一种基于WordNet和IDF的非结构化文本的实体关系分类方法与流程
本发明涉及文本挖掘和深度学习
技术领域:
,是一种在远程监督学习下基于wordnet和idf的非结构化文本的实体关系分类方法,可应用于构建知识图谱、开发问答系统,以及信息检索系统等具体领域。
背景技术:
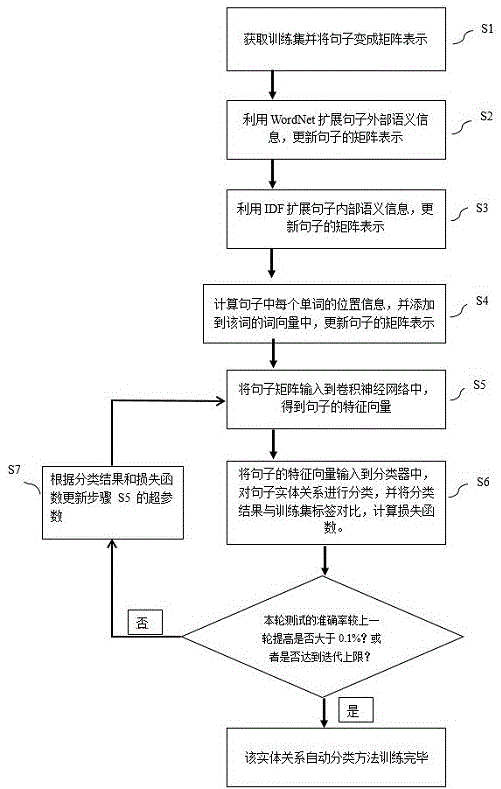
:实体关系抽取是信息抽取领域最重要的子课题之一,是在实体识别的基础上从非结构化文本中抽取出预先定义的实体间的语义关系。根据对标注数据的依赖程度,实体关系抽取方法可分为有监督关系抽取、半监督关系抽取、无监督关系抽取和远程监督关系抽取。有监督关系抽取将关系抽取任务当作关系分类问题,根据训练数据设计合适的特征,从而学习各种分类模型,然后使用训练好的分类器预测关系。半监督关系抽取采用自助抽样法进行关系抽取,首先人工设定种子实例,然后迭代地从数据中抽取关系对应的关系模版和更多的实例。无监督关系抽取假设拥有相同语义关系的实体对拥有相似的上下文信息,然后利用每个实体对上下文信息来代表该实体对的语义关系,并对所有实体对的语义关系进行聚类。远程监督方法是一种使用远程知识库对齐朴素文本的标注方法,可以进行自动标注数据,从而避免人工构建语料库。此方法假设只要一个句子里包含知识库中的两个实体,那么句子中两实体的关系一定是知识库中定义的关系。这种强假设条件会产生大量的错误标签,对于大量错误标签的过滤成为该研究方法的重点。现有的过滤方法总体上分为三种,其一是采用多示例学习(multipleinstancelearning,mil)的方式从训练集中抽取置信度高的训练样例结合分段卷积神经网络(piece-wiseconvolutionalneuralnetwork,pcnn)进行标签过滤。其二是采用pcnn结合注意力机制(attention)为标签正确的示例句子分配较高权重,标签错误的示例句子分配较低权重。其三是在pcnn和attention的基础上添加了实体的描述信息来辅助学习实体的表示。综上,当前远程监督下的关系抽取方法,主要解决远程监督自动生成标注训练集的过程中由于引入强假设条件,导致大量数据的关系被标注错误,使得训练数据存在大量噪声的问题。技术实现要素:本发明提出了一种基于认知语言学的英文词典(wordnet)和逆文档频率(inversedocumentfrequency,idf)的非结构化文本实体关系分类方法,使用外部信息和内部信息对实体及句子进行语义扩展,然后利用分段卷积神经网络提取定长的语义特征向量,用于训练分类器,最后可以对非结构化文本的实体关系进行分类。为达到上述目的,本发明采用如下技术方案:一种基于wordnet和idf的非结构化文本的实体关系分类方法,包括以下步骤:步骤1、获取非结构化的文本训练集,对数据集中的每个句子进行预处理之后,利用word2vec得到句子的矩阵表示;步骤2、利用wordnet扩展句子外部语义信息,更新句子的矩阵表示;步骤3、利用idf扩展句子内部语义信息,更新句子的矩阵表示;步骤4、计算句子中每个单词的位置信息,并将其加入到该词的词向量中,更新句子的矩阵表示;步骤5、将步骤4得到的句子矩阵输入到分段卷积神经网络pcnn中,得到句子的特征向量;步骤6、将步骤5的句子特征向量输入到分类器中,对句子的实体关系进行分类,并将分类结果与训练集标签对比,计算损失函数;步骤7、若本轮测试的准确率较上轮提高大于0.1%或者达到训练次数上限,则该实体关系自动分类方法训练完毕;否则,根据分类结果和损失函数更新步骤5中的超参数,继续迭代训练。所述步骤1中的对数据集进行预处理,并得到句子的矩阵表示,其过程如下:(1-1)预处理:获取数据集后,利用freebase标准知识库标注出数据集中每个句子的两个实体间的关系;标注完成后数据集表示为d={d1,d2,…,di,…,dg},其中di为数据集中的每一个句子,di={t1,t2,…,e1,…,e2,…,tf},ti表示句子中的每个单词,e1和e2是句子的两个实体,f代表句子中单词的数量;(1-2)生成句子矩阵:对数据集中d的每个句子di,利用word2vec找出其每个单词的向量表示并将其组成映射矩阵:xi={w1,w2,…,wi,…,wh},其中wi={v1,v2,…v50}是句子中每个单词的向量表示,每个词向量的维度为50。所述步骤2中利用wordnet扩展句子外部语义信息,更新句子的矩阵表示,其过程如下:(2-1)对数据集中所有句子进行外部语义分析:将句子di中的实体e1和e2输入到wordnet字典中,分别获取其上位词集合,并利用word2vec进行向量化表示,得到和其中m为e1的上位词个数,n为e2的上位词个数;计算每个上位词集合的平均向量wout来代表其实体的外部信息,具体计算公式为:其中,k取m时,wi是中每个词的向量,公式(1)得出的wout为实体e1的平均向量wout1;k取n时,wi是中每个词的向量,公式(1)得出的wout为实体e2的平均向量wout2;(2-2)更新句子矩阵:将e1和e2计算出的两个平均向量wout1和wout2拼接到句子xi中,更新后的句子矩阵:xi={w1,w2,…,wj,wout1,wout2}。所述步骤3中利用idf扩展句子内部语义信息,更新句子的矩阵表示,其过程如下:(3-1)计算idf:将数据集d中的每个句子di看成一篇文章,整个数据集看成一个文本库,计算出句子中每个单词的idf,公式为:其中,表示句子中第i个词的idf,|d|是训练集中的句子总数,|{j:ti∈dj}|表示包含单词ti的句子总数;将句子di中计算出的k个idf使用softmax进行归一化操作,公式为:其中,是归一化后每个单词的idf,k是一个句子中单词总数;(3-2)更新句子矩阵:将上一步中得到的k个idf值拼接到每个单词向量wi={v1,v2,…v50}末尾,将词向量变为51维:所述步骤4中计算句子中每个单词的位置信息,并添加到该词的词向量中,更新句子的矩阵表示,其过程如下:(4-1)计算单词位置信息:计算句子中每个词分别到实体e1和e2的距离,如:中,w1到实体的位置距离为dis1,到实体的位置距离为dis2;(4-2)更新句子矩阵:将上一步得到的dis1和dis2编码进入w1的词向量中,句子矩阵中的单词向量w1更新,更新后所述步骤5中将句子矩阵输入到分段卷积神经网络中,得到句子的特征向量,其过程如下:(5-1)输入层:将步骤(4-2)得到的句子矩阵进行分段标记,以两个实体e1和e2为界限分为3段,e1前面部分的单词全部标记为1;e1和e2之间的单词全部标记为2;e2之后的单词标记为3;(5-2)卷积层:卷积神经网络第二层将步骤(5-1)的输出当作输入进行二维卷积运算,提取局部卷积特征,由多个卷积核同时进行特征提取,最终获得多个向量;具体做法是用一个跨度为l的滑动窗口在句子矩阵上每次取一段单词序列q,然后与卷积矩阵w做运算,计算公式为:pi=[wq+b]i(4)其中,q为滑动窗口从句子矩阵中取到的固定大小的词序列矩阵,b为偏置矩阵;(5-3)池化层:卷积神经网络中的第二层使用piece-wisemaxpooling,句子经过卷积层之后,进入池化层,池化层能够组合所有卷积层得到的局部特征,以获得固定大小的向量,计算公式为:[r]ij=max(pij)(5)其中,pij表示的是第i个卷积核的第j段的向量,其中j的取值范围为1,2,3,在此段中得到其中最大的一个值;将所有卷积核都做完分段池化之后,将结果进行一个非线形的变换最终得到一个句子的特征提取之后的向量表示;非线性变换采用relu函数,公式为:(5-4)输出层:池化层的输出结果就是句子的特征向量,用ri表示。所述步骤6中将句子特征向量输入到分类器中,对句子的实体关系进行分类,并将分类结果与训练集标签对比,计算损失函数,其过程如下:(6-1)先对特征向量ri进行调整,得到该向量与每一种关系的关联程度,计算公式为:oi=rir+b(7)其中,r是所有既定关系矩阵的向量表示,b是偏置向量,oi={o1,o2,…,oj};(6-2)使用softmax更新步骤(6-1)的输出oi,计算公式为:其中,oi是训练集中每一个句子的最终输出,其每一维变成0到1之间的值,表示该句子属于对应类别的概率,nr为oi的维度,也即是类别数量;(6-3)使用损失函数计算预测结果与标签的差值,计算公式为:其中,k是训练集的句子总数,θ表示本模型所有需要更新的超参数。所述步骤7中若本轮测试的准确率较上轮提高大于0.1%或者达到迭代上限,则该实体关系自动分类方法训练完毕;否则,根据分类结果和损失函数更新步骤5中的超参数,继续迭代训练;其过程如下:(7-1)以标签作为训练集实体关系分类的标准,计算本轮训练结果中,其关系预测正确的句子占训练集所有句子的比例作为准确率;(7-2)训练次数上限设置为η,当训练次数到达上限η或者本轮训练准确率较上一轮提高小于0.1%时,该实体关系自动分类方法训练结束;否则,更新步骤5分段卷积神经网络pcnn中所有超参数θ,并在pcnn中输入训练集继续训练,其超参数更新公式为:与现有技术相比,本发明具有如下突出的实质性特点的显著的优点:本发明所述方法与其他在pcnn和添加实体描述信息等方法相比,通过wordnet获取实体语义信息,并通过idf获取句子的内部结构信息当作该句子的背景信息,能更加准确地表达实体和关系的语义特征,缓解训练集数据噪声过大的问题。附图说明图1为基于wordnet和idf的非结构化文本实体关系分类方法流程图。图2为使用wordnet和idf提取句子中词语信息进行拼接。图3为使用pcnn提取一个句子特征信息的过程。具体实施方式为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。本发明提出了一种基于wordnet和idf的非结构化文本的实体关系分类方法,使用外部信息和内部信息向量对实体及句子进行语义扩展,然后利用分段卷积神经网络提取定长的语义特征向量,用于训练分类器,最后可以对非结构化文本的实体关系进行分类。本发明的基本特征主要有以下几个方面:一是将句子向量化之后,在向量中添加实体的外部信息,以及内部信息和句子结构信息;二是使用卷积神经网络来提取句子的特征信息;三是使用分段池化对卷积后的向量进行采样。请参阅图1的关系分类方法流程图,该过程的具体实施步骤如下:步骤1、获取非结构化的文本训练集,对数据集中的每个句子进行预处理之后,利用word2vec得到句子的矩阵表示;(1-1)预处理过程:下载google公布的《纽约时报》标注数据集作为训练集,下载地址:http://t.cn/rpsjayl。利用freebase知识图谱中标注的实体以及实体间对应关系,在语料集中进行回标。过程是:如果训练集中某个句子的两个实体在freebase中标注过属于某种特定关系,那么就假定这个句子的实体关系就是这种特定关系,这样就将训练集中的所有句子打上了关系标注,完成了训练集的创建。训练集一共包括522611个句子,281270个实体对和18252个关系实例。(1-2)生成句子矩阵:上一步中数据集表示为d,d={d1,d2,…,di,…,dg},其中di为数据集中的每一个句子,g=522611。其中di={t1,t2,…,e1,…,e2,…,tf},ti表示句子中的每个单词,e1和e2是句子的两个实体,f代表句子中单词的数量。对数据集中的每个句子,利用word2vec工具找出其每个单词的向量表示并将其组成映射矩阵,即:xi={w1,w2,…,wi,…,wh},h的取值118,若原句子总词数f大于118,丢弃超出的单词;若f小于118,空缺的单词向量则用零向量填充。其中wi是句子中每个单词的向量表示,wi={v1,v2,…v50},每个词向量的维度为50。最后句子矩阵维度:步骤2:利用wordnet扩展句子外部语义信息,更新句子的矩阵表示。具体过程如下:(2-1)对数据集中所有句子进行外部语义分析:将句子di中的实体e1和e2输入到wordnet字典中,分别获取其上位词集合,并利用word2vec进行向量化表示,得到m为e1的上位词个数,和n为e2的上位词个数。计算每个上位词集合的平均向量来代表其实体的外部信息,具体计算公式为:其中,k取m时,wi是中每个词的向量;k取n时,wi是中每个词的向量。(2-2)更新句子矩阵:将e1和e2计算出的两个平均向量wout1和wout2拼接到句子xi中,更新后的句子矩阵:xi={w1,w2,…,wj,wout1,wout2},句子矩阵的维度:步骤3:利用idf扩展句子内部语义信息,更新句子的矩阵表示。具体过程如下:(3-1)计算idf:将数据集d中的每个句子di看成一篇文章,整个数据集看成一个文本库,计算出句子中每个单词的idf,公式为:其中,表示句子中第i个词的idf,|d|是训练集中的句子总数,|{j:ti∈dj}|表示包含单词ti的句子总数。然后将句子di中计算出的k个idf使用softmax进行归一化操作,公式为:其中,是归一化后每个单词的idf,k是一个句子中单词总数。(3-2)更新句子矩阵:将上一步中得到的k个idf值拼接到每个单词向量wi={v1,v2,…v50}末尾,将词向量变为51维:外部信息和内部信息的拼接过程见图2。步骤4:计算句子中每个单词的位置信息,并将其加入到该词的词向量中,更新句子的矩阵表示。具体过程如下:(4-1)计算单词位置信息:计算句子中每个词分别到实体e1和e2的距离,如:中,w1到实体的距离为3,到实体的距离为6,所以词w1的位置信息分别为3和6。(4-2)更新句子矩阵:将上一步得到的3和6编码进行w1的词向量中,句子矩阵中的单词向量w1更新,更新后句子矩阵维度:步骤5:将步骤4得到的句子矩阵输入到pcnn中,得到句子的特征向量,见图3所示:(5-1)输入层:将上一步得到的句子矩阵进行分段标记,以两个实体e1和e2为界限分为3段,e1前面部分的单词全部标记为1;e1和e2之间的单词全部标记为2;e2之后的单词标记为3。用零向量填充的单词标记为0。(5-2)卷积层:卷积神经网络第二层将第一层的输出当作输入进行二维卷积运算,提取局部卷积特征,由多个卷积核同时进行特征提取,最终获得多个向量。具体做法是用一个跨度为l的滑动窗口在句子矩阵上每次取一段单词序列q,然后与卷积矩阵w做运算,计算公式为:pi=[wq+b]i(4)其中,q为滑动窗口从句子矩阵中取到的固定大小的词序列矩阵,b为偏置矩阵。(5-3)池化层:卷积神经网络中的第二层使用piece-wisemaxpooling,句子经过卷积层之后,进入池化层,池化层能够组合所有卷积层得到的局部特征,以获得固定大小的向量。计算公式为:[r]ij=max(pij)(5)其中,pij表示的是第i个卷积核的第j(j的取值范围为1,2,3)段的向量,在此段中得到其中最大的一个值。将所有卷积核都做完分段池化之后,将结果进行一个非线形的变换最终得到一个句子的特征提取之后的向量表示。非线性变换采用relu函数,公式为:(5-4)输出层:池化层的输出结果就是句子的特征向量,用ri表示。步骤6:将上一步得到的句子特征向量输入到分类器中,对句子的实体关系进行分类,并将分类结果与训练集标签对比,计算损失函数。具体过程如下:(6-1)先对特征向量ri进行一些调整,得到该向量与每一种关系的关联程度,计算公式为:oi=rir+b(7)其中,r是所有既定关系矩阵的向量表示,b是偏置向量,oi={o1,o2,…,oj,o53}。(6-2)使用softmax将单个句子的输出oi的每一维映射为0到1之间的值,每一维的值就表示该句子属于该关系的概率。计算公式为:其中,oi是训练集中每一个句子的最终输出,nr为标签总数,值为53。(6-3)使用损失函数计算预测结果与标签的差值,计算公式为:其中,k是训练集的句子总数,θ表示本模型所有需要更新的超参数。步骤7、若本轮测试的准确率较上轮提高大于0.1%或者达到训练次数上限,则该实体关系自动分类方法训练完毕;否则,根据分类结果和损失函数更新步骤5中的超参数,继续迭代训练。其过程如下:(7-1)以标签作为训练集实体关系分类的标准,计算本轮训练结果中其关系预测正确的句子占训练集所有句子的比例作为准确率。(7-2)训练次数上限设置为η,当训练次数到达上限η或者本轮训练准确率较上一轮提高小于0.1%时,该实体关系自动分类方法训练结束。否则,更新步骤5分段卷积神经网络pcnn中超参数θ并在pcnn中输入训练集继续训练,其超参数更新公式为:实验说明及结果:训练集为步骤(1-1)所述的《纽约时报》标注数据集。测试集同样是google公布的《纽约时报》标注数据集,测试集包括172448个句子,96678个实体对和1950个关系。表1显示不同的训练方法在测试集上的对比结果。表1测试结果p@n(%)100200300平均cnn71.370.164.568.6pcnn79.272.169.173.5random+pcnn77.274.170.874.0wordnet+pcnn81.277.174.477.6idf+wordnet+pcnn80.878.276.578.1其中,指标p@n表示前n条数据的准确率;cnn表示使用卷积神经网络作为训练模型;pcnn表示使用分段卷积神经网络作为训练模型;random+pcnn中random表示的是加入随机的句子外部信息然后使用pcnn进行训练的方法;wordnet+pcnn中wordnet表示从wordnet中获取的句子的外部信息然后使用pcnn进行训练的方法;idf+wordnet+pcnn是本发明使用的方法,通过wordnet和idf分别获取句子外部和内部信息,而后使用pcnn进行训练的实体分类方法。可以看出,本发明方法在p@200和p@300下准确率最高,并且平均准确率达到78.1%,比其他方法分别高出9.5个百分点、4.6个百分点、4.1个百分点以及0.5个百分点。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1