一种基于跨分辨率知识蒸馏的神经网络加速方法与流程
本发明涉及深度学习领域,特别涉及一种基于跨分辨率知识蒸馏的神经网络加速方法。
背景技术:
随着大数据的普及和深度学习技术的进步,深度网络取得了长足的进步,并且在人脸识别、行人再识别、物体分类等多个研究任务都取得了重大突破。但是,当前技术在应用场景中面临计算复杂度高、运算速度慢的难题,导致很多深度网络无法满足实时性和资源受限场景的应用需求。
针对神经网络计算复杂度高的问题,hinton等人提出了知识蒸馏的框架:通过很深的网络学习判别鲁棒的特征,把该网络作为教师网络。对于同样的输入,构建一个小而浅的学生网络,并约束学生网络输出与教师网络输出保持一致,通过教师网络知识指导学习网络学习判别鲁棒特征,同时降低神经网络的计算复杂度。
虽然知识蒸馏的方法能在降低神经网络复杂度的同时保持较高的网络性能,但是该方法在应用中并不方便。对于不同的计算复杂度需求,需要重新设计新的网络结构进行知识蒸馏学习,不利于实际应用。此外,网络的计算复杂度主要涉及两方面,一方面是网络的结构,另一方面是输入图像的分辨率。当前知识蒸馏的方法只考虑压缩学生网络的结构和网络参数数量,并没有考虑输入图像的分辨率对计算复杂度的影响。显然,降低输入图像的分辨率能显著降低神经网络提取特征的计算复杂度,但是同时也会降低深度特征的鲁棒性和泛化能力,不利于神经网络的应用。
技术实现要素:
为了克服当前知识蒸馏算法的不足,本发明提出了一种基于跨分辨率知识蒸馏的神经网络加速方法,该方法提出跨分辨率知识蒸馏的框架,通过在高分辨率图像训练教师网络学习鲁棒特征,然后利用教师网络先验知识指导学生网络,提高低分辨率图像深度特征的鲁棒性,实现快速鲁棒的特征提取过程。
本发明的目的通过以下的技术方案实现:一种基于跨分辨率知识蒸馏的神经网络加速方法,包括步骤:
(1)获取同一图像的高分辨率图像和低分辨率图像,将上述高分辨率图像和低分辨率图像分别作为高分辨率训练样本、低分辨率训练样本;
(2)构建跨分辨率知识蒸馏基本框架,该框架包括高分辨率教师网络和低分辨率学生网络;
(3)通过高分辨率样本数据预训练高分辨率教师网络,得到教师网络参数;
(4)固定教师网络参数,并从高分辨率图像提取教师网络输出;利用学生网络提取低分辨率图像特征,并通过跨分辨率蒸馏损失约束高分辨率教师网络和低分辨率学生网络输出特征保持一致;
(5)测试阶段,利用学生网络从低分辨率输入图像提取鲁棒特征。
优选的,所述步骤(1)中,对高分辨率训练样本和低分辨率训练样本均进行归一化预处理,预处理的公式为(x-均值)/标准差,其中x为训练数据,数值在[0,1]区间。
优选的,所述步骤(2)中,高分辨率教师网络和低分辨率学生网络均使用resnet50作为基准网络提取深度特征。
优选的,所述步骤(3)中,通过高分辨率样本数据对高分辨率教师网络进行预训练,以获取高分辨率领域先验知识,方法是:
将教师网络参数表示为wt,高分辨率教师网络的特征提取过程可以表示为:
zt=f(xh;wt)
xh表示高分辨率训练样本,获得教师网络输出特征以后,通过softmax损失学习判别特征,其公式为:
lt=lce(y,zt)
其中y为训练样本对应的类标,lce为交叉熵损失函数。
优选的,所述步骤(4)中,跨分辨率知识蒸馏损失包括两部分,其中一部分是分辨率无关蒸馏损失lrd,另外一部分是成对欧式空间特征约束lpec;跨分辨率知识蒸馏损失的目标函数可以表示为:
l=(1-α)lce(y,zs)+αlrd+βlpec
其中,α是分辨率无关蒸馏损失相关的权值,β是成对欧式空间特征约束相关的权值,lce是交叉熵损失函数,y是训练样本对应的类标,zs是学生网络的输出。
更进一步的,分辨率无关蒸馏损失迫使学生网络模仿教师网络的输出,使得来自不同分辨率输入图像的网络产生分布接近的输出特征,方法是:
采用kl散度约束学生网络和教师网络的响应输出以获取相近的特征概率分布,用公式可以表示为:
其中zt和zs对应教师网络和学生网络的输出,σ(.)对应softmax函数的响应,t是平滑蒸馏损失的参数,n表示样本个数,lkl(.)是kl散度,其公式为:
其中
更进一步的,所述成对欧式空间特征约束直接在特征空间对教师网络和学生网络的特征进行约束,使得教师网络的输出和学生网络的输出在欧式空间尽可能接近,用公式表示为:
其中,(xh,xl)表示高分辨率训练样本、低分辨率训练样本,n表示样本个数,,wt代表教师网络的参数,ws代表学生网络的参数。
本发明与现有技术相比,具有如下优点和有益效果:
1)本发明通过降低输入图像的分辨率减少神经网络特征提取的计算复杂度,提高运算速度,同时通过蒸馏高分辨率教师网络的先验知识提高低分辨率学生网络的判别能力和泛化能力,在提高特征提取速度的同时保持网络的性能。
2)本发明在平衡网络计算复杂度和性能方面比传统的知识蒸馏算法更有优势,能以更低的计算复杂度获取更好的识别准确率。
3)本发明具有很高的灵活度,能根据应用环境的计算资源调整学生网络的输入图像大小,满足实际应用中的多元化需求。
附图说明
图1是本发明总框架图。
图2是本发明使用的测试图样例。
图3是本发明在dukemtmc数据库与其他主流方法对比结果。
图4是本发明在market-1501数据库与其他主流方法对比结果。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例1
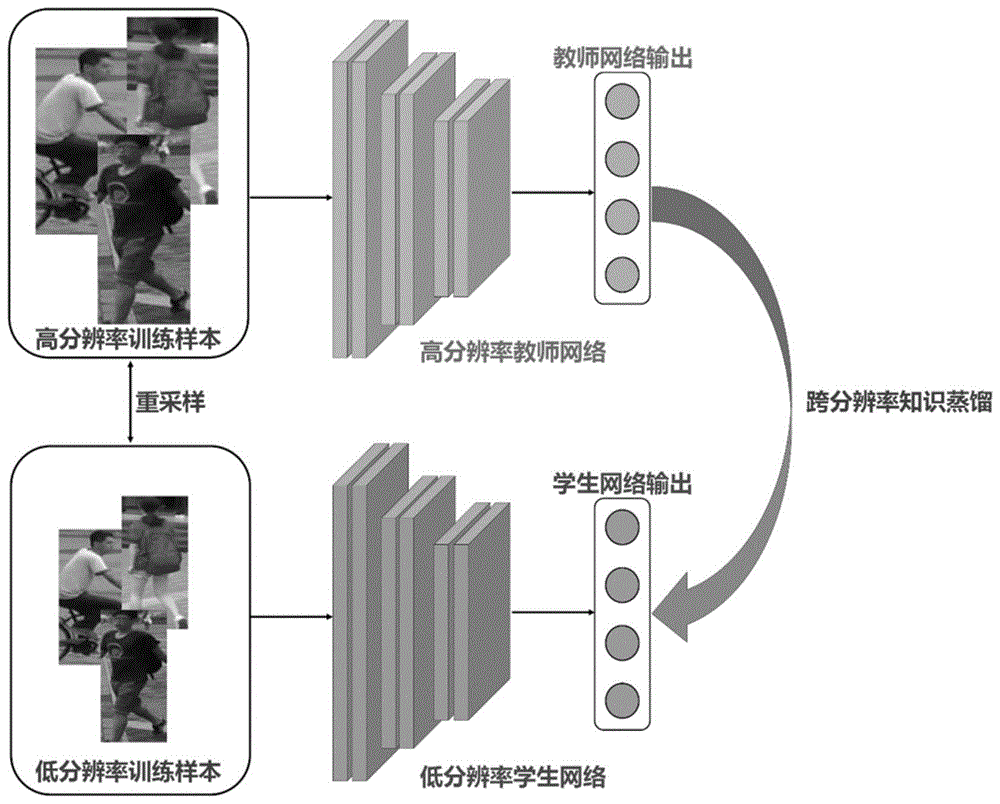
如图1所示,本实施例提供一种基于跨分辨率知识蒸馏的神经网络加速方法,该方法包括高分辨率教师网络和低分辨率学生网络,其中,高分辨率教师网络通过从高分辨率训练样本学习和提取鲁棒的特征表示,低分辨率学生网络通过低分辨率输入快速提取深度特征,并通过跨分辨率知识蒸馏损失提取高分辨率教师网络的先验知识,提高特征的判别能力。
本实施例中,首先需要根据应用环境需求重采样获取高分辨率训练样本和低分辨率训练样本,构建高分辨率教师网络和低分辨率学生网络,主要包括获取样本数据、高分辨率教师网络预训练、基于跨分辨率蒸馏的低分辨率学生网络训练三个步骤。
在获取样本数据步骤,获取高分辨率训练样本
本实施例中构建的跨分辨率知识蒸馏基本框架包括高分辨率教师网络和低分辨率学生网络,均通过利用上述训练样本训练得到。其中网络可使用resnet50作为基准网络提取深度特征。
进行跨分辨率知识蒸馏学习之前,首先需要通过高分辨率样本训练判别的高分辨率教师网络,获取高分辨率领域先验知识。令网络参数表示为wt,高分辨率教师网络的特征提取过程可以表示为:
zt=f(xh;wt)
获得教师网络输出特征以后,我们通过softmax损失学习判别特征,其公式为:
lt=lce(y,zt)
其中y为训练样本对应的类标,lce为交叉熵损失函数。
获得预训练的教师网络以后,第二步是将教师网络的先验知识迁移到学生网络中去,克服分辨率变化带来的特征差异,提高低分辨率学生网络的判别能力和泛化能力。给定成对的高低分辨率训练样本(xh,xl),可以通过教师网络和学生网络提取对应的网络输出(f(xh;wt),f(xl;ws)),并通过跨分辨率知识蒸馏损失(rkd)进行约束以确保来自高分辨率图像和低分辨率图像的深度特征保持一致。
具体的,该损失包括两部分,其中一部分是分辨率无关蒸馏损失(rd),另外一部分是成对欧式空间特征约束(pec)。
所述分辨率无关蒸馏损失迫使学生网络模仿教师网络的输出,使得来自不同分辨率输入图像的网络产生分布接近的输出特征,从而减少不同分辨率之间的鸿沟。具体地,本实施例采用kl散度约束学生网络和教师网络的响应输出以获取相近的特征概率分布,用公式可以表示为:
其中zt和zs对应教师网络和学生网络的输出,σ(.)对应softmax函数的响应,t是平滑蒸馏损失的参数,lkl(.)是kl散度,其公式为:
其中
所述成对欧式空间特征约束直接在特征空间对教师网络和学生网络的特征进行约束,使得教师网络的输出和学生网络的输出在欧式空间尽可能接近,用公式可以表示为:
最终,跨分辨率知识蒸馏过程的目标函数可以表示为:
l=(1-α)lce(y,zs)+αlrd+βlpec
其中,α是分辨率无关蒸馏损失相关的权值,β是成对欧式空间特征约束相关的权值。
本实例通过实验对方法的效果进行说明。本实施例采用dukemtmc和market-1501这两个主流的行人再识别数据库进行网络训练和测试:dukemtmc数据集共有1812类行人的36411张图像样本,来自8个不同的摄像头。其中,训练集包括702类行人的16522张训练样本,测试集包括702类行人的17661张测试样本,另有402个干扰行人图像;market-1501数据集共有1501类行人的32668张图像样本,来自6个不同的摄像头。其中,训练集包括751类行人的12936张训练样本,测试集包括750类行人的19732张训练样本。dukemtmc和market-1501行人数据库的实例如图2所示。在本实施例中,使用resnet50作为基准网络提取深度特征。测试阶段,使用累计匹配特性(cmc)和平均精度均值(map)去评估不同算法的识别效果,并用每秒浮点运算次数(flops)去衡量不同算法的计算复杂度。在这两个数据库,统一设置α=0.1,β=1,t=8。实验结果如表1所示。
表1不同网络结构实验结果
从表1可以看到,相比于用高分辨率图像(384*128)训练的resnet50模型,用更小的模型(resnet18)进行训练会导致性能下降:在dukemtmc数据库,首位识别率从85.7%降到83.3%,map从73.6%降到69%,在market数据库,首位识别率从93.9%降到91.9%,map从84.7%降到79.9%;类似地,用更低的分辨率(128*128)进行训练也会导致性能下降:在dukemtmc数据库,首位识别率从85.7%降到83.3%,map从73.6%降到69.2%,在market数据库,首位识别率从93.9%降到90.8%,map从84.7%降到78.4%。另外,rkd损失函数能有效提高低分辨率学生网络的性能,在dukemtmc数据库上,首位识别率和map分别提升2%和3.6%,在market-1501数据库,首位识别率和map分别提升2.5%和5%。对比传统的知识蒸馏框架(kd),本实施例方法使用同样的损失函数,能取得非常接近甚至更优的识别精度,而且需要的计算复杂度更低(2.1×109对比3×109)。与教师网络相比,基于rkd的学生网络能取得非常接近的精度,譬如在market1501数据库,首位识别率的精度是93.3%对93.9%,但是需要的计算复杂度降到了1/3左右(2.1×109对比6.1×109)。
图3和图4对比了rkd方法和其他一些主流方法的综合性能,其中图3显示的是在dukemtmc数据库上的对比结果,图4显示的是在market-1501数据库上的对比结果。可以看到,相比于kd方法,rkd方法能在用更小的计算复杂度的前提下取得更优的识别准确率。相比于教师网络,rkd方法能用小得多的计算复杂度获得接近的识别准确率。
表2显示了消融实验的结果,如下:
表2姿态算法的可视化结果
从表2可以看到,成对欧式空间特征约束能提升学生网络的性能,在dukemtmc从83.3%/69.2%的首位识别率/map提升到了83.8%/70.7%,在market-1501从90.8%/78.4%的首位识别率/map提升到了92.8%/81.3%。加入分辨率无关蒸馏损失能进一步提升学生网络的性能,在dukemtmc上提升了1.5%/2.1%的首位识别率/map,在market-1501上提升了0.5%/2.1%的首位识别率/map。
本发明利用跨分辨率蒸馏损失实现高低分辨率领域之间的知识传播,通过从低分辨率图像提取特征加速网络,减少计算复杂度,利用高分辨率图像先验知识提高深度特则的判别能力和泛化能力,在大幅度减少深度网络计算复杂度的同时保持优秀的识别性能。本发明具有应用灵活,综合性能优异的特点。
本领域普通技术人员可以意识到,结合本发明中所公开的实施例描述的各示例的算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
另外,在本发明实施例中的实现各算法步骤的功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以是两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分,或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!