。
基于relu的反向传播算法如下所示,
考虑一个输入向量x,经relu函数变换后得到向量r,正向传播得到误差值error(标量e),求e对x的梯度。
x=(x1,x2,x3,x4,x5….xn);
r=relu(x);
e=forward(r);
求解过程:
向量
小批量梯度下降法,是对批量梯度下降以及随机梯度下降的一个折中办法,其思想是:每次迭代使用n个样本来对参数进行更新。假定n为10,其迭代公式为:
相对于传统的梯度下降法,其优点在于:
1)通过矩阵运算,每次在一个样本集上优化神经网络参数速度不会比远低于单个数据慢;
2)每次使用一个样本集可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果;
3)可实现并行化。
在本模型中,小规模样本值设定为总体样本的5%,确定最优参数需要迭代20次。
四:综合woe值和神经网络参数量化企业潜力。
计算各维度woe值;
woe值的计算公式:
pgood为好样本在该标签取值下的占有率;
pbad为坏样本在改标签取值下的占有率。
每个属性对应的分值可以通过下面的公式计算:woe乘以改变量的回归系数,加上回归截距,再乘上比例因子,最后加上偏移量:
对于企业总体的分值,我们可以这么计算:
确定各维度单位分值间隔为:
其中
1)设定当odds每增加1倍时,增加的分数pdo(pointofdoubleodds);
2)将当odds=θ0的分数p0,odds=2θ0的分数p0+pdo带入分数公式。
在本模型中,将基准分设为50分,比率翻倍的分值(pdo)设为5分,通过上述公式,得出企业在该年度的潜力得分。通过上述过程,计算出行业内所有企业潜力得分,通过成立年限对企业进行排序,计算出每一年度企业潜力得分的平均值,至此,行业信用发展趋势分析模型构建完成。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!