基于Hadoop的DGCNN模型加速方法与流程
本发明涉及云计算技术,特别涉及一种基于hadoop的dgcnn模型加速方法。
背景技术:
dgcnn全称dilategatedconvolutionalneuralnetwork,即“膨胀门卷积神经网络”,基于cnn和简单的attention机制,融合较新的膨胀卷积、门卷积,并增加了一些人工特征,最终使得模型在轻、快的基础上达到最佳的效果。dgcnn适用于webqa式的任务,即“一个问题+多段材料”的格式,能够从多段材料中共同决策出问题的精准答案。dgcnn已经在多个数据集上证明其准确性。
dgcnn在训练模型的过程中,涉及到两轮卷积计算、两轮注意力机制整合序列信息以及一次位置向量计算,这些过程中包含大量矩阵和浮点数运算,使得dgcnn模型有较大的参数冗余,训练过程消耗了大量时间,使得训练模型对硬件成本以及时间成本要求较高。虽然现有的单机cpu+gpu系统很大程度上提高了卷积神经网络的运算速度,但是当面对tb级甚至pb级的海量数据时,由于处理器和存储器有限,仍然显得力不从心。
技术实现要素:
本发明的目的在于提供一种基于hadoop的dgcnn加速方法,用于解决上述现有技术的问题。
本发明一种基于hadoop的dgcnn加速方法,其中,包括:利用mapreduce实现训练样本和计算答案初始位置与结束位置的并行化,将整个训练数据集和糅合了问题编码、位置向量和人工提取特征的卷积值分为多个小块,分布式地存储在hadoop平台的每个节点上,每个节点都存储一个相同的完整的卷积神经网络,各个节点使用该节点存储的数据对网络进行训练以及求解答案位置,对于各小块中的每一个样本,节点都执行一次前向传播和反向传播计算,得出各个权值和偏置的局部改变量以及位置信息,接着汇总每个权值和偏置的局部改变量从而得到全局改变量,多次用全局改变量更新权值之后,获得最终网络,得到全局位置信息;使用cuda进行特征矩阵、神经元以及权值的并行化,为每一层的特征矩阵启动一个线程格,线程格中线程块的数目大于等于特征矩阵数目,若线程块数目与线程图数目相等,则一个线程块对应一个特征矩阵;若线程块数目大于线程图数,将特征矩阵分为不重叠的小块,每个小块对应一个线程块,使得特征矩阵的并行,线程块中每个线程对应一个神经元,使得神经元并行,在误差反向传播中,用一个线程对应一个权值,计算该权值的局部梯度改变量,使得权值并行。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,对于训练数据集,需要对训练数据集进行预处理,包括去除停用词、降噪以及语句标注处理。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,进行训练样本的并行化,包括:采用主从结构基于数据并行的方式训练网络:从节点存储相同的网络结构和训练数据集中部分数据,各从节点并行使用本地存储的数据训练网络,计算出权值和偏置的局部梯度改变量之后做一次汇总,求得权值和偏置的全局梯度改变量,然后用全局梯度改变量更新权值和偏置,多次迭代至全体样本收敛或达到最大迭代次数。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,卷积神经网络mapreduce分解方法,包括:整体架构采用主从结构基于数据并行的方式训练网络:从节点存储相同的网络结构和训练数据集中部分数据,各从节点并行使用本地存储的数据训练网络,计算出权值和偏置的局部梯度改变量之后做一次汇总,求得权值和偏置的全局梯度改变量,然后用全局梯度改变量更新权值和偏置,多次迭代至全体样本收敛或达到最大迭代次数;cnn分解过程中,首先mapreduce模型的mapper类首先调用setup()函数,从分布式缓存中读取网络参数,包括网络层、各层神经元数及权值和偏置,并对网络进行初始化,然后调用map()函数接受键值对,经过前向传播和反向传播,计算出网络每一个权值w的局部梯度改变量,生成中间键值对,并将中间结果暂时存储在内存,达到设定值之后写入磁盘,对于每一个split,都将启动一个map任务;然后用reducer类执行reduce任务,以网络中的权值和权值局部梯度改变量列表为输入,统计和求出权值和全局梯度改变量,将权值和权值全局梯度改变量以键值对的形式输出;对于每一个权值都启动一个reduce任务;如果多次mapreduce任务之后,在规定误差范围内或者满足最大迭代次数,结束网络的训练过程。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,将mapreduce模型的分布式地存储到hadoop平台,包括:在hadoop平台中,主节点上的jobtracker负责任务的划分、调度以及失败任务的重新执行,各从节点上的tasktracker负责卷积神经网络的前向传播、反向传播等计算;在计算开始之前,tasktracker先从分布式缓存中读取网络参数信息并初始化网络,然后执行map任务,从split小块中分离出类标号和样本值,接着样本值作为输入开始前向传播和误差反向传播,在反向传播中,计算出每个权值和偏置的局部改变量并输出,当所有训练样本计算完成之后,经过中间数据本地压缩及混排之后,jobtracker启动一个tasktracker执行reduce任务,汇总每一个权值以及偏置的局部梯度改变量得到权值以及偏置的全局改变量,然后对权值以及偏置做一次批处理更新并写入全局文件中;通过mapreduce编程模型将复杂的运行于云平台上的并行计算过程高度地抽象到map和reduce两个函数,map和reduce两个函数的功能是按一定的映射规则将输入的键值对转换成另一个或另一批输出键值对。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,在各个节点进行卷积运算时用卷积运算加速方法进一步加速计算过程,加快了矩阵乘法的时间,包括:
一个n*n的矩阵可以由一个n*1和一个1*n的矩阵相乘得到,通常,一次卷积运算产生的参数个数为:
input_channels×n×n×output_channels;
把卷积核大小分解成n*1和1*n之后,参数的个数就变为:
2×input_channels×n×output_channels。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,用cuda方法并行化卷积神经网络的attention前向传播,将每一个特征矩阵映射到一个线程块上,特征矩阵上的各个神经元映射到线程块上的各个线程上,用线程格的x,y,z三个维度分别对应到每层特征矩阵的宽、高以及数量上,在核函数的设置形式为:kernel<z,x,y>,该核函数启动了z个线程块,每个线程块包含x*y个线程,共启动了z*x*y个线程,由于一个线程块中线程数目最多为512,如果特征矩阵中神经元数目大于这个值,将特征矩阵分割,使用多个线程块对应一个特征矩阵。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,前向传播cuda并行化包括:假设当前卷积层或子采样层有m个特征矩阵,每个特征矩阵的宽为fw,高为fh,那么核函数设置为kernel<m,fw,fh>,启动的线程数目与神经元数目相等并一一对应,使得每个线程计算一个神经元的输出;进行子采样层误差反向传播cuda并行化包括:假设子采样层特征矩阵数目为m,特征矩阵大小为a*b,前层卷积层特征图数目也为m,特征矩阵大小为c*d,在计算偏置和权值的局部改变量的核函数设置为kernel<m,a,b>,计算前层神经元的输出误差的核函数设置为kernel<m,c,d>,首先并行计算出每个神经元的输入误差,接着使用每个线程块中的一个线程来计算该线程块对应偏执的局部梯度改变量,然后,每个线程读取对应神经元的输入误差并通过子采样窗口与千层神经元的输出求取乘积和,并保存在共享内存中,最后,使用线程块内的一个线程将共享内存中保存的数据累加即求的线程块对应的权值的局部梯度改变量;进行卷积层误差反向传播,包括:假设当前卷积层有n1个特征矩阵,特征矩阵大小为a*b,卷积窗口大小为kw×kh,前层子采样层有n2个特征矩阵,特征矩阵大小为c*d,为使得所有权值并行求得局部梯度改变量,计算权值的局部改变量的核函数设置为kernel<n1×n2,kw,kh>,线程数与卷积层权值个数相等,线程块数与权值矩阵数相等,每个线程块对应一个权值矩阵,在计算过程中,将权值矩阵对应的前层特征矩阵中神经元的输出和卷积层对应特征矩阵神经元的输入误差读入共享内存,计算千层神经元的输出误差的核函数设置为kernel<n2,c,d>,计算偏置的局部改变量的核函数。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,利用gpu进一步并行化map函数,加速其计算过程,在gpu加速的平台内,cpu负责i/o操作,gpu加速map()函数的运算过程,gpu运算结束后,在cpu的控制下将计算结果拷贝到内存,在hadoop平台上,从节点在cpu线程中执行map任务时,从单个cpu线程的计算来看,仍然相当于卷积神经网络在单机上串行执行,在gpu加速的异构hadoop平台中,cpu负责控制和i/o操作,网络的特征矩阵、神经元和权值映射到线程块和线程上并行计算,达到加速运算的目的。
根据本发明的基于hadoop的dgcnn加速方法的一实施例,其中,进行求位置信息的并行化包括:
训练数据集是把材料和问题分布到不同的节点上,接下来由各个节点分别求解每一段材料的答案位置信息,通过求出答案在材料中的起始位置与结束为止,而求解答案的位置信息,在不同节点上分别求出材料的答案位置之后,再根据各个材料的打分,求出问题的解。
本发明通过云计算利用多台机器并行处理数据,解决了单机处理器速度慢,无法处理大规模数据的问题。本发明提出了利用mapreduce并行化训练卷积神经网络的方法,并部署到hadoop云计算平台,使得算法具有更快的速度。
附图说明
图1所示为基于hadoop的dgcnn加速方法整体流程图;
图2所示为卷积神经网络的mapreduce并行化分解过程图;
图3为线程格与特征矩阵和神经元映射示意图;
图4为hadoop平台数据流图;
图5为gpu并行加速hadoop平台数据流图。
具体实施方式
为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
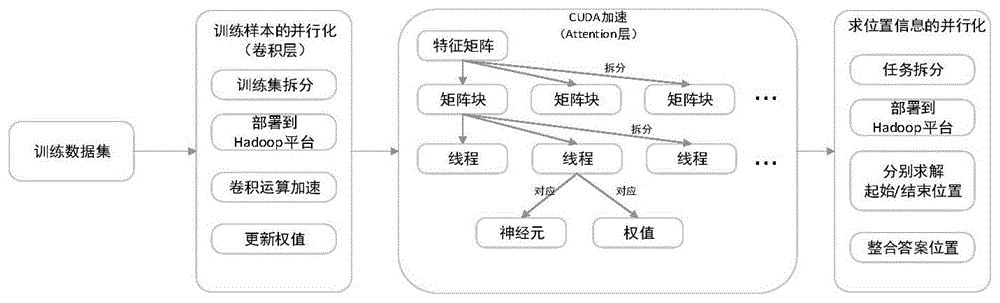
图1所示为基于hadoop的dgcnn加速方法整体流程图,如图1所示,基于hadoop的dgcnn加速整体流程包括:利用hadoop平台实现训练样本的并行性、特征矩阵的并行性、神经元的并行性、权值的并行性以及求答案位置的并行性;和使用cuda(computeunifieddevicearchitecture)技术实现特征矩阵、神经元、权值的并行化。
(1)利用mapreduce实现训练样本和计算答案初始位置与结束位置的并行化,即将整个训练数据集和糅合了问题编码、位置向量和人工提取特征的卷积值分为一个一个小块,分布式地存储在hadoop平台的每个节点上。每个节点都存储一个相同的完整的卷积神经网络,各个节点使用该节点存储的数据对网络进行训练以及求解答案位置。对于小块中的每一个样本,节点都执行一次前向传播和反向传播计算,得出各个权值和偏置的局部改变量以及位置信息,接着汇总每个权值和偏置的局部改变量从而得到全局改变量,多次用全局改变量更新权值之后,获得最终网络,也通过相同的方法汇总求得的局部位置信息从而得到全局位置信息。在这种并行方式中,训练数据集中所有的样本以及位置信息经过网络计算之后进行一次通信,因此这是一种“粗粒度”的并行方式,可以有效地减少平台中各个节点的通信开销,有利于在分布式网络环境下实现。
(2)使用cuda技术实现了特征矩阵、神经元、权值的并行化。为每一层的特征矩阵启动一个线程格,线程格中线程块的数目大于等于特征矩阵数目。若线程块数目与线程图数目相等,则一个线程块对应一个特征矩阵;若线程块数目大于线程图数,可将特征矩阵分为不重叠的小块,每个小块对应一个线程块,这样就做到了特征矩阵的并行。线程块中每个线程对应一个神经元,这样就做到了神经元并行。在误差反向传播中,用一个线程对应一个权值,计算该权值的局部梯度改变量,这就实现了权值并行。
下面针对基于hadoop的dgcnn加速方法的详细步骤进行介绍。
训练数据集包括:
首先需要对训练数据集进行预处理,包括去除停用词、降噪、语句标注等。由于dgcnn模型更多的是处理类似“问题-多文本”的问答系统的问题,所以数据格式应当形如:
<问题>社保缴纳多少年可以领养老金</问题>;
<答案>15年</答案>;
<材料1>最好不辞,交够15年到退休就可以领养老金了,如果有特殊原因非要辞,可以个人接着交</材料1>;
<材料2>您好!养老保险缴纳满15年。达到退休年龄可以领取养老金。</材料2>;
<材料3>在生活中,每个人都会缴纳社保,多少年可以领取退休金呢,在下文中为大家介绍</材料3>;
训练样本的并行化,包括:
(1)训练数据集拆分
卷积神经网络mapreduce并行分解的总体思路是在平台中采用主从结构基于数据并行的方式训练网络:从节点存储相同的网络结构和训练数据集中部分数据,各从节点并行使用本地存储的数据训练网络,计算出权值和偏置的局部梯度改变量之后做一次汇总,求得权值和偏置的全局梯度改变量,然后用全局梯度改变量更新权值和偏置,多次迭代至全体样本收敛或达到最大迭代次数。
图2所示为卷积神经网络的mapreduce并行化分解过程图,如图2所示,卷积神经网络mapreduce分解方法,包括:
执行map任务的主题是mapper类。mapper类首先调用setup()函数,从分布式缓存中读取网络参数,包括网络层、各层神经元数及权值和偏置,并对网络进行初始化。然后调用map()函数接受键值对,经过前向传播和反向传播,计算出网络每一个权值w的局部梯度改变量,生成中间键值对,并将中间结果暂时存储在内存,达到设定值之后写入磁盘。对于每一个split,都将启动一个map任务。
执行reduce任务的主体是reducer类。类调用reduce()函数,以网络中的权值和权值局部梯度改变量列表为输入,统计、求出权值和全局梯度改变量。然后将权值和权值全局梯度改变量以键值对的形式输出。对于每一个权值都启动一个reduce任务。
如果多次mapreduce任务之后,神经网络的权值变化已经很小,在规定误差范围内或者满足最大迭代次数,结束网络的训练过程。
(2)将mapreduce模型的训练部署到hadoop平台
在hadoop平台中,主节点上的jobtracker负责任务的划分、调度以及失败任务的重新执行,各从节点上的tasktracker负责卷积神经网络的前向传播、反向传播等计算。在计算开始之前,tasktracker先从分布式缓存中读取网络参数信息并初始化网络,然后执行map任务,即从split小块中分离出类标号和样本值,接着样本值作为输入开始前向传播和误差反向传播。在反向传播中,计算出每个权值和偏置的局部改变量并输出。当所有训练样本计算完成之后,经过中间数据本地压缩及混排之后,jobtracker启动一个tasktracker执行reduce任务,即汇总每一个权值、偏置的局部梯度改变量得到权值、偏置的全局改变量,然后对权值、偏置做一次批处理更新并写入全局文件中。
mapreduce编程模型将复杂的运行于云平台上的并行计算过程高度地抽象到map和reduce两个函数,这两个函数的功能是按一定的映射规则将输入的键值对转换成另一个或另一批输出键值对,大大简化了编程的难度。使用mapreduce编程模型的任务必须符合一个基本要求:待处理的数据集可以分解成为多个互相独立的子数据集,并且每个子数据集完全可以并行地进行计算。
(3)将卷积层的训练数据进行卷积运算加速
此外,由于卷积运算的过程是两个矩阵相乘得到一个新的矩阵,在各个节点进行卷积运算时也可用如下的卷积运算加速方法进一步加速计算过程,从而加快了矩阵乘法的时间:
一个n*n的矩阵可以由一个n*1和一个1*n的矩阵相乘得到,通常,一次卷积运算产生的参数个数为:
input_channels×n×n×output_channels
这样的运算过程会产生大量的参数,为了把参数个数减少,我们把卷积核大小分解成n*1和1*n之后,参数的个数就变为
2×input_channels×n×output_channels
参数的数量与之前相比少了n/2倍,参数的个数减少了,计算资源的消耗也相应减少。同时要避免在接近输入卷积层的地方进行分解。同时,分接一个3*3的卷积核会影响网络的性能,应当在具有较大卷积核的地方进行分解,这样就可以更快的得到卷积运算结果。
利用gpu加速的方法包括:
在dgcnn中,对于训练数据集进行卷积计算既是对训练数据集进行了特征提取,之后通过attentionencoder层要对得到的特征进行特征编码从而得到了问题的编码,之后将材料的词向量与问题编码拼接,再进行一次卷积运算与attentionencoder就可以得到“问题-材料”的总编码,但是用传统的运算方法在此过程中会消耗大量的时间,本发明基于gpu和cuda并行化技术对attentionencoder过程进行加速。
图3为线程格与特征矩阵和神经元映射示意图,如图3所示,用cuda技术并行化卷积神经网络的attention前向传播过程,最直观的方法就是将每一个特征矩阵映射到一个线程块上,特征矩阵上的各个神经元映射到线程块上的各个线程上,即用线程格的x,y,z三个维度分别对应到每层特征矩阵的宽、高、数量上。在核函数的设置形式为:kernel<z,x,y>。该核函数启动了z个线程块,每个线程块包含x*y个线程,共启动了z*x*y个线程。由于一个线程块中线程数目最多为512。如果特征矩阵中神经元数目大于这个值,可以将特征矩阵分割,使用多个线程块对应一个特征矩阵。
(1)前向传播cuda并行化
假设当前卷积层或子采样层有m个特征矩阵,每个特征矩阵的宽为fw,高为fh,那么核函数设置为kernel<m,fw,fh>,启动的线程数目与神经元数目相等并一一对应,使得每个线程计算一个神经元的输出。由于计算单元从片内共享内存读取数据的速度远远快于从全局内存读取数据的速度,因此将需要多次读取的数据线读入到片内共享内存。
(2)子采样层误差反向传播cuda并行化
假设子采样层特征矩阵数目为m,特征矩阵大小为a*b,前层卷积层特征图数目也为m,特征矩阵大小为c*d。在计算偏置和权值的局部改变量的核函数设置为kernel<m,a,b>,计算前层神经元的输出误差的核函数设置为kernel<m,c,d>。首先并行计算出每个神经元的输入误差,接着使用每个线程块中的一个线程来计算该线程块对应偏执的局部梯度改变量。然后,每个线程读取对应神经元的输入误差并通过子采样窗口与千层神经元的输出求取乘积和,并保存在共享内存中。最后,使用线程块内的一个线程将共享内存中保存的数据累加即求的线程块对应的权值的局部梯度改变量。
(3)卷积层误差反向传播
假设当前卷积层有n1个特征矩阵,特征矩阵大小为a*b,卷积窗口大小为kw×kh。前层子采样层有n2个特征矩阵,特征矩阵大小为c*d。为使得所有权值并行求得局部梯度改变量,计算权值的局部改变量的核函数设置为kernel<n1×n2,kw,kh>。线程数与卷积层权值个数相等,线程块数与权值矩阵数相等,每个线程块对应一个权值矩阵。在计算过程中,将权值矩阵对应的前层特征矩阵中神经元的输出和卷积层对应特征矩阵神经元的输入误差读入共享内存。计算千层神经元的输出误差的核函数设置为kernel<n2,c,d>,计算偏置的局部改变量的核函数与子采样层的计算偏置局部改变量的核函数类似。
(4)整合了gpu加速的并行算法设计
在上文的并行计算算法中,计算量最大的是map()函数,所以利用gpu进一步并行化map函数,加速其计算过程。map()函数在hadoop云计算平台和利用gpu加速的map()函数在异构hadoop云计算平台上的数据流分别如图4和图5所示。图4为hadoop平台数据流图;图5为gpu并行加速hadoop平台数据流图。
在gpu加速的平台内,cpu负责i/o操作,gpu加速map()函数的运算过程,gpu运算结束后,在cpu的控制下将计算结果拷贝到内存。
在hadoop平台上,从节点在cpu线程中执行map任务时,从单个cpu线程的计算来看,仍然相当于卷积神经网络在单机上串行执行。在gpu加速的异构hadoop平台中,cpu只负责控制和i/o操作,网络的特征矩阵、神经元和权值映射到线程块和线程上并行计算,达到加速运算的目的。
求位置信息的并行化包括:
在前面的训练构成中,dgcnn模型已经得到了“问题-材料”的总编码以及各个材料的打分,进而可以得到材料中问题答案位置的预测,对于求位置信息的并行化,数据集是把材料和问题分布到不同的节点上,接下来由各个节点分别求解每一段材料的答案位置信息,其中的部署到hadoop平台、更新权值与步骤二中对问题求解问题编码的方法基本一致,所不同的是求解问题编码是对整个问题语句求其特征向量,而求解答案的位置信息只需求出答案在材料中的起始位置与结束为止。在不同节点上分别求出材料的答案位置之后,再根据各个材料的打分(视为权重),求出问题的解。
本发明通过云计算利用多台机器并行处理数据,解决了单机处理器速度慢,无法处理大规模数据的问题。本发明提出了利用mapreduce并行化训练卷积神经网络的方法,并部署到hadoop云计算平台,使得算法具有更快的速度。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!