一种计算机物联网数据处理系统的制作方法
本发明属于计算机物联网领域,具体涉及一种计算机物联网数据处理系统。
背景技术:
计算机物联网正导致物流行业思考模式的转变。物流服务供应商使用gps或遥测等传感器技术来跟踪和管理他们的货物过程,传感器有助于标记和连接工厂、轮船和机器等,在此过程中,还通过使用外部数据,这些数据包含有关事件的关键信息,如信息交通事故和自然灾害,将来自不同传感器和社交媒体的数据关联起来并实时进行分析,提供交付延迟的预测事件和预防意外。“事物”的连接性通过internet实现设备之间的即时通信,这个高度连接的生态系统对物流运营商、其业务客户和最终客户的收益均具有深远的影响。物联网生态系统的主要优势之一它能将后勤传感器与外部传感器,如天气传感器和交通(gps)传感器等信息交汇融合,物联网还能够与社交媒体连接,如提供重要交通、事故、天气、自然灾害等事件的信息。
然而,由于数据的多样性和收集速度的不同,导致从不同来源收集和处理数据的准确性和速度性也大不相同,同时,实时处理数据的工作量很大,传统的物流信息系统无法解决这一问题。另一方面,尽管预测分析以预测装运延误或规定分析以优化路线均能够在规定时间内提高交付速度进而提高客户满意度,但延迟交货仍然是一个悬而未决的问题,及时交货是物流公司面临的巨大挑战,因为有时延误是由任何人无法控制的因素所造成的。延迟交货会带来各种影响,如客户流失或订单取消进而造成巨大的损失。因此,及时交货对物流公司至关重要。近年来,物流企业开始着手调查如何利用数据预测延迟,尤其是,在大数据技术方面,物流供应商正在关注大量使用事故、交通拥挤等事件流源于外部资源,如社交媒体实时分析和预测延迟。实时预测延迟使公司能够采取行动,如优化实时飞行路线。现有的解决方案是建立在经典的数据处理技术之上的,因此,传统的物流信息系统无法实时处理传感器或社交媒体数据,因为这些数据以高速状态流动,另外传统的数据处理方法无法处理无模式数据,如文本。现有的数据处理方法(例如,技术或算法)没有足够的效率来实时处理数据。
考虑到对数据源的评估,大多数现有解决方案仅限于一个数据源。另外,对于实时系统持续改进,现有技术使用的是静态历史数据集进行测试,而显然,仅依靠历史数据已经不能满足当今的物流需求。基于此,本发明提出了一种批处理和实时处理海量数据的混合框架,该框架建立在归类算法的基础上,能够从多个异构系统中实时采集物流数据传以实时或批处理方式高效地处理数据。本发明专注于开发一种混合解决方案,使实时数据能够得到批量处理,使物流服务成为可能,迫切需要计算机加工提供程序以实时执行分析。
技术实现要素:
本发明提出了一种计算机物联网数据处理系统,建立在归类算法的基础上,能够从多个异构系统中采集物流数据以实时高效地处理数据。
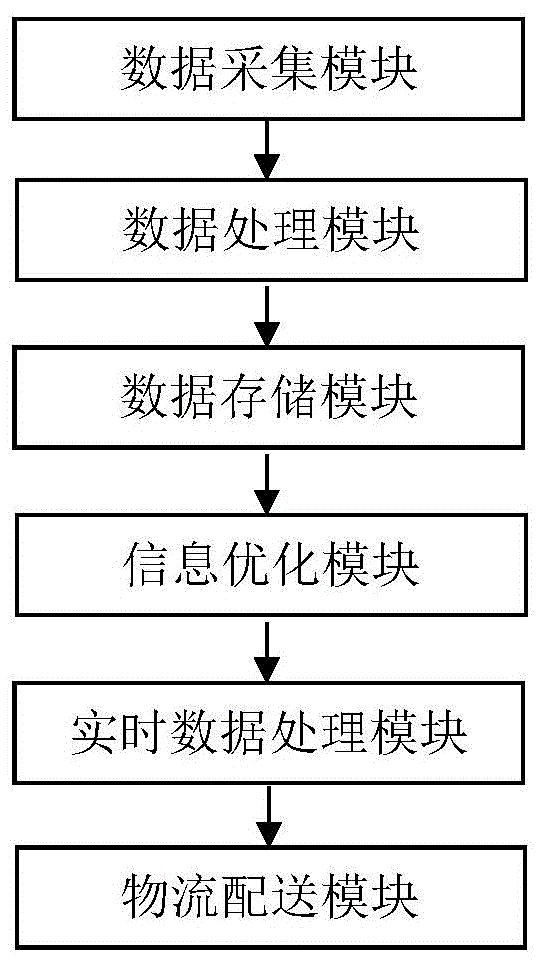
一种计算机物联网数据处理系统,包括数据采集模块、数据处理模块、数据存储模块、信息优化模块及物流配送模块,所述数据处理模块包括批数据处理设备和实时数据处理模块,批数据处理设备用于读取/提取存储数据并进行数据准备,批数据处理设备包括数据准备阶段和数据处理阶段,所述数据准备阶段包括数据提取、数据清理、数据过滤、数据集成和数据存储,所述数据处理阶段将准备充分的数据进行归类处理,所述批数据处理设备通过无线/有线网络将数据直接发送到实时数据处理模块,信息优化模块对物流进行线路优化,并将优化线路通过无线/有线数据传输给物流配送模块,批数据处理设备将来自多个数据传感器及物流应用的物流数据进行批处理。
进一步地,数据提取器从云服务器上抓取特定网站中所链接的网页,并从已爬取来的网页中提取链接,提取的链接数据信息分别存储在数据存储模块中,同时,数据提取器包括网页预处理模块和查询模块,网页预处理模块将分析抓取来的网页,建立索引、计算网页的等级;查询模块提供用户搜索界面,用户输入搜索词,并根据用户的查询向用户返回查询结果所述数据过滤是对网页进行去噪,过滤掉一些脚本标识符和无用的信息,并将每个页面中有用的文本保存下来,进行分词、去噪、排序,提取出网页的关键字,根据网页抓取模块中提取到的网页间的链接关系,根据pagerank排序算法思想,获取基于网页的链接关系计算得出的网页pr值;再利用空间向量模型计算物流相关信息与相关网页关键字的相似度权重,并且增加用户历史搜索与搜索关键字的权重,最后通过算法重新计算有链接关系的网页间的贡献值,并获得等级排名,并由此作为物流服务的重要参考依据。
进一步地,数据过滤包括如下步骤:
(1)分析需要排序的网页链接集合setweb中链接指向关系,确定每个网页的链出链入情况;
(2)从setweb中每个网页的页面内容中提取关键词,生成网页的关键词集合sweb_keywords={v1,v2,v3,…,vi};
(3)计算setweb中每个网页对应的的关键词和k的相似度,得到关键词相关度因子集合w(u);
(4)根据id找到该用户对应的物流、交通、天气、地理位置等关键词列表sh_web_keywords;
(5)计算setweb中每个网页对应的关键词和sh_web_keywords的距离d,得到影响因子h(u);
(6)对每个网页,都有三个因子,根据公式gr=(1-d)+d[∑pr(v)(α/nv+β·w(u)+γ·h(u))];
计算每个网页的综合得分,得到最终的网页排名gr;其中α,β,γ分别代表的是链接、主题相关度因子以及用户因子在pr值分配中的权重。
进一步地,数据提取包括用于收集各种结构化和非结构化数据信息来源,以获得完整的以及对感兴趣区域的准确描述并将多源异构数据进行标准化处理。
进一步地,网页的抓取是利用heritrix开源爬虫程序进行的,在它现有的开源的代码上,用户可扩展其各个组件以实现自己的抓取逻辑,并从网络中获取所需的资源。
进一步地,所述数据采集模块采集多源异构数据,多源异构数据包括数据传感器的信息和物流应用的信息,所述数据传感器包括车辆传感器、天气传感器;物流应用包括微博、社交媒体。
进一步地,数据清理是检测纠正或移除损坏或不准确的记录集、表。
进一步地,执行数据集成分两个步骤:第一步,数据被转换从源到目标序列化格式;第二步是合并转换的数据。
进一步地,所述实时数据处理模块对数据项进行分组或分段,将目标函数生成一个聚集的数据集,在预测交货延迟时进行有效的分析。
进一步地,信息优化模块用于构建高吞吐量的持久性数据和可靠交付的收集系统的信息,进而对物流线路进行主题集合,分为一个或多个线性有序的消息序列,其中每个消息都按其索引被标识。
原始pagerank算法仅考虑网页的链入和链出关系,并没有分析网页内容是否与用户搜索的主题一致或者类似,虽然能抓取到高质量的网页,但是也会抓取到与查询主题无关或者相似度很低的网页,即存在主题漂移的问题,而本发明通过引入链接、主题相关度因子以及用户因子的权重比例,通过每一项权重的分配,得到更加符合实际需要的排序,为物流提供有效信息。
实时数据处理模块实时执行事件的集群并获取对已处理数据的即时洞察,将目标函数生成一个聚集的数据集,进而有助于在预测交货延迟时进行有效的分析。并实时根据交互数据对物流输送进行及时调整,以实现物流配送产品的信息化与规范化。
通过本发明计算机物联网数据处理系统对物流线路进行优化,能够节约大量人力物力,使货物及时交付到顾客手中,提高用户满意度,提高货物的依次投送能力,降低货物在中间节点的转发次数,提高货物的运输效率,克服了复杂事件管理不及时等困难。
附图说明
图1是本发明的一种计算机物联网数据处理系统的示意图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
一种计算机物联网数据处理系统,包括数据采集模块、数据处理模块、数据存储模块、物流配送模块,数据处理模块包括批数据处理设备和实时数据处理模块,批数据处理设备用于读取/提取存储数据并进行数据准备,以及在实时数据处理情况下进行数据的清理、过滤,批数据处理设备通过无线网络将数据直接发送到实时数据处理模块。
数据采集模块采集多源异构数据,多源异构数据包括数据传感器的信息和物流应用的信息,其中数据传感器包括车辆传感器、天气传感器;物流应用包括微博、twitter、社交媒体、facebook等。
批数据处理设备将来自多个数据传感器及物流应用的物流数据进行批处理,批数据处理设备包括两个阶段:数据准备阶段和数据处理阶段。数据准备阶段包括数据提取、数据清理、数据过滤、数据集成和数据存储。数据处理阶段,将准备充分的数据进行归类处理。具体地:
数据提取:用于收集各种信息来源以获得完整的以及对感兴趣区域的准确描述并将多源异构数据进行标准化处理。数据提取器使用内部和外部的数据,内部数据源通常是用户使用的系统。一个用户系统包括由供应链管理构成的信息系统(供应链管理)、客户关系管理(crm),物流管理系统和账户管理系统(ams)。这些系统产生大量由数据提取器收集的数据。它也从外部源气象传感器、和其他社交媒体获取数据。此外,可以收集结构化和非结构化数据。例如,可以从微博收集非结构化文本,也可以收集来自物流信息系统的结构化业务流程数据。数据提取器从云服务器上抓取特定网站中所链接的网页,并从已爬取来的网页中提取链接,提取的链接数据信息分别存储在数据存储模块中,同时,数据提取器包括网页预处理模块和查询模块,网页预处理模块将分析抓取来的网页,建立索引、计算网页的等级;查询模块提供用户搜索界面,用户输入搜索词,并根据用户的查询向用户返回查询结果。网页的抓取是利用heritrix开源爬虫程序进行的,heritrix是一种以多线程方式抓取网页内容的爬虫,在它现有的开源的代码上,用户可以扩展其各个组件以实现自己的抓取逻辑,并从网络中获取所需的资源。
数据过滤:指广泛的策略或优化数据集的解决方案。数据集被细化为一组用户需要什么,而不包括其他可能重复、不相关甚至敏感的数据,数据过载会增加计算成本和数据处理的准确性。在收集过程中,特别是其标签的数据块决定了运输,交货,物流,装运过程中直接和间接的联系。例如获取消息“今天股票价格非常高”将被数据筛选器删除,因为它没有携带任何与物流流程相关的信息。数据过滤要由三个部分组成:网页去噪、中文分词和链接分析。大多数网页是半结构化的,存在着大量的格式信息,因此分析网页内容的第一步就是对网页进行去噪,过滤掉一些脚本标识符和无用的信息。随后将每个页面中有用的文本保存下来,并且分析这些文本,对其进行分词、去噪、排序,提取出网页的关键字。根据网页抓取模块中提取到的网页间的链接关系,并使用pagerank排序算法思想,首先获取基于网页的链接关系计算得出的网页pr值。再利用空间向量模型计算物流相关信息与相关网页关键字的相似度权重,并且增加用户历史搜索与搜索关键字的权重。最后通过算法重新计算有链接关系的网页间的贡献值,并获得等级排名,并由此作为物流服务的重要参考依据。具体分为如下步骤:
(1)分析需要排序的网页链接集合setweb中链接指向关系,确定每个网页的链出链入情况;
(2)从setweb中每个网页的页面内容中提取关键词,生成网页的关键词集合sweb_keywords={v1,v2,v3,…,vi};
(3)计算setweb中每个网页对应的的关键词和k的相似度,得到关键词相关度因子集合w(u);
(4)根据id找到该用户对应的物流、交通、天气、地理位置等关键词列表sh_web_keywords;
(5)计算setweb中每个网页对应的关键词和sh_web_keywords的距离d,得到影响因子h(u);
(6)对每个网页,都有三个因子,根据公式gr=(1-d)+d[∑pr(v)(α/nv+β·w(u)+γ·h(u))]
计算每个网页的综合得分,得到最终的网页排名gr;其中α,β,γ分别代表的是链接、主题相关度因子以及用户因子在pr值分配中的权重,三个参数都大于0,并且为了保证算法的收敛性,三个值之和要等于1,每一项的权重都代表着这些因子在分配过程中的重要程度,三者取值的变化都会影响到排序结果的优劣。
数据清理:它是检测纠正(或移除)损坏或不准确的记录集、表。
数据集成:执行数据集成分两个步骤。在第一步中,数据被转换从源到目标序列化格式;第二步是合并转换的数据。
数据存储:此步骤旨在处理集成数据集并将数据存储到存储器中。
数据查询模块主要包括两部分:查询代理和用户界面。在系统预处理后,此时传递到查询模块的数据由两部分组成:索引网页库和倒排文件。查询代理接受用户通过用户界面输入的查询短语,并在分割短语后,从索引网页库和倒排文件中检索,并获取包含查询短语的文档,然后将它们作为返回结果返回给用户。在实现查询过程中,对查询短语分词后,获得查询的向量表示,并综合考虑在倒排索引中查询短语的权重以及该术语的位置信息。通过传统的信息检索模型计算查询与网页文档的相似度;结合网页预处理阶段获得的网页排名,对网页进行排序形成最终排名,然后根据排名的先后顺序将相应的网页返回给用户。
实时数据处理模块是核心部件。物流服务有不同的装运方式,包括空运、船舶和陆运,单一的运输方式不能满足运送需求。尤其是境外物流,如在中国制造的产品被装运面向国外不同城市的客户;装运过程必须是多式联运,这意味着这一过程将包括卡车、火车、轮船或航空等。综合多式联运物流过程容易遇到各种各样的挑战,导致交货延误。例如,如果在港口的通关被延误,货物可能会延误,即使所有其他运输方式都符合预定的时间表。不确定事件,如自然灾害、战争、罢工抗议可能会影响一个或多个交付模式或是整合物流流程的更多步骤。不确定性是这类事件的主要挑战。因此,本发明通过实时分析数据以提取可能导致交货延误的因素,其信息包含可能导致交货延误事件的连续数据流。实时数据处理模块基于社交媒体及传感器事件,其访问速度是磁盘的十万倍,实时数据处理模块的设计目的是添加缺少的数据信息以方便事件的及时应对处理。这些事件首先进入通过分布式消息传递到数据存储模块。对于此类不确定事件,实时数据处理模块能够优先扩展处理行为,而不是成批处理。实时数据处理模块实时执行事件的集群并获取对已处理数据的即时洞察。归类是对数据项进行分组或分段的过程,这些数据项它们在集群中相似,但与数据不同属于另一个群集的项。本发明基于归类概念,将目标函数生成一个聚集的数据集,进而有助于在预测交货延迟时进行有效的分析。
令xi={x1,x2,…,xn}表示具有n个物流对象的数据集,其中xi={x1,x2,…,xn}表示第i个对象的m个属性,数据集表示成n×m的矩阵。对数据集进行t次归类,ri={ri1,ri2,…,rit}表示第i个对象在t次归类下的结果,基归类结果表示成n×t的矩阵,数据信息采用成对约束,成对约束所描述的是两个数据对象之间的关系,其包括两种关系:反映数据对象属于同一类的必连关系信息,记作m,反应数据对象不属于同一类的不连关系信息,记作c。
在原数据特征空间中,将原数据表示成n×n的矩阵d,d(i,j)表示对象i与对象j之间的相似度,用高斯相似度计算
δ(rit,rjt)=1,rit=rjt;δ(rit,rjt)=0,rit≠rjt。
在监督信息特征空间中,将成对约束表示成n×n的矩阵s。对于给定的同一数据集上,成对约束具有对称性和传递性。根据下式计算对象点之间的相似度,以保证相似性矩阵s的非负性,
这样,在原数据、基归类、监督信息三种特征空间上分别构造n×n的矩阵d、b和s后,将三个相似性矩阵线性结合构造一个新矩阵l=w1d+w2b+w3s,其中,w1、w2、w3分别为原数据、基归类及监督信息的权重,对l进行nmf归类,得到结果,在最终的结果矩阵中选取nmi值最大的一列为类标签。
信息优化模块根据nmi值、买家信息、卖家信息以及运输信息(如航班、车次等),对物流进行线路优化,信息优化模块是基于发布订阅的信息系统,它是快速且高度可扩展的分布式信息模块,它用于构建持久数据高吞吐量和可靠交付的收集系统的信息对物流线路进行主题集合,分为一个或多个线性有序的消息序列,其中每个消息都按其索引被标识。信息优化模块将优化线路通过无线/有线数据传输给物流配送模块,实现数据交互。
物流配送模块包括gps模块和位移传感器,通过gps模块和位移传感器结合实时对货物的地点进行监测,并实时根据交互数据对物流输送进行及时调整,以实现物流配送产品的信息化与规范化。
以上所述仅是对本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!