视频个体识别方法、系统、设备及可读存储介质与流程
本发明涉及图像识别技术领域,特别涉及一种视频个体识别方法、系统、设备及可读存储介质。
背景技术:
人脸识别技术被广泛应用于安防、销售行业、银行业务等多种领域。以在零售行业为例,进店消费者流动性强,每个消费者拥有个人的消费习惯,人脸识别技术可帮助快速认出消费者身份,关联历史消费记录,从而提供准确的推荐服务。目前基于视频中人脸的监控方案主要是通过抓取视频中的人脸图像,提取有效表达的数字特征,从而将人脸匹配的过程转换为数字特征计算的方式。
但是,基于视频监控的人脸识别技术具有许多的缺点,其需要在理想的光照环境、用户主动配合的前提下,才会具有较好的性能,而传统人脸提取特征往往受到这些因素的影响,特征表达能力有限;视频数据中可使用的人脸图像数量较多,不合理的采样技术很容易抓取到低质量人脸图像,从而发生误检或漏检的现象;选择单一的评价标准或依赖于人工经验设置的硬性条件无法有效地选择优质的图像提取更具有代表性的人脸特征;监控视频捕获的人脸图像具有时间属性,随着时间的推移,图像数量呈现爆炸性增长趋势,简单的聚类算法容易导致个体类别数量急速膨胀或人脸特征被错误归类,长期的错误累积容易导致整个系统的崩盘。
技术实现要素:
本发明要解决的技术问题是如何提供一种高效、精确的视频个体识别方法、系统、设备及可读存储介质。
为了解决上述技术问题,本发明的技术方案为:
第一方面,本发明提出一种视频个体识别方法,包括步骤:
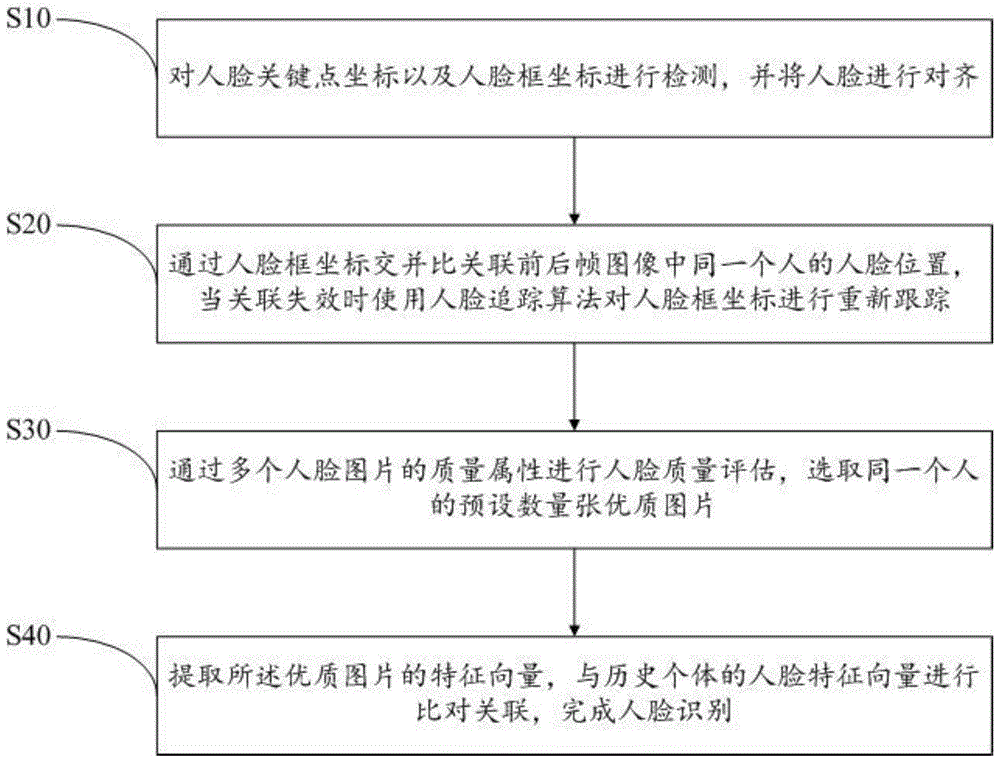
人脸关键点坐标以及人脸框坐标进行检测,并将人脸进行对齐;
通过人脸框坐标交并比关联前后帧图像中同一个人的人脸位置,当关联失效时使用人脸追踪算法对人脸框坐标进行重新跟踪;
通过多个人脸图片的质量属性进行人脸质量评估,选取同一个人的预设数量张优质图片;
提取所述优质图片的特征向量,与历史个体的人脸特征向量进行比对关联,完成人脸识别。
优选地,将人脸进行对齐的过程包括:计算一图片的人脸关键点坐标与预存的标准人脸的关键点坐标之间的变换矩阵,并将所述变换矩阵作用于该图片,获得对齐后的人脸图像。
优选地,使用人脸追踪算法对人脸框坐标进行重新跟踪的过程包括:根据前一帧图像分别建立相关的位置滤波器与尺度滤波器,根据当前帧图像及两个滤波器分别对当前帧的人脸框坐标与人脸框尺度进行估计。
优选地,人脸质量评估使用的质量属性包括人脸姿态、眼部状态、嘴部状态、妆容状态、整体亮度、左右脸亮度差异、模糊度、遮挡。
优选地,人脸姿态、眼部状态、嘴部状态、妆容状态、模糊度及遮挡均采用mobilefacenet结构作为主体构建多任务卷积神经网络,多个任务输出分别对应人脸的各个质量属性。
优选地,眼部状态、嘴部状态、妆容状态及人脸遮挡为分类任务,采用softmax损失函数作为目标函数;
人脸姿态、图像的光照度、图像模糊度为回归任务,采用euclidean损失函数做为目标函数;
网络训练的总目标函数包括多个softmax损失函数和euclidean损失函数的组合,多个任务进行共同学习时,总目标函数为多个损失函数的线性组合。
优选地,提取所述优质图片,使用50层resnet神经网络输出512维度的浮点向量,记做人脸特征向量;
通过比对当前个体的人脸特征向量与历史个体的人脸特征向量之间的相似程度进行关联,公式为:
其中,si为当前第i帧人脸特征向量,smn为历史存储的人脸特征向量群中第m个体的第n张人脸特征向量,nm表示历名特征向量中属于第m个个体的向量总数,m表示总的个体数量,i表示用于判断个体id的最大帧数。
另一方面,本发明还提出了一种视频个体识别系统,包括:
检测模块:人脸关键点坐标以及人脸框坐标进行检测,并将人脸进行对齐;
关联模块:通过人脸框坐标交并比关联前后帧图像中同一个人的人脸位置,当关联失效时使用人脸追踪算法对人脸框坐标进行重新跟踪;
评估模块:通过多个人脸图片的质量属性进行人脸质量评估,选取同一个人的预设数量张优质图片;
识别模块:提取所述优质图片的特征向量,与历史个体的人脸特征向量进行比对关联,完成人脸识别。
又一方面,本发明还一种视频个体识别设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的视频个体识别方法的步骤。
再一方面,本发明提出一种视频个体识别的可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时间实现上述的视频个体识别方法的步骤。
本发明技术方案通过人脸框坐标交并比关联前后帧图像中同一个人的人脸位置,当关联失效时使用人脸追踪算法对人脸框坐标进行重新跟踪;通过多个人脸图片的质量属性进行人脸质量评估,选取同一个人的预设数量张优质图片;提取所述优质图片的特征向量,与历史个体的人脸特征向量进行比对关联,完成人脸识别。通过人脸检测与人脸识别算法将人脸图像转换为可计算的人脸特征向量,不仅可以通过数值向量之间的相似程度来度量人脸图像之间的相似程度,转换的数值向量也方便使用数据库存储工具实现高效管理保存。其整体流程无需人员主动干预,完成人脸区域的捕获、特征转换与人脸优选。使用人脸图像择优的方式,不仅可以有效地提升人脸识别模型预测的稳定性,还可以减少系统的运算成本。通过人脸特征向量可以实现快速识别个体身份,关联个体相关信息,应用于诸如精准营销、历史行为分析等领域。
附图说明
图1为本发明视频个体识别方法一实施例中的步骤流程图;
图2为本发明视频个体识别方法另一实施例中的步骤流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明要解决的技术问题是如何提供一种高效、精确的视频个体识别方法、系统、设备及可读存储介质。
为了解决上述技术问题,本发明的技术方案为:
第一方面,本发明提出一种视频个体识别方法,包括步骤:
人脸关键点坐标以及人脸框坐标进行检测,计算一图片的人脸关键点坐标与预存的标准人脸的关键点坐标之间的变换矩阵,并将变换矩阵作用于该图片,将人脸进行对齐;
通过人脸框坐标交并比关联前后帧图像中同一个人的人脸位置,当关联失效时使用人脸追踪算法对人脸框坐标进行重新跟踪,根据前一帧图像分别建立相关的位置滤波器与尺度滤波器,根据当前帧图像及两个滤波器分别对当前帧的人脸框坐标与人脸框尺度进行估计。
通过多个人脸图片的质量属性进行人脸质量评估,选取同一个人的预设数量张优质图片;
具体地,人脸质量评估使用的质量属性包括人脸姿态、眼部状态、嘴部状态、妆容状态、整体亮度、左右脸亮度差异、模糊度、遮挡。
人脸姿态、眼部状态、嘴部状态、妆容状态、模糊度及遮挡均采用mobilefacenet结构作为主体构建多任务卷积神经网络,多个任务输出分别对应人脸的各个质量属性。
其中眼部状态、嘴部状态、妆容状态及人脸遮挡为分类任务,采用softmax损失函数作为目标函数;人脸姿态、图像的光照度、图像模糊度为回归任务,采用euclidean损失函数做为目标函数;
网络训练的总目标函数包括多个softmax损失函数和euclidean损失函数的组合,多个任务进行共同学习时,总目标函数为多个损失函数的线性组合。
提取优质图片的特征向量,与历史个体的人脸特征向量进行比对关联,完成人脸识别。
提取优质图片,本实施例中使用50层resnet神经网络输出512维度的浮点向量,记做人脸特征向量;
通过比对当前个体的人脸特征向量与历史个体的人脸特征向量之间的相似程度进行关联,公式为,
其中,si为当前第i帧人脸特征向量,smn为历史存储的人脸特征向量群中第m个体的第n张人脸特征向量,nm表示历名特征向量中属于第m个个体的向量总数,m表示总的个体数量,i表示用于判断个体id的最大帧数。
本发明技术方案通过人脸框坐标交并比关联前后帧图像中同一个人的人脸位置,当关联失效时使用人脸追踪算法对人脸框坐标进行重新跟踪;通过多个人脸图片的质量属性进行人脸质量评估,选取同一个人的预设数量张优质图片;提取优质图片的特征向量,与历史个体的人脸特征向量进行比对关联,完成人脸识别。通过人脸检测与人脸识别算法将人脸图像转换为可计算的人脸特征向量,不仅可以通过数值向量之间的相似程度来度量人脸图像之间的相似程度,转换的数值向量也方便使用数据库存储工具实现高效管理保存。其整体流程无需人员主动干预,完成人脸区域的捕获、特征转换与人脸优选。使用人脸图像择优的方式,不仅可以有效地提升人脸识别模型预测的稳定性,还可以减少系统的运算成本。通过人脸特征向量可以实现快速识别个体身份,关联个体相关信息,应用于诸如精准营销、历史行为分析等领域。
在本发明的另一实施例中,视频个体识别的过程为:
s1:人脸检测
s11:使用一种级联式的神经网络算法,对图像中出现的人脸关键点坐标以及人脸框坐标进行预测。人脸关键点坐标是指人脸面部区域的106个关键点的位置,覆盖到人脸面部区域的眉毛、眼镜、鼻子、嘴巴以及面部轮廓部位;人脸框坐标是指包含人脸面部区域的矩形人脸框。
s12:计算步骤s11中提取的人脸关键点坐标与标准人脸关键点坐标之间的变换矩阵,并将变换矩阵作用于最初的人脸图像,得到对齐后的人脸图像,对齐后的人脸关键点坐标的分布更加趋于一致。
s2:人脸关联
s21:iou关联
通过人脸框坐标交并比(简称为iou)关联前后帧图像中同一个人的人脸位置,人脸框坐标交并比定义为,
iou=(a1∩a2)/(a1ua2)
其中,a1和a2表示人脸框坐标,人脸框坐标交并比的值越大,说明两个人脸面部区域重叠程度越高。
实际上,通过步骤s11得到的人脸框坐标具有一定的波动性,同一个人在视频前后两帧图像中的人脸框坐标交并比会低于既定阈值,造成无法关联的现象。本发明中,当关联失效时使用人脸追踪算法对人脸框坐标重新进行预测。
s22:追踪关联
追踪算法有两个相关滤波器,定义为位置滤波器和尺度滤波器,追踪算法首先根据前一帧图像分别建立位置相关滤波器与尺度滤波器,然后根据当前帧图像与建立的两个滤波器分别对当前帧的人脸框坐标与人脸框尺度进行估计。
s3:人脸优选
通过步骤s2可以得到同一个人在视频中依次出现的人脸框坐标,从其中选择人脸区域图像质量最理想的若干帧(本发明使用数量为3帧)输送到步骤s4提取人脸特征。
s31:人脸质量评估算法
人脸质量评估算法采用了深度学习和传统图像分析算法相结合的方式,实现了根据人脸图像的面部特征得到人脸姿态、眼部状态、嘴部状态、妆容状态、整体亮度、左右脸亮度差异、模糊度、遮挡等质量属性,其中,人脸图像的亮度采用了传统算法,具体为将人脸图像的rgb三个通道根据一定的比例转成灰度图像,并根据灰度级来映射光照度大小。其它属性采用深度学习的方法实现,采用了轻量级的mobilefacenet结构作为主体来构建多任务卷积神经网络,多个任务输出分别对应人脸的各个质量属性。其中,眼部状态、嘴部状态、妆容状态、人脸遮挡等质量判断属于分类任务,采用softmax损失函数作为目标函数;人脸姿态、图像的光照度、图像模糊度等属于回归任务,采用euclidean损失函数做为目标函数。网络训练的总目标函数为多个softmax损失函数和euclidean损失函数的组合,多个任务进行共同学习时,总目标函数为多个损失函数的线性组合。
计算softmax损失:
计算euclidean损失:
s32:人脸质量决策
使用步骤s31得到的人脸姿态属性定义人脸图像姿态质量分数,
人脸图像姿态质量分数
fi=[1-(|pi|+|yi|)/(max|pi|+max|yi|)]×[1-(|pi|-|yi|)/(max|pi|+max|yi|)]
其中,pi表示左右侧脸姿态角度,yi表示抬头低头姿态角度。(|pi|+|yi|)/(max|pi|+max|yi|)衡量的是人脸姿态在两个方向上的综合大小,值越大,图像姿态质量越不理想;(|pi|-|yi|)/(max|pi|+max|yi|)衡量的是人脸姿态在两个方向上的差别大小,值越大,图像姿态质量越不理想。人脸姿态在两个方向上分布均衡,且均较小时,人脸图像姿态质量分数fi越大,图像姿态质量越理想。
另外,清晰度越高、光线亮度越柔和的图像具有越多的人脸面部细节,定义人脸图像质量分数,
ti=0ci>0.9
ti=fi×(1-bi)×(1-|li-0.5|)ci≤0.9
其中,bi表示人脸图像的模糊程度,取值范围为0到1,值越大,清晰度越差;li表示人脸图像的光照度,越接近于0表示光线越暗,越接近于1表示曝光度越大,趋于0.5表示光线越柔和,ci表示人脸图像的遮挡程度。人脸图像质量分数的含义是在人脸面部区域遮挡性不强的前提下(ci≤0.9指的是五官保持不被遮挡),优先选择人脸姿态较小,人脸图像清晰度较高,光线条件越理想的图像。
结合当前图像周边若干帧的人脸图像质量分数的加权作为当前帧的人脸图像质量分数,即,
人脸图像质量分数ti=α×ti-1+β×ti+γ×ti+1
其中,ti-1表示前一帧人脸图像质量分数,ti+1表示后一帧人脸图像姿态质量分数,α,β,γ表示前一帧、当前帧、后一帧人脸图像质量分数的权重。本发明实施例中,使用参数分别为α=0.2,β=0.6,γ=0.2。
s4:个体聚类
s41经过步骤s3后,每个人在视频中挑选出若干帧(本发明使用数量为3帧)人脸图像质量分数较高的图像,使用50层resnet神经网络输出512维度的浮点向量,记做人脸特征向量。
s42通过比对当前个体的人脸特征向量与历史个体的人脸特征向量之间的相似程度进行关联,公式为,
其中,si为当前第i帧人脸特征向量,smn为历史存储的人脸特征向量群中第m个体的第n张人脸特征向量,nm表示历名特征向量中属于第m个个体的向量总数,m表示总的个体数量,i表示用于判断个体id的最大帧数。
通过步骤s1对视频图像中出现的人脸框坐标进行预测,使用步骤s2中的iou及追踪算法对视频前后帧图像进行关联,步骤s3对每个个体关联的所有人脸图像质量进行评分、筛选择优,输送到步骤s4的人脸特征提取环节提取人脸特征,用于个体匹配、标志符存储。
另一方面,本发明还提出了一种视频个体识别系统,包括:
检测模块:人脸关键点坐标以及人脸框坐标进行检测,并将人脸进行对齐;
关联模块:通过人脸框坐标交并比关联前后帧图像中同一个人的人脸位置,当关联失效时使用人脸追踪算法对人脸框坐标进行重新跟踪;
评估模块:通过多个人脸图片的质量属性进行人脸质量评估,选取同一个人的预设数量张优质图片;
识别模块:提取优质图片的特征向量,与历史个体的人脸特征向量进行比对关联,完成人脸识别。
又一方面,本发明还一种视频个体识别设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现上述的视频个体识别方法的步骤。
再一方面,本发明提出一种视频个体识别的可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时间实现上述的视频个体识别方法的步骤。
该视频个体识别方法,至少包括步骤:
人脸关键点坐标以及人脸框坐标进行检测,并将人脸进行对齐;
通过人脸框坐标交并比关联前后帧图像中同一个人的人脸位置,当关联失效时使用人脸追踪算法对人脸框坐标进行重新跟踪;
通过多个人脸图片的质量属性进行人脸质量评估,选取同一个人的预设数量张优质图片;
提取所述优质图片的特征向量,与历史个体的人脸特征向量进行比对关联,完成人脸识别。
本发明使用神经网络结构,基于大量不同场景下的人脸数据进行学习训练,提取的人脸特征可以有效地判断人脸图像的模糊程度、人脸姿态、遮挡状况等质量评价要素,以及可以有效地区分不同个体;使用一种决策算法对输出的多种质量评价要素进行综合评判分析,有效采样高质量人脸图像,为后续的人脸特征匹配提供初步的筛选判断;基于提取的鲁棒人脸特征,对捕获的人脸图片进行归类。本发明基于以上技术手段,提供一种基于视频人脸质量分析的,综合人脸检测技术、人脸追踪技术以及人脸识别技术的视频个体分类方法。该方法可有效使用于视频监控范畴,实现快速识别个体身份,关联个体相关信息,应用于诸如精准营销、历史行为分析等领域。
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!