一种复杂光污染环境下产品特征图像人工智能识别方法与流程
本发明属于汽车生产技术领域,具体涉及一种复杂光污染环境下产品特征图像人工智能识别方法。
背景技术:
汽车生产过程中有很多形状需要检测,有的是规则的形状、有的是不规则的形状。对于比较规则的形状我们可以采用图像处理、边缘检测、霍夫变换、曲线拟合来定位待检测目标的位置。但是对于不规则的形状,曲线拟合比较复杂。另外由于汽车生产车间的环境复杂,光照环境并不一定能够满足进行图像处理所需的要求,会出现光照过亮或者过暗的情况。即使用同一种亮度的光源进行照射,不同的材料表面对光照的反射情况也不同,同种材料在有污渍、锈斑的情况下也会反射不同。这就出现了在同样光源亮度的情况下,物体反射不一样表现出不同的成像效果,出现照片过亮过暗的情况,从而导致图像处理算法失效,目标检测失败。
近年来随着深度学习的快速发展,基于深度学习的目标检测方法迎来了快速进步。常见的目标检测方法有r-cnn,fastr-cnn,fasterr-cnn,ssd,yolo等等。这些目标检测方法相比于传统的图像处理方法检测效果更好。但是也存在着检测速度不理想的问题。本发明将采用综合考虑检测速度与精度,采用yolov3目标检测算法作为基础的目标检测方法。并且对yolov3目标检测算法进行改进。以满足生产车间的实时性要求。
技术实现要素:
针对以上技术问题,本发明提供一种复杂光污染环境下产品特征图像人工智能识别方法,包括如下步骤:
1、一种复杂光污染环境下产品特征图像人工智能识别方法,包括如下步骤:
(1)模型优化改进
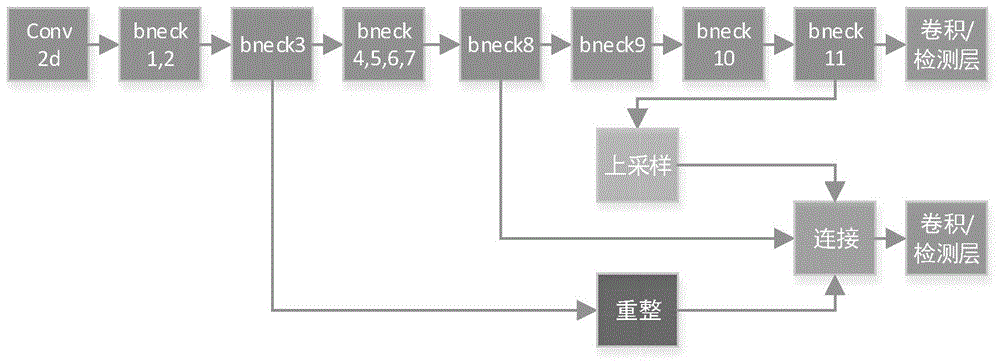
采用mobilenetv3-small替换yolov3的darknet53,将mobilenetv3-small的第11个bneck输出特征进行一次卷积操作,卷积特征作为一层检测输出,之后将第11个bneck上采样,将第3个bneck输出特征重整与第八个bneck输出特征大小一致,然后将这两层特征与第8个bneck融合之后进行一次卷积操作,卷积特征作为第二层检测输出,最后采用focalloss函数改进原yolov3的置信损失函数,采用giouloss函数改进原yolov3的位置损失函数;
(2)数据集制作及锚点(anchor)聚类
在生产车间拍摄待检测目标的照片10000张,然后对照片进行标注得到标准的数据集,将物体的类别、位置信息存储在xml文件中,yolov3采用了anchor的方法进行候选框的位置预测,将所建立的数据集的位置边框信息读取到txt文件中,对边框信息进行k-means++聚类得到适合的anchor的个数及大小;
(3)模型训练
用步骤(2)中制作的数据集进行训练,其中8000张是训练集、2000张是测试集,并且在训练之前采用了旋转、增加噪声、缩放、裁剪等方法进行了数据增强,采用keras搭建目标检测模型,在训练时将训练图片大小设置为224*224,批次大小为16,训练论述为800轮,优化器为sgd优化器,学习率设为0.001,并且在训练过程中监测验证集损失的大小,若连续10轮损失函数没有下降则学习率降为原来的0.9倍,并且保存模型权重时,只保存验证集上损失函数最小时的模型权重;
(4)模型调用
将步骤(3)的检测模型移植到车间工控机,把车间相机拍摄照片后首先重整至大小为224×224,然后送入检测模型,对检测模型的输出结果进行非极大值抑制之得到待检测工件的位置及类别。
进一步的,步骤(1)中,focalloss公式如下:
focal_loss(p)=αy(1-p)γlog(p)-(1-α)(1-y)pγlog(1-p)
这里p是yolov3模型所预测的物体的置信值,y是真实的标签置信,有物体的置信为1,无物体的置信为0,α用来平衡正负样本,取α=0.25,γ是一个缩放参数,设置γ=2;
giouloss的公式如下:
其中a,b分别代表预测框与真实框,c为检测框a与预测框b的包围矩形框,a∩b表示预测框a与检测框b的交集面积,a∪b表示预测框a与检测框b的并集面积。
有益效果:
针对产品特征检测过程中的光污染问题,本发明提出了采用深度学习的方法进行产品特征检测,针对深度学习目标检测方法模型参数多、运行速度慢的问题,本发明提出了应用轻量卷积代替目标检测模型中的卷积,并且又对模型的损失函数进行改进使得模型的检测速度、精度都有所改善,满足生产车间需求;另外建立产品特征的数据集,并且对数据集进行k-means++聚类得到了适合数据集的锚点,经过训练得到了产品特征检测模型,该模型相比于传统的图像处理检测方法受环境的影响更小,在光照过亮、过暗等光污染情况下都能取得很好的检测效果,而且改进后的模型能对车间工控机的硬件配置要求更低,不需要昂贵的gpu,在生产车间测试,该方法能够满足精度与速度要求。
附图说明
图1为本发明改进yolov3结构图。
具体实施方式
下面结合实施例及附图,对本发明作进一步地的详细说明,但本发明的实施方式不限于此。
本发明为了解决产品特征检测时受光照影响大,在光污染的情况下容易检测失败的问题,采用了基于深度学习的目标检测方法yolov3,并对深度学习目标检测方法yolov3进行改进得到满足车间生产要求,主要的技术方案如下:
1、yolov3卷积结构改进
yolov3的基础卷积层是darknet53,虽然该网络结构的运行速度已经很快,但是在生产车间的工控机上硬件配置较差,一般没有配置gpu,该网络在工控机上仍然存在着模型参数多、计算量大、检测速度慢的问题,为了减少yolov3的模型参数,提高运行速度。本发明采用了mobilenetv3-small作为特征提取的卷积层,代替了yolov3的darknet53卷积层,并且也采用特征金字塔结构,做多层输出做预测,为了进一步加快检测速度,且考虑到车间检测工件的尺寸大小,本发明只采用了两层输出预测。如图1所示,本发明将mobilenetv3-small的第11个bneck输出特征进行卷积之后作为一层检测输出,之后将第11个bneck上采样,将第3个bneck输出特征重整至与第8个bneck输出特征大小一致,然后将这两层特征与第8个bneck融合之后进行一次卷积,之后作为第二层检测输出。
2、损失函数改进
为了进一步提升模型的检测精度本发明在替换卷积层的同时又对损失函数进行了改进,首先我们采用了focalloss方法解决了单阶段目标检测方法yolov3正负样本不均衡的问题,然后采用新的边框回归方法广义交并比损失(generalizedintersectionoverunionloss,giouloss)代替原来的边框回归损失,与原来的位置损失函数相比,giou直接把评定标准iou作为损失函数进行优化。
优化损失函数的后的模型相比上一步于只替换卷积层的模型,检测精度提升了0.2%。与yolov3相比检测精度仅下降了0.3%。
focalloss公式如下:
focal_loss(p)=αy(1-p)γlog(p)-(1-α)(1-y)pγlog(1-p)
这里p是yolov3模型所预测的物体的置信值,y是真实的标签置信,有物体的置信为1,无物体的置信为0,α用来平衡正负样本,本发明使用α=0.25,γ是一个缩放参数,设置γ=2。
giouloss的公式如下:
其中a,b分别代表预测框与真实框,c为检测框a与预测框b的包围矩形框。a∩b表示预测框a与检测框b的交集面积,a∪b表示预测框a与检测框b的并集面积。
3、数据集制作及锚点(anchor)聚类
基于深度学习的目标检测方法需要专门的数据集。本发明在生产车间拍摄待检测目标的照片10000张,然后对照片进行标注得到标准的数据集,将物体的类别、位置信息存储在xml文件中。10000张数据中8000张作为训练集,2000张作为测试集。yolov3采用了anchor的方法进行候选框的位置预测,该方法相比于直接回归预测框检测效果更好。对于不同的数据集我们都要先进行聚类得到适合的锚点。这是因为,采用聚类后anchor的大小和真实的物体大小更一致。在训练的过程中更容易回归,模型训练更快。本发明将所建立的数据集的位置边框信息读取到txt文件中,由于k-means++聚类算法相比于k-means聚类更稳定,本发明对边框信息进行k-means++聚类得到适合的anchor的个数及大小。
4、模型训练
用3中制作的数据集进行训练。其中8000张是训练集、2000张是测试集。并且在训练之前采用了旋转、增加噪声、缩放、裁剪等方法进行了数据增强。目前常用的深度学习框架有tensorflow,keras,pytorch等。由于keras简单方便,本发明采用keras搭建目标检测模型。在训练时,考虑到硬件配置,本发明将训练图片大小设置为224*224,批次大小为16,训练论述为800轮,优化器为sgd优化器,学习率设为0.001,并且在训练过程中监测验证集损失函数大小,若连续10轮损失函数没有下降则学习率降为原来的0.9倍,并且保存模型权重时,我们只保存验证集上损失函数最小时的模型权重。
5、模型调用
在生产线上我们将调用训练好的模型进行检测,由于在训练时我们设置的图片大小为224*224,因此在检测时我们需要将相机拍摄的照片先转换为224*224大小。然后将图片送入模型,检测出的结果先去除置信较低的检测框,然后经过非极大值抑制去除重合较多的检测框,最终得到置信得分高的检测结果。
- 还没有人留言评论。精彩留言会获得点赞!