一种基于ERNIE的远程监督关系抽取的降噪方法与流程
本发明涉及自然语言处理
技术领域:
,尤其涉及一种基于ernie的远程监督关系抽取的降噪方法。
背景技术:
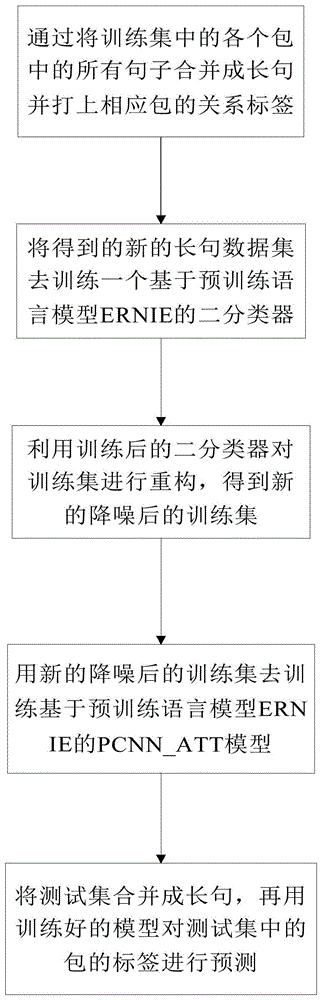
:关系抽取是信息抽取中的一个基本任务,研究的是如何预测句子中实体对之间的语义关系。关系抽取的一个关键问题是相对缺乏大规模的高质量的标注数据。近年来,应对这一挑战的常用而有效的方法是利用远程监督实现通过语料与知识库对齐来获取训练数据的方法,即假设知识库中存在某一个实体对,那么语料中所有含有这个实体对的句子都被标记为此实体对在知识库中对应的关系。远程监控策略是一种有效的大规模训练数据自动标注方法。远程监督关系抽取被广泛应用于寻找新的关系文本中的事实。然而,由于一句话中提到两个实体并不一定表示两者之间的关系情况,因此远程监督不可避免地存在着错误的标签问题,这些问题中的噪音数据会严重影响关系抽取的性能。大量关于处理远程监督的噪声数据的研究工作已经取得重大进展,特别是近年来用于关系抽取的深度神经网络的快速发展给处理噪声工作带来了质的飞跃,但是在处理噪声的实验结果仍然有待提升。基于深度学习远程监督的多实例学习的框架已成为取代了基于特征和图模型的最先进的统计方法。在远程监督的多实例学习框架中,每个实体通常对应有多个实例,其中一些实例是噪音,通常情况下知识库中关系为na的实体对对应的包中噪声很少,可以忽略不计,因此降噪工作主要是处理关系为非na的包中的噪声,由于在真实语料中大多数实体关系是na,所以主要处理的噪声是假正性噪声。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种基于ernie的远程监督关系抽取的降噪方法。本发明通过重构训练集来进行有效地去除包中的假正性噪声数据,并通过结合注意机制和深度神经网络来达到比较好的关系抽取的效果。本发明的目的能够通过以下技术方案实现:一种基于ernie的远程监督关系抽取的降噪方法,包括步骤:通过将训练集中的各个包中的所有的句子合并成长句并打上相应包的关系标签;将得到的新的长句数据集去训练一个基于预训练语言模型ernie的二分类器;利用训练后的二分类器对训练集进行重构,得到新的降噪后的训练集;用新的降噪后的训练集去训练基于预训练语言模型ernie的pcnn_att模型;将测试集合并成长句,再用训练好的模型对测试集中的包的标签进行预测。具体地,所述关系标签为na和notna这两种关系标签。具体地,利用训练后的二分类器对训练集中标签为非na的包中的句子进行分类,如果分类结果为na则去除这个句子,即去除训练集中标签为非na的包中的假正性噪声数据。具体地,所述利用重构训练集去训练基于attention机制的pcnn模型的步骤中,利用pcnn作为编码器得到句子级别的向量表示,用attention机制选出包中的对于关系分类的重要句子的信息,得到包级别的向量表示,再通过一个基于ernie的多分类器对当前的包做相应的关系分类。本发明相较于现有技术,具有以下的有益效果:本发明通过两个步骤的降噪来实现远程监督带来的噪声影响,从而达到一个很好的关系抽取的效果。其中第一个步骤的降噪是在远程监督得到的数据集进行降噪,通过合并后的长句去训练一个二分类器,然后利用这个训练好的二分类器对原始训练集进行降噪的操作,从而有效地降低数据集中的假正性噪声。第二个步骤的降噪在于attention机制的使用,在获得包的表示的时候通过给包中不同句子分配不同的权重,实现提升对于分类结果有重要作用句子的权重,从而实现降噪的效果。附图说明图1为本发明中一种基于ernie的远程监督关系抽取的降噪方法的流程图。图2为合并训练集中的包训练一个二分类器对原始训练集去噪过程图。图3为预训练语言模型ernie的训练策略。图4为利用pcnn得到一个句子的向量表示示意图。图5为利用attention机制得到包的向量表示示意图。具体实施方式下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。实施例如图1所示为一种基于ernie的远程监督关系抽取的降噪方法的流程图,所述方法包括步骤:(1)通过将训练集中的各个包中的所有的句子合并成长句并打上相应包的关系标签;所述关系标签为na和notna这两种关系标签。在训练集中,将含有相同的实体对的所有句子组成的集合称为一个包,每个句子都有一个句子的关系标签,而这个句子所属的包的标签就是这个包中所有句子的标签的集合。因为一个包中是可能存在噪声数据的,因此将一个包中所有句子都合并成一个长句这就使得实体对可以反映包的关系。举一个具体的例子:rawbag:sentence_1:2011年5月11日,何勇受邀参加摇滚女星姜昕《长发飞扬的日子》首发式。sentence_2:2007年7月,鄂尔多斯摇滚音乐节上moen效果器大放异彩,何勇及乐队,姜昕及乐队,面孔乐队现场均使用了moen效果器。sentence_3:何勇说:姜昕的这本小说让我想起了我的新歌《记得吗》里的一句歌词。reconstructedlongsentence:何勇,姜昕:2011年5月11日,何勇受邀参加摇滚女星姜昕《长发飞扬的日子》首发式。2007年7月,鄂尔多斯摇滚音乐节上moen效果器大放异彩,何勇及乐队,姜昕及乐队,面孔乐队现场均使用了moen效果器。何勇说:姜昕的这本小说让我想起了我的新歌《记得吗》里的一句歌词。(2)将得到的新的长句数据集去训练一个基于预训练语言模型ernie的二分类器;本实施例不是直接使用预训练的词向量,而是使用预训练语言模型ernie。如图2所示为合并训练集中的包训练一个二分类器对原始训练集去噪过程图。ernie提出了一种多阶段的知识掩蔽策略,将短语和实体层次的知识整合到语言表示中,而不是直接加入知识嵌入。ernie存在三个掩蔽水平,图3中描述了句子的不同掩蔽级别:以句子“harrypotterisaseriesoffanatasynovelswrittenbybritishanthorj.k.rowling.”为例。首先ernie采用了单词级别的掩蔽,即随机掩蔽并预测句子中的某些单词,使得ernie可以捕捉一个句子中的上下文语义。在上述例子中,随机mask即随机掩蔽了harry,of等词,通过随机掩蔽掉一个句子中的词,可以获得这个这个句子的上下文的语义信息,帮助理解整个句子的含义。其次应用了实体级掩蔽策略来捕捉模型中实体对之间的关系,因为通常实体在句子中包含重要信息,而且进行关系抽取任务时主要考虑的也是实体对上下文之间的语义关系。具体做法就是随机掩蔽这个句子中的实体和单词。在上述例子中,掩蔽了实体j.k.rowling,实体的类型包括人名person,地名location,组织名organization,这里的j.k.rowling是一个人名,所以属于一个实体,通过随机掩蔽实体和单词可以获得句子中有关于实体的相关上下文关系,帮助计算机理解和捕捉实体的相关信息,而实体的相关信息对于关系分类来讲至关重要。在短语屏蔽阶段,ernie首先分析句子中的命名实体,然后随机掩蔽句子中存在的短语、实体、单词。在上述例子中掩蔽了短语aseriesof,通过掩蔽短语,可以帮助计算机更好的理解整个句子的不可分割部分的语义信息,即理解短语级别的信息,进一步增强对句子含义的理解。通过三阶段学习使得ernie可以得到丰富的实体对上下文语义关系信息的词性表达。然后在ernie之后接一个二分类器,用步骤1得到的长句训练集来训练这个二分类器。(3)利用训练后的二分类器对训练集进行重构,得到新的降噪后的训练集;将原始训练集分成标签为na和非na的两部分,再利用之前训练好的二分类器对训练集中标签为非na的包中的句子进行分类,如果分类结果为na则从原始训练集中去除这个句子,这样就去除了训练集中标签为非na的包中的假正性噪声数据,将去除假正性噪声数据的关系为非na的包和原始训练集中关系为na的包合并成新的数据集,即得到了新的降噪后的训练集。(4)用新的降噪后的训练集去训练基于预训练语言模型ernie的pcnn_att模型;在关系抽取中,主要的挑战是句子的长度是可变的,重要信息可以出现在句子的任何区域。因此,应该利用所有的局部特征,在全局范围内进行关系预测。在本实施例中,使用卷积层来合并所有这些特征。如图4所示为利用新的训练集训练基于attention机制的cnn模型的示意图,包括步骤:(4-1)利用cnn作为编码器得到各个包中的句子的向量表示;卷积层首先利用步长为l的滑动窗口提取句子的局部特征。在图3示意图中,假设滑动窗口的长度为3,最后获得输入语句的固定大小的向量表示。首先一个句子中第i个词的词向量设为mi∈rd,其中d为词向量的维度,这里m指代一个句子的所有词向量组成的矩阵,n则是一个句子长度。m=(m1,m2......mn)卷积操作定义为长度为滑动窗口大小的句子的词向量序列和卷积核之间的操作,其中,l为窗口大小,d为词向量维度,dc为卷积核个数。向量qi定义为第i个窗口对应的l个词的向量序列,表示为:qi=mi-l+1:i(1≤i≤m+l-1)第i个卷积操作如下:pi=[wq+b]i对于最终句子的向量表示的第i个元素的计算如下:[x]i=max(pi)(4-2)利用attention机制选出包中的对于关系分类的重要句子的信息,即使得同一个包中不同句子分配了不同权重,句子表示的加权求和就得到包级别的向量表示;在学习一个包中所有句子的分布向量表示后,使用句子级注意力机制来选择真正表达对应关系的句子。定义一个包为s,其包含了n个句子即s={x1,x2......xn},这个包对应的关系的向量为r,包中第i个句子对应的权重设为αi,包的向量表示定义为:为了衡量一个句子和包的关系r之间的匹配程度定义下述公式:ei=xiar其中a是一个对角矩阵,xi是包中第i个句子的向量表示。得到一个包中不同句子的权重,计算公式为:如图5所示为利用attention机制得到包的向量表示示意图。(4-3)将得到的包的向量表示输入到一个基于ernie的多分类器中得到最后的关系分类结果。(5)将测试集也用类似方法合并成长句,再用训练好的模型对测试集中的包的标签进行预测。将测试集中的包中的句子合并成一个长句,然后利用得到的基于ernie的多分类器,得到最终测试集的关系分类的预测结果。结合具体示例和实验数据来阐述本方法的实验效果。在本实施例中,采用的数据集是中文人物关系的数据集,共35种人物关系,其中训练集共有287351条句子,一共37948个包。验证集共有共有38417条句子,一共5416个包。测试集共有77092条句子,一共10849个包。实验的超参数设置如下表所示:batch_size64epoch200window_size3leariningrate0.001dropout0.5word_dim300hidden_dim300采用f1值来衡量实验结果的评价指标,其计算公式如下:其中nr是算法正确分类为非na类别的包的个数,nsys是算法分类为非na的包的个数。nstd是数据集种非na的包的个数。实验结果如下表所示:其中最后一个算法是本文提到的降噪算法结合预训练语言模型ernie和attention机制结合pcnn的模型的实验效果。可以看出本文提出的降噪方法使得实验效果得到了显著提升。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1