一种结合逻辑规则和碎片化知识的关系预测方法与流程
本发明涉及一种结合逻辑规则和碎片化知识的关系预测方法。
背景技术:
在关系推理领域,以transe[1]为代表的关系推理模型,因其简单而高效,同时具有良好的预测性能而成为近年来研究热点。transe模型采用直接对知识库中的事实三元组(h,r,t)进行建模,其基本思路是将知识库中的实体和关系映射到一个低维连续向量空间中,从而简化知识库的相关计算。基本的表示学习模型虽然简单高效,但因仅仅考虑了知识库中的直接事实三元组(h,r,t),而忽略了知识库中隐藏的语义信息,使得推理精度有限。近期的一些工作利用添加外部数据,比如实体类型、文本描述、逻辑规则等来进一步提升推理精度。文献[2]通过引入关系的定义域和值域来过滤掉一些错误样本,减少噪声数据对模型的影响。文献[3]则考虑向表示学习模型添加实体上下文信息,从而提升模型的语义表达能力。文献[4]通过对额外的文本信息和知识库中的直接事实三元组进行统一建模,从而提升其推理性能。文献[5]首先通过规则挖掘系统提取一组可表示知识库语义信息的horn逻辑规则。随后通过基于规则的物化推理方法得到一组新的事实。文献[6]利用实体间存在的大量多跳关系路径来表示实体间的语义关系。
随着互联网的快速发展,新的知识碎片也在源源不断地产生,知识库已不再是静态不变的。因此在应用关系推理技术实现知识库的自动化补全时,应该考虑知识库的动态增长情形。近年来,基于知识表示学习的关系推理获得了极大的关注。然而,大多数现有的知识表示学习方法仅仅使用事实三元组执行嵌入,忽略了知识网络中一些隐藏的语义信息,不仅使得学习到的向量不能准确的表达原知识库中的语义关系,而且不能充分利用碎片化知识所带来的价值。由此,本发明提出了一种结合逻辑规则和碎片化知识的关系预测方法。该方法首先对事实三元组和逻辑规则进行统一的建模,通过这种方式,将隐藏的语义信息嵌入到基于知识表示的关系推理模型中。其次,结合碎片化知识,不断迭代更新,使得知识库变得越加完备,实现关系预测。
技术实现要素:
本发明的目的在于提供一种结合逻辑规则和碎片化知识的关系预测方法,该方法对事实三元组和逻辑规则进行统一的建模,将隐藏的语义信息嵌入到基于知识表示的关系推理模型中,实现更精准地预测。
为实现上述目的,本发明的技术方案是:一种结合逻辑规则和碎片化知识的关系预测方法,首先对事实三元组和逻辑规则进行统一的建模,将隐藏的语义信息嵌入到基于知识表示的关系推理模型中;其次,结合碎片化知识,不断迭代更新,使得知识库变得越加完备。
在本发明一实施例中,该方法具体实现如下:
第一阶段:对知识库中的直接事实三元组进行建模,得到知识库中所有实体和关系的向量表达,用于第三阶段计算规则间的语义关联度;
第二阶段:通过规则挖掘算法挖掘出一组可代表知识库语义信息的逻辑规则;
第三阶段:应用逻辑规则推理阶段,有两种方式:一是通过基于逻辑规则的物化推理,推理出新的事实并添加到知识库中,实现知识库的动态扩充;二是将事实三元组(h,r,t)中的关系r用逻辑规则取代表示,从而将逻辑规则嵌入到基于表示学习的关系推理模型中,h、t均表示实体;由于知识库中存在多条以关系r为规则头的推理规则,因此,提出以关系r为规则头的不同规则体与关系r之间语义关联度的方法;
第四阶段:基于第一阶段至第三阶段三个阶段的输出作为第四阶段的输入,对事实三元组和逻辑规则进行统一建模,通过这一方式,将逻辑规则丰富的语义信息嵌入到基于表示学习的关系推理模型rtranse中,紧接着通过训练好的rtranse模型进行关系推理,实现对知识库的补全;
第五阶段:结合动态知识碎片,不断迭代更新,使得知识库变得越加完备。
在本发明一实施例中,第四阶段中,对事实三元组和逻辑规则进行统一建模的过程如下:
给定一个三元组(h,r,t),当三元组成立时,transe模型满足以下关系:h+r≈t;在||h+r-t||1的基础上对三元组得分函数进行归一化改进,如下公式(1)所示:
式(1)中d(h,r,t)=||h+r-t||1为距离函数,可以很容易看出f(h,r,t)∈[0,1],如果三元组成立,则f(h,r,t)应尽可能小,反之则尽可能大;
该模型使用知识库中现有的事实三元组作为正例,随机替换头尾实体和关系产生的与知识库现有事实相矛盾的三元组作为负例进行训练,三元组建模损失函数如下公式(2)所示:
式(2)中,s={s1,s2,...si,...sn}为事实三元组的集合,
在本发明一实施例中,第四阶段中,将逻辑规则丰富的语义信息嵌入到基于表示学习的关系推理模型rtranse的具体过程如下:
嵌入逻辑规则联合表示的距离函数
k为以关系r为规则头的第i条逻辑规则的规则体个数;bi为第i条逻辑规则的规则体;如果逻辑规则能表示关系r的语义信息,则
嵌入逻辑规则的表示学习模型使用推理出的逻辑规则作为正例,随机替换规则头产生的与现有逻辑规则相矛盾的规则作为负例,逻辑规则的损失函数如下公式(4)所示:
其中lr为逻辑规则的集合,
嵌入规逻辑规则的表示学习模型损失函数
由式(5)可知,该模型损失函数由两部分组成,分别为知识库直接事实三元组距离函数和逻辑规则与关系r的距离函数。
在本发明一实施例中,引入实体类型取代规则实例化中实体的嵌入表示将具有更强的预测性,因此:
对式(1)中d(h,r,t)进行改进的结合实体类型的距离函数d(h,r,t,htype,ttype),如下公式(6)所示:
d(h,r,t,htype,ttype)=||(h+htype)+r-(t+ttype)||1(6)
式(6)中htype表示头实体h对应的实体类型,ttype表示尾实体t对应的实体类型;
对式(2)的三元组建模损失函数进行改进的加入实体类型的三元组建模损失函数
式(7)中el为实体类型标签集,实体标签集el={el1,el2,...,eln},它表示可代表知识库中所有实体类别的标签集合,f(h,r,t,htype,ttype)为新的三元组得分函数,具体表示如下公式(8)所示:
对式(3)进行改进的嵌入逻辑规则和实体类型联合表示的距离函数
式(9)中mie表示关系r的第i条规则的规则体的连接变量实体的类型向量相加;
对式(4)进行改进的加入实体类型的逻辑规则损失函数
式(10)中mie表示关系r的第i条规则的规则体的连接变量实体的类型向量相加;
对式(5)进行改进的加入实体类型的嵌入规逻辑规则的表示学习模型损失函数
在本发明一实施例中,第五阶段中,触发模型迭代训练的条件函数rt,如下公式(12)所示:
式(12)中,#facts、#entity分别为临时知识库kb′的事实三元组个数和实体个数,θ为模型迭代训练阈值。
在本发明一实施例中,该方法应用于人物关系预测中。
相较于现有技术,本发明具有以下有益效果:
1、本发明对事实三元组和逻辑规则进行统一的建模,将隐藏的语义信息嵌入到基于知识表示的关系推理模型中,实现更精准地预测;
1、本发明方法能够针对动态流入的知识碎片运行激活策略,适应动态知识网络的同时实现了更准确的知识推理。
附图说明
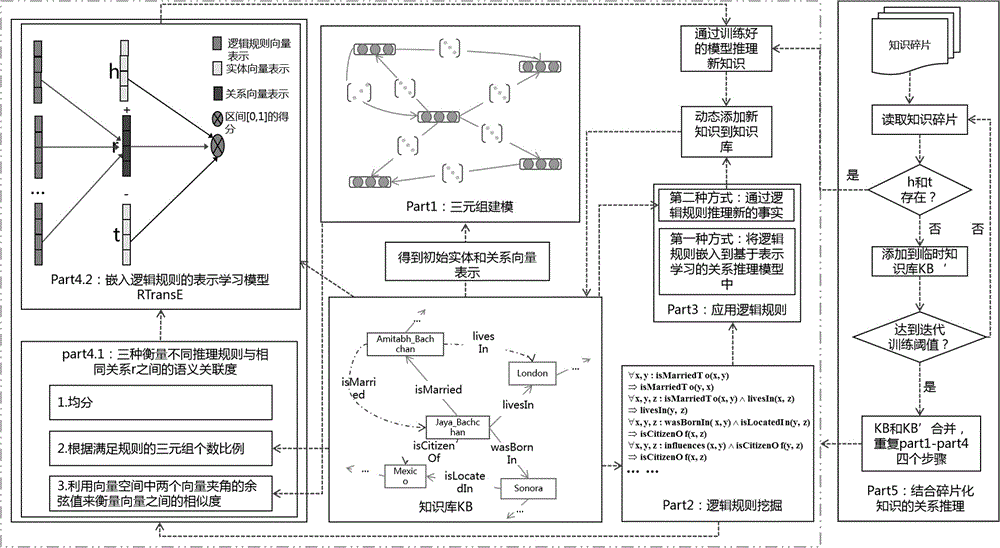
图1为本发明方法框架图。
图2为临时知识库示例。
图3为关系推理整体框架图。
图4为结合逻辑规则和碎片化知识推理过程图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
本发明提供了一种结合逻辑规则和碎片化知识的关系预测方法,首先对事实三元组和逻辑规则进行统一的建模,将隐藏的语义信息嵌入到基于知识表示的关系推理模型中;其次,结合碎片化知识,不断迭代更新,使得知识库变得越加完备。该方法具体实现如下:
第一阶段:对知识库中的直接事实三元组进行建模,得到知识库中所有实体和关系的向量表达,用于第三阶段计算规则间的语义关联度;
第二阶段:通过规则挖掘算法挖掘出一组可代表知识库语义信息的逻辑规则;
第三阶段:应用逻辑规则推理阶段,有两种方式:一是通过基于逻辑规则的物化推理,推理出新的事实并添加到知识库中,实现知识库的动态扩充;二是将事实三元组(h,r,t)中的关系r用逻辑规则取代表示,从而将逻辑规则嵌入到基于表示学习的关系推理模型中,h、t均表示实体;由于知识库中存在多条以关系r为规则头的推理规则,因此,提出以关系r为规则头的不同规则体与关系r之间语义关联度的方法;
第四阶段:基于第一阶段至第三阶段三个阶段的输出作为第四阶段的输入,对事实三元组和逻辑规则进行统一建模,通过这一方式,将逻辑规则丰富的语义信息嵌入到基于表示学习的关系推理模型rtranse中,紧接着通过训练好的rtranse模型进行关系推理,实现对知识库的补全;
第五阶段:结合动态知识碎片,不断迭代更新,使得知识库变得越加完备。
以下为本发明的具体实现过程。
本发明提出的方法主要处理过程分为五个阶段:第一阶段,对知识库中的直接事实三元组进行建模,得到知识库中所有实体和关系的向量表达,用于第三阶段计算规则间的语义关联度。第二阶段,通过规则挖掘算法挖掘出一组可代表知识库语义信息的逻辑规则。第三阶段,应用逻辑规则推理阶段,主要有两种方式:一是通过基于逻辑规则的物化推理,推理出新的事实并添加到知识库中,实现知识库的动态扩充;二是将事实三元组(h,r,t)中的关系r用逻辑规则取代表示,从而将逻辑规则嵌入到基于表示学习的关系推理模型中。由于知识库中存在多条以关系r为规则头的推理规则,因此,提出了三种计算以关系r为规则头的不同规则体与关系r之间语义关联度的方法;第四阶段,基于上面三个阶段的输出作为第四阶段的输入,关键思想在于对事实三元组和逻辑规则进行统一建模,通过这种方式,将逻辑规则丰富的语义信息嵌入到基于表示学习的关系推理模型中,紧接着通过训练好的rtranse模型进行关系推理,实现对知识库的补全。第五阶段,结合动态知识碎片,不断迭代更新,使得知识库变得越加完备。本发明方法总体框架设计如图1所示:
以下给出本文的相关定义。
定义1(知识库,kb)设知识库kb=<e,r,f,p,v>,其中e表示entity(实体)的集合,r表示relation(关系)的集合,f代表知识库中事实的集合,p表示property(属性)的集合,v表示value(属性值)的集合。
定义2(实体集,e)设实体集e={e1,e2,...,en}=∏subject(kb)∪∏object(kb),它描述了语义网络知识库数据层中的所有实体,并且对应rdf中的实例集合。
定义3(关系集,r)设关系集r={r1,r2,...,rn}=∏relation(kb),它表示实体与实体之间的关系。
定义4(事实集,f)设事实集
定义5(属性,p)属性集p表示全体属性的集合p={p1,p2,...,pn},它将e与属性值v关联起来。
定义6(属性值,v)属性值集v表示全体属性值的集v={v1,v2,...,vn},它表示文本等节点。
定义7(实体标签集,el)设实体标签集el={el1,el2,...,eln},它表示可代表知识库中所有实体类别的标签集合。针对yago、dbpedia等常用数据集,本文对per、loc、org分别进行扩展,定义了39种类型作为本文的实体标签集,表示为el,其cf={per|org|loc}表示三大类的集合。如表1所示。
表1实体标签集
本发明方法具体如下:
1、三元组建模
给定一个三元组(h,r,t),当三元组成立时,transe模型希望尽量满足以下关系:h+r≈t。例如,姚明+国籍=中国和詹姆斯+国籍=美国。本文在||h+r-t||1的基础上对三元组得分函数进行归一化改进。
定义8三元组的得分函数f(h,r,t),如下公式1所示:
式(1)中d(h,r,t)=||h+r-t||1为距离函数,可以很容易看出f(h,r,t)∈[0,1],如果三元组成立,则f(h,r,t)应尽可能小,反之则尽可能大。
该模型使用知识库中现有的事实三元组作为正例,随机替换头尾实体和关系产生的与知识库现有事实相矛盾的三元组作为负例进行训练,其损失函数如下定义9所示。
定义9三元组建模的损失函数
式(2)s={s1,s2,...si,...sn}为事实三元组的集合,
2、逻辑规则挖掘
结合文献[7],本发明实现了一个在大型图数据中发现horn逻辑规则的算法hornconcerto。该算法在运行时间和内存消耗方面优于现有的方法,并为知识推理任务挖掘出更高质量的逻辑规则。hornconcerto算法受anie+算法的启发,也引入了置信度度量方法pca。逻辑规则的支持度和置信度如定义10和定义11所示。
定义10逻辑规则的支持度
其中规则的支持度supp表示知识库中同时满足规则头和规则体的事实三元组个数,z1,...zm表示除了x和y之外的规则变量。
定义11逻辑规则的pca置信度
其中分子表示规则的支持度,分母中y′表示通过pca假设所计算得到的规则头的所有可能关系。规则的置信度反应的是这条规则的可信程度以及所表达的语义丰富度,置信度越接近1,越可信。
3、应用逻辑规则
知识库本身通常已经包含了足够的信息来派生和添加新的事实。通过规则挖掘算法可以在知识库中找到一些规则。例如,我们可以挖掘规则:
这条规则捕捉到这样一个事实,一个人的配偶通常与这个人居住在同一个地方。
由背景知识可知,这些逻辑规则蕴含丰富的语义信息,这将使得知识推理具有更强的预测性。而本文将所挖掘的逻辑规则应用于两个方面:
其一,将事实三元组(h,r,t)中的关系r用逻辑规则取代表示,从而将逻辑规则嵌入到基于表示学习的关系推理模型中。然而,知识库中可能存在多条以关系r为规则头的推理规则。比如,以下两条规则均能推理出“国籍”这个关系,但其与“国籍”之间的语义关联度是不同的。
1、
2、
在本小节中,我们将介绍三种方法来衡量以关系r为规则头的不同规则体与关系r之间的语义关联度。定义
定义12equal(均分):认为每条推理规则对关系r的影响程度是一样的,因此对于以关系r为规则头的第i条逻辑规则与关系r的语义关联度计算方法如下公式5所示:
定义13numberratio(个数比例):通过计算知识库中满足该条逻辑规则的事实三元组个数与满足n条逻辑规则的事实三元组个数总和的比例来衡量语义关联度,因此对于以关系r为规则头的第i条逻辑规则与关系r的语义关联度计算方法如下公式6所示:
定义14vectordistance(向量距离):通过transe模型学习到的关系向量表示来计算逻辑规则中规则体与规则头的语义关联度,即利用向量空间中两个向量夹角的余弦值来衡量向量之间的相似度,因此对于以关系r为规则头的第i条逻辑规则与关系r的语义关联度计算方法如下公式7所示:
式(7)中n为向量的维度,k为第i条逻辑规则中规则体的个数,bi为第i条逻辑规则的规则体,t为归一化因子,可以很容易的看出
其二,通过基于逻辑规则的物化推理,推理出新的事实并添加到知识库中,实现对知识更充分的利用。然而,不可信的事实三元组将会给模型带来更多噪声,本文通过公式(3)和(4)对噪声数据进行过滤,向模型中引入更具可靠性的规则和事实三元组信息。
定义15推理出的新事实三元组的置信度函数tripleconf(h,r,t),如下公式8所示:
4、嵌入式逻辑规则的表示学习模型rtranse
针对前面的章节中介绍的基于trans系列模型因仅考虑知识库中的直接事实三元组,以及基于逻辑规则的表示学习方法中仅考虑置信度最高的逻辑规则而忽略了其他推理规则对该事实三元组的影响,导致在面对1-n、n-1和n-n复杂关系类型时表现出推理精度低下的问题。本章节提出了一种基于逻辑规则和表示学习的关系推理模型rtranse。该模型原理图如图1-part4所示。
由原理图1-part4可知,该模型不仅考虑三元组(h,r,t)中实体h与实体t之间的直接关系r,还考虑以关系r为规则头的n条逻辑规则,因此嵌入逻辑规则的表示学习模型所学习到的实体关系向量更能完整地表达知识库中的语义信息,实现更精准的预测。
定义16嵌入逻辑规则联合表示的距离函数
k为以关系r为规则头的第i条逻辑规则的规则体个数。如果逻辑规则能表示关系r的语义信息,则
嵌入逻辑规则的表示学习模型使用推理出的逻辑规则作为正例,随机替换规则头产生的与现有逻辑规则相矛盾的规则作为负例。其损失函数如下定义17所示。
定义17逻辑规则的损失函数
其中lr为逻辑规则的集合,
定义18嵌入规逻辑规则的表示学习模型损失函数
式(11)可知,该模型损失函数由两部分组成,分别为知识库直接事实三元组距离函数和逻辑规则与关系r的距离函数。主要思想是想让那些正样本的距离函数值远远小于负样本的距离函数值。
5、实体类型对表示学习模型的影响
由式(9)可知,距离函数
来说,实例y必定对应不同的实体,但是其对应的实体类型是相同的,因此引入实体类型取代规则实例化中实体的嵌入表示将具有更强的预测性。
定义19对式(1)中的d(h,r,t)进行改进的结合实体类型的距离函数d(h,r,t,htype,ttype),如下公式12所示:
d(h,r,t,htype,ttype)=||(h+htype)+r-(t+ttype)||1公式(12)
式(12)中htype表示头实体h对应的实体类型,ttype表示尾实体t对应的实体类型。
定义20对式(9)进行改进的嵌入逻辑规则和实体类型联合表示的距离函数
其中mie表示关系r的第i条规则的规则体的连接变量实体的类型向量相加。
定义21对式(2)进行改进的加入实体类型的三元组建模损失函数
式(14)中el为实体类型标签集,具体参考定义7,f(h,r,t,htype,ttype)为新的三元组得分函数,具体表示如下公式15所示。
定义22对式(10)进行改进的加入实体类型的逻辑规则损失函数
定义23对式(11)进行改进的加入实体类型的嵌入规逻辑规则的表示学习模型损失函数
6、结合动态知识碎片的关系推理
当今时代是互联网高速发展的时代,新的知识碎片也在源源不断地产生,因此知识库不再是静态不变的。利用动态知识碎片进行关系推理也是实现知识库动态增长极其有效的手段之一。
举例说明,如知识库中已存在事实三元组“<姚明,出生地,上海>”,结合新流入的知识碎片“<上海,所属国家,中国>”,若“上海”和“中国”在知识库中能找到对应的实体向量,那么通过训练好的rtranse模型可以为“姚明”和“中国”两个实体间补上“国籍”这个关系。若不存在,则加入临时知识库池中,直至池中事实三元组个数与实体个数的比例达到迭代训练的阈值θ时,将临时知识库kb′与原始知识库kb合并,并进行重新训练,得到新的逻辑规则和新的rtranse模型,再结合碎片化知识进行关系推理。如此反复,直到不再流入新的知识碎片或不再产生新的事实为止。
设定阈值的好处在于减少迭代次数,提升算法执行效率。本小节用事实三元组个数与实体个数的比例来衡量临时知识库的离散程度,比例越大,表明实体间联系更加紧密,更能挖掘实体间潜在的联系。此时,重新训练才显得更加有意义。反之亦然。由图2可知,显然满足图2-a的临时知识库更符合重新训练的标准。
定义24触发模型迭代训练的条件函数rt,如下公式18所示。
式(18)中,#facts、#entity分别为临时知识库kb′的事实三元组个数和实体个数,θ为模型迭代训练阈值。
7、本发明方法的应用
尽管一个普通的知识库中已经包含数百万实体和数以亿计的事实,但仍然不完整。知识库的补全是通过现有知识结合碎片化知识来推理预测实体之间的关系。本发明将通过实现一个在大型图数据中发现horn逻辑规则的算法hornconcerto[8]和racrfk算法,去完成进一步的知识库补全,实现对知识更充分的利用。
由背景知识可知,逻辑规则蕴含丰富的语义信息,这将使得知识推理具有更强的预测性。因此,首先利用规则挖掘算法hornconcerto挖掘出一组可表示知识库语义信息的horn逻辑规则。其次将逻辑规则应用于结合逻辑规则和动态知识碎片的关系推理算法racrfk,结合碎片化知识,不断迭代更新,使得知识库变得越加庞大、越加完备。
应用hornconcerto算法和racrfk算法进行关系推理的整体框架图如图3所示。
首先,本文通过规则挖掘算法hornconcerto挖掘一组可表示知识库语义信息的horn逻辑规则,例如,可以挖掘这样一条规则
接着,举例说明,通过结合逻辑规则和碎片化知识的关系推理算法racrfk对知识库进行补全。结合逻辑规则和碎片化知识的推理过程如图4所示。
由图4可以观察出,一个知识碎片的流入可能触发模型对知识库迭代推理出成千上万个事实,体现了本文模型能充分利用动态知识碎片所带来的价值。图4中,虚线部分(即图中国籍部分内容)为本文模型结合碎片化知识所推理出来的新事实。
参考文献:
[1]bordesa,usuniern,garcíadurána,etal.translatingembeddingsformodelingmulti-relationaldata.[c]//internationalconferenceonneuralinformationprocessingsystems.2013.
[2]krompaβ,denis,s.baier,andv.tresp."type-constrainedrepresentationlearninginknowledgegraphs."(2015).
[3]xier,liuz,sunm.representationlearningofknowledgegraphswithhierarchicaltypes[c]//internationaljointconferenceonartificialintelligence.aaaipress,2016.
[4]wangz,lij.text-enhancedrepresentationlearningforknowledgegraph[c]//internationaljointconferenceonartificialintelligence.aaaipress,2016.
[5]陈曦,陈华钧,张文.规则增强的知识图谱表示学习方法[j].情报工程,2017,3(1):026-034.
[6]liny,liuz,luanh,etal.modelingrelationpathsforrepresentationlearningofknowledgebases[j].computerscience,2015.
[7]sorut,valdestilhas,andré,marxe,etal.beyondmarkovlogic:efficientminingofpredictionrulesinlargegraphs[j].2018
[8]sorut,valdestilhas,andré,marxe,etal.beyondmarkovlogic:efficientminingofpredictionrulesinlargegraphs[j].2018.。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!