基于监督学习和文本分类的AC构建方法与流程
本发明属于仿真系统可信度评估领域,具体为一种基于监督学习和文本分类的ac构建方法。
背景技术:
随着复杂仿真系统的快速发展,仿真系统可信度评估工作逐渐被仿真系统的开发者和使用者所重视。可接受性标准(acceptabilitycriteria,ac)是建模与仿真(modeling&simulation,m&s)中确认决策的基础,定义了仿真系统满足于仿真需求或仿真目标的所需要的功能和该功能应当满足的质量要求。simoneyoungblood等人在其论文中提出,可接受性标准分为两大类:代表性标准和系统标准。代表性标准定义了仿真系统所需的功能清单;系统标准描述了仿真系统必须满足的所有其他条件以充分服务于用户的基础功能。当前对于ac的研究与应用工作还是在起步阶段,主要还是依靠人工对仿真需求文本进行归纳总结,抽取仿真需求文本中各个实体、属性及其它们之间的关系。由于仿真需求语句与ac之间可能存在多对多的关系,仅依靠人工进行抽取不仅耗时,而且很难从复杂仿真系统需求文本中抽取出高清晰度的ac。
技术实现要素:
本发明的目的在于提供一种基于监督学习和文本分类的ac构建方法。
实现本发明的技术解决方案为:一种基于监督学习与文本分类的ac构建方法,具体步骤为:
步骤1、将训练语料经过分词与标注后形成的文件输入到crf模型,把训练好的crf模型用于待实体识别的仿真需求文本中,即可得到仿真需求文本中实体。
步骤2、获得训练语料中实体对所在句子的特征向量,并将该特征向量与类别标签训练svm模型,将训练好的svm模型用于仿真需求文本的实体关系识别。
步骤3、提取训练语料中实体对所在句子的特征向量,训练svm分类模型;将待识别的仿真需求文本根据阈值规则和距离规则从该语句中抽取出阈值与性能指标,其次将部件实体与性能指标、性能指标与阈值两两配对形成实体对,构建实体对所在句子的特征向量并输入到各自svm分类模型中,获得抽取结果。
步骤4、首先训练语料进行数据预处理,其次确定文本特征的表达方式,基于此训练分类模型,并将该分类模型应用于系统标准语句识别中。
步骤5、基于步骤4的系统标准语句识别结果,将系统标准语句进行关键词提取,计算关键词与特征词的语义相似度,并依据相似度大小将关键词划分到最近似类,最后使用加权投票方法确定具体分类。
本发明与现有技术相比,其显著优点为:1)自动对包含系统标准的语句进行识别与分类,提高了ac构建的效率;2)使用规则和svm相结合的方法提取部件实体、性能指标和阈值,提高了抽取部件性能信息的准确率。
附图说明
图1为本发明基于监督学习和文本分类的ac构建方法的流程图。
图2为本发明实体抽取的算法流程图。
图3为本发明实体关系抽取的算法流程图。
图4为本发明部件精度信息抽取的算法流程图。
图5为本发明系统标准语句识别的算法流程图。
图6为本发明系统标准语句分类的算法流程图。
具体实施方式
下面结合附图和具体实施例,进一步说明本发明方案。
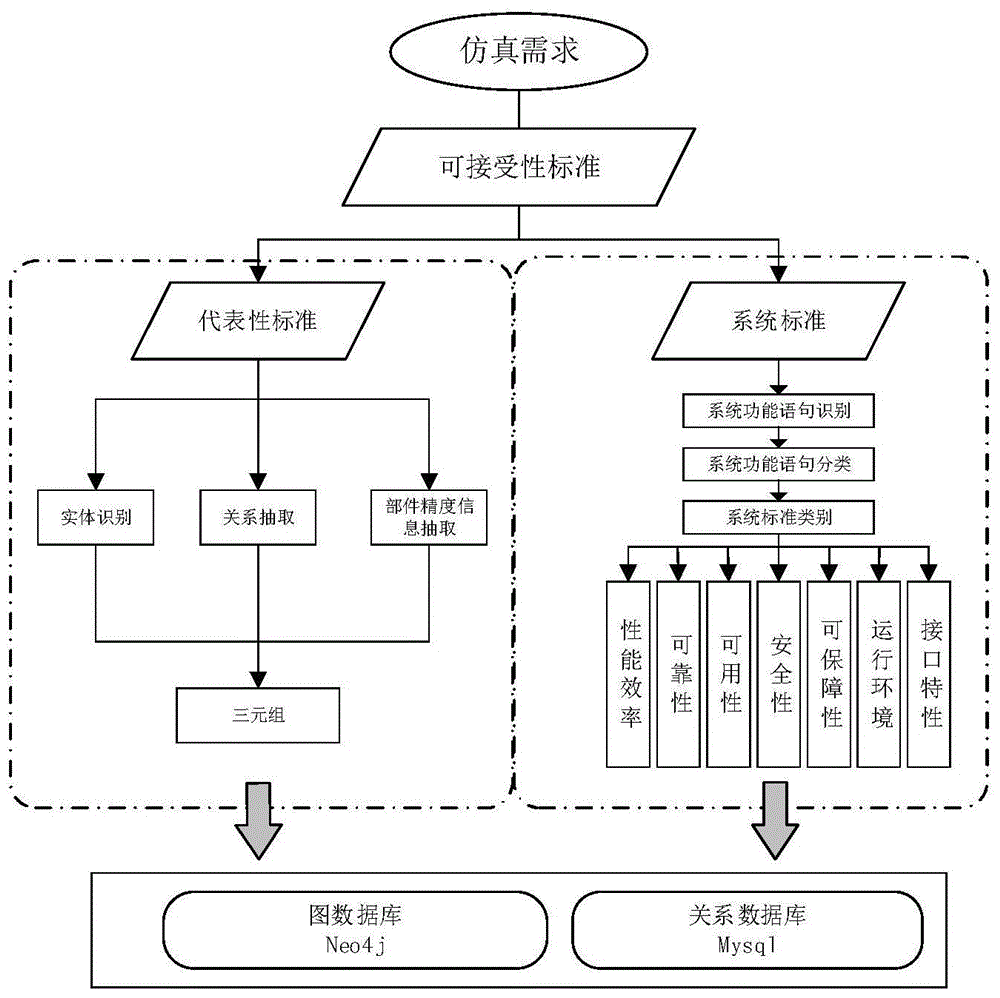
如图1所示,基于监督学习和文本分类的ac构建方法,包含以下步骤:
步骤1,基于crf模型对仿真需求文本进行实体抽取,如图2所示。
将训练语料经过分词与标注后形成的文件输入到crf模型,把训练好的crf模型用于待实体识别的仿真需求文本中,即可得到仿真需求文本中实体。实体主要包括三类:(1)部件实体,如目标模拟器、负载模拟器、总控制台等;(2)模型实体,弹体运动学模型、相对运动学模型、弹体运动学模型等;(3)能力实体,物理效应、指令传输、分析显示等。
所述步骤1具有以下两个子步骤,如下:
步骤1.1:crf模型训练阶段,训练语料由与待ac构建的仿真需求文本同类别的半实物仿真系统需求文档组成,首先将训练语料进行分词、词性标注、词边界标注、指示词标注、特征词标注和实体标注,并生成crf模型输入文件;接下来使用crf++对该crf模型输入文件进行迭代,生成crf模型;
步骤1.2:实体识别阶段,将待识别的仿真需求文本进行分词词性标注、词边界标注、指示词标注、特征词标注,生成crf模型输入文件,并将生成crf模型输入文件输入到步骤1.1中训练好的crf模型,即可得到待识别的仿真需求文本中的部件实体、模型实体和能力实体。
步骤2,基于svm模型对仿真需求文本进行实体关系抽取,如图3所示。
获得训练语料中实体对所在句子的特征向量,并将该特征向量与类别标签训练svm模型,将训练好的svm模型用于仿真需求文本的实体关系识别。实体关系是抽取的实体之间的归属关系,共有三种:包含关系、属于关系和无关系,如“目标模拟器能模拟某些物理效应”中包含“目标模拟器”和“物理效应”两个实体,其中“目标模拟器”包含“物理效应”。
所述步骤2具有以下两个子步骤,如下:
步骤2.1:svm分类模型训练阶段,训练语料由各类半实物仿真系统需求文档组成,与步骤1.1的训练语料为同一训练语料集,首先将训练语料中每条语句的实体两两组合,形成实体对;接下来提取实体对所在句子的特征,即实体对本身的特征、实体对所在句子特征和核心谓词特征,此过程由哈工大ltp工具完成,并将这些特征形成特征向量;接着将特征向量与其分类标签输入到svm分类模型,得到训练好的svm分类模型;
步骤2.1:实体关系抽取阶段,首先将待进行实体关系抽取的仿真需求文本经过步骤1.2,并将句子中包含两个及以上实体的语句抽取出来,将语句中的实体两两配对组成实体对,提取实体对所在句子的特征,即实体对本身的特征、实体对所在句子特征和核心谓词特征,并形成特征向量,将该特征向量输入到步骤2.1中训练好的svm分类模型,即可得到实体之间的关系,即部件实体、模型实体和能力实体之间的三元组关系(实体-关系-实体)。
步骤3,基于规则和svm模型对仿真需求文本进行部件精度信息抽取,如图4所示。
提取训练语料中实体对所在句子的特征向量,训练svm分类模型;将待识别的仿真需求文本根据阈值规则和距离规则从该语句中抽取出阈值与性能指标,其次将部件实体与性能指标、性能指标与阈值两两配对形成实体对,构建实体对所在句子的特征向量并输入到各自svm分类模型中,获得抽取结果。
部件精度信息由部件实体、性能指标及阈值组成,部件实体为半实物仿真系统中的设备,性能指标为部件的某些精度特性,阈值表示应达到的该特性应达到的质量要求,如负载模拟器、中心直径及70~330mm。
所述步骤3具有以下两个子步骤,如下:
步骤3.1:训练阶段,训练语料由各类半实物仿真需求文本组成,与步骤1.1的训练语料为同一训练语料集,将训练语料中的部件实体与性能指标组成实体对,并将该实体对所在句子的特征形成特征向量,将特征向量输入svm模型,形成部件实体与性能指标的svm分类模型;将训练语料中的性能指标与阈值组成实体对,并将该实体对所在句子的特征形成特征向量,将特征向量输入svm模型,形成性能指标与阈值的svm分类模型。
部件实体与性能指标的svm分类模型目的是判断语句中的部件实体与性能指标是否存在关系,存在关系则为“1”,不存在关系则为“0”;性能指标与阈值的svm分类模型目的是判断语句中的性能指标与阈值是否存在关系,存在关系则为“1”,不存在关系则为“0”。因此在进行部件精度信息抽取之前需要构建这两个分类器。
步骤3.2:部件精度信息抽取阶段,首先将待进行部件精度信息抽取的仿真需求文本经过步骤1.2过程,得到所有包含部件实体的语句,将该语句进行去停用词处理,根据以下阈值规则抽取该语句中的阈值,并根据位置规则抽取性能指标的候选词,并组成部件实体、性能指标实体对和性能指标、阈值实体对。对部件实体、性能指标实体对与性能指标实体、阈值实体对形成各自所在语句的特征向量,此过程由哈工大ltp工具完成,将该特征向量分别输入到步骤3.1中训练好的部件实体与性能指标svm分类模型和性能指标与阈值svm分类模型中,如果输出都为1,则表示该部件实体、性能指标及阈值之间是存在关系的,从而获得部件实体、性能指标及阈值三元组关系,示例如表1所示。
表1部件性能信息的抽取结果表
阈值规则表现为词性组成规则,在仿真系统需求文本中的表现为三类:“数词”+“量词”(如15nm、0.2nm等)、“符号”+“数词”+“量词”(≥15hz、±30°等)、“数词”+“~”+“数词”+“量词”(15~20hz)。
位置规则为提取该语句中阈值前的第一个或第二个名词词性的词语,即为性能指标的候选词。
步骤4,基于bow+nbsvm对仿真系统需求文本进行系统标准语句识别,如图5所示。
首先训练语料进行数据预处理,其次确定文本特征的表达方式,基于此训练分类模型,并将该分类模型应用于系统标准语句识别中。
系统标准可以认为是一般系统中的非功能需求,只是在仿真系统中具有特殊的意义。系统标准分为性能效率、可靠性、可用性、安全性、可保障性、运行环境和接口特性七类。
所述步骤4具有以下四个子步骤,如下:
步骤4.1:训练与语料由与待构建ac的需求文本同类别的需求文本组成,可以与步骤1.1、2.1、3.1采用同一个训练语料,首先使用hanlp工具对训练语料进行分词、词性标注和关键词提取;
步骤4.2:使用文本特征模型bow确定步骤4.1文本特征的表达方式;
步骤4.3:将文本特征化表示输入nbsvm分类模型,得到训练好的nbsvm分类模型;
步骤4.4:使用步骤4.1的分词与关键词提取以及步骤4.2的文本特征表示处理待识别的仿真需求文本,将得到的特征输入到步骤4.3中训练好nbsvm分类模型中,即可得出分类结果为“包含系统标准”和“不包含系统标准”两类标签。
步骤5,基于改进的非功能需求分类算法进行系统标准语句分类,如图6所示。
基于步骤4的系统标准语句识别结果,将系统标准语句进行关键词提取,计算关键词与特征词的语义相似度,并依据相似度大小将关键词划分到最近似类,最后使用加权投票方法确定具体分类。
所述步骤5具有以下四个子步骤,如下:
步骤5.1:首先使用hanlp工具将步骤4中识别的包含系统标准的语句进行关键词抽取,每个语句可能存在多个关键词;
步骤5.2:其次利用词林与词向量融合的词语相似度计算方法,计算5.1中的关键词与七类系统标准的常用特征词之间的语义相似度;
词林与词向量融合的词语相似度计算方法为:使用仿真系统需求文本语料库训练word2vec模型,并将训练好的word2vec模型与词林相似度计算方法进行简单融合,融合的权重设置为word2vec权重为0.5,词林权重为0.5;
步骤5.3:最后依据关键词与特征词的相似度大小将关键词划分到最近似类,由于每个特征词拥有不同的权重,最终对语句中的所有关键词使用加权投票方式将系统标准语句划分到具体类别,从而得到系统标准语句的具体分类。
步骤6,基于步骤2与步骤3得到的两对三元组关系和步骤5得到的系统标准语句及其具体分类共同构建仿真需求文档中的ac。
- 还没有人留言评论。精彩留言会获得点赞!