一种红外人脸对齐方法与流程
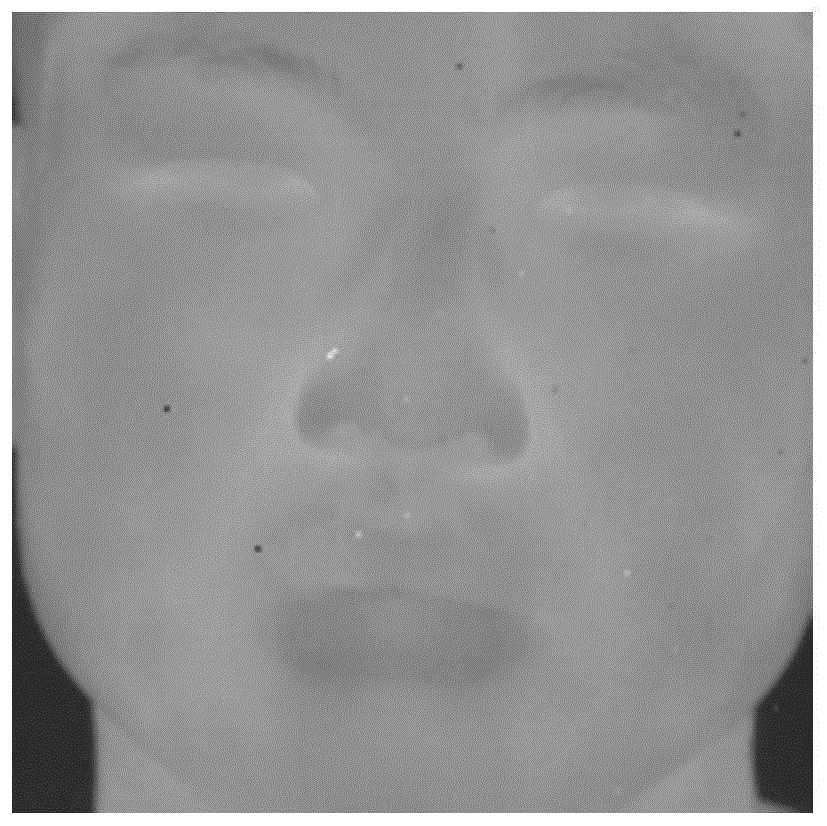
本发明属于生物特征识别技术领域,更具体地,涉及一种人脸对齐方法。
背景技术:
人脸识别技术能够为人们的日常生活带来极大的便利,提升人民生活质量。目前,可见光的人脸识别技术已经日趋成熟,其工程应用设备已在生活中广泛部署,如:银行采用人脸识别技术进行身份验证、现今的手机多支持人脸识别解锁。可见光的人脸识别技术大体可分为传统的人工设计特征并进行提取与深度学习的机器学习特征并进行提取两种方式。传统方式如hog、haar+adaboost等相较于深度学习的方法而言,其检测精度较差,但其识别速度较快;深度学习方式进行人脸识别,其检测效率高,且精度可达到人眼水平,但其需要大量的带标注的样本进行训练。但不论是哪种方式,在整个人脸识别过程中,都面临如下问题:
①易遭到攻击。对于传统方式的人脸检测,通过戴眼镜等方式就可能导致识别出现问题;对于深度学习方式的人脸检测,通过额头贴带有攻击图像的纸条便可使系统识别失效。两种方式都会被照片欺骗,产生误识别,导致风险的出现。
②需要外界光源支持。可见光式的人脸识别需要一定的光源,如在无光源情况下,则无法形成人脸图像,整个人脸识别流程难以进行。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种红外人脸对齐方法,其利用人体的热辐射,无需光源的辅助,为被动式人脸识别检测;并且因为热红外成像本身便利用的是人体的热辐射,这也在根源上消除了照片攻击的风险。
为实现上述目的,按照本发明的一个方面,提供了一种红外人脸对齐方法,其特征在于,包括以下步骤:
(1)对三通道的热红外人脸图像提取三官区域形成三官提取图像,三通道的热红外人脸图像与其提取的三官提取图像组成图像对,以此方式,获得m个图像对;其中,三官指双眼、鼻子和嘴巴;
(2)搭建卷积神经网络,将m个所述图像对分为m-n个训练集和n个测试集,并将训练集输入卷积神经网络训练出网络模型;
(3)在测试集的热红外人脸图像中选取q张正脸图像,各正脸图像与该正脸图像提取的三官提取图像作为标定图像对,然后将测试集中的各个热红外人脸图像输入网络模型,网络模型输出的三官区域图像作为三官生成图像,其中,各标定图像对中的热红外人脸图像的三官生成图像分别作为三官标定图像;
(4)利用三官区域中各像素的坐标和通道值,实现三官生成图像和测试集中三官提取图像的三官区域的定位;
(5)分别获取左眼、右眼、鼻子和嘴巴区域的形心作为人脸关键点,其中三官标定图像获取的人脸关键点作为标定关键点;
(6)将步骤(5)获得的三官生成图像的人脸关键点与测试集中三官提取图像的人脸关键点比对进行误差评价,若误差不满足要求,则返回步骤(2);若满足要求,则执行步骤(7);
(7)对于待对齐的热红外人脸图像,通过网络模型生成待对齐的三官生成图像,然后获得待对齐的三官生成图像的人脸关键点,通过待对齐的三官生成图像的人脸关键点与标定关键点获得仿射变换矩阵,然后通过仿射变换矩阵将待对齐的热红外人脸图像对齐后输出。
优选地,步骤(1)具体过程如下:
(1.1)采集宽度为w且高度为h的单通道的热红外人脸图像,通过以下公式将其通道扩展为3:
ci(u,v)=corg(u,v),i=1,2,3
c(u,v)=[r=c1(u,v),g=c2(u,v),b=c3(u,v)]
其中,u、v分别表示热红外人脸图像中各像素在u-v照片坐标系下的宽度坐标和高度坐标,corg(u,v)表示单通道的热红外人脸图像中坐标(u,v)处的通道值,c(u,v)表示转换为三通道后的热红外人脸图像中坐标(u,v)处的通道值,ci(u,v)表示转换为三通道后的热红外人脸图像中坐标(u,v)处的通道i的通道值,r、g、b分别代表红色通道值、绿色通道值、蓝色通道值;
(1.2)对于经过步骤(1.1)处理后的图像,形成三官提取图像的过程如下:
herg=hori
werg=wori
其中,herg、hori分别表示三官提取图像的高和三通道的热红外人脸图像的高,werg、wori分别表示三官提取图像的宽和三通道的热红外人脸图像的宽,c(u,v)表示坐标(u,v)处的像素的通道值,areairrelevant表示无关区域,areaeyes表示双眼区域,包含左眼区域与右眼区域;areanose表示鼻子区域,areamouth表示嘴巴区域。
优选地,步骤(4)具体过程如下:
对于三官生成图像,对三官区域进行如下定位:
areanose={c(u,v)=[r=0,g≥220,b=0]|0≤u≤w,0≤v≤h}
areamouth={c(u,v)=[r≥220,g=0,b=0]|0≤u≤w,0≤v≤h}
areaeye={c(u,v)=[r=0,g=0,b≥220]|0≤u≤w,0≤v≤h}
优选地,步骤(5)的具体过程如下:
(5.1)采用形心公式计算各目标区域质心作为人脸关键点,步骤(5)已确定各区域的位置,则先采用已定位的鼻子区域获得鼻子区域的形心:
其中,
嘴巴处的形心获取如下:
mouthtotal表示嘴巴区域内的像素的总数,xk表示鼻子区域处的第k个像素的宽度坐标,yk表示鼻子区域处的第k个像素的高度坐标;
对于眼睛区域,采用鼻子关键点与嘴巴关键点的连线将眼睛区域划分为左眼区域和右眼区域,具体划分如下:
其中,
优选地,所述步骤(6)具体过程如下:
(6.1)对于测试集中同一个图像对的热红外人脸图像获得的三官生成图像与三官提取图像,通过下式进行人脸关键点误差分析:
其中,error表示三官生成图像相较于三官提取图像的误差,其作为网络模型生成效果的评判基准,
(6.2)将测试集的所有三官提取图像与获得的三官生成图像按步骤7.1)进行误差分析,以分别获取误差error;
(6.3)获得平均误差
其中,n为测试集中图像对的总数量;
若平均误差
优选地,所述步骤(7)具体过程如下:
(7.1)每张三官标定图像获得标定关键点的坐标信息后,按下式获得修正关键点坐标
其中,
(7.2)选取待对齐的三官生成图像的左眼、右眼和嘴巴区域的形心,按下式获得仿射变换矩阵:
其中,(xp,yp)为待对齐的热红外人脸图像p区域的人脸关键点坐标,xp和yp分别为宽度坐标和高度坐标,a、b、c、d、e、f为仿射变换矩阵中的待求参数。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
1)本发明的热红外人脸成像能够直接避免上述易遭到外界攻击和需要外界光源支持问题:热红外人脸成像利用人体的热辐射,无需光源的辅助,为被动式人脸识别检测,并且因为热红外成像本身便利用的是人体的热辐射,这也在根源上消除了照片攻击的风险。
2)本发明通过卷积神经网络训练后的三官提取图像来获得热红外人脸关键点,其定位准确,偏差和误差小,识别率高。
附图说明
图1为三通道的热红外人脸图像;
图2为图1的热红外人脸图像形成的三官提取图像;
图3为一张三官标定图像,;
图4为三官生成图像获得的人脸关键点显示在图1的热红外人脸图像上的示意图;
图5为三官提取图像获得的人脸关键点显示在图1的热红外人脸图像上的示意图;
图6为三官生成图像和三官提取图像获得的人脸关键点均显示在图1的热红外人脸图像上的示意图;
图7为待对齐的热红外人脸图像;
图8为图7的热红外人脸图像对齐后的热红外人脸图像;
图9是本发明的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明提供了对热红外人脸图像进行人脸对齐的方法,该方法考虑到可见光的人脸关键点定位的方法对于热红外人脸图像进行关键点定位的失效,不能采用点坐标回归的方式进行热红外人脸图像的关键点定位。对于热红外人脸图像而言,其面部纹理特征相较于可见光而言较少,可见光人脸图像中的常用的五个关键点:左眼球中心、右眼球中心、鼻尖下沿、左嘴角、右嘴角,在热红外人脸图像中难以凭肉眼分辨其位置并进行标注。若人工无法标注样本,则采用深度学习方式进行训练,实现关键点的自动标注,且无法进行对齐。
本发明提出了热红外人脸对齐方法,包括以下步骤:
(1)对三通道的热红外人脸图像提取三官区域形成三官提取图像,三通道的热红外人脸图像与其提取的三官提取图像组成图像对,以此方式,获得m个图像对;其中,三官指双眼、鼻子和嘴巴;
(2)搭建卷积神经网络,将m个所述图像对分为m-n个训练集和n个测试集,并将训练集输入卷积神经网络训练出网络模型,显然,n<m,m个图像对作为训练样本,其取值要足够大,以保证训练样本足够多,一般取值为n=70%m;
(3)在测试集的热红外人脸图像中选取q张正脸图像,各正脸图像与该正脸图像提取的三官提取图像作为标定图像对,然后将测试集中的各个热红外人脸图像输入网络模型,网络模型输出的三官区域图像作为三官生成图像,其中,各标定图像对中的热红外人脸图像的三官生成图像分别作为三官标定图像;
(4)利用三官区域中各像素的坐标和通道值,实现三官生成图像和测试集中三官提取图像的三官区域的定位;
(5)分别获取左眼、右眼、鼻子和嘴巴区域的形心作为人脸关键点,其中三官标定图像获取的人脸关键点作为标定关键点;
(6)将步骤(5)获得的三官生成图像的人脸关键点与测试集中三官提取图像的人脸关键点比对进行误差评价,若误差不满足要求,则返回步骤(2);若满足要求,则执行步骤(7);
(7)对于待对齐的热红外人脸图像,通过网络模型生成待对齐的三官生成图像,然后获得待对齐的三官生成图像的人脸关键点,通过待对齐的三官生成图像的人脸关键点与标定关键点获得仿射变换矩阵,然后通过仿射变换矩阵将待对齐的热红外人脸图像对齐后输出。
进一步,所述步骤(1)具体包括:
①对于单通道的热红外人脸图像的预处理,设单通道的热红外人脸图像的尺寸为w*h*c,w为宽度,h为高度,c为通道,将其通道扩展为3,使图像变为w*h*3,具体表现为:
ci(u,v)=corg(u,v),i=1,2,3
c(u,v)=[r=c1(u,v),g=c2(u,v),b=c3(u,v)]
其中,u、v分别表示热红外人脸图像中各像素在u-v照片坐标系下的宽度坐标和高度坐标,corg(u,v)表示单通道的热红外人脸图像中坐标(u,v)处的通道值,c(u,v)表示转换为三通道后的热红外人脸图像中坐标(u,v)处的通道值,ci(u,v)表示转换为三通道后的热红外人脸图像中坐标(u,v)处的通道i的通道值,r、g、b分别代表红色通道值、绿色通道值、蓝色通道值。
将热红外人脸图像从单通道图像处理成三通道图像,对于图像成像并无影响,反而使得后续人脸热图像设计有了更多的通道值选择,从而使得目标区域能与无关区域有明显的区域划分。
②设计三官提取图像,并构建{热红外人脸图像,三官提取图像}图像对,共获得m个图像对:
为了便于区别在热红外人脸热图像中的目标区域与无关区域,对于经过①预处理后的图像,其三官提取图像设计为:
herg=hori
werg=wori
其中,herg、hori分别表示三官提取图像的高和三通道的热红外人脸图像的高,werg、wori分别表示三官提取图像的宽和三通道的热红外人脸图像的宽,c(u,v)表示坐标(u,v)处的像素的通道值,areairrelevant表示无关区域,areaeyes表示双眼区域,包含左眼区域与右眼区域;areanose表示鼻子区域,areamouth表示嘴巴区域。
将双眼、鼻子、嘴巴分别以不同的颜色进行表示,不仅能够使目标区域与无关区域具有明显区分,还能使得三类目标区域具有明显区分,便于后续精确定位双眼、鼻子、嘴巴位置。由于左眼和右眼比较相似,以不同颜色进行标注将会使得模型学习困难,故在此以同色标注,后续进行细分。
对于每一张三通道的热红外人脸图像,提取一张三官提取图像,按照一一对应的关系构成{热红外人脸图像,三官提取图像}图像对,提取可以通过人工提取来将三官区域圈出,也可以通过图像处理软件进行提取,譬如通过图像边缘和轮廓特征的提取。
所述步骤(4)具体如下:
对于网络模型生成的三官生成图像,对其眼睛,鼻子、嘴巴区域进行如下定位:
areanose={c(u,v)=[r=0,g≥220,b=0]|0≤u≤w,0≤v≤h}
areamouth={c(u,v)=[r≥220,g=0,b=0]|0≤u≤w,0≤v≤h}
areaeye={c(u,v)=[r=0,g=0,b≥220]|0≤u≤w,0≤v≤h}
通过上述方法,可通过像素的坐标值和对应的通道值,对各像素进行定位,对各像素属于的区域进行归类,从而实现网络模型自动生成的三官生成图像的目标区域(双眼区域、鼻子区域和嘴巴区域)的坐标,实现目标区域的定位。
所述步骤(5)具体如下:
采用形心公式计算各目标区域的形心作为关键点;由于步骤(4)已确定各目标区域的位置,可以先采用已定位的鼻子、嘴巴区域计算鼻子、嘴巴处的形心:
其中,
以同样的方式计算嘴巴处的形心作为关键点:
mouthtotal表示嘴巴区域内的像素的总数,xk表示鼻子区域处的第k个像素的宽度坐标,yk表示鼻子区域处的第k个像素的高度坐标;
对于眼睛区域,采用鼻子关键点与嘴巴关键点的连线将眼睛区域划分为左眼区域,右眼区域。具体划分如下式:
其中,
参照图4、图5和图6,三官生成图像获得的人脸关键点采用横线和竖线长度相等的十字表示,形心在十字交叉处;三官生成图像获得的人脸关键点采用横线适于竖线的十字表示,形心也在十字交叉处。
所述步骤(6)具体如下:
对于测试集中的{热红外人脸图像,三官提取图像}图像对,由步骤(5)可得到一张三官提取图像的人脸关键点,对于三官提取图像的人脸关键点与网络模型形成的三官生成图像,通过下式进行关键点定位效果评判:
其中,error表示三官生成图像相较于三官提取图像的误差,其作为网络模型生成效果的评判基准,
将测试集的所有三官提取图像与获得的三官生成图像按步骤7.1)进行误差分析,以分别获取误差error,然后进行误差分析,通过平均误差
其中,n为测试集中图像对的总数量;
若平均误差
所述步骤(7)具体包括:
对于一张红外人脸图像,输入网络得到自动生成的三官提取图像,并按照步骤(5)获得人脸关键点坐标信息。
对于每一张正脸图像获得各标准关键点坐标信息后,按下式获得修正关键点坐标
其中,
选取待对齐的三官生成图像的左眼、右眼和嘴巴区域的形心,按下式获得仿射变换矩阵:
其中,(xp,yp)为待对齐的热红外人脸图像p区域的人脸关键点坐标,xp和yp分别为宽度坐标和高度坐标,a、b、c、d、e、f为仿射变换矩阵中的待求参数。
需要说明的是,本发明提到的坐标中,“x”和“x”的都是指在图像坐标系下的宽度坐标,带“y和“y”的都是指在图像坐标系下的高度坐标。三官提取图像和三官生成图像中双眼、鼻子和嘴巴区域的形心坐标的获取可通过软件程序实现,本发明中提到的所有坐标都是在u-v照片坐标系下的坐标。
通过对大量热红外人脸图像进行实验验证,做生成关键点与标定关键点的偏差分析。如表1,依据实验结果可以得出,平均误差
表1测试集中生成关键点与标定关键点的偏差
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!