用于分布式文件系统的加密的制作方法
用于分布式文件系统的加密
[0001]
优先权要求
[0002]
本申请要求于2018年6月8日提交的标题为“用于分布式文件系统的加密”的美国临时专利申请第62/682,198号和于2019年2月13日提交的标题为“用于分布式文件系统的加密”的美国专利申请第16/274,541号的优先权。
背景技术:
[0003]
通过将数据存储的传统方法与参考附图在本公开的其余部分中阐述的本申请的方法和系统的一些方面进行比较,传统方法的限制和缺点对于本领域技术人员而言将变得显而易见。
[0004]
引用并入
[0005]
标题为“分布式擦除编码虚拟文件系统”的美国专利申请第15/243,519号通过引用整体并入本文。
技术实现要素:
[0006]
基本上如在权利要求中更完整地阐述并结合至少一个附图所示出和/或描述的,提供了用于在分布式文件系统中加密的方法和系统。
附图说明
[0007]
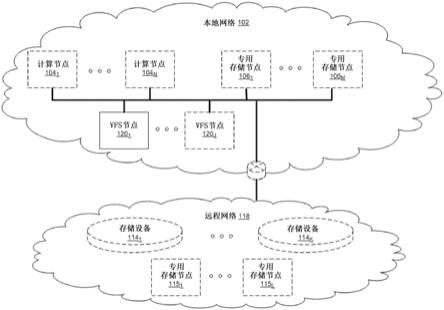
图1示出了根据本公开的各个方面的分布式文件系统的各种示例性配置。
[0008]
图2示出了根据本公开的各个方面的分布式文件系统节点的示例性配置。
[0009]
图3示出了根据本公开的示例性实现方式的分布式文件系统的另一种形式。
[0010]
图4示出了根据本公开的一个或多个实施例的加密文件系统中的计算设备的实例。
[0011]
图5示出了根据本公开的一个或多个实施例的计算设备的集群的实例。
[0012]
图6是示出用于从加密文件系统中的客户端读取的示例性方法的流程图。
[0013]
图7是示出用于向加密文件系统中的客户端写入的示例性方法的流程图。
[0014]
图8示出了两个分布式故障容错地址空间驻留在多个固态存储磁盘上的示例性实现方式。
[0015]
图9示出了根据本公开的示例性实现方式的可以用于保护存储到虚拟文件系统的非易失性存储器中的数据的前向纠错方案。
具体实施方式
[0016]
传统上,文件系统对元数据结构(例如,目录、文件、属性、文件内容等)使用集中控制。如果本地文件系统能够从单个服务器访问而该服务器发生故障,那么如果没有进一步的保护,则文件系统的数据可能丢失。为了增加保护,一些文件系统(例如,由netapp提供的)已经以主动-被动方式使用一对或多对控制器来在两个或以上计算机上复制元数据。其
他解决方案已经以集群方式使用了多个元数据服务器(例如,由ibm gpfs、dell emc isilon、lustre等提供的)。然而,因为传统集群系统中的元数据服务器的数量被限制在较小的数量,所以这样的系统不能扩展。
[0017]
本发明中的系统能够应用于小集群,并且还能够扩展到成千上万个节点。讨论了关于非易失性存储器(nvm)(例如,固态驱动器(ssd)形式的闪存)的示例性实施例。nvm可以被划分为4kb的块(block)和128mb的组块(chunk)。盘区(extents)可以存储在易失性存储器中,例如用于快速访问的ram,也可以由nvm存储装置备份。盘区可以存储用于块的指针,例如,针对存储在块中的1mb数据存储256个指针。在其他实施例中,也可以使用更大或更小的存储器分区。本公开中的元数据功能可以有效地分布在许多服务器上。例如,在大负载针对文件系统命名空间的特定部分的“热点”的情况下,该负载可以跨多个节点分布。
[0018]
图1示出了根据本公开的各个方面的分布式文件系统的各种示例性配置。图1所示的是局域网(lan)102,其包括一个或多个节点120(由从1到j的整数索引,其中j≥1),并且任选地包括(由虚线表示):一个或多个专用存储节点106(由从1到m的整数索引,其中m≥1)、一个或多个计算节点104(由从1到n的整数索引,其中n≥1)和/或将lan 102连接到远程网络118的边缘路由器。远程网络118任选地包括一个或多个存储服务114(由从1到k的整数索引,其中k≥1)和/或一个或多个专用存储节点115(由从1到l的整数索引,其中l≥1)。
[0019]
每个节点120
j
(j是整数,其中1≤j≤j)是网络计算设备(例如,服务器、个人计算机等),其包括用于直接在设备104
n
的操作系统上和/或在设备104
n
中运行的一个或多个虚拟机中运行进程(例如,客户端进程)的电路。
[0020]
计算节点104是可以在没有虚拟后端的情况下运行虚拟前端的网络设备。计算节点104可以通过将单根输入/输出虚拟化(sr-iov)纳入网络接口卡(nic)并占用一个完整的处理器核来运行虚拟前端。可替换地,计算节点104可以通过经由linux内核网络栈路由联网并使用内核进程调度来运行虚拟前端,因此不要求完整的核。在用户不想为文件系统分配完整的核或者网络硬件与文件系统要求不兼容的情况下,这将非常有用。
[0021]
图2示出了根据本公开的各方面的节点的示例性配置。节点包括前端202和驱动程序208、存储器控制器204、后端206以及ssd代理214。前端202可以是虚拟前端;存储器控制器204可以是虚拟存储器控制器;后端206可以是虚拟后端;并且驱动程序208可以是虚拟驱动程序。如本公开中所使用的,虚拟文件系统(vfs)进程是实现前端202、存储器控制器204、后端206以及ssd代理214中的一者或多者的进程。因此,在示例性实现方式中,可以在客户端进程和vfs进程之间共享节点的资源(例如,处理和存储器资源)。vfs的进程可以被配置为需要相对少量的资源以使对客户端应用的性能所造成的影响最小。前端202、存储器控制器204和/或后端206和/或ssd代理214可以在主机201的处理器上或网络适配器218的处理器上运行。对于多核处理器,不同的vfs进程可以在不同的核上运行,并且可以运行服务的不同子集。从客户端进程212的角度来看,与虚拟文件系统的接口独立于vfs进程在其上运行的特定物理机器。客户端进程仅要求存在驱动程序208和前端202以便为它们提供服务。
[0022]
节点可以被实现为直接在操作系统上运行的单个租户服务器(例如,裸机(bare-metal)服务器)或者实现为裸机服务器内的虚拟机(vm)和/或容器(例如,linux容器(lxc))。vfs可以作为vm环境在lxc容器内运行。因此,在vm内部,唯一可以运行的是包括vfs的lxc容器。在经典的裸机环境中,存在用户空间应用程序,并且vfs在lxc容器中运行。如果
服务器正在运行其他容器化的应用程序,则vfs可以在容器部署环境(例如,docker)的管理范围之外的lxc容器内运行。
[0023]
节点可以由操作系统和/或虚拟机监视器(vmm)(例如,超级管理程序)来服务。vmm可用于在主机201上创建和运行节点。多个核可以驻留在运行vfs的单个lxc容器内,并且vfs可以使用单个linux内核在单个主机201上运行。因此,单个主机201可以包括多个前端202、多个存储器控制器204、多个后端206和/或一个或多个驱动程序208。驱动程序208可以在lxc容器的范围之外的内核空间中运行。
[0024]
sr-iov pcie虚拟功能可以用于在用户空间222中运行网络栈210。sr-iov允许pci express隔离,使得可以在虚拟环境上共享单个物理pci express,并且可以向单个物理服务器机器上的不同虚拟组件提供不同的虚拟功能。i/o栈210使vfs节点能够绕过标准tcp/ip栈220并直接与网络适配器218通信。可以通过无锁队列向vfs驱动程序208提供可移植操作系统接口(posix)vfs功能。sr-iov或全pcie物理功能地址也可以用于在用户空间222中运行非易失性存储器规范(nvme)驱动程序214,从而完全绕过linux io栈。nvme可用于访问经由pci express(pcie)总线连接的非易失性存储介质216。非易失性存储介质220可以是例如固态驱动器(ssd)的形式的闪存或者ssd或存储器模块(dimm)形式的存储级内存(scm)。其他实例可以包括存储级存储技术,比如3d-xpoint。
[0025]
通过将物理ssd 216与ssd代理214和网络210耦接,ssd可以被实现为网络设备。可替换地,ssd可以通过使用诸如nvme-of(基于fabrics的nvme)的网络协议来实现为网络附加的nvme ssd 222或224。nvme-of可以允许使用冗余网络链路来访问nvme设备,从而提供更高级别的容错性。网络适配器226、228、230和232可以包括用于连接到nvme ssd 222和224的硬件加速,以在不使用服务器的情况下将它们转换成网络nvme-of设备。nvme ssd 222和224可以各自包括两个物理端口,并且可以通过这些端口中的任一个来访问所有数据。
[0026]
每个客户端进程/应用212可以直接在操作系统上运行,或者可以在由操作系统和/或超级管理程序服务的虚拟机和/或容器中运行。客户端进程212可以在执行其主要功能的过程中从存储装置读取数据和/或向存储装置写入数据。然而,客户端进程212的主要功能不是与存储相关的(即,该进程仅关注其数据被可靠地存储并且在需要时能够取回,而不关注数据在何时以何种方式被存储在何地)。产生此类进程的示例性应用包括:电子邮件服务器、web服务器、办公生产力应用、客户关系管理(crm)、动画视频呈现、基因组学计算、芯片设计、软件构建以及企业资源规划(erp)。
[0027]
客户端应用212可以对与vfs驱动程序208通信的内核224进行系统调用。vfs驱动程序208将相应的请求放在vfs前端202的队列上。如果存在若干个vfs前端,则驱动程序可以对不同的前端进行负载均衡访问,确保始终经由同一前端访问单个文件/目录。这可以通过基于文件或目录的id来共享前端来实现。vfs前端202基于负责该操作的桶(bucket)提供用于将文件系统请求路由到适当的vfs后端的接口。适当的vfs后端可以在同一主机上或其可以在另一主机上。
[0028]
vfs后端206主管若干桶,它们中的每一个都服务于其接收的文件系统请求并执行任务以以其他方式管理虚拟文件系统(例如,负载均衡、日志记录、维护元数据、高速缓存、在层之间移动数据、移除陈旧数据、纠正损坏的数据等)。
[0029]
vfs ssd代理214处理与相应存储设备216的交互。这可以包括例如转换地址以及生成向存储设备发出的命令(例如,在sata、sas、pcie或其他合适的总线上发出)。因此,vfs ssd代理214作为存储设备216与虚拟文件系统的vfs后端206之间的中介进行操作。ssd代理214还可以与支持标准协议比如nvme-of(基于fabrics的nvme)的标准网络存储设备通信。
[0030]
图3示出了根据本公开的示例性实现方式的分布式文件系统的另一种形式。在图3中,单元302表示其上驻留有虚拟文件系统(如以上关于图2所述)的各种节点(计算、存储和/或vfs)的存储器资源(例如,dram和/或其他短期存储器)和处理(例如,x86处理器、arm处理器、nic、asic、fpga和/或类似物)资源。单元308表示提供虚拟文件系统的长期存储的一个或多个物理存储设备216。
[0031]
如图3所示,物理存储装置被组织成多个分布式故障容错地址空间(dfras)518。每个包括多个组块310,组块310又包括多个块312。在一些实现方式中,将块312组织成组块310仅仅是为了方便,并不是在所有实现方式中都这样做。每个块312存储已提交数据316(其可以采用各种状态,如下所述)和/或描述或引用已提交数据316的元数据314。
[0032]
将存储装置308组织成多个dfras实现了来自虚拟文件系统的多个(可能是所有的)节点(例如,图1的所有节点104
1-104
n
、106
1-106
m
和120
1-120
j
)的高性能并行提交。在示例性实现方式中,虚拟文件系统的每个节点可以拥有多个dfras中的相应一个或多个,并对其拥有的dfras具有排他的读取/提交访问。
[0033]
每个桶拥有一个dfras,因此在写入时不需要与任何其他节点协调。每个桶可以在许多不同的ssd上跨许多不同的组块构建条带,因此每个桶及其dfras可以基于许多参数来选择当前写入什么“组块条带”,并且一旦组块被分配给该桶,就不需要为了完成该操作而进行协调。所有的桶都可以有效地写入所有的ssd,而不需要进行任何协调。
[0034]
每个dfras仅由在特定节点上运行的其所有者桶拥有并能够访问,使得vfs的每个节点控制存储装置308的一部分而不必与任何其他节点协调(例如,除了在初始化期间或在节点故障之后[重新]指派持有dfras的桶期间之外,这可以与对存储装置308的实际读取/提交异步执行)。因此,在这样的实现方式中,每个节点可以独立于其他节点正在做的工作来对其桶的dfras进行读取/提交,而无需在对存储装置308进行读取和提交时达到任何一致性。此外,在特定节点发生故障的情况下,特定节点拥有多个桶使得能够将其工作负载更智能且更有效地重新分配给其他节点(而不是必须将整个工作负载指派给单个节点,这可能产生“热点”)。在这点上,在一些实现方式中,桶的数量相对于系统中的节点的数量可以是较大的,使得任何一个桶放置在另一个节点上可以是相对较小的负载。这允许根据其他节点的性能和容量对故障节点的负载进行细粒度的重新分配(例如,可以将更高比例的故障节点的桶给予具有更高性能和容量的节点)。
[0035]
为了能够进行此操作,可以维护将每个桶映射到其当前拥有节点的元数据,使得对存储装置308的读取和提交可以被重定向到适当的节点。
[0036]
负载分配是可能的,因为整个文件系统元数据空间(例如,目录、文件属性、文件中的内容范围等)可以被分割(例如,分隔或分片)成较小的均匀的片(例如,分片(shard))。例如,一个拥有30k服务器的大型系统可以将元数据空间分割为128k或256k的分片。
[0037]
每个这样的元数据分片被维护在“桶”中。每个vfs节点可以负责若干个桶。当桶正在服务于给定后端上的元数据分片时,该桶被认为是“活动的”或该桶的“主导者
(leader)”。典型地,存在比vfs节点多得多的桶。例如,具有6个节点的小型系统可以具有120个桶,而具有1000个节点的大型系统可以具有8k个桶。
[0038]
每个桶可以在小的节点集合上是活动的,通常是为该桶形成五元组的5个节点。集群配置使所有参与的节点在关于每个桶的五元组分配方面保持最新。
[0039]
每个五元组监控自身。例如,如果集群具有10k个服务器,并且每个服务器具有6个桶,则每个服务器将仅需要与30个不同的服务器对话来维持其桶的状态(6个桶将具有6个五元组,因此6*5=30)。与集中监控的实体必须监视所有节点并保持集群范围状态的情况相比,该数量小得多。使用五元组使得性能能够随着集群变大而扩展,因为当集群大小增大时节点并不执行更多的工作。这可能造成以下缺点,即在“哑”模式下,小型集群实际上可能产生比物理节点更多的通信,但是该缺点可以通过在两个服务器及它们共享的所有桶之间仅发送单个心跳来克服(随着集群的增长,这将变为仅一个桶,但是如果您有一个小型的5个服务器的集群,则它将恰好在所有消息中包括所有桶,并且每个服务器将仅与其他4个服务器对话)。五元组可以使用类似于拉夫特(raft)一致性算法的算法来决定(即,达到一致性)。
[0040]
每个桶可以具有能够运行它的一组计算节点。例如,五个vfs节点可以运行一个桶。然而,在任何给定时刻,组中只有一个节点是控制器/主导者。此外,对于足够大的集群,没有两个桶共享同一个组。如果集群中只有5或6个节点,则大多数桶可以共享后端。在相当大的集群中,有许多不同的节点组。例如,在26个节点的情况下,有超过种可能的五节点组(即5元组)。
[0041]
组中的所有节点知道并同意(即达成一致性)哪个节点是该桶的实际活动控制器(即主导者)。访问桶的节点可以记住(高速缓存)组的成员(例如,五个)中的作为该桶的主导者的最后一个节点。如果它访问桶的主导者,则该桶的主导者执行所请求的操作。如果它访问不是当前主导者的节点,则该节点指示主导者“重定向”该访问。如果访问高速缓存的主导者节点超时,则正在联络的节点可以尝试同一五元组的不同节点。集群中的所有节点共享集群的公共“配置”,这允许节点知道每个桶可以运行哪个服务器。
[0042]
每个桶可以具有指示该桶被在文件系统上运行的应用使用的程度的负载/使用值。例如,具有11个轻微使用的桶的服务器节点可以在具有9个严重使用的桶的服务器之前接收待运行的另一桶元数据,即使会导致所使用桶的数量不平衡。可以根据平均响应等待时间、并发运行操作的数量、存储器消耗或其他度量来确定负载值。
[0043]
即使当vfs节点没有故障时,也可能发生重新分配。如果系统基于所跟踪的负载度量识别出一个节点比其他节点更繁忙,则系统可以将其桶中的一个移动(即,“失效转移”)到较不繁忙的另一服务器。然而,在将桶实际重定位到不同主机之前,可以通过转移写入和读取来实现负载均衡。因为每次写入可在不同节点组(由dfras决定)上结束,所以在数据正被写入的条带中可以不选择具有较高负载的节点。该系统还可以选择不服务于来自高负载节点的读取。例如,可以执行“退化模式读取”,其中从同一条带的其他块重建高负载节点中的块。退化模式读取是通过同一条带中的其余节点执行的读取,并且通过故障保护来重建数据。当读取等待时间过长时,可以执行降级模式读取,因为读取的发起者可能假设该节点发生故障。如果负载高到足以产生更长的读取等待时间,则集群可以返回到从其他节点读
取该数据并使用降级模式读取来重建所需数据。
[0044]
每个桶管理其自身的分布式擦除编码实例(即dfras 518),并且不需要与其他桶协作来执行读取或写入操作。可能存在数千个并发的分布式擦除编码实例并发工作,每个用于不同的桶。这是扩展性能的主要部分,因为它有效地允许任何大型文件系统被分成不需要协调的独立部分,从而不管如何扩展都能实现高性能。
[0045]
每个桶处理落入其分片中的所有文件系统的操作。例如,目录结构、文件属性和文件数据范围将落入特定桶的管辖范围。
[0046]
任何前端完成的操作都是由找出哪个桶拥有该操作启动的。然后确定该桶的后端主导者和节点。该确定可以通过尝试上次已知的主导者来执行。如果上次已知的主导者不是当前主导者,则该节点可以知道哪个节点是当前主导者。如果上次已知的主导者不再是桶的五元组的一部分,则该后端将让前端知道它应该返回到配置以找到该桶的五元组的成员。对操作进行分布允许由多个服务器处理复杂的操作,而不是由标准系统中的单个计算机处理。
[0047]
如果集群的大小较小(例如,5)并且使用五元组,则将存在共享相同组的桶。随着集群大小的增长,对桶进行重新分配,使得没有两个组是相同的。
[0048]
加密存储对于许多不同的应用是重要的。例如,必须根据联邦信息处理标准(fips)来保护金融应用,并且必须根据医疗保险可携性和责任法案(hippa)来保护保健应用。
[0049]
存储的数据可能需要加密。例如,如果一个或多个存储设备受到危害,则对所存储的数据进行加密可以防止恢复明文数据。
[0050]
对于通过网络传送的数据也可能需要“运行中(on-the-fly)”加密。例如,“运行中”的加密防止窃听和中间人试图篡改数据。
[0051]
图4示出了加密文件系统400中的计算设备401的实例。该计算设备包括前端403和后端405。前端403可以在数据进入和离开系统时在客户端侧对数据进行加密和解密。前端403能够操作以在数据被写入系统400中的数据文件时对数据进行加密。前端403还能够操作以在从系统400中的数据文件读取数据时对数据进行解密。
[0052]
前端403至少根据文件密钥413对数据进行加密。可以通过复制数据文件来旋转文件密钥413。文件密钥413(例如,每个文件一个密钥)可以被提供给客户端用于前端加密和解密。文件密钥413可以由具有fips批准的安全随机数生成器的文件系统401生成。如果要保存文件密钥413,则可以通过文件系统密钥415对文件密钥415进行加密。另外,文件系统id和索引节点(inode)id可以用作文件密钥413的认证数据。可以通过复制文件来旋转文件密钥。当复制文件时,将使用新生成的文件密钥对内容进行重新加密。
[0053]
文件系统密钥415(例如,每个文件系统一个密钥)决不会离开文件系统的边界。文件系统密钥415可以由密钥管理系统/服务器(kms)生成。如果要保存文件系统密钥415,则可以通过集群密钥417来对文件系统密钥进行加密。另外,集群id和文件系统id可以用作文件系统密钥415的认证数据。文件系统密钥415可以立即由文件系统400旋转。例如,文件系统400可以请求kms生成用于指定文件系统的新密钥。新创建的文件将使它们的文件密钥413用最新的文件系统密钥415加密,而更新的文件可以使它们的文件密钥413用最新的文件系统密钥415进行重新加密。
[0054]
文件密钥413可以通过文件系统密钥415来进行加密。此外,可以通过集群密钥417对文件系统密钥415进行加密。当旋转文件系统密钥415时,可以对文件密钥413进行重新加密,并且当旋转集群密钥417时,可以文件系统密钥415进行重新加密。
[0055]
后端包括多个桶407a、407b...407m。所述计算设备401可操作地连接至多个存储设备409a、409b、409c、409d...407n,例如ssd的。桶的数量可以小于、大于或等于存储设备的数量。
[0056]
多个桶407a、407b...407m中的每个桶407x能够操作以构建包括多个存储块(例如,块x1、块x2和块x3)的故障保护条带411x。多个存储块包括加密数据以及检错和/或纠错编码。为了说明,条带411a包括块a1、块a2和块a3;条带411b包括块b1、块b2和块b3;并且条带411c包括块c1、块c2和块c3。条带中的块的数量可以小于、大于或等于三。特定条带的每个存储块位于多个存储设备中的不同存储设备中。由后端405中的多个桶407构建的所有故障保护条带411在与文件系统密钥415相关联的公共文件系统400中。
[0057]
图5示出了计算设备401a、401b、401c...401p的集群501的实例。计算设备的集群501与集群密钥417相关联。集群密钥417(例如,每个集群一个密钥)决不会离开集群的边界。集群密钥417可以由kms生成。kms可以即时旋转集群密钥。在旋转时,kms对每个文件系统密钥415进行重新加密,并且旧的集群密钥可以被销毁。文件系统不需要知道该旋转。当客户端(例如,计算设备401b或401c)加入集群501时,其向主导者注册公共密钥503。每个客户端节点在启动时生成长期公共密钥/私有密钥对503。
[0058]
网络加密密钥可以由两个节点(例如,计算设备401b或401c)协商以对这两个节点之间的通信进行加密。节点(包括系统节点和客户端节点)之间的网络交互被称为远程过程调用(rpc)。rpc可以将它们的参数、输出参数和返回值标记为已加密。rpc可以使用仅为两个rpc端点(例如,节点)所知的预协商密钥来对它们的自变量有效负载进行加密。根据需要,每个客户端可以与其连接的每个系统节点协商会话密钥507。可以使用由每个节点(例如,计算节点401b或401c)在其被加入到集群501时生成的长期密钥签名(例如,长期密钥503b和503c)的临时密钥对(使用例如临时密钥对生成器505)对会话密钥以完美前向保密(perfect forward security)进行协商。
[0059]
系统间(system-to-system)密钥可以用于减少到新启动的服务器能够连接到其他服务器之前的时间。在加入之后,新启动的服务器可以从文件系统主导者接收密钥。该系统间密钥被加密并保存在配置中。从服务器到服务器a的rpc可以使用表示为例如“config.serverkeys[a]”的配置。
[0060]
为了认证客户端,管理员可以生成可由客户端用于加入集群的令牌或证书。该令牌可以是时间有限的并且可以由管理员基于质询-响应机制来配置。令牌可以标识特定机器(例如,我的ip地址或实例id)。令牌可以标识客户端类,从而允许许多机器使用同一令牌加入。令牌也可以由管理员撤销。当令牌被撤销时,新客户端将不能使用该令牌加入,并且使用该令牌加入的现有客户端将断开,除非现有客户端具有更新的有效令牌。
[0061]
为了授权挂接,管理员可以配置哪些客户端(特定机器或机器组)可以挂接哪些文件系统。当客户端尝试挂接文件系统时,将验证此授权。可以防止未挂接文件系统的客户端访问文件系统。管理员可以指定所允许的访问是只读、只写或读/写。管理员还可以允许客户端挂接为root(例如,rootsquash或非rootsquash)。
[0062]
每个文件系统可以具有可以从文件系统密钥导出的文件名加密密钥。当客户端挂接文件系统时,客户端可以接收文件名加密密钥。客户端可以使用对称加密来创建具有加密文件名的文件。
[0063]
对象存储装置中的文件数据(例如,用于备份和还原的分层数据)可以以与盘上数据相同的方式被加密。当上载到对象存储装置时,文件数据可以包含文件系统参数,比如加密的文件系统密钥。例如,文件系统密钥可以用经由kms可获取的特殊“备份专用集群密钥”来进行加密。
[0064]
如果集群被丢弃并且通过从对象存储下载文件系统来创建新的集群,则所下载的文件系统可以由具有备份专用密钥的文件系统密钥来进行解密并且利用集群的新的集群密钥来进行重新加密。
[0065]
当将快照装载到简单存储服务(s3)时,可以使用新的集群密钥来对文件系统密钥进行重新加密。“装载(stow)”命令可以包含新的集群密钥id和从kms访问它的证书。可以用新的集群密钥对现有的文件系统密钥进行重新加密,并将其与剩余的文件系统元数据一起保存在s3中。恢复装载的快照需要访问装载时指定的同一集群密钥。
[0066]
可以对系统页面高速缓存进行加密,以降低存储器(例如,内核存储器)将被其他进程访问的可能性。为了对抗这种未授权访问,内核页面高速缓存接收的加密数据不能在其在网络中被接收时立即被解密。因为内核将存储加密数据,所以恶意应用将无法访问它。当实际拥有文件的进程访问加密数据时,内核驱动程序将在前端的帮助下对数据进行解密,同时将数据复制到该进程的存储空间。因此,系统存储器将被加密,直到其被合法访问。
[0067]
加密和解密进程可以利用硬件加速。当执行加密时,文件系统可以寻找能够对加密进程进行加速的硬件。文件系统可以对哪个硬件更有效(例如,标准cpu操作码(opcode)、cpu内的加速、协处理器上的加密、或网卡)进行排序,并使用对解密数据进行加密的最有效方式。
[0068]
除了上述加密之外,还可以使用自加密驱动器(sed)。在文件系统中的标准加密代码之上,sed可以对正在接收的已经加密的数据进行加密。
[0069]
存储数据的加密可以使用对称加密密钥,其中使用同一密钥进行加密和解密数据。根据文件系统的配置,有几种密钥管理选项。
[0070]
同一密钥可以用于所有驱动器(例如,ssd的)。然而,如果该密钥被泄露,则可以读取所有驱动器。
[0071]
对于每个ssd可以使用不同的密钥。这些密钥可以由随机选取并存储用于每个ssd的不同加密密钥的文件系统来管理。可替代地,这些密钥可以由处理创建和存储加密密钥的客户端自己的密钥管理系统来管理。文件系统可以用客户端的ksm认证这些密钥,并为每个ssd请求正确的密钥。在下次重新启动之前,ssd保留密钥并可以使用它。
[0072]
密钥管理的另一选项是使ssd上的每个组块具有不同的密钥。这允许在同一文件系统上支持多个客户。具有不同的分布式故障容错地址空间的文件系统可以访问相同的ssd代理。每个文件系统可以为每个dfras设置不同的密钥。ssd可能不会在引导时交换基本密钥。相反,可以在引导时向ssd注册不同的密钥。如果驱动器要求为每个io给出加密密钥,则每个密钥可以具有每个io使用的索引。当dfras访问ssd时,dfras可以记住其ssd的加密密钥的索引,并将其与io请求一起传送。因此,文件系统可以共享在同一ssd上运行的若干
工作负载和不同的dfras,而不会损害安全性。
[0073]
hippa需要数据的三个独立副本和静态加密。可以通过使用写入两个独立对象存储装置的复合对象存储装置后端来实现三个独立副本。可以首先加密发送到对象存储装置的数据。文件系统可以被配置为在由应用定义的预定义时间(例如,每30分钟)拍摄快照并将该快照传送到对象存储装置。通过将自加密ssd驱动器与ksm集成,集群可以具有静止加密。
[0074]
图6是示出用于从加密文件系统中的客户端读取的示例性方法的流程图。在框601中,客户端打开文件以进行读访问。在框603中,在验证客户端可以访问该文件系统之后,系统将文件密钥安全地发送到客户端的计算设备。在框605中,客户端前端使用文件密钥来对从文件读取的数据进行解密。
[0075]
在框607中,使用来自客户端的计算设备和另一计算设备的由长期密钥签名的临时密钥对来对会话密钥进行协商。在框609中,使用会话密钥对数据进行加密。在框611中,将(通过会话密钥加密的)数据从客户端的计算设备传送到另一计算设备。
[0076]
在框613中,关闭该文件。在框615中,从存储器清除文件密钥和会话密钥。
[0077]
图7是示出用于向加密文件系统中的客户端写入的示例性方法的流程图。在框701中,使用来自客户端的计算设备和另一计算设备的由长期密钥签名的临时密钥对来对会话密钥进行协商。在框703中,使用会话密钥对数据进行加密。在框705中,将(通过会话密钥加密的)数据从其他计算设备传送到客户端的计算设备。
[0078]
在框707中,客户端打开文件以进行写访问。在框709中,在验证客户端可以访问该文件系统之后,系统将文件密钥安全地发送到客户端的计算设备。在框711中,客户端前端使用会话密钥来对所接收的数据进行解密。
[0079]
在框713中,客户端前端使用文件密钥来对解密的数据进行加密。在框715中,将(通过文件密钥加密的)数据写入客户端的计算设备上的打开的文件。
[0080]
在框717中,关闭该文件。在框719中,从存储器清除文件密钥和会话密钥。
[0081]
图8示出了两个分布式故障容错地址空间驻留在多个固态存储磁盘上的示例性实现方式。
[0082]
组块910
1,1-910
d,c
可以被组织成多个组块条带920
1-920
s
(s是整数)。在示例性实现方式中,每个组块条带920
s
(s是整数,其中1≤s≤s)使用前向纠错(例如,擦除编码)来单独保护。因此,可以基于期望的数据保护级别来确定任何特定组块条带920
s
中的组块910
d,c
的数量。
[0083]
出于说明的目的,假设每个组块条带920
s
包括n=m+k个(其中n、m和k中的每一个都是整数)组块910
d,c
,则n个组块910
d,c
中的m个可以存储数据位(典型地,对于当前存储设备是二进制位或“比特”),并且n个组块910
d,c
中的k个可以存储保护位(典型地还是比特)。然后,对于每个条带920
s
,虚拟文件系统可以从n个不同的故障域中指派n个组块910
d,c
。
[0084]
如本文所使用的,“故障域”指的是一组组件,其中这些组件中的任何单个组件的故障(该组件失去电力、变得无响应和/或类似等)可以导致所有组件的故障。例如,如果机架具有单个架顶式交换机,则该交换机的故障将降低对该机架上所有组件(例如,计算、存储和/或vfs节点)的连接性。因此,对于系统的其余部分,它相当于该机架上的所有组件一起发生故障。根据本发明的虚拟文件系统可以包括比组块910更少的故障域。
[0085]
在虚拟文件系统的节点以全冗余方式连接并供电,其中每个这样的节点仅具有单个存储设备906的示例性实现方式中,故障域可以恰好是该单个存储设备906。因此,在示例性实现方式中,每个组块条带920
s
包括驻留在存储设备906
1-906
d
中的n个中的每一个上的多个组块910
d,c
(因此d大于或等于n)。图9示出了这种实现方式的实例。
[0086]
在图8中,d=7,n=5,m=4,k=1,并且存储装置被组织成两个dfras。这些数字仅用于说明而不旨在作为限制。为了说明,任意调用第一dfras的三个组块条带920。第一组块条带920
1
由块910
1,1
、910
2,2
、910
3,3
、910
4,5
和910
5,6
组成;第二组块条带920
2
由块910
3,2
、910
4,3
、910
5,3
、910
6,2
和910
7,3
组成;第三组块条带920
3
由块910
1,4
、910
2,4
、910
3,5
、910
5,7
和910
7,5
组成。
[0087]
虽然在图8的简单实例中,d=7,n=5,但是在实际实现方式中,d可以比n大得多(例如,大于1的整数倍并且可能高许多数量级),并且可以选择这两个值,使得单个dfras的任意两个组块条带920驻留在同一组n个存储设备906上(或者更一般地,驻留在同一组n个故障域上)的概率低于期望阈值。以这种方式,任何单个存储设备906d的故障(或者更一般地,任何单个故障域)将至多造成(可能基于以下确定期望的统计:d和n的选择值、n个存储设备906的大小以及故障域的布置)损失任意特定条带920
s
的一个组块910
b,c
。更进一步,双重故障将造成绝大多数条带损失至多单个组块910
b,c
,仅少量条带(基于d和n的值确定的)将损失任何特定条带920s中的两个组块(例如,具有两个故障的条带的数量可能指数级地少于具有一个故障的条带的数量)。
[0088]
例如,如果每个存储设备906
d
是1tb,并且每个组块是128mb,则存储设备906
d
的故障将造成(可能基于以下确定期望的统计:d和n的选择值、n个存储设备906的大小以及故障域的布置)7812个(=1tb/128mb)组块条带920损失一个组块910。对于每个这样的受影响的组块条带920
s
,可以使用适当的前向纠错算法和组块条带920
s
的其他n-1个组块来快速重建损失的组块910
d,c
。此外,由于受影响的7812个组块条带在所有存储设备906
1-906
d
上均匀分布,因此重建损失的7812个块910
d,c
将涉及(可能基于以下确定期望的统计:d和n的选择值、n个存储设备906的大小以及故障域的布置)906,以及故障域的布置)从存储设备906
1-906
d
中的每一个读取相同量的数据(即,重建损失数据的负担被均匀地分布在所有存储设备上,以从故障非常快速地恢复)。
[0089]
接下来,转向存储设备906
1-906
d
中有两个并发故障(或者更一般地,两个故障域并发故障)的情况,由于每个dfras的组块条带920
1-920
s
在所有存储设备906
1-906
d
上均匀分布,仅数量非常少的组块条带920
1-920
s
将损失其n个组块中的两个。该虚拟文件系统能够操作以基于指示组块条带920
1-920
s
与存储设备906
1-906
d
之间的映射的元数据来快速识别这样的两个损失的组块条带。一旦识别出这样的两个损失的组块条带,虚拟文件系统就可以在开始重建单个损失的组块条带之前优先重建那些两个损失的组块条带。剩余的组块条带将仅具有单个损失的组块,并且对于它们(绝大多数受影响的组块条带)来说,两个存储设备906
d
的并发故障与仅一个存储设备906
d
的故障相同。类似的原理适用于三并发故障(在两个并发故障情形中,具有三个故障块的组块条带的数量将甚至少于具有两个故障块的数量),等等。在示例性实现方式中,可以基于组块条带920
s
中的损失的数量来控制执行组块条带920
s
的重建的速率。这可以通过例如控制执行重建的读取和提交的速率、执行重建的fec计算的速率、传送重建的网络消息的速率等来实现。
[0090]
图9示出了根据本公开的示例性实现方式的可以用于保护存储到虚拟文件系统的非易失性存储器中的数据的前向纠错方案。示出了dfras的块条带930
1-930
4
的存储块902
1,1-902
7,7
。在图9的保护方案中,每个条带的五个块用于数据位的存储,并且每个条带的两个块用于保护位的数据存储(即,m=5,k=2)。在图9中,使用下面的公式(1)至(9)计算保护位:
[0091][0092][0093][0094][0095][0096][0097][0098][0099][0100]
因此,图9中的四个条带930
1-930
4
是多条带(在这种情况下是四个条带)fec保护域的一部分,并且块条带930
1-930
4
中的任意一个中的任意两个或更少的块的损失可以从使用上述等式(1)-(9)的各种组合来恢复。为了比较,单条带保护域的实例是如果d1
1
、d2
2
、d3
3
、d4
4
、d5
4
仅由p1保护,并且d1
1
、d2
2
、d3
3
、d4
4
、d5
4
都被写入条带930
1
(930
1
是单条带fec保护域)。
[0101]
根据本公开的示例性实现方式,多个计算设备经由网络彼此通信耦接,并且多个计算设备中的每一个包括多个存储设备中的一个或多个。多个故障容错地址空间分布在多个存储设备上,使得多个故障容错地址空间中的每一个跨越多个存储设备。多个故障容错地址空间中的每一个被组织成多个条带(例如,图8和图9中的多个930)。多个条带中的每一个或多个条带是多个前向纠错(fec)保护域(例如,如图8中的多条带fec域)中的相应一个的一部分。多个条带中的每一个可以包括多个存储块(例如,多个912)。多个条带中的特定一个的每个块可以驻留在多个存储设备中的不同存储设备上。多个存储块的第一部分(例如,图9中由条带930
1
的902
1,2-902
1,6
组成的五个的量)可以用于存储数据位,并且多个存储块的第二部分(例如,图9中由条带930
1
的两个902
1,1
和902
1,7
的量)可以用于存储至少部分地基于数据位计算的保护位。
[0102]
多个计算设备可以操作来对多个条带进行排序。该排序可以用于选择多个条带中的哪个条带用于对多个故障容错地址空间中的这一个进行下一提交操作。该排序可以基于在多个条带的每一个中存在多少受保护和/或不受保护的存储块。对于多个条带中的任意特定条带,该排序可以基于与多个条带中的该特定条带一起存储在多个存储设备上的位图。该排序可以基于多个条带的每一个中当前有多少存储数据的块。该排序可以基于向多个条带中的每一个提交读取和写入开销。在任意给定时间,故障容错地址空间中的每一个可仅由多个计算设备中的一个拥有,并且多个故障容错地址空间中的每一个可仅由其拥有者读取和写入。每个计算设备可以拥有多个故障容错地址空间。多个存储设备可以被组织成多个故障域。多个条带中的每一个可以跨多个故障域。每个故障容错地址空间可以跨所
有多个故障域,使得在多个故障域中的任意特定一个故障域发生故障时,在多个故障域中的其他故障域中的每一个之间分配用于重建损失数据的工作量。多个条带可以跨多个故障域分布,使得在多个故障域中有两个并发故障的情况下,多个条带中的任意特定一个的两个块驻留在多个故障域中的有故障的两个上的几率指数级地小于多个条带中的任意特定一个的仅一个块驻留在多个故障域中的有故障的两个上的几率。
[0103]
多个计算设备能够操作以首先重建多个条带中的任何具有两个故障块的条带,接着重建多个条带中的任何仅具有一个故障块的条带。多个计算设备能够操作以比多个条带中的仅具有一个故障块的条带的重建速率更高的速率(例如,专用于重建的cpu时钟周期百分比更大、专用于重建的网络传送机会百分比更大,和/或类似的)执行多个条带中的具有两个故障块的条带的重建。多个计算设备能够操作以在故障域中的一个或多个发生故障的情况下基于多个条带中的同一条带已损失多少个其他块来确定重建任意特定损失块的速率。其中,多个故障域中的一个或多个包括多个存储设备。多个fec保护域中的每一个可以跨越多个条带中的多个条带。
[0104]
多个条带可以被组织成多个组(例如,如图8中所示的组块条带920
1-920
s
),其中多个组中的每一个包括多个条带中的一个或多个,并且多个计算设备能够操作以针对每个组为该组中的多个条带中的一个或多个进行排序。多个计算设备能够操作以:对多个组中的选定组执行连续提交操作,直到该组的多个条带中的一个或多个不再满足所确定的标准为止,并且在多个组中的选定组不再满足所确定的标准时,选择多个组中的不同的一组。该标准可以基于有多少块可用于要写入的新数据。
[0105]
虽然已经参考特定实现方式描述了本方法和/或系统,但是本领域技术人员将理解,在不脱离本方法和/或系统的范围的情况下,可以进行各种改变并且可以替换等同物。此外,在不脱离本发明的范围的情况下,可以进行许多修改以使特定情况或材料适应本发明的教导。因此,意图是本方法和/或系统不限于所公开的特定实现方式,而是本方法和/或系统将包括落入所附权利要求的范围内的所有实现方式。
[0106]
如本文所使用的,术语“电路”和“电路系统”是指物理电子组件(即,硬件),以及可以配置该硬件、由该硬件执行或以其他方式与该硬件相关联的任何软件和/或固件(“代码”)。如本文所使用的,例如,特定的处理器和存储器在执行第一一行或多行代码时可以包括第一“电路系统”,并且在执行第二一行或多行代码时可以包括第二“电路系统”。如本文所用,“和/或”意指由“和/或”加入的列表中的项目中的任一个或多个。作为示例,“x和/或y”意指三元素集合{(x),(y),(x,y)}中的任意元素。换言之,“x和/或y”意指“x和y中的一者或两者”。作为另一示例,“x、y和/或z”意指七元素集合{(x),(y),(z),(x,y),(x,z),(y,z),(x,y,z)}中的任意元素。换言之,“x、y和/或z”意指“x、y和z中的一者或多者”。如本文所用,术语“示例性”意指用作非限制性示例、实例或说明。如本文所使用的,术语“例如”和“举例来说”包括一个或多个非限制性示例、实例或说明的列表。如本文所用,电路系统是“能够操作的”以执行功能,只要电路包括执行该功能所必需的硬件和代码(如果有必要的话),而不管功能的性能是否被禁用或未启用(例如,通过用户可配置的设置、出厂修整等)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1