一种基于语义向量的知识图谱表示学习方法与流程
本发明涉及知识图谱、表示学习、语义信息等领域,特别给出了一种基于语义向量的知识图谱表示学习方法。
背景技术:
知识图谱表示学习旨在通过构建连续低维的向量表示空间,将所有实体及关系映射到该空间并保留其原有属性,使得大批高效数值化计算与推理方法得以适用,更好地解决数据稀疏及计算低效性问题,对知识图谱补全和推理等具有重要意义。
基于翻译的表示学习模型transe(annualconferenceonneuralinformationprocessingsystems,2013)是近年来提出的一种重要的表示学习方法,该模型将关系r看成是从头实体h翻译成尾实体t的平移向量,使得h+r≈t,模型简单高效,但是,该模型无法处理1-n、n-1和n-n的复杂关系,例如,(美国,总统,奥巴马)和(美国,总统,特朗普)两个三元组,关系“总统”属于1-n的复杂关系,若用transe对这两条三元组进行知识表示,由于它们拥有相同的头实体和关系,根据h+r≈t,导致“奥巴马”和“特朗普”的向量完全相同,但这并不符合事实。
在transe模型的基础上,研究者们提出一些改进算法。transh(aaaiconferenceonartificialintelligence,2014)模型对于每个关系r,同时使用平移向量r’和以wr为法向量的超平面进行建模,并将头实体、尾实体分别映射到关系r的超平面上,事实上实体和关系不应该在同一语义空间中,而超平面的选取也仅仅简单的令r和wr近似正交,但r可能拥有很多超平面。kg2e(acminternationalconferenceoninformationandknowledgemanagement,2015)认为不同的实体和关系可能包含不同的确定性,每个实体/关系都用高斯分布表示,其中均值表示其位置,协方差可以很好地表示其确定性,它可以有效地对实体和关系的不确定性进行建模,但它没有考虑实体的类型和粒度。teke(internationaljointconferenceonartificialintelligence,2016)模型基于文本语料构建单词与实体的共现网络以得到实体描述信息,关系描述信息是所在三元组头实体和尾实体的描述信息交集,因此关系在不同三元组中有不同表示,解决了知识图谱复杂关系建模问题,但该方法涉及的文本单词过多,导致训练时间过长。ckge(patternrecognition,2018)模型用灵活的采样策略生成邻居上下文,将实体邻居上下文与词文本上下文进行类比,借助skip-gram学习知识图谱结构信息的向量表示。kec(knowledge-basedsystems,2019)模型基于概念图中实体的常识性概念,将实体及实体概念共同嵌入到语义空间,将损失向量投影到概念子空间,以此度量三元组的可能性。
技术实现要素:
为了能够对复杂的1-n、n-1和n-n关系进行向量表示,并提高向量表示的精确度,本发明提出了一种基于语义向量的表示学习方法,语义向量融合了文本描述语义和上下文语义,丰富了实体和关系的语义信息,提高了知识图谱表示的精确度。
为了解决上述技术问题本发明提供如下的技术方案:
一种基于语义向量的知识图谱表示学习方法,包括以下步骤:
1)融合文本语料库的语义向量构建,过程如下:
(1.1)语料库标注
根据待处理的知识图谱,利用实体标注工具tagme将知识图谱中的实体与语料库中的标题进行链接,得到实体对应的文本描述信息,进一步得到关系对应的文本描述信息,为关系所在三元组中头实体、尾实体的文本描述单词交集;
(1.2)语料库清洗
由于文本描述中存在冗余以及干扰信息,需要对描述信息进行预处理,包括次干化、规范大小写、删除停用词及高频词操作;
(1.3)编码文本描述及微调
利用bert模型对处理好的文本描述信息进行编码得到实体及关系对应的语义向量,由于bert模型包含过于丰富的语义信息和先验知识,需要对得到的语义向量进行微调,并包含降维操作,为:
vei'=veix+b(1)
vri'=vrix+b(2)
其中,vei为实体的向量表示,vri为关系的向量表示,x为768*n的向量矩阵,b是n维的偏移向量,n是实体与关系的向量维度,vei'为微调后实体的向量表示,vri'为微调后关系的向量表示;
接着以vei'和vri'为输入,以vei'(head)+vri'=vei'(tail)为得分函数,利用随机梯度下降法训练得到最终的融合文本描述的实体和关系的语义向量;
2)融合文本语料库及知识图谱上下文的语义向量构建,过程如下:
(2.1)实体及关系的上下文获取
将连通路径长度设为2,得到以该实体为头实体或尾实体的所有路径,该路径经过的所有实体是该实体的上下文信息,获取方法是:
context(ei)={ti|(ei,r,ti)∈t∪(ti,r,ei)∈t}∪{ti|((ei,ri,tj)∈t∩(tj,rj,ti)∈t)∪((ti,ri,ej)∈t∩(ej,rj,ei)∈t)}(3)
其中ei、ti为知识图谱中的实体,ri为知识图谱中的关系,t为知识图谱中的三元组集合,context(ei)为所得到实体的上下文;
关系的上下文是关系所在的三元组中头实体和尾实体的上下文的交集;
(2.2)编码上下文
以融合文本描述的语义嵌入为输入,对实体和关系的上下文进行编码,得到最终融合文本描述和知识图谱上下文的实体与关系的语义嵌入;
实体的最终语义向量vei″为:
关系的最终语义向量vri″为:
其中,n是每个ej或wj的权重,根据它在实体上下文中出现的次数设定,c(ei)是实体上下文,c(eh)是头实体上下文,c(et)是尾实体上下文,vei'和vri'分别是仅融合文本描述的实体和关系的语义向量;
3)语义矩阵的构建,过程如下:
以三元组和关系的语义向量作为输入,得到每个关系对应的语义矩阵,方法是:假设关系r对应的三元组集合中的元素个数为n,则关系r有n个语义向量,由于关系r的语义向量的维数为n,需从n个语义向量中选择n个期望的语义向量,该操作通过k-means聚类算法来实现,最后利用选定的语义向量构建语义矩阵;
4)建模与训练,过程如下:
设计了一个新的得分函数对知识图谱中实体和关系的嵌入表示进行建模,得到所述知识图谱的嵌入表示模型,为:
fr(h,t)=||h⊥+r⊥mr-t⊥||l1(6)
其中,h⊥、r⊥、t⊥分别为头实体、关系、尾实体对应的语义向量,mr为每个关系对应的语义矩阵;
对h⊥、r⊥、t⊥的范式添加约束,对任意h⊥、r⊥、t⊥,令:
||r⊥mr||2≤1,||h⊥||2≤1,||t⊥||2≤1,||r⊥||2≤1(7)
然后,使用随机梯度下降法训练所述嵌入表示模型,使得损失函数的值最小化,得到最终知识图谱中实体和关系的语义向量,为:
其中,[x]+为max{0,x},γ为margin,s为正三元组集合,s’为负三元组集合。
本发明的有益效果是:本发明给出的表示学习模型能够充分利用语料库文本描述以及知识图谱上下文构建实体语义向量和关系语义向量,从而深度扩展知识图谱的语义结构,从语义角度将知识图谱中实体间的复杂关系转化为精确的简单关系,能够对复杂关系进行表示学习,并提高向量表示的精确度。
附图说明
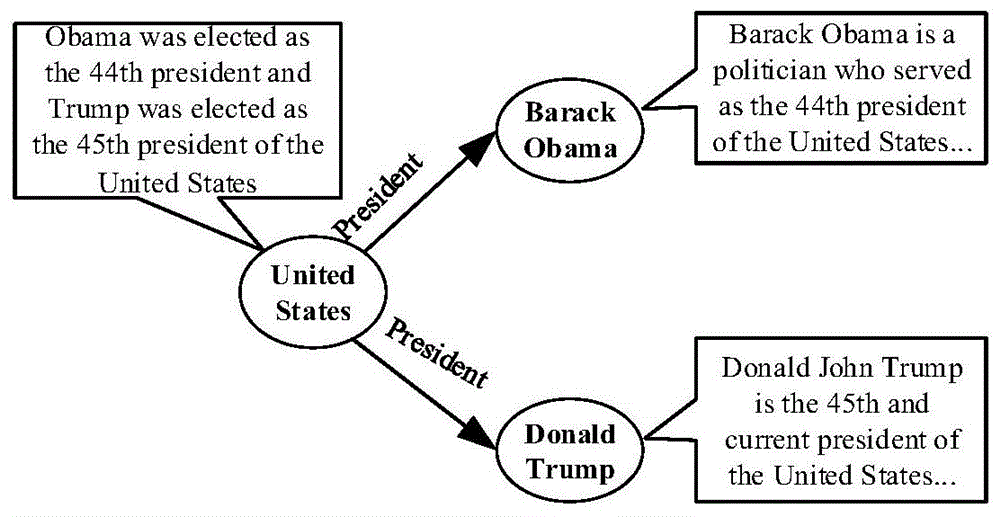
图1是已标注语义信息的知识图谱示例。
图2是含有上下文的简单知识图谱示例。
图3是本发明的算法框架图。
具体实施方式
下面结合附图对本发明的作进一步说明。
参照图1、图2和图3,一种基于语义向量的知识图谱表示学习方法,包括以下步骤:
1)融合文本语料库的语义向量构建,过程如下:
(1.1)语料库标注
根据待处理的知识图谱,使用实体标注工具将知识图谱中的实体链接到外部语料库,得到实体对应的文本描述信息,进一步得到关系的文本描述,其中,实体标注工具可为tagme或wikify;如图1所示,存在两个三元组(unitedstated,president,barackobama)和(unitedstated,president,donaldtrump),利用实体标注得到的实体unitedstated/barackobama/donaldtrump的文本描述分别为obamawaselectedasthe44thpresidentandtrumpwaselectedasthe45thpresidentoftheunitedstates/barackobamaisapoliticianwhoservedasthe44thpresidentoftheunitedstates/donaldjohntrumpisthe45thandcurrentpresidentoftheunitedstates;而关系president在两条三元组中的文本描述是不同的,在前者中表示为实体unitedstated和实体barackobama的文本描述的单词交集,即44thpresident,而在后者中表示为实体unitedstated和实体donaldtrump的文本描述的单词交集,即45thpresident;
(1.2)语料库清洗
将实体对应的描述信息进行预处理,包括次干化、规范化大小写、删除停用词及高频词操作,其中,次干化算法可用porterstemmer或lancasterstemmer,将所有单词中的大写字母统一处理成小写,比如unitedstates被处理成unitedstates,删除在停用词表中出现的单词以及频率过高且无实际意义的单词;
(1.3)编码文本描述及微调
利用bert模型对处理好的文本描述信息进行编码得到实体及关系对应的语义向量,由于bert模型包含过于丰富的语义信息和先验知识,需要进一步对得到的语义向量进行微调,其中包含降维操作,并借助transe的得分函数以及随机梯度下降法对上述实体和关系的语义向量进行微调;
2)融合文本语料库及知识图谱上下文的语义向量构建,过程如下:
(2.1)实体及关系的上下文获取
获取实体上下文,将连通路径长度设为2,得到以该实体为头实体或尾实体的所有路径,该路径经过的所有实体则为该实体的上下文信息;例如,图2中实体a的上下文为:context(a)={a,b,c,e,f},实体b的上下文为:context(b)={a,b,c,d,f,h};
获取关系上下文,关系的上下文具体为该关系所在的三元组中头实体、尾实体的上下文交集。例如,图2中关系r1的上下文为context(r1)={a,b,c,f};
(2.2)编码上下文
以融合文本描述的语义嵌入为输入,对实体和关系的上下文进行编码,得到最终融合文本描述和知识图谱上下文的实体与关系的语义嵌入;
3)语义矩阵的构建,过程如下:
以三元组和关系的语义向量作为输入,得到每个关系对应的语义矩阵,该语义矩阵包含同一关系的所有语义;例如,图1中关系“president”对应的三元组个数为2,则关系“president”有2个语义向量,假设语义向量的维数为1,我们则需要从这2个语义向量中选择1个期望的语义向量,并且该语义向量应同时包含语义“44thpresident”与“45thpresident”,该操作通过k-means聚类算法来实现,最后利用选定的语义向量构建语义矩阵;
4)建模与训练,过程如下:
根据本发明所设计的新得分函数对知识图谱中实体和关系的嵌入表示进行建模,得到所述知识图谱的嵌入表示模型;使用随机梯度下降法训练所述嵌入表示模型,使损失函数的值最小化,得到最终的知识图谱中实体和关系的语义向量。
- 还没有人留言评论。精彩留言会获得点赞!