一种Spark环境下的两段式流水线任务调度方法及系统与流程
本发明属于大数据分布式并行计算领域,更具体地,涉及一种spark环境下的两段式流水线任务调度方法及系统。
背景技术:
随着互联网的高速发展,搜索引擎、社交网络等数据密集型应用的普及,数据规模急剧膨胀,为了应对大数据时代数据处理的挑战,以“计算跟随数据移动”为特征的新型海量数据处理平台应运而生。spark便是这一类型的典型代表。
调度在spark中占据非常重要的地位,其调度策略分为多个级别,包括应用(application)调度、工作(job)调度、调度阶段(stage)调度、任务(task)调度。本发明主要关注任务级别的调度。在spark中,一个工作会被划分为一个或多个阶段,一个阶段包含一个任务集。为了实现并行处理,spark中会将rdd划分为更小的数据分片(partition),每个任务处理对应的一个分片数据。任务调度的目的就是要充分挖掘数据本地性减少数据混洗(shuffle)阶段的数据传输。一般而言,任务的数据本地化级别越高,需要传输的数据越少,任务执行的总时间就越少。
近年来,许多学者致力于任务调度的研究,综合来看,大致可以分为以下几种:(1)提高任务的执行性能,xiej等人提出将更多的数据存储在处理速度较快的节点。(2)减少任务的数据传输,如virajithjalaparti等人提出将job的所有任务集中于若干个机架而不是全部机架来减少机架间的数据传输。(3)任务推测执行。当存在执行速度很慢的任务,启动任务的多个副本同时执行,以最快完成的任务的结果作为实际任务运行结果。
在大多数研究方法中,其最核心的思想都是通过考虑任务的放置,使其进行更少的数据传输或者更少的跨机架数据传输,本质都是减少任务的数据拉取时间。但是考虑到任务在它的运行期间需要多种资源如cpu、网络等,并且其对资源的需求是随时间变化的。一个任务的执行生命周期主要会经历输入、计算、输出等阶段。在输入阶段,主要需要网络资源;在计算阶段,主要需要cpu资源;而在输出阶段,主要是磁盘资源。在spark中,单个执行器(executor)中最大的能运行的任务的数量为cpu内核(cpucore)的数量,大多数解决方案都遵循这一规则。这就带来一个问题,即使某个cpu内核被分配了任务,但其仍然不能被充分利用。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种spark环境下的两段式流水线任务调度方法,其目的在于提高集群资源利用率,减少工作运行时间,由此解决即使cpu内核被分配了任务但仍不能被充分利用的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种spark环境下的两段式流水线任务调度方法,包括以下阶段:
网络空闲(network-free)阶段任务调度,该阶段为共生任务及等待任务分配cpu资源,当正在运行的任务有共生任务时,在其执行完成后,将其占用的cpu资源分配给其共生任务;否则,在其执行完成后,按照spark环境优先级的调度将其占用的cpu资源分配给相应等待任务;所述共生任务,为需要进行数据拉取的与特定的正在运行的任务关联的任务,所述共生任务在运行初期与所述特定的正在运行的任务共用同一个cpu内核;
网络需求(network-intensive)阶段任务调度,该阶段为正在运行的任务匹配数据拉取时间大于其剩余完成时间的等待任务作为共生任务,并对共生任务进行调度,使得所述共生任务利用网络带宽资源进行远程数据拉取,并在此期间内完成所述正在运行任务的执行。
优选地,所述spark环境下的两段式流水线任务调度方法,其所述网络空闲阶段任务调度包括以下步骤:
(1)获取所有可用的cpu内核正在运行的任务列表、共生任务列表、以及等待任务队列;
(2)资源调度:对于所有正在运行的任务,当其在共生任务列表中具有相应共生任务时,该任务执行完毕后,调度其使用的cpu内核执行共生任务;当其在共生任务列表中没有相应共生任务时,该任务执行完毕后,释放cpu内核并执行默认调度;
(3)更新任务列表:根据步骤(2)的调度结果,将已执行的共生任务从共生任务队列中移除,并加入到正在运行的任务列表中,将默认调度被执行的等待任务从等待任务队列中删除。
优选地,所述spark环境下的两段式流水线任务调度方法,其所述网络需求阶段任务调度包括以下步骤:
s1、获取所有可用的cpu内核正在运行的任务列表、共生任务列表、等待任务队列、以及等待任务数据拉取信息;所述数据拉取信息,包括所述任务要处理的数据总量和远程数据量;
s2、共生任务匹配:遍历步骤s1中获得的正在运行的任务列表,选择没有共生任务的正在运行的任务作为目标任务;对于目标任务,当步骤s1中获得的等待任务队列中存在数据拉取时间大于目标任务剩余完成时间时,选择数据拉取时间大于目标任务剩余完成时间且最小的等待任务作为目标任务的共生任务;否则所述目标任务匹配共生任务失败;
s3、共生调度:将步骤s4中获取的与步骤s1中获取的与正在运行的任务相匹配的共生任务,从等待任务列表中移除,加入到共生任务列表并进行该任务的调度执行。
优选地,所述spark环境下的两段式流水线任务调度方法,其步骤s2按照其剩余完成时间从小到大的顺序将所述没有共生任务的正在运行任务依次作为目标任务。
优选地,所述spark环境下的两段式流水线任务调度方法,其步骤s2所述正在运行任务taski的剩余完成时间为其总执行时间与已执行时间的差值,所述正在运行任务taski的总执行时间按照以下方法估计:
ti=di/v,v=df/tf
其中,di为所述正在运行任务taski的数据总量,df为已完成的同一阶段的任务taskf的数据总量df,tf为任务taskf的执行时间。
优选地,所述spark环境下的两段式流水线任务调度方法,其步骤s2所述各等待任务的数据拉取时间采用数据量除以平均网络速率方式、或采用智能预测算法预测。
优选地,所述spark环境下的两段式流水线任务调度方法,其步骤s2所述采用智能预测算法预测等待任务的数据拉取时间,具体包括以下步骤:
离线训练:收集任务的历史运行信息,所述历史运行信息包括:任务所需远程拉取数据量、任务远程数据拉取请求数、远程数据拉取时网络状态、数据拉取时间;将任务历史运行信息用于数学模型训练直至收敛,获得用于预测任务数据拉取时间的数学模型,优选bp神经网络模型;
在线预测:获取所述等待任务的运行信息;所述运行信息包括所述任务要拉取远程数据量、所述任务远程数据拉取请求数、目前网络状态,输入到离线训练获得的用于预测任务数据拉取时间的数据学模型,预测得到所述任等待任务的数据拉取时间。
优选地,所述spark环境下的两段式流水线任务调度方法,其所述用于预测任务数据拉取时间的bp神经网络模型由输入层、两层隐含层、输出层组成,采用sigmoid函数作为激活函数,均方误差作为损失函数,收敛条件为误差小于1e-5或者迭代8000次。
按照本发明的另一个方面提供了一种spark环境下的两段式流水线任务调度系统,包括网络空闲阶段任务调度模块和网络需求阶段任务调度模块;
所述网络空闲阶段任务调度模块,用于为共生任务及等待任务分配cpu资源:当正在运行的任务有共生任务时,在其执行完成后,将其占用的cpu资源分配给其共生任务;否则,在其执行完成后,按照spark环境优先级的调度将其占用的cpu资源分配给相应等待任务;所述共生任务,为需要进行数据拉取的与特定的正在运行的任务关联的任务,所述共生任务在运行初期与所述特定的正在运行的任务共用同一个cpu内核;
所述网络需求阶段任务调度模块,用于为正在运行的任务匹配数据拉取时间大于其剩余完成时间的等待任务作为共生任务,并对共生任务进行调度,使得所述共生任务利用网络带宽资源进行远程数据拉取,并在此期间内完成所述正在运行任务的执行。
优选地,所述的spark环境下的两段式流水线任务调度系统,其所述所述网络需求阶段任务调度模块,包括调度器、估算器、收集器、以及多个记录器;
所述多个记录器(recorder),分别用于收集spark环境执行器(executor)中任务的历史运行信息并提交给收集器,所述历时运行信息包括:任务所需远程拉取数据量、任务远程数据拉取请求数、远程数据拉取时网络状态、数据拉取时间;
所述收集器(collector),用于收集多个记录器提交的任务的历史运行信息,并将所述任务历史运行信息进行存储用于数学模型训练直至收敛,获得用于预测任务数据拉取时间的数学模型,将所述用于预测任务数据拉取时间的数学模型更新到估算器;
所述估算器(estimator),用于根据其存储的用于预测任务数据拉取时间的数学模型,估算等待任务列表中的等待任务的数据拉取时间,以及估算正在执行的任务的剩余完成时间,并提交给调度器;
所述调度器(scheduler),用于根据估算器估算的等待任务的数据拉取时间,为spark环境执行器(executor)中运行的没有共生任务的正在运行任务匹配共生任务,从而本发明提供的spark环境下的两段式流水线调度方法中的网络需求阶段任务调度。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,由于提前对共生任务进行调度,使得任务在执行时,其共生任务执行网络i/o,共生任务在执行完网络i/o后,恰能获得任务执行完毕释放的cpu资源,实现流水线作业,能够取得提高cpu资源及网络资源利用率、从而有效地减少了资源的空闲时间和job的完成时间。
附图说明
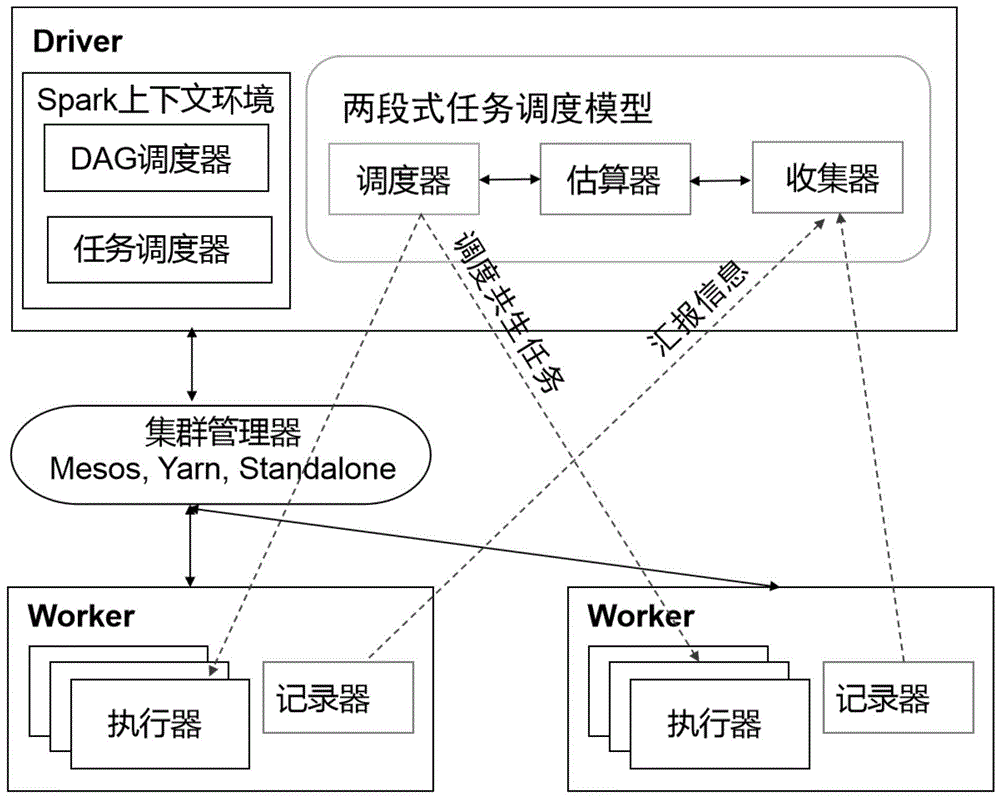
图1是一个实施例中两段式流水线任务调度方法的应用架构图;
图2是一个实施例中数据拉取时间预测的流程示意图。
图3是一个实施例中数据拉取时间预测模型图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明提供的spark环境下的两段式流水线任务调度方法,包括以下阶段:
网络空闲阶段任务调度,该阶段为共生任务及等待任务分配cpu资源:当正在运行的任务有共生任务时,在其执行完成后,将其占用的cpu资源分配给其共生任务;否则,在其执行完成后,按照spark环境优先级的调度将其占用的cpu资源分配给相应等待任务;所述共生任务,为需要进行数据拉取的与特定任务关联的任务,并会在运行初期与特定任务共用同一个cpu内核,因其首先会进行网络i/o,资源的主要诉求不同,故可进行共生;具体包括以下步骤:
(1)获取所有可用的cpu内核正在运行的任务列表、共生任务列表、以及等待任务队列;
(2)资源调度:对于所有正在运行的任务,当其在共生任务列表中具有相应共生任务时,该任务执行完毕后,调度其使用的cpu内核执行共生任务;当其在共生任务列表中没有相应共生任务时,该任务执行完毕后,释放cpu内核并执行默认调度;
(3)更新任务列表:根据步骤(2)的调度结果,将已执行的共生任务从共生任务队列中移除,并加入到正在运行的任务列表中,将默认调度被执行的等待任务从等待任务队列中删除。
网络需求阶段任务调度:该阶段为正在运行的任务匹配数据拉取时间大于其剩余完成时间的等待任务作为共生任务,并对共生任务进行调度,使得所述共生任务利用网络带宽资源进行远程数据拉取,并在此期间内完成所述正在运行任务的执行,共生任务首先会利用网络带宽资源进行远程数据拉取,而不需要利用cpu资源进行计算,如此流水线调度提高了cpu资源和网络带宽资源得利用率;具体包括以下步骤:
s1、获取所有可用的cpu内核正在运行的任务列表、共生任务列表、等待任务队列、以及等待任务数据拉取信息;所述数据拉取信息,包括所述任务要处理的数据总量和远程数据量;
s2、共生任务匹配:遍历步骤s1中获得的正在运行的任务列表,选择没有共生任务的正在运行的任务作为目标任务;对于目标任务,当步骤s1中获得的等待任务队列中存在数据拉取时间大于目标任务剩余完成时间时,选择数据拉取时间大于目标任务剩余完成时间且最小的等待任务作为目标任务的共生任务;否则所述目标任务匹配共生任务失败;
优选方案,按照其剩余完成时间从小到大的顺序将所述没有共生任务的正在运行任务依次作为目标任务。
所述正在运行任务taski的剩余完成时间为其总执行时间与已执行时间的差值,所述正在运行任务taski的总执行时间按照以下方法估计:
ti=di/v,v=df/tf
其中,di为所述正在运行任务taski的数据总量,df为已完成的同一调度阶段的任务taskf的数据总量df,tf为任务taskf的执行时间。
所述各等待任务的数据拉取时间,采用数据量除以平均网络速率方式、或采用智能预测算法预测。
所述采用智能预测算法预测等待任务的数据拉取时间,具体包括以下步骤:
离线训练:收集任务的历史运行信息,所述历史运行信息包括:任务所需远程拉取数据量、任务远程数据拉取请求数、远程数据拉取时网络状态、数据拉取时间;将任务历史运行信息用于数学模型训练直至收敛,获得用于预测任务数据拉取时间的数学模型,优选bp神经网络模型;所述用于预测任务数据拉取时间的bp神经网络模型由输入层、两层隐含层、输出层组成,采用sigmoid函数作为激活函数,均方误差作为损失函数,收敛条件为误差小于1e-5或者迭代8000次。
在线预测:获取所述等待任务的运行信息;所述运行信息包括所述任务要拉取远程数据量、所述任务远程数据拉取请求数、目前网络状态,输入到离线训练获得的用于预测任务数据拉取时间的数据学模型,预测得到所述任等待任务的数据拉取时间。
s3、共生调度:将步骤s4中获取的与步骤s1中获取的与正在运行的任务相匹配的共生任务,从等待任务列表中移除,加入到共生任务列表并进行该任务的调度执行。
本发明提供的spark环境下的两段式流水线任务调度系统,包括网络空闲阶段任务调度模块和网络需求阶段任务调度模块;
网络空闲阶段任务调度模块,用于为共生任务及等待任务分配cpu资源:当正在运行的任务有共生任务时,在其执行完成后,将其占用的cpu资源分配给其共生任务;否则,在其执行完成后,按照spark环境优先级的调度将其占用的cpu资源分配给相应等待任务;所述共生任务,为需要进行数据拉取的与特定任务关联的任务,并会在运行初期与特定任务共用同一个cpu内核,因其首先会进行网络i/o,资源的主要诉求不同,故可进行共生;
网络需求阶段任务调度模块,用于为正在运行的任务匹配数据拉取时间大于其剩余完成时间的等待任务作为共生任务,并对共生任务进行调度,使得所述共生任务利用网络带宽资源进行远程数据拉取,并在此期间内完成所述正在运行任务的执行。
所述网络需求阶段任务调度模块,包括调度器、估算器、收集器、以及多个记录器;
所述多个记录器(recorder),分别用于收集spark环境执行器(executor)中任务的历史运行信息并提交给收集器,所述历时运行信息包括:任务所需远程拉取数据量、任务远程数据拉取请求数、远程数据拉取时网络状态、数据拉取时间;
所述收集器(collector),用于收集多个记录器提交的任务的历史运行信息,并将所述任务历史运行信息进行存储用于数学模型训练直至收敛,获得用于预测任务数据拉取时间的数学模型,将所述用于预测任务数据拉取时间的数学模型更新到估算器;
所述估算器(estimator),用于根据其存储的用于预测任务数据拉取时间的数学模型,估算等待任务列表中的等待任务的数据拉取时间,以及估算正在执行的任务的剩余完成时间,并提交给调度器;
所述调度器(scheduler),用于根据估算器估算的等待任务的数据拉取时间,为spark环境执行器(executor)中运行的没有共生任务的正在运行任务匹配共生任务,从而本发明提供的spark环境下的两段式流水线调度方法中的网络需求阶段任务调度。
以下为实施例:
一种spark环境下的两段式流水线任务调度系统,如图1所示,包括网络空闲阶段任务调度模块和网络需求阶段任务调度模块;
网络空闲(network-free)阶段任务调度模块,为spark环境默认的任务调度器,接受网络需求阶段任务调度模块调度的共生任务列表,用于为共生任务及等待任务分配cpu资源,当正在运行的任务有共生任务时,在其执行完成后,将其占用的cpu资源分配给其共生任务;否则,在其执行完成后,按照spark环境优先级的调度将其占用的cpu资源分配给相应等待任务;所述共生任务,为需要进行数据拉取的与特定任务关联的任务,并会在运行初期与特定任务共用同一个cpu内核,因其首先会进行网络i/o,资源的主要诉求不同,故可进行共生;
网络需求(network-intensive)阶段任务调度模块,用于为正在运行的任务匹配数据拉取时间大于其剩余完成时间的等待任务作为共生任务,并对共生任务进行调度,使得所述共生任务利用网络带宽资源进行远程数据拉取,并在此期间内完成所述正在运行任务的执行。
所述网络需求阶段任务调度模块,包括调度器、估算器、收集器、以及多个记录器;
所述多个记录器(recorder),分别用于收集spark环境worker的执行器(executor)中任务的历史运行信息并提交给收集器,所述历时运行信息包括:任务所需远程拉取数据量、任务远程数据拉取请求数、远程数据拉取时网络状态、数据拉取时间;
所述收集器(collector),用于收集多个记录器提交的任务的历史运行信息,并将所述任务历史运行信息进行存储用于数学模型训练直至收敛,获得用于预测任务数据拉取时间的数学模型,将所述用于预测任务数据拉取时间的数学模型更新到估算器;
所述估算器(estimator),用于根据其存储的用于预测任务数据拉取时间的数学模型,估算等待任务列表中的等待任务的数据拉取时间,以及估算正在执行的任务的剩余完成时间,并提交给调度器;
所述调度器(scheduler),用于根据估算器估算的等待任务的数据拉取时间,为spark环境执行器(executor)中运行的没有共生任务的正在运行任务匹配共生任务,从而本发明提供的spark环境下的两段式流水线调度方法中的网络需求阶段任务调度。
实施例2
应用实施例1中调度系统的两段式流水线任务调度方法,将分别处于网络需求(network-intensive)阶段和网络空闲(network-free)阶段的任务(task)放置于同一个cpu内核,形成任务共生状态;通过在正在执行的task的运行后期(主要需要cpu资源,对应network-free阶段)进行需要进行远程数据拉取的task(主要需要网络资源,对应network-intensive阶段)的调度,使任务更快运行起来,提高资源的利用率。
网络空闲阶段任务调度,具体包括以下步骤:
步骤1:在工作(job)运行过程中收集task的历史运行信息,用于bp神经网络模型的离线训练,如图2所示。所述历史运行信息包括:任务所需远程拉取数据量、任务远程数据拉取请求数、远程数据拉取时网络状态、数据拉取时间;所述用于预测任务数据拉取时间的bp神经网络模型如图3所示,由输入层、两层隐含层、输出层组成,采用sigmoid函数作为激活函数,均方误差作为损失函数,收敛条件为误差小于1e-5或者迭代8000次;将任务历史运行信息用于数学模型训练直至收敛,获得用于预测任务数据拉取时间的数学模型。
步骤2:在调度阶段(stage)提交时,统计task要处理的数据总量和远程数据量,以两个hashmap的结构进行记录,其键(key)均为由其所在的调度阶段id和要处理的数据分片(partition)的id联合拼接而成,值(value)分别为long类型的数据总量大小和hashmap类型的<主机名,当task在该主机启动时需要拉取的远程数据量>键值对集合。
步骤3:在task执行完成时,由于共生状态的存在,cpu资源不一定得到释放。所以首先判断完成的task是否存在共生task。
步骤4:如果完成的task不存在共生task,即该task独占cpu内核,进行spark的默认调度策略,从等待任务(pendingtasks)队列中选择最后一个task进行调度。跳转到网络需求阶段任务调度。
步骤5:如果完成的task存在共生task,也就是说在该task执行后期,就进行了新的task的调度。那么该task完成之后,其cpu资源将由共生任务使用。阻塞执行器(executor)发给驱动器(driver)的关于task完成状态的消息,实现不进行spark的默认调度策略。
网络需求阶段任务调度,为正在运行的任务寻找共生task并调度。在executor中会同时运行多个task,无论执行完成的task是否存在共生task,都可以为其它的正在执行的task寻找共生task。这是考虑到一个task通常会经历输入、计算、输出等阶段,而不同的阶段其需要的主要资源是不一样的,所以当executor中运行的task的数量超过其cpu内核的数量时,也很少会出现资源竞争的情况,反而减少了资源的空闲时间,提高资源的利用率。具体包括如下步骤:
1、初始化共生任务集合为空。
2、利用离线训练好的bp模型在线预测pendingtasks队列中任一taski的数据拉取时间tpulli,如图2所示。
3、对pendingtasks队列中的task根据数据拉取时间递减排序。
4、计算executor的剩余完成时间tremain。所述的executor的剩余时间计算,其特征在于将其上运行的所有tasks的最小剩余执行时间作为executor的剩余执行时间。同一个stage的task利用不同的数据集执行相同的数据逻辑,所以利用同一stage已完成的task的执行时间对正在执行的task进行估计,具体如下:
所述正在运行任务taski的剩余完成时间为其总执行时间与已执行时间的差值,所述正在运行任务taski的总执行时间按照以下方法估计:
ti=di/v,v=df/tf
其中,di为所述正在运行任务taski的数据总量,df为已完成的同一调度阶段的任务taskf的数据总量df,tf为任务taskf的执行时间。
5、依次遍历排序后的等待任务队列中的task的数据拉取时间tpulli。如果最小的数据拉取时间tpull1小于tremain,则代表不存在共生task,结束调度,跳转到6。否则依序判断tpull1是否小于tremain,小于的话代表它的前一个task就是我们要找的共生task,将它的前一个task加入共生任务集合,并从等待任务队列中移除。跳转到3继续查找。
6、得到共生任务集合。
然后将共生任务集合中的共生任务由scheduler调度到相应的executor中进行执行。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!