一种基于链路预测实现跨语言知识空间实体对齐方法及系统与流程
本发明涉及人工智能、机器学习领域,尤其涉及一种基于链路预测实现跨语言知识空间实体对齐方法。
背景技术:
随着现代互联网技术的发展,互联网上的信息积累越来越多,用户在检索信息时,咨询电商时,不仅仅满足于传统的简单的关键词检索匹配的结果,追求更加智能化个性化的搜索和问答服务。目前,大批国内外的互联网企业,例如谷歌、亚马逊、百度、腾讯都建立了自己的知识空间系统,利用知识空间技术为客户提供更加智能化的服务,知识空间技术可以结合现实中的相关知识,不论在信息检索领域,还是智能问答领域,都能根据知识空间的知识,理解用户的语句的隐藏语义信息,为用户提供更加智能化服务。
当前互联网大企业的知识空间提供了海量的信息,例如谷歌的知识空间系统已经入录了16亿条的知识信息。但是这些知识空间存在一定的局限性,例如英文知识空间里对于非英语地区的信息入录入不全面,因此通过融合这些不同语言知识空间的信息,组成更庞大、信息更全的多语言知识空间系统,可以为客户提供更全面的信息服务。但是传统基于词翻译模型的融合技术会受限于词的翻译精度和词的本身一词多义的问题,例如朝阳这个词就可以指北京的朝阳区,也可以是辽宁省的朝阳市。深度学习模型学习知识空间的实体和关系向量,利用已经标注好的实体对,训练对齐模型,需要标注大量信息,耗费了大量人力。
自学习技术目前应用于深度学习模型中,主要思想是根据现有的标注数据训练模型,模型预测新的数据,将预测的结果作为新的标注数据添加到训练数据中,对模型进行新一轮的训练,其中要保证新添加的标注数据不能跟旧的标注数据冲突。
技术实现要素:
为达到在知识空间融合过程中实现节约人力,增强对齐模型智能程度的目的,本发明采用了下列技术方案:
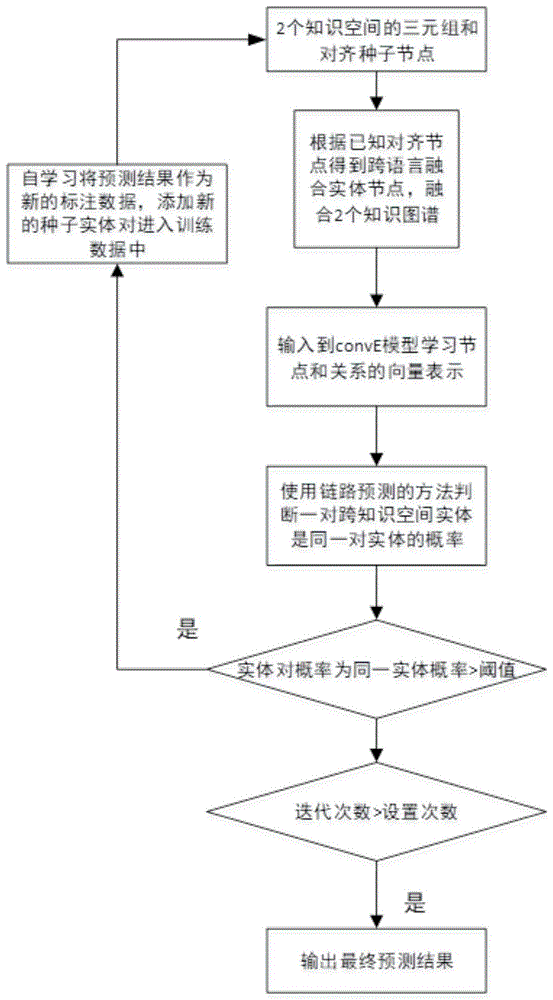
一种基于链路预测实现跨语言知识空间实体对齐方法,包括:
步骤一:跨语言知识空间三元组融合;
步骤二:知识空间表示学习;
步骤三:预测新对齐实体对;
步骤四:当存在预测出的一对新的对齐实体时,自学习添加新的训练数据;
步骤五:输出最终预测结果。
步骤一包括:
在两个知识空间中通过三元组结构,即通过头实体和尾实体以及二者之间的关系三元定义知识空间,对齐种子实体对;
生成新的跨知识空间三元组,通过所述新的跨空间三元组约束同一对实体之间的语义向量接近,将两个知识空间的实体的表示向量统一在同一个语义空间中,具体的:采用扩展知识空间三元组的方法,将两个现有知识空间融合为一个新的知识空间,那么所述新的知识空间的三元组集合包括所述现有知识空间的三元组以及融合后新增三元组集合,即通过已知对齐节点得到跨语言融合实体节点,进而融合两个实体空间。
步骤二包括:
通过conve模型来学习知识空间中实体与关系的表示,具体的:经过初始化embedding后分别获得实体与关系的embedding,然后将它们reshape成二维形式,之后stack起来;用特定个filter对stack后的矩阵进行卷积操作,生成一个特征矩阵;把特征矩阵reshape成一个向量,然后用一个全连接其都射进一个特定维度空间;之后与目标实体的embedding相乘获得相应的分数;最后通过softmax打分函数获得具体分数;
上述过程的损失函数使用二元的交叉熵函数计算。
步骤三包括:
收集关于实体充当头实体或者尾实体的三元组集合,计算目标知识空间中实体和原知识空间中实体是同一个实体的概率;
计算阈值,计算原有训练数据集中种子对齐实体对是同一个实体的概率,算出它们的均值,将这个均值作为阈值。
选出目标空间中满足概率最大的实体,如果概率超过训练数据中计算的阈值,那么生成新的跨空间对齐实体对。
步骤四包括:
当存在预测出的一对新的对齐实体时,自学习方法将其视为新的标注对齐种子实体对数据,添加到旧的训练数据中进行训练。添加的过程中,如果新预测实体对和旧的训练数据产生冲突,那么舍弃新的预测实体对;
如果新预测的实体对集合内部出现冲突,计算两个冲突的对齐实体对的概率差,选择概率值大的新预测实体队作为下一轮迭代的种子实体对;
当自学习迭代次数超过设定的次数上限(次数为50),停止迭代,训练对齐模型输出最终的跨语言实体对齐结果。
步骤五包括:
根据预测结果对两个知识空间进行合并,生成新的知识空间。
一种基于链路预测实现跨语言知识空间实体对齐系统,包括:
信息输入模块,用于两个不同的知识空间的数据库;
基于链路预测实现跨语言知识空间实体对齐模块,应用上述基于链路预测实现跨语言知识空间实体对齐方法,对输入知识空间数据进行合并;
信息输出模块,将自动生成的新的知识空间的数据进行输出。
本发明相对于现有技术的优点在于:
1、由于深度学习模型需要大量标注语料才能训练出模型,模型设计复杂,需要消耗较大的计算资源。本方法针对少量的训练语料,设计简单基于链路预测的方法预测新的实体对,进行跨语言知识空间融合,需要的训练语料较少,只需要少量的标注语料,可以学习出较好的效果,因此需要使用的标注人力较少。
2、本方法基于链路预测的方法判断跨语言知识空间的实体对是否是同一个实体,因此方法的设计较为轻便,其形成的系统比其他方法形成的系统节省了计算资源和更加快速。
附图说明
图1系统架构图;
图2跨语言知识空间三元组融合过程图;
具体实施方式
以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于此实施例。
本发明的基于链路预测实现跨语言知识空间实体对齐方法包括跨语言知识空间三元组融合、知识空间表示学习、预测新对齐实体对、自学习添加新的训练数据四个主要步骤,其作用分别如下:
跨语言知识空间三元组融合:主要的工作是根据现有的对齐种子实体对,生成新的跨知识空间三元组,这些新的跨空间三元组的存在是约束同一对实体之间的语义向量接近,将两个知识空间的实体的表示向量统一在同一个语义空间中。
知识空间表示学习:使用conve模型学习实体的向量表示,根据该向量表示学习用于下游的具体任务中。
预测新的对齐实体对:利用链路预测的技术方法,计算一对新跨空间实体对是同一个实体的概率,如果超过设定阈值,预测出新的种子实体对。
自学习方法添加新训练数据:将新预测种子实体对添加到旧的的对齐种子实体对集合中,生成更多的跨语言知识空间三元组。
步骤一:跨语言知识空间三元组融合
所谓kg(知识空间)融合即是指将来自不同知识空间的同一实体融合在一起,从而构成一个新的知识空间,之后我们就可以通过学习新的知识空间中的信息,建立我们需要的模型。
我们采用的方法为扩展知识空间三元组的方法,知识空间的表示为g=(e,r,s),其中e={e1,e2…,en}是知识空间的实体集合,其中包含|e|种不同实体;r={r1,r2,…,r|r|}是知识空间中的关系集合,包含|r|种不同关系,而s∈e×r×e则表示知识空间中的三元组集合,一般表示为(h,r,t),其中h和t表示头实体和尾实体,而r表示h和t之间的关系。
现在有两个知识空间g1,g2,我们需要将其进行融合为一个新的知识空间g,设它们的三元组集合为s1与s2,则g的三元组集合为s=s1∪s2∪s′,其中s‘为融合后新增三元组集合,具体内容如图所示,在两个知识空间中分别存在同一个实体e1,e2,在g1中存在某个包含e1的三元组,例如(e1,r2,et),则我们可添加新的三元组(e2,r2,et),以此类推,对于在g1包含e1的所有三元组都添加替换为含有e2的三元组,同理,在g2包含e2的所有三元组都添加替换为含有e1的三元组,这些新替换的三元组就构成了s‘,这样,我们便获得了一个新的知识空间g。它包含两个知识空间的全部关系信息,从而可以在新的知识空间中进行相关任务的学习。
步骤二:知识空间表示学习
知识空间的表示学习主要通过学习三元组(h,r,t)的信息,获得一个实体与关系的好的表示(embedding),我们主要通过conve来学习知识空间g中实体与关系的表示,conve的模型为:
其中es,eo分别表示头实体与尾实体,rr∈rk是依赖于r的关系,带上上划线是各自embedding的2dreshaping版本,*表示卷积操作,f是一个非线性函数,比如relu,打分函数采用
经过初始化embedding后分别获得实体与关系的embedding,然后将它们reshape成2d形式,之后stack起来,用c个filter对stack后的矩阵进行卷积操作,生成一个特征矩阵τ∈rc×m×n,把τreshape成一个向量v∈rcmn,然后用一个全连接层w∈rcmn×k,将其都射进一个k维空间,之后与目标实体的embedding相乘获得相应的score,最后通过softmax打分函数获得具体分数。
损失函数使用二元的交叉熵。
其中t是标签,p是计算所得分数。p作为后面计算一个知识空间中链路存在的概率,即知识空间中一个三元组成立的概率数值。
步骤三:预测新的对齐实体对
本发明认为,对于一个源知识空间中的实体es,首先收集关于实体es充当头实体或者尾实体的三元组集合,例如<es,r1,et>、<ec,r2,es>。
对于目标知识空间中实体e′s和es是同一个实体的概率为:
其中h(es)是es充当头实体的三元组集合,t(es)是es充当尾实体的三元组集合。其中三元组的成立概率计算公式:
p(<e's,r1,et>)=p_link(<e's,r1,et>)
p_link是指conve模型计算链路存在的概率值,即该三元组成立的概率。
阈值的计算:
其中a是已对齐实体对集合,n是该集合的大小。
选出目标空间中满足概率p(<es,e's>)最大的实体e's,如果p(<es,e's>)超过计算的阈值,那么生成新的跨空间对齐实体对。
步骤四:自学习添加新的训练数据
每次预测出一对新的对齐实体,自学习方法将其视为新的标注对齐种子实体对数据,添加到旧的训练数据中进行训练。添加的过程中,如果新预测实体对和训练数据产生冲突,当前训练数据中存在一个种子实体对<es,e′s>,当前预测出新的实体对<es,e″s>,如果<es,e′s>是最原始的标注数据,那么舍弃新的预测实体对。否则就计算p(<es,e's>)和p(<es,e″s>),选择概率值大的种子实体对。自学习迭代次数超过设定的次数上限,停止迭代,训练对齐模型输出最终的跨语言实体对齐结果。
在上述步骤的基础上,最终输出预测结果,并以此形成用于融合两个知识空间中数据的系统。
- 还没有人留言评论。精彩留言会获得点赞!