用于训练扩增鉴别器的设备和方法与流程
用于训练扩增鉴别器的设备和方法
1.本发明涉及用于训练扩增鉴别器的方法和系统,以及机器可读存储介质。
现有技术
2.生成性对抗网络或称“gan”从goodfellow等人的“generative adversarial networks
”ꢀ
arxiv预印本已知。
3.本发明的优点具有独立权利要求1的步骤的方法具有实现更强大的生成性对抗网络生成器的优点,从而也提供了已经在生成性对抗网络中训练的更强大的鉴别器。
技术实现要素:
4.在机器学习中,数据对于训练机器学习系统很重要,但同时,用于训练的现实数据可能是一种稀缺资源。生成性建模可以以各种方式帮助丰富数据集,诸如合成数据生成、数据扩增和迁移学习。由于现实问题经常需要对高维概率分布建模,因此生成性建模仍然是具有挑战性的研究问题。
5.生成性对抗网络是最成功的建模方法之一。gan背后的核心思想是为两个玩家建立竞争游戏,这两个玩家通常称为鉴别器(d)和生成器(g)。生成器努力创建样本,所述样本应来自与训练数据相同的分布。相反,鉴别器的目的是为了将它们区分开。
6.从数学上讲,d和g的目标可以表述为min
‑
max问题:其中代表将实值函数d(x)映射到单位区间[0,1]的sigmoid函数。是由生成器g支配的生成性分布。鉴别器d解决了两类分类任务,其中这两类分别与和相关联。生成器g试图欺骗d。当双玩家博弈达到纳什均衡时,可以示出所获得的生成性分布必须与相同。
[0007]
考虑到易处理性问题,直接在函数空间中优化g和d是不现实的,尽管这在理论上是最优的。方便地,d和g可以采取深度神经网络来参数化它们的功能,例如,dcgan(例如参见“unsupervised representation learning with deep convolutional generative adversarial networks”,arxiv预印本arxiv:1511.06434v2,2016,alec radford,luke metz,soumith chintala)。
[0008]
更进一步地,在大多数情况下,用于g的神经网络显式地对遵循而不是的采样器进行建模。采样器将随机噪声向量z作为其输入,并应用变换g来获得合成样本= g(z)。z和g的先验分布共同定义了。
[0009]
随机梯度下降(sgd)方法通常被应用于求解min
‑
max问题。g和d的神经网络参数交替且迭代地更新,直到收敛或满足某个停止准则。要注意的是,这样的训练处理不存在收敛或其收敛到期望的纳什均衡的保证。出于该理由,gan的性能因应用而异,并且示出了对训练初始化、网络架构和超参数选择的敏感。简而言之,训练gan是具有挑战性的任务。
[0010]
gan潜在失败的一个根本原因出自于代价函数的公式,特别是当与sgd方法进行组合来优化时。当鉴别器d为次优时,代价函数从不饱和。当d达到最好时,即,当d对于给定的g被很好地优化,并且能够可靠地从由g生成的合成样本鉴别中出现实样本时,用于进一步更新g的梯度消失。最终,min
‑
max博弈未能达到期望的最优。还重要的是注意,和的支撑相应地驻留在低维流形上。由于在现实问题中,两个流形不太可能重叠或完美地对准,因此使d达到最好几乎是微不足道的。所以,在gan训练的过程期间,强大的d危害到g的学习处理。另一方面,弱的d通过有意地选取过于简化的神经网络而无法为g提供正确的反馈来学习真值。
[0011]
为了解决该问题,文献工作典型地借助于代价函数重构和训练处理正则化。在由goodfellow等人2014年的以上提及的出版物中,已经示出方程(1)中代价函数的内部最大值被标识为和之间的詹森
‑
香农散度(jsd)。它是两个分布的相似性度量,在时,取得它的最小值等于零。
[0012]
被本发明作为目标的问题是在gan训练过程期间避免d的过早饱和。因此,提供了一种平衡g和d的优化处理的新颖方法。
[0013]
为了说明所提出的方法为什么有效,考虑以下数学考虑是方便的。詹森
‑
香农散度(jsd)是分布对的相似性度量。gan旨在优化,使得其jsd相对于被最小化。从数学上讲,如方程(1)中捕获的gan相当于。
[0014]
从方程(2)开始,本发明的推导基于以下要点:引入了具有均匀分布的二元随机变量s,它将两个分布和连接成混合分布p(x)。
[0015]
也就是说,和是p(x)的两种模式,而s是模式指示器。在这样的结构下,x和s之间的互信息等于和的jsd,使得。
[0016]
互信息i(s,x)是联合分布p(x,s)和非联合(disjoint)分布p(x)p(s)之间的kulback
‑
leibler(kl)散度测度。因为方程(4)中的目标是使互信息最小化,所以用jsd替换kl散度没有损失。它们都在相同的条件——即,p(x,s)=p(s)p(x)——下被最小化。从数学上讲,该标识导致了第二个等价问题。
[0017]
非联合分布p(s)p(x)可以分解为非联合分布p(s)p(x)可以分解为
其中q(x,s)是在如(3)中所定义的p(x,s)之上应用模式翻转的结果。使p(x,s)和p(x)p(s)等同本质上是让p(x,s)等于q(x,s),即,。
[0018]
将(7)中的第一个和最后一个最小化问题联系起来的一种方式是将s视为样本x的一位扩增。一个基于p(x,s)的规则是分别利用0和1扩增来自和的样本。从q(x,s)导出的另一个规则完全相反。在常规的gan中,鉴别器d通过将数据和合成样本分类为真(true)和假(false)来估计和之间的jsd。
[0019]
因此,在本发明的第一方面中,设想具有一种用于训练扩增鉴别器ad和生成器(g)的计算机实现的方法。扩增鉴别器ad需要区分扩增的样本。因此,根据本发明的第一方面的方法包括以下步骤
‑
提供包括现实训练样本()和人工训练样本()的训练集,用于扩增鉴别器(ad)的训练,其中人工训练样本()由生成器(g)生成;
‑
将数据序列(s)分派给训练集的至少一个数据样本(x);
‑
其中数据样本(x)和分派的数据序列(s)的每一对(x,s)被分派给多个类中的一个类,使得一并考虑的多个类中的分派的一个类和分派的数据序列(s)表征数据样本(x)是现实训练样本()还是人工训练样本();和
‑
训练扩增鉴别器(ad)以能够从数据样本(x)和分派的数据序列(s)的对(x,s)计算对应的对(x,s)被分派到的相应一个类()
‑
训练生成器(g)以能够生成人工训练样本(),使得扩增鉴别器(ad)不能正确计算前述一个类()。
[0020]
优选地,所述多个类包括两个类,即,它包括不多于也不少于两个类。
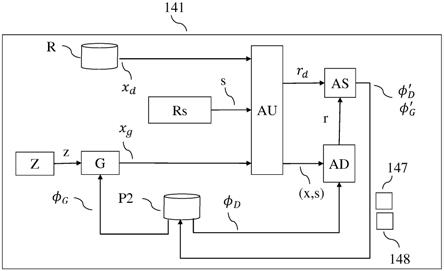
[0021]
注意到,可以构建鉴别器d来区分p(x,s)和q(x,s)即,(7)中最后一个jsd。另一种解决办法可以是区分p(x,s)和p(s)p(x),如(7)中倒数第二个jsd中所指示的。由于p(s)p(x)是(6)中p(x,s)和q(x,s)的混合物,因此这两种对比分布保证了重叠的支撑,以减轻消失的梯度问题。这在图15中图示。
[0022]
图15a)中示出的是联合分布p(x,s)的图示,图15b)中示出的是对于给定的人工训练样本p
g
和现实训练样本p
d
的分布的对应模式翻转联合分布q(x,s)的图示。如果可能对应的类分别被标示为真和假,则图15a)中示出的分布对应于 =真,而图15b)中所示的分布对应于 =假。图15c))中示出的是p(x,s)和q(x,s)的算术平均值的图示。
[0023]
图15c)中所示的分布在s=0和1时有两种相同的模式。清楚地看到图15a)中示出的和图15c)中示出的分布的支撑的重叠。为了欺骗鉴别器,生成器必须优化g,使得图15a)中s = 1时的模式水平出现在与s=0时的模式相同形状的相同位置处。仅当这种情况发生时,图15c)中所示的分布才变得与图15a)中所示的分布相同。这是因为当p
g = p
d
时,p
g
的曲线向左移动并与p
d
水平对齐,并且它们具有相同的形状。
[0024]
当这种情况发生时,图15c)中的四个模式将减少到与图15a)相同的两个模式。那
么,这两个分布是等同的。扩增鉴别器ad将不能从p(x,s)和p(x)p(s)区分样本。
[0025]
对该方法的改进是从属权利要求的主题。
[0026]
这样的扩增鉴别器有许多应用。例如,可以设想使用经训练的扩增鉴别器来分类被提供给机器学习系统的输入信号是更类似于现实训练样本()还是更类似于人工训练样本(),即,经训练的扩增鉴别器取决于输入信号是更类似于现实训练样本()还是更类似于人工训练样本()来对输入信号进行分类。例如,这可以用于检测输入数据中的异常。
[0027]
可替代地,在扩增鉴别器的训练期间训练的生成器可以用于训练鉴别器。这样的鉴别器比扩增鉴别器更容易使用。
[0028]
在本发明的另一方面中,经训练的生成器可以用于生成训练样本,该训练样本然后可以用于训练机器学习系统。该机器学习系统然后可以用于控制致动器,从而致使控制更可靠和/或更精确。
[0029]
将参考以下各图更详细地讨论本发明的实施例。各图示出:图1是致动器控制系统,该致动器控制系统具有控制其环境中的致动器的机器学习系统;图2是控制至少部分自主的机器人的致动器控制系统;图3是控制制造机器的致动器控制系统;图4是控制自动化个人助理的致动器控制系统;图5是控制访问控制系统的致动器控制系统;图6是控制监督系统的致动器控制系统;图7是控制成像系统的致动器控制系统;图8是用于控制机器学习系统的训练系统;图9是用于训练扩增鉴别器和生成器的对抗训练系统;图10是由所述对抗训练系统实行的训练方法的流程图;图11是图示由图12中所示的训练系统实行的训练方法的流程图;图12是用于训练鉴别器d的训练系统;图13是图示使用经训练的扩增鉴别器的方法的流程图;图14是图示使用经训练的生成器g的方法的流程图;图15是图示本发明如何工作的概率分布的图示。
具体实施方式
[0030]
图1中示出了在其环境20中的致动器10的一个实施例。致动器10与致动器控制系统40交互。致动器10及其环境20将被统称为致动器系统。优选地,在均匀间隔的距离处,传感器30感测致动器系统的状况。传感器30可以包括若干个传感器。对所感测的状况进行编码的传感器30的输出信号s(或者,在传感器30包括多个传感器的情况下,每个传感器的输出信号s)被传输到致动器控制系统40。
[0031]
因此,致动器控制系统40接收传感器信号s流。它取决于传感器信号s流计算一系列致动器控制命令a,然后将其传输到致动器10。
[0032]
致动器控制系统40在可选的接收单元50中接收传感器30的传感器信号s流。接收单元50将传感器信号s变换成输入信号x。可替代地,在没有接收单元50的情况下,每个传感器信号s可以直接当做输入信号x。例如,输入信号x可以作为来自传感器信号s的摘录而给出。可替代地,传感器信号s可以被处理以产生输入信号x。输入信号x可以例如包括图像或视频记录的帧。换句话说,根据传感器信号s提供输入信号x。
[0033]
输入信号x然后被传递到机器学习系统60,该机器学习系统60例如可以由人工神经网络给出。
[0034]
机器学习系统60由参数参数化,参数存储在参数存储装置p中并由参数存储装置p提供。
[0035]
机器学习系统60从输入信号x确定输出信号y。输出信号y被传输到转换单元80,转换单元80将输出信号y转换成控制命令a。致动器控制命令a然后被传输到致动器10,用于相应地控制致动器10。
[0036]
致动器10接收致动器控制命令a,被相应地控制,并实行对应于致动器控制命令a的动作。致动器10可以包括控制逻辑,该控制逻辑将致动器控制命令a变换成进一步的控制命令,然后该进一步的控制命令被用于控制致动器10。
[0037]
在进一步的实施例中,致动器控制系统40可以包括传感器30。在甚至进一步的实施例中,致动器控制系统40可替代地或附加地可以包括致动器10。
[0038]
更进一步地,致动器控制系统40可以包括处理器45(或多个处理器)和至少一个机器可读存储介质46,所述至少一个机器可读存储介质46上存储有指令,所述指令如果被实行,则引起致动器控制系统40实行根据本发明的一个方面的方法。
[0039]
对于致动器10而言,可替代地或附加地,实施例可以包括显示单元10a,该显示单元10a也可以根据致动器控制命令a来被控制。
[0040]
在所有以上实施例中,机器学习系统60可以包括鉴别器,该鉴别器被配置为检测输入信号x是否具有预定义属性。例如,机器学习系统60可以被配置为确定输入信号x是否可以被信任以用于进一步处理。
[0041]
可以取决于输入信号x是否被判断为具有预定义属性来确定输出信号y。例如,在输入信号x已经被确定为值得信任的情况下,输出信号y可以被选取为对应于常规输出信号y,并且在输入信号x已经被确定为不值得信任的情况下,输出信号y可以包含引起致动器10和/或显示单元10a在安全模式下操作的信息。
[0042]
图2示出了实施例,其中致动器控制系统40用于控制至少部分自主的机器人、例如至少部分自主的车辆100。
[0043]
传感器30可以包括包括一个或多个视频传感器和/或一个或多个雷达传感器和/或一个或多个超声波传感器和/或一个或多个lidar传感器和/或热相机传感器和/或一个或多个定位传感器(如例如,gps)。这些传感器中的一些或全部优选地但非必须被集成在车辆100中。可替代地或附加地,传感器30可以包括用于确定致动器系统的状态的信息系统。这样的信息系统的一个示例是确定环境20中天气的当前或未来状态的天气信息系统。
[0044]
例如,使用输入信号x,机器学习系统60可以例如检测在至少部分自主的机器人附近的对象。输出信号y可以包括表征对象位于在至少部分自主机器人附近的何处的信息。然后可以根据该信息确定控制命令a,例如以避免与所述检测到的对象碰撞。
[0045]
优选地集成在车辆100中的致动器10可以由车辆100的制动器、推进系统、引擎、传动系或转向装置给出。致动器控制命令a可以被确定为使得(一个或多个)致动器10被控制,使得车辆100避免与所述检测到的对象碰撞。检测到的对象也可以根据它们被机器学习系统60认为最有可能是什么(例如行人或树木)来分类,并且致动器控制命令a可以取决于分类来确定。
[0046]
在进一步的实施例中,至少部分自主的机器人可以由另一个移动机器人(未示出)给出,该另一个移动机器人可以例如通过飞行、游泳、潜水或行走来移动。该移动机器人尤其可以是至少部分自主的割草机,或者至少部分自主的清洁机器人。在所有上述实施例中,致动器命令控制a可以被确定为使得移动机器人的推进单元和/或转向装置和/或制动器被控制,使得移动机器人可以避免与所述标识的对象碰撞。
[0047]
在进一步的实施例中,至少部分自主的机器人可以由园艺机器人(未示出)给出,园艺机器人使用传感器30(优选光学传感器)来确定环境20中植物的状态。致动器10可以是用于喷射化学品的喷嘴。取决于标识的植物种类和/或标识的植物状态,致动器控制命令可以被确定为引起致动器10利用合适量的合适化学品喷洒植物。
[0048]
在甚至进一步的实施例中,至少部分自主的机器人可以由家用器具(未示出)给出,家用器具如例如是洗衣机、炉子、烤箱、微波炉或洗碗机。传感器30(例如光学传感器)可以检测将由家用器具进行处理的对象的状态。例如,在家用器具是洗衣机的情况下,传感器30可以检测洗衣机内部衣物的状态。然后可以取决于检测到的衣物材料来确定致动器控制信号a。
[0049]
图3中示出了如下实施例,其中致动器控制系统40被用来控制例如作为生产线的一部分的制造系统200的制造机器11(例如冲压刀具、刀具或枪钻)。致动器控制系统40控制致动器10,致动器10进而控制制造机器11。
[0050]
传感器30可以由光学传感器给出,该光学传感器捕获例如所制造产品12的属性。机器学习系统60可以根据这些捕获的属性来确定所制造产品12的状态。然后,控制制造机器11的致动器10可以取决于所确定的所制造产品12的状态被控制,以用于所制造产品12的随后制造步骤。或者,可以设想致动器10在随后的所制造产品12的制造期间取决于所确定的所制造产品12的状态被控制。
[0051]
图4中示出了如下实施例,其中致动器控制系统40用于控制自动化个人助理250。在优选实施例中,传感器30可以是声学传感器,其接收人类用户249的语音命令。传感器30还可以包括光学传感器,例如以用于接收用户249的手势的视频图像。
[0052]
致动器控制系统40然后确定用于控制自动化个人助理250的致动器控制命令a。根据传感器30的传感器信号s确定致动器控制命令a。传感器信号s被传输到致动器控制系统40。例如,机器学习系统60可以被配置为例如实行手势识别算法以标识用户249做出的手势,或者它可以被配置为实行语音命令识别算法以标识用户249发出的口头命令。致动器控制系统40然后可以确定致动器控制命令a,以用于传输到自动化个人助理250。然后,它将所述致动器控制命令a传输到自动化个人助理250。
[0053]
例如,可以根据由机器学习系统60识别的所标识的用户手势或所标识的用户语音命令来确定致动器控制命令a。然后,它可以包括引起自动化个人助理250从数据库检索信息并以适合供用户249接收的形式输出该检索到的信息的信息。
[0054]
在进一步的实施例中,可以设想,致动器控制系统40代替自动化个人助理250来控制根据所标识的用户手势或所标识的用户语音命令控制的家用器具(未示出)。家用器具可以是洗衣机、炉子、烤箱、微波炉或洗碗机。
[0055]
图5中示出如下实施例,其中致动器控制系统控制访问控制系统300。访问控制系统可以被设计成物理地控制访问。例如,它可以包括门401。传感器30被配置为检测与决策是否准许访问相关的场景。例如,它可以是用于提供图像或视频数据以用于检测人脸的光学传感器。机器学习系统60可以被配置为解释该图像或视频数据,例如通过将身份与存储在数据库中的已知人员进行匹配,从而确定该人员的身份。然后可以取决于机器学习系统60的解释,例如根据所确定的身份,来确定致动器控制信号a。致动器10可以是取决于致动器控制信号a准许访问或不准许访问的锁。非物理的逻辑访问控制也是可能的。
[0056]
图6中示出了如下实施例,其中致动器控制系统40控制监督系统400。该实施例在很大程度上与图5中所示的实施例等同。因此,将仅详细描述不同的方面。传感器30被配置为检测被监督的场景。致动器控制系统不一定控制致动器10,而是控制显示器10a。例如,机器学习系统60可以确定由光学传感器30检测到的场景是否可疑。传输到显示器10a的致动器控制信号a可以例如被配置为引起显示器10a突出显示被机器学习系统60认为可疑的对象。
[0057]
图7中示出了用于控制成像系统500的致动器控制系统40的实施例,成像系统500例如是mri装置、x光成像装置或超声波成像装置。传感器30例如可以是成像传感器,其感测到的图像由机器学习系统60解释。然后可以根据该解释选取致动器控制信号a,从而控制显示器10a。例如,机器学习系统60可以将所感测图像的区域解释为潜在异常。在这种情况下,致动器控制信号a可以被确定为引起显示器10a显示成像且突出显示的潜在异常区域。
[0058]
图8中示出了用于训练机器学习系统60的训练系统140的实施例。训练数据单元150确定输入信号x,输入信号x被传递给机器学习系统60。例如,训练数据单元150可以访问计算机实现的数据库q,其中存储了训练数据集合t。集合t包括输入信号x和对应的期望输出信号y
s
的对。训练数据单元150从集合t(例如随机地)选择样本。所选样本的输入信号x被传递到机器学习系统60。期望的输出信号y
s
被传递到评估单元180。
[0059]
机器学习系统60被配置为从输入信号x计算输出信号y。这些输出信号x也被传递到评估单元180。
[0060]
修改单元160取决于来自评估单元180的输入确定更新的参数。更新的参数被传输到参数存储装置p以替换当前参数。
[0061]
例如,可以设想评估单元180取决于输出信号y和期望的输出信号y
s
来确定损失函数的值。然后,修改单元160可以使用例如优化损失函数的随机梯度下降来计算更新的参数。
[0062]
更进一步地,训练系统140可以包括(一个或多个)处理器145和至少一个机器可读存储介质146,在该至少一个机器可读存储介质146上存储指令,所述指令如果被执行,则引起致动器控制系统140实行根据本发明的一个方面的方法。
[0063]
图9中示出了用于训练扩增鉴别器ad和生成器g的对抗训练系统141。现实训练样本被存储在现实训练样本数据库r中,并且被传输到扩增器au。
[0064]
随机数生成器z生成从预定义分布p(z)采样的随机数z。应当很好理解的是,计算
机生成的随机数可以是伪随机数。该理解应贯穿本专利申请隐含地假定。
[0065]
用于根据预定义分布生成随机数的方法是本领域普通技术人员公知的。例如,如果预定义分布p(z)是高斯分布,则可以通过使用公知的box
‑
muller变换从均匀分布的随机数获得随机(或伪随机)数z。随机数z被传递给生成器g。生成器g可以被定义为由生成器参数参数化的函数,并且将数字z在其输入处变换成人工训练样本。人工训练样本被传递给扩增器au。
[0066]
生成器g可以例如由人工神经网络给出,该人工神经网络的被理想地裁剪成使得人工训练样本和现实训练样本具有相同的维度的维度。
[0067]
数据序列生成器生成数据序列s。数据序列s可以是比特流。例如,数据序列生成器可以是产生均匀分布随机数的随机数生成器。该生成的数据序列s也被传递给扩增器au。
[0068]
生成器参数存储在第二参数存储装置p2中,并由第二参数存储装置p2供应给生成器g。所生成的人工训练样本被传递给扩增器au。
[0069]
扩增器au通过选择现实训练样本或人工训练样本作为训练样本x来生成训练样本x,并将所生成的训练样本x和数据序列s的对传递到扩增鉴别器ad。另外,扩增器au根据数据序列s及其对现实训练样本x的选择(即,其选择现实训练样本还是人工训练样本作为训练样本x)来计算扩增鉴别器ad的期望结果。所述期望结果被传递给评估器as。
[0070]
扩增鉴别器ad包括由鉴别器参数参数化的数学函数,例如人工神经网络。鉴别器参数存储在第二参数存储装置p2中,并且被提供给扩增鉴别器ad。使用该数学函数,扩增鉴别器ad取决于训练样本x和数据序列s计算结果r。结果r被传递给评估器as。
[0071]
取决于接收到的结果r和接收到的期望结果,评估器as计算新的鉴别器参数和/或新的生成器参数,并将它们传输到第二参数存储装置p2,以替换现有的鉴别器参数和/或生成器参数。
[0072]
更进一步地,对抗训练系统141可以包括处理器147(或多个处理器)和至少一个机器可读存储介质148,在该至少一个机器可读存储介质148上存储有指令,所述指令如果被执行,则引起对抗训练系统141实行根据本发明的一个方面的方法。
[0073]
图10中所示的流程图图示了可以由对抗训练系统141实行的用于训练生成器g和扩增鉴别器ad的方法的实施例。
[0074]
首先(1000),从训练样本数据库r检索现实的训练样本。
[0075]
然后(1100),数据序列生成器为每个检索到的现实训练样本生成预定义数量的数据序列s。优选地,对于所有检索到的现实训练样本,该预定义的数字是相同的。该数字大于1,尽管每个检索到的现实训练样本一个所生成的数据序列s也是一个选项。在优选实施例中,步骤(1000)中的检索操作包括多次从所有训练样本的集合中提取现实训练样本的可能性。然后,对于每个所提取的训练样本,生成一个对应的数据序列s。如
果再次提取相同的训练样本,则生成新的对应数据序列s(其可能与第一个相同,但很可能不同)。
[0076]
生成的数据序列s的长度可以是预定义长度。该预定义长度可以在所有迭代上是固定的。然而,在另一个实施例中,它可以即时(on
‑
the
‑
fly)增加,这取决于扩增鉴别器d的训练进度(参见下面步骤(1300)中)。
[0077]
现实训练样本然后被扩增,即,对于每个现实训练样本和对于每个生成的数据序列s,提供现实训练样本和生成的数据序列s的对()。如果预定义的数量大于一,则存在比现实训练样本更多的对。
[0078]
此外,扩增器au优选地计算对应于逻辑值“真”或“假”之一的期望结果。在优选实施例中,如果数据序列s的校验和(即,其比特值之和)是偶数,则为真,并且如果其是奇数,则为假。
[0079]
在下一步骤(1200)中,生成器g生成人工训练样本。像现实训练样本一样,数据序列生成器为每个生成的人工训练样本生成预定义数量的数据序列s。
[0080]
人工训练样本然后被扩增,即,对于每个人工训练样本和对于每个生成的数据序列s,提供人工训练样本和生成的数据序列s的对()。如果预定义的数量大于一,则存在比人工训练样本更多的对。
[0081]
此外,扩增器au计算期望的结果。在以上优选实施例中,如果数据序列s的校验和(即,其比特值之和)是奇数,则为真,并且如果其是偶数,则为假。
[0082]
然后(1300),向扩增鉴别器ad提供训练样本x和生成的数据序列s的对(x,s),该对(x,s)是在步骤(1100)中提供的现实训练样本和生成的数据序列s的对(),或者是在步骤(1200)中提供的现实训练样本和生成的数据序列s的对()。扩增鉴别器ad然后计算结果r。评估器as接收从对(x,s)获得的结果r和对应的期望结果。然后计算新的鉴别器参数(并存储在第二参数存储装置p2中),使得如果结果r和期望结果不匹配则进行惩罚的损失函数例如通过随机梯度下降被最小化。
[0083]
可选地,取决于损失函数的值,如果扩增鉴别器ad的性能优于阈值水平,则以其生成所生成的生成数据序列s的预定义长度可以针对所有后续运行而增加。
[0084]
接下来(1400),检查生成器g的训练过程是否已经收敛。如果没有收敛,则然后(1500)计算新的生成器参数(并存储在第二参数存储装置p2中),使得以上损失函数例如通过随机梯度上升被最大化。该方法然后迭代回到步骤(1100)。如果收敛,则然后(1600),在可选步骤中,可以训练被供应有现实训练样本或人工训练样本的鉴别器d,以区分被供应给它的数据样本是现实训练样本还是人工训练样本。该方法的一个可能实施例在图11中图示。该方法到此结束。
[0085]
在该方法的替代实施例中,每个生成的数据序列s可以各自与一个扩增鉴别器相关联。这些都可以作为鉴别器的系综(ensemble)被训练,其中,生成的数据序列s的每个实现导致不同的鉴别器。新的生成器参数可以通过计算平均损失(即,在系综中的所有或
一些鉴别器之上求平均)、或者通过在系综中的鉴别器之中取得最流行的结果来更新。
[0086]
图11中所示的流程图图示了如在图10的步骤(1600)中概述的用于训练鉴别器d的方法的实施例。图12中示出了用于训练鉴别器d的训练系统141的实施例。它在很大程度上与图9中所示的对抗训练系统等同。因此,将仅突出显示差异。系统不是训练扩增鉴别器ad,而是训练鉴别器d。使用选择器se,而不是使用扩增器au,选择器se接收现实训练样本和人工训练样本。然而,不需要数据序列生成器rs,也不需要数据序列s。除了扩增器au之外,选择器se仅选取现实训练样本或人工训练样本,并将其作为训练样本x传递给鉴别器d。鉴别器d计算的结果r指示鉴别器d判断接收的训练样本x是现实训练样本,还是人工训练样本。因此,期望结果指示训练样本x实际上是现实训练样本还是人工训练样本。
[0087]
图11中图示的方法开始于(2000),尤其是通过步骤(1100)
‑
(1500),利用如在图10中图示的方法训练生成器g。
[0088]
然后(2100),该预训练的生成器g生成人工训练样本。更进一步地(2200),从训练样本数据库r检索现实训练样本。
[0089]
现在(2300),向鉴别器d供应训练样本x,该训练样本x取自生成的人工训练样本或检索的现实训练样本。然后,对于每个训练样本,鉴别器d计算结果r,其指示训练样本x实际上是现实训练样本还是人工训练样本。取决于这些训练样本x,鉴别器d生成结果r。基于结果r和期望结果,根据方程(1)的内部最大化,表征鉴别器d的参数被更新为新的参数。
[0090]
可选地,现在可以确定(2400)是否已经达到停止准则。如果不是这种情况(2500),则根据方程(1),将表征生成器g的参数更新为新的参数,并且该方法迭代回到(2100)。如果确定已经达到停止准则,则该方法结束(2600)。
[0091]
通过接收输入信号x并确定该输入信号x本质上表现为现实的还是人工的,经训练的鉴别器d可以以直接的方式用作机器学习系统60的一部分。例如,如果生成器g被配置为在训练期间生成包含特定特征的信号,并且如果该特征不存在于实际训练数据中,则已经如图11中所示的算法中所例示的在具有生成器g的gan设置中被训练的鉴别器d将被训练以检测该特定特征是否存在于输入信号x中。例如,鉴别器d可以被训练来检测输入信号x是否已经被系统的入侵者修改过。然后可以根据是否已经检测到该特定特征来选取输出信号y。
[0092]
图13示出了一种方法的实施例,该方法使用经训练的扩增鉴别器ad作为用于相同目的的机器学习系统60的一部分。
[0093]
首先(3000),机器学习系统60接收输入信号x,例如图像。为每个接收的输入信号x创建数据序列s,优选为多个数据序列s。这可以通过例如使用图9中所示的数据序列生成器来实现。
[0094]
然后(3100),对于输入信号x和数据序列s的每个对(x,s),扩增鉴别器ad计算结果r。
[0095]
然后(3200),对于以上对(x,s)中的每一对,可以由生成器g生成的参考信号与
数据序列s组合,并被馈送到扩增鉴别器ad。根据该输入,扩增鉴别器ad计算参考结果。替代地,参考信号可以是取得自现实训练样本数据库r的现实训练样本之一。
[0096]
然后(3300),对于每个输入信号x,判断扩增鉴别器ad是将其分类为现实样本类型,还是人工样本类型。为此,对于每个数据序列s,将从扩增鉴别器ad获得的结果r与参考结果进行比较。如果它们相同,则输入信号x被判断为具有与参考信号相同的类型(即,如果参考信号取自现实训练样本数据库r,则为现实样本类型,并且如果参考信号由生成器g生成,则为人工样本类型)。如果它们不相同,则输入信号x被判断为具有不同于参考信号类型的类型(即,如果参考信号取自现实训练样本数据库r,则为人工样本类型,并且如果参考信号由生成器g生成,则为现实样本类型)。
[0097]
在已经生成多个数据序列s的情况下,可以通过使用所有数据序列s的多数投票来进行对输入信号x具有现实样本类型还是人工样本类型的判断。可选地,如果不存在足够清楚的多数(例如,如果判断与多数判断的不一致超过预定义比例,对于所有数据序列s的30%),则该判断可以被判断为无结论。
[0098]
最后(3400),基于对输入信号x的以上判断,可以采取不同的动作。如果输入信号x被判断为是人工样本类型(3500),则输出信号y和对应的致动器控制信号a可以被选取为使得致动器a的操作被转移到安全模式。如果输入信号x被判断为是现实采样类型(3600),则可以输出信号y可以被选取为使得维持致动器a的操作模式,即,如果它目前在正常模式下操作,则正常模式下的操作将持续。如果目前在安全模式下操作,则安全模式下的操作将持续。如果对输入信号x的判断是无结论(3700),则该输入信号x可以被忽略用于操作,并且例如输出信号y可以从先前的时间步长复制。
[0099]
图14中示出的流程图图示了一种方法的一个实施例,其中生成器g用于训练机器学习系统60,机器学习系统60可以是或可以不是致动器控制系统40的一部分。
[0100]
首先(4000),利用图10中图示的方法训练生成器g。然后(4100),使用生成器g生成人工训练样本x集合。利用合适的方法生成对应的期望输出信号y
s
。例如,可以将人工训练样本x呈现给人类专家,并且可以接收由所述人类专家输入的对应输出信号y
s
。
[0101]
(可替代地,代替由人类专家标记所有人工训练样本x,生成器g可能已经被训练成也与人工训练样本x一起生成期望的输出信号y
s
。然后,生成器g可以用于生成期望的输出信号y
s
。为了以这样的方式训练生成器g,可能的是从几个标记的训练数据样本(例如,其已经由人类专家标记)开始,并且如上面在图9和图10中所述那样训练g,其具有如下差异:训练样本x将必须全部由训练样本x和对应的输出信号y
s
的对(x,y
s
)替换。
[0102]
人工训练样本x和对应的输出信号y
s
的对(x,y
s
)可以被添加到训练数据集t,并存储在计算机实现的数据库q中。
[0103]
然后可以使用训练系统140训练机器学习系统60(4200)。致动器控制系统40然后可以取决于由机器学习系统60生成的输出信号y来控制(4300)致动器10和/或显示单元10a。该方法到此结束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1