视频音频识别方法、设备、存储介质及装置与流程
本发明涉及人工智能的技术领域,尤其涉及一种视频音频识别方法、设备、存储介质及装置。
背景技术:
金融场景中在对用户进行真实的校验需求时,需要对用户的数据真实性反复收集再验证真假,以便尽可能提升风控能力,以尽可能的精确评价用户的贷款金融,目标是精准风控。在目前贷款场景中,比较常见都会增加一个身份验证的过程,验证通过后在通过用户在网页或者应用程序(application,app)中输入信息,以进行用户资料的收集,如此繁琐的操作,会导致页面比较多,异常也会增加,用户信息的录入耗时长,对于用户体验也非常差。
上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
本发明的主要目的在于提供一种视频音频识别方法、设备、存储介质及装置,旨在解决现有技术中用户信息的录入操作繁琐导致耗时长的技术问题。
为实现上述目的,本发明提供一种视频音频识别方法,所述视频音频识别方法包括以下步骤:
接收用户输入的目标业务类型,根据所述目标业务类型查找对应的目标业务文案,将所述目标业务文案进行展示;
拍摄所述用户朗读所述目标业务文案的目标视频,通过音视频分离器对所述目标视频进行音频分离,获得目标音频信息;
对所述目标音频信息进行文字识别,获得目标信息;
对所述目标视频进行抽帧处理,获得用户图片;
根据所述用户图片和所述目标信息生成所述用户的目标业务文档。
优选地,所述对所述目标音频信息进行文字识别,获得目标信息,包括:
对所述目标音频信息进行文字识别,获得对应的文本信息;
将所述文本信息与所述目标业务文案进行比对,获得所述文本信息的正确率;
在所述正确率大于预设正确率阈值时,通过正则表达式对所述文本进行信息提取,获得目标信息。
优选地,所述在所述正确率大于预设正确率阈值时,通过正则表达式对所述文本进行信息提取,获得目标信息之后,所述视频音频识别方法包括:
判断所述目标信息是否满足预设规则;
若不满足,则进行提示,以使所述用户重新朗读所述目标业务文案;
若满足,则执行所述对所述目标视频进行抽帧处理,获得用户图片的步骤。
优选地,所述对所述目标视频进行抽帧处理,获得用户图片之前,所述视频音频识别方法还包括:
对所述目标视频进行人脸识别,对识别到的人脸进行活体检测;
在活体检测成功时,执行所述对所述目标视频进行抽帧处理,获得用户图片的步骤。
优选地,所述对所述目标视频进行人脸识别,对识别到的人脸进行活体检测,包括:
对所述目标视频进行人脸识别,对识别到的人脸的眼部区域进行截取,获得眼部区域图像;
通过预设眨眼模型识别所述眼部区域图像是否有眨眼动作;
若识别到所述眼部区域图像有眨眼动作,则认定活体检测成功。
优选地,所述对所述目标视频进行抽帧处理,获得用户图片之后,所述视频音频识别方法还包括:
对所述用户图片进行预处理,获得预处理图片;
根据清晰度对所述预处理图片进行筛选,获得筛选图片;
将所述筛选图片与预设图片进行对比,获得比对结果;
相应地,所述根据所述用户图片和所述目标信息生成所述用户的目标业务文档,包括:
在所述对比结果超过预设相似度阈值时,根据所述筛选图片和所述目标信息生成所述用户的目标业务文档。
优选地,所述拍摄所述用户朗读所述目标业务文案的目标视频,通过音视频分离器对所述目标视频进行音频分离,获得目标音频信息,包括:
播放目标音乐的同时,拍摄所述用户朗读所述目标业务文案的目标视频;
通过音视频分离器对所述目标视频进行音频分离,获得混合音频信息;
通过计算听觉场景分析算法从所述混合音频信息中提取所述用户朗读所述目标业务文案的目标音频信息。
此外,为实现上述目的,本发明还提出一种视频音频识别设备,所述视频音频识别设备包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的视频音频识别程序,所述视频音频识别程序配置为实现如上文所述的视频音频识别方法的步骤。
此外,为实现上述目的,本发明还提出一种存储介质,所述存储介质上存储有视频音频识别程序,所述视频音频识别程序被处理器执行时实现如上文所述的视频音频识别方法的步骤。
此外,为实现上述目的,本发明还提出一种视频音频识别装置,所述视频音频识别装置包括:
查找模块,用于接收用户输入的目标业务类型,根据所述目标业务类型查找对应的目标业务文案,将所述目标业务文案进行展示;
音频分离模块,用于拍摄所述用户朗读所述目标业务文案的目标视频,通过音视频分离器对所述目标视频进行音频分离,获得目标音频信息;
文字识别模块,用于对所述目标音频信息进行文字识别,获得目标信息;
抽帧处理模块,用于对所述目标视频进行抽帧处理,获得用户图片;
生成模块,用于根据所述用户图片和所述目标信息生成所述用户的目标业务文档。
本发明中,通过接收用户输入的目标业务类型,根据所述目标业务类型查找对应的目标业务文案,将所述目标业务文案进行展示,拍摄所述用户朗读所述目标业务文案的目标视频,通过音视频分离器对所述目标视频进行音频分离,获得目标音频信息,通过语音朗读减少手动输入的繁琐步骤;对所述目标音频信息进行文字识别,获得目标信息,对所述目标视频进行抽帧处理,获得用户图片,以对用户身份实现验证;根据所述用户图片和所述目标信息生成所述用户的目标业务文档,基于人工智能,通过解析视频获得多方面的数据,验证用户身份的同时提升用户的信息录入效率。
附图说明
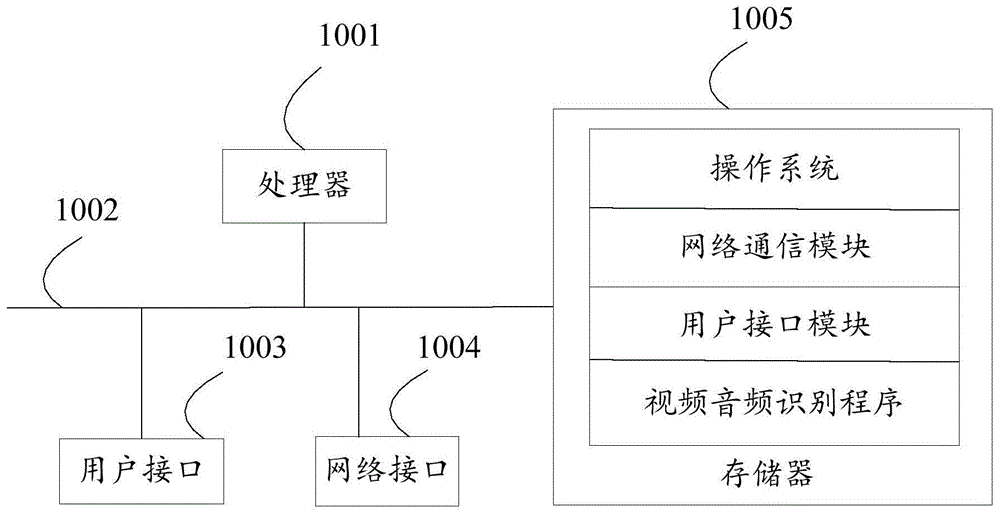
图1是本发明实施例方案涉及的硬件运行环境的视频音频识别设备的结构示意图;
图2为本发明视频音频识别方法第一实施例的流程示意图;
图3为本发明视频音频识别方法第二实施例的流程示意图;
图4为本发明视频音频识别方法第三实施例的流程示意图;
图5为本发明视频音频识别装置第一实施例的结构框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参照图1,图1为本发明实施例方案涉及的硬件运行环境的视频音频识别设备结构示意图。
如图1所示,该视频音频识别设备可以包括:处理器1001,例如中央处理器(centralprocessingunit,cpu),通信总线1002、用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display),可选用户接口1003还可以包括标准的有线接口、无线接口,对于用户接口1003的有线接口在本发明中可为usb接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如无线保真(wireless-fidelity,wi-fi)接口)。存储器1005可以是高速的随机存取存储器(randomaccessmemory,ram)存储器,也可以是稳定的存储器(non-volatilememory,nvm),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图1中示出的结构并不构成对视频音频识别设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及视频音频识别程序。
在图1所示的视频音频识别设备中,网络接口1004主要用于连接后台服务器,与所述后台服务器进行数据通信;用户接口1003主要用于连接用户设备;所述视频音频识别设备通过处理器1001调用存储器1005中存储的视频音频识别程序,并执行本发明实施例提供的视频音频识别方法。
基于上述硬件结构,提出本发明视频音频识别方法的实施例。
参照图2,图2为本发明视频音频识别方法第一实施例的流程示意图,提出本发明视频音频识别方法第一实施例。
在第一实施例中,所述视频音频识别方法包括以下步骤:
步骤s10:接收用户输入的目标业务类型,根据所述目标业务类型查找对应的目标业务文案,将所述目标业务文案进行展示。
应理解的是,本实施例的执行主体是所述视频音频识别设备,其中,所述视频音频识别设备可为智能手机、个人电脑或服务器等电子设备,本实施例对此不加以限制。在网页或者app内,可通过选项呈现各种业务类型,用户选择需要进行的所述目标业务类型,在接收到用户输入的所述目标业务类型时,从预设映射关系表中查找与所述目标业务类型对应的目标业务文案,所述预设映射关系表中包括业务类型与业务文案之间的对应关系。所述目标业务类型包括贷款、租赁或保险等业务,所述目标业务文案为各业务类型需要收集的用户相关信息,比如各业务类型均需采集用户的个人基本信息,如一段个人信息文案:我是xxx,我的身份证件号是xxxxx,我是来自xxx地区等。不同的业务类型还需采集业务类型对应的相关信息,比如贷款业务还需采集如下信息:是否有在还贷款,是否有房产、车子以及年收入多少等信息,可预先按照业务类型建立对应的业务文案,将需要采集的信息以填空形式呈现。
步骤s20:拍摄所述用户朗读所述目标业务文案的目标视频,通过音视频分离器对所述目标视频进行音频分离,获得目标音频信息。
需要说明的是,用户在朗读所述目标业务文案时,可对需要填空的内容结合自己的信息在朗读时进行填充。对所述用户朗读所述目标业务文案的过程进行拍摄,视频录制可通过所述视频音频识别设备的摄像功能进行,比如智能手机的录像功能。在所述网页或者app内有摄像按钮,所述目标业务文案在所述网页或者app内进行展示时,所述业务文案的上方或者下方设置摄像按钮,用户通过点击该摄像按钮,拍摄自己朗读所述目标业务文案的视频,获得所述目标视频。
可理解的是,音频分离通常是将视频的声音和图像分别取出来,分离音频步骤为:设置音频源;获取源文件中轨道的数量,并遍历找到需要的音频轨;对找到的音频轨进行提取,获得所述目标音频信息。
步骤s30:对所述目标音频信息进行文字识别,获得目标信息。
在具体实现中,将所述目标音频信息中首尾端的静音切除,降低对后续步骤造成的干扰。对静音切除后的第一音频信息进行分帧,也就是把所述第一音频信息切开成一小段一小段,每小段称为一帧,分帧操作一般使用移动窗函数来实现。分帧后,所述第一音频信息就变成了很多小段。再将波形作变换,提取梅尔倒谱系数(mel-scalefrequencycepstralcoefficients,mfcc)特征,把每一帧波形变成一个多维向量。接着,把帧识别成状态;把状态组合成音素;把音素组合成单词。若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词,从而获得对应的文本信息,可将所述文本信息中用户填充的内容进行提取,作为所述目标信息。
步骤s40:对所述目标视频进行抽帧处理,获得用户图片。
应理解的是,对所述目标视频实例化的同时进行初始化,获取所述目标视频总帧数并打印,定义一个变量,用来存放存储每一帧图像,循环标志位,定义当前帧,读取所述目标视频每一帧,字符串流,将长整型long类型的转换成字符型传给对象str,设置每10帧获取一次帧,将帧转成图片输出,结束条件,当前帧数大于总帧数时候时,循环停止,输出的图片即为所述用户图片。
步骤s50:根据所述用户图片和所述目标信息生成所述用户的目标业务文档。
需要说明的是,所述用户图片可作为所述用户的身份验证信息,还可对所述音频进行用户的声纹提取,将提取的声纹作用用户的身份标识,并根据声纹进行身份验证。所述目标信息为从用户朗读的文本中提取的关于用户的相关信息,将所述用户图片和所述目标信息结合生成一个资料文档,即为所述目标业务文档,则所述目标业务文档包括用户身份验证信息和所述目标业务类型需要的各种用户信息。
本实施例中,通过接收用户输入的目标业务类型,根据所述目标业务类型查找对应的目标业务文案,将所述目标业务文案进行展示,拍摄所述用户朗读所述目标业务文案的目标视频,通过音视频分离器对所述目标视频进行音频分离,获得目标音频信息,通过语音朗读减少手动输入的繁琐步骤;对所述目标音频信息进行文字识别,获得目标信息,对所述目标视频进行抽帧处理,获得用户图片,以对用户身份实现验证;根据所述用户图片和所述目标信息生成所述用户的目标业务文档,基于人工智能,通过解析视频获得多方面的数据,验证用户身份的同时提升用户的信息录入效率。
参照图3,图3为本发明视频音频识别方法第二实施例的流程示意图,基于上述图2所示的第一实施例,提出本发明视频音频识别方法的第二实施例。
在第二实施例中,所述步骤s30,包括:
步骤s301:对所述目标音频信息进行文字识别,获得对应的文本信息。
应理解的是,对所述目标音频信息进行文字识别,首先,将所述目标音频信息中首尾端的静音切除,再对静音切除后的第一音频信息进行分帧,若干帧语音对应一个状态,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态,构建一个状态网络,从状态网络中寻找与声音最匹配的路径,语音识别过程其实就是在状态网络中搜索一条最佳路径,每三个状态组合成一个音素,若干个音素组合成一个单词,从而获得所述目标音频信息对应的所述文本信息。
步骤s302:将所述文本信息与所述目标业务文案进行比对,获得所述文本信息的正确率。
可理解的是,所述文本信息为用户朗读所述目标业务文案所形成的文本,为了判断所述用户是否朗读了正确的业务文案,以及是否正确进行所述目标业务文案的朗读,可对所述文本信息中的固定内容进行提取,将提取的内容与所述目标业务文案进行对比,可将提取的内容与所述目标业务文案之间的相似度作为所述文本信息的正确率。
步骤s303:在所述正确率大于预设正确率阈值时,通过正则表达式对所述文本进行信息提取,获得目标信息。
需要说明的是,所述预设正确率阈值可根据经验值进行设置,比如80%,在所述正确率大于所述预设正确率阈值时,两者内容相近,即认为所述文本细信息的正确率符合要求,可对所述文本信息进行进一步分析。
在具体实现中,提取特定位置字符串的需求可通过正则表达式实现,具体为:单个位置的字符串提取,可以使用(.+?)这个正则表达式来提取,举例,一个字符串"a123b",如果我们想提取ab之间的值123,可以使用findall配合正则表达式,这样会返回一个包含所以符合情况的列表list,对于提取用户的电话号码和身份证号码等数字即可用该方法进行对应位置的字符串提取而获得。一个字符串”a123b456b”,如果我们想匹配a和最后一个b之间的所有值而非a和第一个出现的b之间的值,可以用?来控制正则贪婪和非贪婪匹配的情况。控制只匹配0或1个,所以只会输出和最近的b之间的匹配情况。连续多个位置的字符串提取,使用(?p<name>…)这个正则表达式来提取,举例,有一行webserver的access日志:'192.168.0.125/oct/2012:14:46:34"get/apihttp/1.1"20044"http://abc.com/search""mozilla/5.0"',想提取这行日志里面所有的内容,可以写多个(?p<name>expr)来提取,其中名称name可以更改成该位置字符串命名的变量,表达式expr改成提取位置的正则即可,从而将所述文本信息中用户朗读时填充的内容进行提取,获得所述目标信息。
进一步地,在本实施例中,所述步骤s303之后,还包括:
判断所述目标信息是否满足预设规则;
若不满足,则进行提示,以使所述用户重新朗读所述目标业务文案;
若满足,则执行所述步骤s40。
应理解的是,预先根据所述目标业务文案填写出的模板资料进行分析,对每一处需要填写的信息均设置对应的规则,比如,电话号码为11位的数字,则所述目标业务文案中电话号码对应的所述预设规则为判断所述电话号码是否为11位的数字,若满足所述预设规则,则可认为所述目标信息中的电话号码的内容正确,若不满足所述预设规则,则可认为所述目标信息中电话号码朗读错误,可进行语音提示,例如,提示电话号码为11位数字,现在朗读的内容位数不正确或者现在朗读的内容多了一位数字等。也可以以文字提示方式进行提示,例如,将所述文本信息中错误的内容标红,并在旁边以文字批注形式提示所述文本信息有误。输入框可以支持修改纠错,以使用户对所述文本信息进行修改。
可理解的是,地区也会预先设置对应的所述预设规则,例如预先录入地图中各个地理位置信息,在所述目标业务文案朗读的内容是地址信息时,判断所述文本信息中的地址信息是否属于预先录入的地理位置信息,若属于,则认为朗读的地址信息正确,若不属于,则认为朗读的地址信息有误。
在本实施例中,通过将语音识别出的所述文本信息与所述目标业务文案进行比对,在正确率大于预设正确率阈值时,通过正则表达式对所述文本进行信息提取,获得目标信息,从而提高信息录入的准确率。
参照图4,图4为本发明视频音频识别方法第三实施例的流程示意图,基于上述第一实施例或第二实施例,提出本发明视频音频识别方法的第三实施例。本实施例基于所述第一实施例进行说明。
在第三实施例中,所述步骤s40之前,还包括:
对所述目标视频进行人脸识别,对识别到的人脸进行活体检测;
在活体检测成功时,执行所述步骤s40。
应理解的是,对所述目标视频进行人脸识别,视频找人跟图片找人原理一样,视频就是图片的集合,本质上还是图片找人,将找到的人和识别到的人脸画上矩形框,实现人脸识别。脸部识别技术(facedetection)负责人脸位置的识别,人脸配准(facealignment)进行人脸对齐,算法是采用仿射变换,根据眼睛坐标进行人脸对齐,使用视觉几何组网络(visualgeometrygroupnetwork,vgg)模型做特征提取,get_feature_new函数打开图片,使用vgg网络提取特征。compare_pic函数对传入的两个特征计算相似度。关键点在于阈值的选取。face_recog_test函数会读取测试图片,计算各组图片最佳的参数。将对齐后的人脸图片保存,作为后续人脸特征比较时使用。使用seetafaceengine或者facealignment进行人脸识别。获取输入图片中的人脸特征。使用opencv的cv2.cascadeclassifier做人脸识别。
进一步地,所述对所述目标视频进行人脸识别,对识别到的人脸进行活体检测,包括:
对所述目标视频进行人脸识别,对识别到的人脸的眼部区域进行截取,获得眼部区域图像;
通过预设眨眼模型识别所述眼部区域图像是否有眨眼动作;
若识别到所述眼部区域图像有眨眼动作,则认定活体检测成功。
可理解的是,对识别到的人脸进行活体检测,检测到的人脸是否发生运动,或,是否眨眼等来判断是否为真实的人,而非照片。首先对人脸检测与眼睛定位;然后眼部区域截取,从归一化处理后的图像中计算眼睛的开合程度;基于卷积神经网络建立用于判断眨眼动作的模型,根据该模型识别图像中是否有眨眼动作。可预先建立待训练的卷积神经网络模型,获取大量的样本图像,对所述样本图像中的人脸眼部区域进行截取,获得样本眼部图像,并获取与各所述样本图像对应的样本眨眼信息,根据所述样本眼部图像与对应的样本眨眼信息对所述待训练的卷积神经网络模型进行训练,获得所述预设眨眼模型,则可通过所述预设眨眼模型对所述眼部区域图像进行识别,若识别到所述眼部区域图像有眨眼动作,则认为所述目标视频中是真实的人,认定活体检测成功。
在本实施例中,所述步骤s40之后,还包括:
步骤s401:对所述用户图片进行预处理,获得预处理图片。
应理解的是,对所述目标视频进行抽帧处理,通常获得多张所述用户图片,则需对所述用户图片进一步处理,以获得质量更好的用户图片,作为所述用户的身份验证信息。可预先对所述用户图片进行预处理,图像预处理的目的是消除图像中无关的信息,尽可能去除或者减少光照、成像系统或外部环境等对图像的干扰,使它具有的特征能够在图像中明显地表现出来。所述预处理过程包括人脸图像的光线补偿、灰度变换、直方图均衡化、归一化、几何校正、滤波以及锐化等处理步骤,从而获得所述预处理图片。
步骤s402:根据清晰度对所述预处理图片进行筛选,获得筛选图片。
需要说明的是,通常所述预处理图片为多张,从中选择清晰度较高的图片进行人脸识别。图像的清晰度是衡量图像质量优劣的重要指标,清晰度的评价可采用二次模糊reblur算法,如果一幅图像已经模糊了,那么再对它进行一次模糊处理,高频分量变化不大;但如果原图是清楚的,对它进行一次模糊处理,则高频分量变化会非常大。因此可以通过对待评测图像进行一次高斯模糊处理,得到该图像的退化图像,然后再比较原图像和退化图像相邻像素值的变化情况,根据变化的大小确定清晰度值的高低,计算结果越小表明图像越清晰,反之越模糊。这种思路可称作基于二次模糊的清晰度算法,具体为将所述预处理图片通过低通滤波,获得模糊图像,计算所述预处理图片中相邻像素灰度值的变化,获得第一像素变化值,并计算所述模糊图像中相邻像素灰度值的变化,获得第二像素变化值,将所述第一像素变化值与所述第二像素变化值进行比较分析,并进行归一化处理,获得清晰度结果,根据所述清晰度结果对所述预处理图片进行筛选,获得所述筛选图片。
步骤s403:将所述筛选图片与预设图片进行对比,获得比对结果。
在具体实现中,对所述筛选图片进行面部特征点定位,获得所述筛选图片对应的待处理人脸特征点;将所述待处理人脸特征点与预设正脸特征点进行比较,获得单应性矩阵;通过所述单应性矩阵对照片中的人脸进行变换,获得校准人脸图片;所述预设图片为公安系统中用户的图片,通过卷积神经网络模型对所述校准人脸图片和公安系统库中的各照片特征进行比对,获得所述筛选图片与各所述预设图片之间的人脸相似度,将所述人脸相似度作为所述比对结果。
相应地,所述步骤s50,包括:
步骤s501:在所述对比结果超过预设相似度阈值时,根据所述筛选图片和所述目标信息生成所述用户的目标业务文档。
可理解的是,将所述人脸相似度作为所述比对结果,若所述人脸相似度超过所述预设相似度阈值,则认为所述用户的身份得到核实,可进一步为该用户建立业务资料。所述预设相似度阈值可根据经验值进行设置,比如40%。做人脸特征的比较,计算人脸相似度,若所述预设相似度阈值设置为0.4,就是说在相似度大于40%,就认为是同一个人,则可根据所述筛选图片和所述目标信息生成所述用户的目标业务文档。
在本实施例中,所述步骤s20,包括:
播放目标音乐的同时,拍摄所述用户朗读所述目标业务文案的目标视频;
通过音视频分离器对所述目标视频进行音频分离,获得混合音频信息;
通过计算听觉场景分析算法从所述混合音频信息中提取所述用户朗读所述目标业务文案的目标音频信息。
应理解的是,为了确保个人信息安全性,在用户朗读所述目标业务文案时,可同时播放所述目标音乐,所述目标音乐能够制造嘈杂的语音环境,避免用户的个人信息被其他人获悉,此时拍摄的所述目标视频中的包括所述目标音乐和所述用户朗读所述目标业务文案的音频。通过音视频分离器对所述目标视频进行音频分离,获得混合音频信息,需要进一步采用计算听觉场景分析(calculationauditorysceneanalysis,casa)算法来模拟人类听觉系统将所述用户朗读的语音从噪声环境中提取出来。会对音频信息进行编码从而实现分组和解析。目前有几十种分组依据涉及时间和频率相关,包括音高、空间位置和起始/结束时间。音高是一个非常重要的分组依据,它根据不同的谐波模式来鉴别某种声音的唯一特征。当采用两个或者多个麦克风时,声音隔离系统可以根据空间位置信息来确定每个麦克风声音的方向和距离。casa建模方式使得声音隔离系统能够集中于某一声音源,比如某个特定的人,并且屏蔽掉背景声音。起始/停止时间分组指的是某一声音成分开始出现和停止的时刻,这些数据与原始的频率数据合并时就能够判断是否来自同一声音源。屏蔽掉一系列噪声集中识别某一特定的声音源。具有相似属性的声音会形成同一音频流,同样的,不同的属性的会形成各自的音频流。可以采用这些不同的音频流来鉴别持续或者重复的声源。有了足够的声音分组,实际的声音隔离处理就可从已经鉴别过的声源中去匹配,并且响应真正说话者的声音,从而分离出所述用户朗读所述目标业务文案的目标音频信息。
本实施例中,通过将用户图片进行处理,获得质量较好的筛选图片,再将所述筛选图片与公安系统中的预设图片进行比对,以对所述用户身份进行验证,提高信息录入的安全性和可靠性。
此外,本发明实施例还提出一种存储介质,所述存储介质上存储有视频音频识别程序,所述视频音频识别程序被处理器执行时实现如上文所述的视频音频识别方法的步骤。
此外,参照图5,本发明实施例还提出一种视频音频识别装置,所述视频音频识别装置包括:
查找模块10,用于接收用户输入的目标业务类型,根据所述目标业务类型查找对应的目标业务文案,将所述目标业务文案进行展示。
应理解的是,在网页或者app内,可通过选项呈现各种业务类型,用户选择需要进行的所述目标业务类型,在接收到用户输入的所述目标业务类型时,从预设映射关系表中查找与所述目标业务类型对应的目标业务文案,所述预设映射关系表中包括业务类型与业务文案之间的对应关系。所述目标业务类型包括贷款、租赁或保险等业务,所述目标业务文案为各业务类型需要收集的用户相关信息,比如各业务类型均需采集用户的个人基本信息,如一段个人信息文案:我是xxx,我的身份证件号是xxxxx,我是来自xxx地区等。不同的业务类型还需采集业务类型对应的相关信息,比如贷款业务还需采集如下信息:是否有在还贷款,是否有房产、车子以及年收入多少等信息,可预先按照业务类型建立对应的业务文案,将需要采集的信息以填空形式呈现。
音频分离模块20,用于拍摄所述用户朗读所述目标业务文案的目标视频,通过音视频分离器对所述目标视频进行音频分离,获得目标音频信息。
需要说明的是,用户在朗读所述目标业务文案时,可对需要填空的内容结合自己的信息在朗读时进行填充。对所述用户朗读所述目标业务文案的过程进行拍摄,视频录制可通过所述视频音频识别设备的摄像功能进行,比如智能手机的录像功能。在所述网页或者app内有摄像按钮,所述目标业务文案在所述网页或者app内进行展示时,所述业务文案的上方或者下方设置摄像按钮,用户通过点击该摄像按钮,拍摄自己朗读所述目标业务文案的视频,获得所述目标视频。
可理解的是,音频分离通常是将视频的声音和图像分别取出来,分离音频步骤为:设置音频源;获取源文件中轨道的数量,并遍历找到需要的音频轨;对找到的音频轨进行提取,获得所述目标音频信息。
文字识别模块30,用于对所述目标音频信息进行文字识别,获得目标信息。
在具体实现中,将所述目标音频信息中首尾端的静音切除,降低对后续步骤造成的干扰。对静音切除后的第一音频信息进行分帧,也就是把所述第一音频信息切开成一小段一小段,每小段称为一帧,分帧操作一般使用移动窗函数来实现。分帧后,所述第一音频信息就变成了很多小段。再将波形作变换,提取梅尔倒谱系数(mel-scalefrequencycepstralcoefficients,mfcc)特征,把每一帧波形变成一个多维向量。接着,把帧识别成状态;把状态组合成音素;把音素组合成单词。若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词,从而获得对应的文本信息,可将所述文本信息中用户填充的内容进行提取,作为所述目标信息。
抽帧处理模块40,用于对所述目标视频进行抽帧处理,获得用户图片。
应理解的是,对所述目标视频实例化的同时进行初始化,获取所述目标视频总帧数并打印,定义一个变量,用来存放存储每一帧图像,循环标志位,定义当前帧,读取所述目标视频每一帧,字符串流,将长整型long类型的转换成字符型传给对象str,设置每10帧获取一次帧,将帧转成图片输出,结束条件,当前帧数大于总帧数时候时,循环停止,输出的图片即为所述用户图片。
生成模块50,用于根据所述用户图片和所述目标信息生成所述用户的目标业务文档。
需要说明的是,所述用户图片可作为所述用户的身份验证信息,还可对所述音频进行用户的声纹提取,将提取的声纹作用用户的身份标识,并根据声纹进行身份验证。所述目标信息为从用户朗读的文本中提取的关于用户的相关信息,将所述用户图片和所述目标信息结合生成一个资料文档,即为所述目标业务文档,则所述目标业务文档包括用户身份验证信息和所述目标业务类型需要的各种用户信息。
本实施例中,通过接收用户输入的目标业务类型,根据所述目标业务类型查找对应的目标业务文案,将所述目标业务文案进行展示,拍摄所述用户朗读所述目标业务文案的目标视频,通过音视频分离器对所述目标视频进行音频分离,获得目标音频信息,通过语音朗读减少手动输入的繁琐步骤;对所述目标音频信息进行文字识别,获得目标信息,对所述目标视频进行抽帧处理,获得用户图片,以对用户身份实现验证;根据所述用户图片和所述目标信息生成所述用户的目标业务文档,基于人工智能,通过解析视频获得多方面的数据,验证用户身份的同时提升用户的信息录入效率。
在一实施例中,所述文字识别模块30,还用于对所述目标音频信息进行文字识别,获得对应的文本信息;将所述文本信息与所述目标业务文案进行比对,获得所述文本信息的正确率;在所述正确率大于预设正确率阈值时,通过正则表达式对所述文本进行信息提取,获得目标信息。
在一实施例中,所述视频音频识别装置还包括:
判断模块,用于判断所述目标信息是否满足预设规则;
提示模块,用于若不满足,则进行提示,以使所述用户重新朗读所述目标业务文案;
所述抽帧处理模块40,还用于若满足,则执行所述对所述目标视频进行抽帧处理,获得用户图片的步骤。
在一实施例中,所述视频音频识别装置还包括:
活体检测模块,用于对所述目标视频进行人脸识别,对识别到的人脸进行活体检测;
所述抽帧处理模块40,还用于在活体检测成功时,执行所述对所述目标视频进行抽帧处理,获得用户图片的步骤。
在一实施例中,所述活体检测模块,还用于对所述目标视频进行人脸识别,对识别到的人脸的眼部区域进行截取,获得眼部区域图像;通过预设眨眼模型识别所述眼部区域图像是否有眨眼动作;若识别到所述眼部区域图像有眨眼动作,则认定活体检测成功。
在一实施例中,所述视频音频识别装置还包括:
预处理模块,用于对所述用户图片进行预处理,获得预处理图片;
筛选模块,用于根据清晰度对所述预处理图片进行筛选,获得筛选图片;
对比模块,用于将所述筛选图片与预设图片进行对比,获得比对结果;
所述生成模块50,还用于在所述对比结果超过预设相似度阈值时,根据所述筛选图片和所述目标信息生成所述用户的目标业务文档。
在一实施例中,所述音频分离模块20,还用于播放目标音乐的同时,拍摄所述用户朗读所述目标业务文案的目标视频;
通过音视频分离器对所述目标视频进行音频分离,获得混合音频信息;
通过计算听觉场景分析算法从所述混合音频信息中提取所述用户朗读所述目标业务文案的目标音频信息。
本发明所述视频音频识别装置的其他实施例或具体实现方式可参照上述各方法实施例,此处不再赘述。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如只读存储器镜像(readonlymemoryimage,rom)/随机存取存储器(randomaccessmemory,ram)、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!