一种用于高效处理汇集数据的云平台和方法与流程
一种用于高效处理汇集数据的云平台和方法
1.本发明涉及一种用于高效处理由云平台的用户共享的汇集数据(pooled data)的计算机实现方法。
2.云平台经由网络连接到不同用户或客户的多个客户端设备。客户端设备可以将数据上载到云平台的数据库。这些数据可以包括例如由相应用户的工业系统中的机器的传感器生成的传感器数据。此外,云平台可以向云平台的用户提供不同的服务。这些服务可以包括在云平台的数据库中存储的用户数据上执行过程。例如,用户可以调用云平台上的分析过程,该过程分析所存储的用户数据(诸如,传感器数据)以发现有用的信息。该平台经由网络将分析过程的结果返回给用户的客户端设备。这些过程还可以包括用于数据模型的机器学习的训练过程、测试过程和/或推理过程。然而,常规的云平台没有提供如下机制:该机制允许用户自动汇集他们的个体数据以生成数据池,以使得用户在云平台内对汇集数据的高效处理成为可能。
3.us 2018/181641 a1公开了基于数据集的相似性来推荐分析任务。一种系统包括数据处理器、匹配模块和推荐模块。数据处理器接收传入数据集,并且针对传入数据集生成特征向量。匹配模块确定所生成的特征向量与数据库中的多个数据集的代表性特征向量之间的相似性度量,并且基于该相似性度量来选择该多个数据集中的至少一个数据集。推荐模块标识与所选数据集相关联的至少一个分析任务,并且推荐要对传入数据集执行的至少一个分析任务。
4.us 2014/195818 a1公开了一种对数据以及与该数据相关联的隐私属性进行加密的用户设备。处理设备接收经加密的数据和隐私属性,从请求者接收经签名的脚本,并且验证该签名。如果成功验证,则私钥被解封并且用于对隐私属性和脚本属性进行解密,隐私属性和脚本属性被比较以确定该脚本是否尊重隐私属性。如果是,则加密数据被解密,并且该脚本处理私有数据以生成使用请求者的密钥而被加密的结果,并且然后该加密结果被输出。
5.因此,本发明的目的是提供一种用于高效处理由云平台的用户共享的汇集数据的方法和系统。
6.根据本发明的第一方面,该目的通过包括权利要求1的特征的计算机实现方法来实现。
7.根据第一方面,本发明提供了一种用于高效处理由云平台的用户共享的汇集数据的计算机实现方法,所述方法包括以下步骤:由用户的客户端设备将至少一个数据集上载到云平台,计算相似性得分,相似性得分指示当前上载的数据集与先前由其他用户的客户端设备上载的数据集之间的相似性程度,以及基于汇集数据来执行由云平台上的用户选择的过程,所述汇集数据包括相应用户的当前数据集以及先前从其他用户的客户端设备上载的、存储在云平台的数据库中的数据集,所述先前从其他用户的客户端设备上载的数据集具有与相应用户的当前上载的数据集相关的、超过可配置相似性得分阈值的所计算的相似性得分,
其中已经在云平台上上载了当前数据集的用户的客户端设备从云平台接收推荐消息,以对云平台的其他用户的、与当前数据集相匹配的数据集进行汇集,以及其中如果云平台从用户的客户端设备接收到用以对数据集进行汇集的接受消息,则自动对所述匹配数据集进行汇集以生成数据集池。
8.在根据本发明的第一方面的方法的可能实施例中,由云平台基于所述汇集数据来执行的过程包括用于训练数据模型的训练过程。
9.在根据本发明的第一方面的方法的进一步可能实施例中,由云平台基于所述汇集数据来执行的过程包括用于测试经训练的数据模型的测试过程。
10.在根据本发明的第一方面的方法的进一步可能实施例中,由云平台基于所述汇集数据来执行的过程包括用于执行经训练和测试的数据模型的推理过程。
11.在根据本发明的第一方面的方法的可能实施例中,所使用的数据模型包括人工神经网络。
12.在根据本发明的第一方面的方法的进一步可能实施例中,针对每个所上载的数据集,计算表示向量,所述表示向量包括表示所上载的数据集的统计性质的向量元素。
13.在根据本发明的第一方面的方法的进一步可能实施例中,基于所上载的数据集的所述表示向量来计算指示所上载的数据集之间的相似性程度的相似性得分。
14.在根据本发明的第一方面的方法的仍进一步可能实施例中,所计算的相似性得分包括余弦相似性得分。
15.在根据本发明的第一方面的方法的仍进一步可能实施例中,如果针对当前上载的数据集所计算的、与另一用户的先前上载的数据集相关的相似性得分超过可配置相似性得分阈值,则将相应的先前上载并存储的数据集标记为关于由用户的客户端设备当前上载的数据集的匹配数据集。
16.在根据本发明的第一方面的方法的仍进一步可能实施例中,所述汇集数据包括被标记为匹配数据集的从不同用户的客户端设备上载的数据集。
17.在根据本发明的第一方面的方法的仍进一步可能实施例中,响应于从相应用户的客户端设备上载新的当前数据集而触发计算关于存储在所述云平台的数据库中的其他用户的先前上载的数据集的相似性得分。
18.在根据本发明的第一方面的方法的仍进一步可能实施例中,所述匹配数据集在它们被汇集以生成数据集池之前经历同态加密。
19.在根据本发明的第一方面的方法的仍进一步可能实施例中,在云平台上既基于所生成的数据集池并且又基于由用户的客户端设备在云平台上上载的当前数据集来执行由用户选择的过程以计算基准(benchmark),所述基准指示在通过所选过程来处理所上载的数据集方面的效率增加,所述效率增加是由数据汇集引起的。
20.在根据本发明的第一方面的方法的进一步可能实施例中,由云平台将所计算的基准发送到用户的客户端设备。
21.在根据本发明的第一方面的方法的可能实施例中,数据集包括被加标签的数据。
22.在根据本发明的第一方面的方法的进一步可能实施例中,数据集包括未加标签的数据。
23.根据进一步的第二方面,本发明进一步提供了一种包括权利要求16的特征的云平
台。
24.根据第二方面,本发明提供了一种用于高效处理由云平台的用户共享的汇集数据的云平台,其中云平台包括:数据库,其被适配成存储由用户的客户端设备上载到云平台的数据集,得分计算单元,其被配置成计算相似性得分,每个相似性得分指示当前上载的数据集与存储在所述数据库中的先前上载的数据集之间的相似性程度,以及处理器,其被适配成基于汇集数据来执行由用户选择的过程,所述汇集数据包括相应用户的当前上载的数据集和其他用户的先前上载的数据集,所述其他用户的先前上载的数据集具有与相应用户的当前上载的数据集相关的、超过可配置相似性阈值的所计算的相似性得分,其中已经在云平台上上载了当前数据集的用户的客户端设备从云平台接收推荐消息,以对云平台的其他用户的、与当前数据集相匹配的数据集进行汇集,以及其中如果云平台从用户的客户端设备接收到用以对数据集进行汇集的接受消息,则自动对所述匹配数据集进行汇集以生成数据集池。
25.在下文中,参考附图更详细地描述了本发明的不同方面的可能实施例。
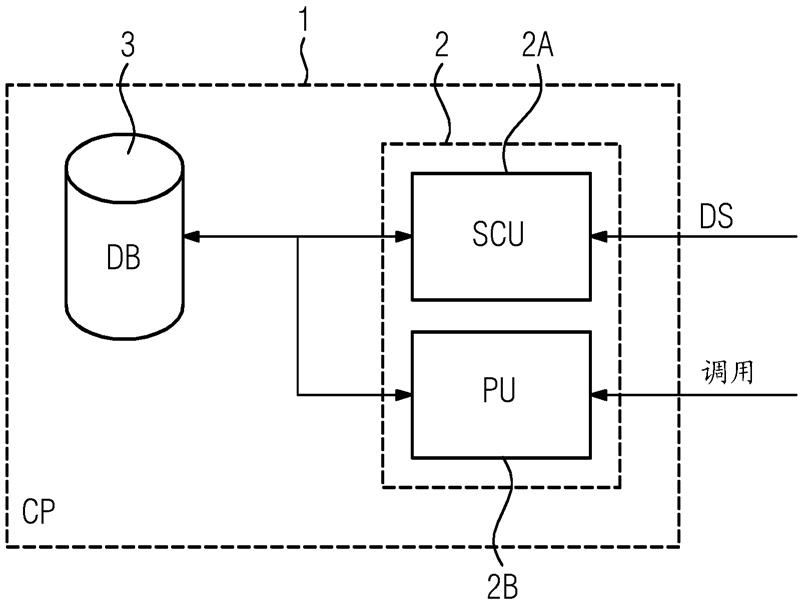
26.图1示出了根据本发明的第一方面的计算机实现方法的可能示例性实施例的流程图;图2示出了根据本发明的进一步方面的云平台的可能示例性实施例的框图;图3示出了用于说明根据本发明的用于高效处理由云平台的用户共享的汇集数据的计算机实现方法的操作的信号图。
27.从图1的流程图中可以看出,在所图示的实施例中,根据本发明的第一方面的用于高效处理由云平台1的用户共享的汇集数据的计算机实现方法包括三个主要步骤。
28.在第一步骤s1中,由用户的客户端设备将至少一个数据集ds上载到云平台1。数据集ds经由网络从用户的客户端设备被上载到云平台1的服务器2,服务器2还如图2的框图中所图示的那样实现了得分计算单元2a和处理单元2b。数据集ds可以包括被加标签的数据或未加标签的数据。数据集ds可以例如包括由用户的机器的传感器所生成并且由客户端设备上载到云平台1的传感器数据。客户端设备可以包括自动化系统的边缘设备。在可能的实施例中,诸如传感器数据之类的用户数据可以经历由客户端设备的处理器执行的预处理。在可能的实施例中,数据集ds可以包括数据结构或数据分组。数据集ds的数据结构可以包括描述所上载的用户数据的元数据。在可能的实施例中,客户端设备经由网络将数据集ds推送到云平台1。在替代实施例中,云平台1可以例如周期性地从用户的客户端设备拉取数据集ds。
29.在进一步的步骤s2中,计算相似性得分ss,相似性得分ss指示当前上载的数据集ds与先前由其他用户的客户端设备上载的其他数据集ds之间的相似性程度。在可能的实施例中,针对每个所上载的数据集ds,计算表示向量,该表示向量包括表示所上载的数据集ds的统计性质的向量元素。这些统计性质可以例如包括平均值或标准差等。表示向量可以包括给定数据集ds的最常见的统计特征。在可能的实施例中,在步骤s2中基于所上载的数据集ds的表示向量来计算指示所上载的数据集之间的相似性程度的相似性得分ss。在可能的实施例中,所计算的相似性得分ss可以包括余弦相似性得分。在可能的实施例中,如果针对
当前上载的数据集ds所计算的、与另一用户的先前上载的数据集ds相关的相似性得分ss超过可配置相似性得分阈值,则可以将相应的先前上载并存储的数据集ds标记为关于由用户的客户端设备当前上载的数据集ds的匹配数据集ds。因此,每当两个数据集ds之间的成对相似性超过可配置阈值时,平台1就可以将其表示为匹配。
30.在进一步的步骤s3中,基于汇集数据来执行由云平台1上的用户选择的过程。汇集数据可以包括由相应用户最近上载的该用户的当前数据集ds以及先前从其他用户的客户端设备上载的、存储在云平台1的数据库3中的数据集ds,该先前从其他用户的客户端设备上载的数据集ds具有与相应用户的当前上载的数据集ds相关的、超过可配置相似性得分阈值th的所计算的相似性得分ss。
31.在可能的实施例中,可配置相似性得分阈值th由云平台1的服务提供商来设置。在替代实施例中,可配置相似性得分阈值th可以通过用户选择将由云平台1的处理单元2b执行的过程来应用。在该实施例中,云平台1的用户可以调整所需的相似性得分阈值th,以定义其他用户的其他数据集ds必须与他自己提供的数据集ds相似的程度。
32.为了在步骤s3中选择该过程,用户的客户端设备可以调用由云平台1提供的过程。该过程可以是例如对汇集数据集ds执行数据分析的分析过程。分析过程可以例如是预测用户的自动化系统的组件可能何时发生故障的预测性维护过程。该分析预测性维护过程当在包括多个用户的数据集ds的多个汇集数据上执行时更加准确,该多个用户在其相应的自动化系统中具有相似或相同的机器。
33.在可能的实施例中,由用户选择的过程还可以包括用于训练数据模型、特别是人工神经网络ann的训练过程。由用户选择或调用的过程还可以包括用于测试经训练的数据模型、特别是经训练的人工神经网络ann的测试过程。由用户选择或调用的过程可以进一步包括用于执行经训练和测试的数据模型、特别是经训练和测试的人工神经网络ann的推理过程。
34.云平台1取决于所计算的相似性得分ss来执行对数据集ds的汇集。汇集数据包括被标记为匹配数据集ds的从不同用户的客户端设备上载的数据集ds。在可能的实施例中,可以响应于从相应用户的客户端设备上载新的当前数据集ds而触发在步骤s2中关于存储在云平台1的数据库3中的其他用户的先前上载的数据集ds的相似性得分ss的计算。已经将当前数据集ds上载到云平台1上的用户的客户端设备从云平台1接收推荐消息,以对云平台1的其他用户的、与当前数据相匹配——即,具有与相应用户的当前上载的数据集ds相关的、超过可配置相似性得分阈值th的所计算的相似性得分ss——的数据集ds进行汇集。仅在云平台1从用户的客户端设备接收到用以对数据集ds进行汇集的接受消息的情况下,才自动对匹配数据集ds进行汇集以生成数据集池。用户可以具有对是否将他的数据集ds与其他用户的数据集ds进行汇集的完全控制。
35.在根据本发明的计算机实现方法的可能实施例中,匹配数据集ds在它们被汇集以生成数据集ds之前经历同态加密。因此,在用户之间共享数据之前,对数据应用同态加密。同态加密是一种用于对数据进行加密的方式,该方式允许执行计算,使得在被加密时该计算的结果与对未加密数据的相同计算过程的结果相匹配。同态加密用于安全外包计算,即在云平台1的处理资源上执行所选过程。
36.在根据本发明的第一方面的计算机实现方法的进一步可能实施例中,在云平台1
的处理器上、既基于所生成的数据集池并且又基于由用户的客户端设备在云平台1上上载的当前数据集ds来执行由用户选择的过程以计算基准,该基准指示在作为所选过程来处理所上载的数据集ds方面的效率增加,该效率增加是由数据汇集引起的。在可能的实施例中,所计算的基准可以由云平台1发送回用户的客户端设备。在该实施例中,向用户通知数据汇集对所执行过程的结果的影响。可以向用户通知由数据汇集引起的、在执行该过程方面的效率增加。
37.图2示出了根据本发明的一方面的云平台1的可能示例性实施例的框图。云平台1用于高效处理由云平台1的用户共享的汇集数据。多个客户端设备可以经由网络、特别是互联网连接到云平台1。如图2中所图示的云平台1可以包括有权访问数据库3的服务器2。数据库3可以是中央数据库,但是也可以是分布式数据库。在所图示的示例性实施例中,服务器2可以实现得分计算单元(scu)2a和处理单元(pu)2b。得分计算单元2a被配置成计算相似性得分ss,每个相似性得分ss指示至少一个当前上载的数据集ds与存储在云平台1的数据库3中的先前上载的数据集ds之间的相似性程度。服务器2的处理单元2b可以被适配成基于汇集数据来执行由用户选择或调用的过程,该汇集数据包括相应用户的当前上载的数据集ds和其他用户的先前上载的数据集,该其他用户的先前上载的数据集具有与相应用户的当前上载的数据集ds相关的、超过可配置相似性阈值th的所计算的相似性得分ss。相似性阈值th可以由云平台1的提供商来配置,或者可以由用户的客户端设备在调用相应过程时提交给云平台1。在可能的实施例中,由处理单元2b基于汇集数据执行的过程可以包括分析汇集数据的分析过程。由处理单元2b执行的过程还可以包括用于训练数据模型的训练过程、用于测试经训练的数据模型的测试过程、和/或用于执行经训练和测试的数据模型的推理过程。在可能的实施例中,该数据模型可以包括人工神经网络ann,例如前馈神经网络或递归神经网络。人工神经网络ann可以由输入层、若干个隐藏层、以及输出层组成。在可能的实施例中,用户可以指示所上载的数据集ds是否将用于特定数据模型的训练过程、测试过程和/或推理过程。在可能的实施例中,用户还可以指定所使用的数据模型的类型,特别是用于相应的所调用过程的人工神经网络ann的类型。处理单元2b被适配成基于汇集数据来执行由用户选择的过程,该汇集数据包括相应用户的当前上载的数据集ds和其他用户的先前上载的数据集ds,该其他用户的先前上载的数据集ds具有与相应用户的当前上载的数据集ds相关的、超过可配置相似性阈值th的所计算的相似性得分ss。该过程的计算结果可以被返回到已经调用了该过程的用户的客户端设备。此外,在可能的实施例中,用户的客户端设备可以接收基准,该基准指示在通过所选过程来处理所上载的数据集ds方面的效率增加,该效率增加是由所执行的数据汇集引起的。
38.图3示出了用于说明用于高效处理由云平台1的用户共享的汇集数据的计算机实现方法的操作的图。在所图示的示例中,两个用户a、b经由数据网络连接到公共云平台cp,诸如图2中所图示的云平台1。在所图示的示例中,第一用户a将数据集ds
a
上载到云平台cp。基于所上载的数据集ds
a
,云平台1计算表示向量v
a
,该表示向量v
a
包括表示所上载的数据集ds
a
的统计性质(诸如,平均值或标准差)的向量元素。
39.当另一用户b将数据集ds
b
上载到云平台时,用与图3中所图示的方式相同的方式来计算表示向量v
b
。基于所计算的两个表示向量v
a
、v
b
,使用预定义的相似性得分函数来计算相似性得分ss。在可能的实施例中,由云平台1的处理单元2b所计算的相似性得分ss包括
余弦相似性得分。处理单元2b包括比较器,该比较器被适配成将所计算的相似性得分ss与可配置相似性得分阈值th进行比较,如图3中所图示。在所图示的实施例中,如果所计算的相似性得分ss超过预配置的相似性得分阈值th,则用户a、b两者从云平台1接收用以共享其数据的推荐rec。由云平台1的服务器2将推荐rec传输到用户a、b的客户端设备。已经将当前数据集ds上载到云平台1上的用户的客户端设备从云平台1接收推荐消息rec,以将他的数据集ds与云平台1的其他用户的、跟当前数据集ds相匹配(即,具有超过阈值th的相似性得分ss)的数据集ds进行汇集。如果云平台1从相应用户的客户端设备接收到用以对数据集ds进行汇集的接受消息acc,则自动对匹配数据集ds进行汇集以生成数据集池,也如图3中所图示。在可能的实施例中,匹配数据集ds在它们被汇集以生成数据集池之前自动经历由服务器2的处理单元2b执行的同态加密。基于汇集数据在云平台1上执行由用户选择的过程p。在图3中所图示的示例中,用户a调用了不仅对用户a的数据集ds
a
执行而且还对用户b的数据集ds
b
执行的过程p。所调用的过程的结果被返回到用户a的客户端设备,如图3中所示。类似地,如果另一用户b调用了相同的过程p,则也对该汇集数据执行该过程,该汇集数据包括用户a的数据集ds
a
和用户b的数据集ds
b
,如图3中所示。所调用的过程p的结果被返回到用户b的客户端设备,如图3中所示。
40.在进一步可能实施例中,还可以既基于提供了第一结果的所生成的数据集池并且又基于由用户的客户端设备上载的当前数据集ds来执行所调用的过程p,以仅提供进一步的结果,其中这两个结果之间的差异可以形成基准,该基准指示在通过所调用的过程来处理所上载的数据集ds方面的效率增加,该效率增加是由数据汇集引起的。在该实施例中,用户可以认识到由数据汇集引起的效率增加,并且当下一次从云平台1接收到推荐消息rec时,用户将更可能接受数据汇集。在可能的实施例中,效率增加可以由云平台1来计算并且提供给用户的客户端设备,以便经由客户端设备的用户界面向用户显示。大多数分析过程被设计成使得它们从尽可能多的数据中受益,并且如果来自不同用户的许多数据集被汇集在数据池中,则可以更高效地执行这些分析过程。当执行机器学习数据模型、特别是人工神经网络ann的训练过程时,数据汇集特别有益。在可能的实施例中,云平台1可以监测正在联合平台上构建机器学习模型的用户,并且可以向他们通知将数据汇集在一起的益处。为了增加安全性,在与数据池中的其他用户共享所提供的数据之前,可以对所提供的数据进行加密。在优选实施例中,所提供的用户数据在被汇集到数据池中之前经历同态加密。该计算机实现方法允许在云平台1上自动共享用户数据。在可能的实施例中,汇集数据用于训练数据模型、特别是人工神经网络ann。数据模型是根据如下数据来训练的:该数据在可能的实施例中可以通过可能以docker容器、shell脚本、knime工作流等形式出现的配方(recipe)来定义。
41.分析服务或过程p可以由云平台1提供,以通过在指定数据集ds上执行这些配方来训练和/或构建数据模型。在可能的实施例中,根据本发明的计算机实现方法可以在组合的汇集数据集ds上自动重新训练用户的数据模型。云平台1提供了一种反馈机制,该反馈机制向用户通知对其数据进行汇集的预期益处或已实现的益处。在得分计算单元2a中实现的数据评估引擎可以测量数据集ds之间的相似性水平,并且决定对它们进行组合是否是有意义的。在可能的实施例中,由云平台1的用户的客户端设备上载的每个数据集ds可以计算并组合两个数字向量。第一向量v包含最常见的统计特征,诸如给定数据集ds的平均值或标准
差。第二向量可以包含对于云平台1上可用的相应过程p高度相关的特征。每当新的过程p被引入到云平台1中时,可以用附加特征来增强第二向量。
42.由云平台1的不同用户上载的每对数据集ds可以基于表示向量来计算相似性得分ss。存在可以被得分计算单元2a用于该目的的许多不同的相似性度量,诸如余弦相似性。每当两个数据集ds之间的成对相似性超过可配置阈值时,得分计算单元2a就可以将其表示为匹配数据集ds。
43.每当云平台1检测到匹配时,就有理由相信这些用户正在对其进行工作的数据集ds是相似的。云平台1然后可以比较这些用户通常在他们的数据上调用的过程p。如果检测到匹配,则明显的是,两个用户都可以受益于在他们之间共享数据。云平台1然后可以向两个用户发布推荐rec以在他们之间共享他们的数据,从而改进所执行的过程的结果的质量。例如,如果所执行的过程p是训练过程,则经机器学习的数据模型的质量会增加。
44.可选地,在发布推荐rec之前,云平台1可以在汇集数据的组合数据集ds上重新训练用户先前创建的数据模型中的一些,以量化这些数据模型的质量中的改进。
45.如果用户接受用以共享数据集ds的推荐rec,则每当用户之一调用了相应过程p时,云平台1就可以对组合的数据集ds执行相同的动作。所执行的过程p的结果可以变得对于两个所涉及的用户都是可获得的。为了确保用户的数据隐私,在共享数据之前对数据集ds应用同态加密。替代地,诸如训练数据模型之类的过程的执行可以在其中数据对于用户不可获得的云平台1的安全环境中执行。在可能的实施例中,云平台1可以自动标识将受益于共享其数据集ds中包含的数据或信息的用户。云平台1提供了对于用户上载和共享其数据的鼓励。例如,用于训练数据模型的共享数据为需要较少的被加标签数据的用户带来了更好的数据模型。由于收集被加标签的数据是昂贵且耗时的,因此云平台1显著增加了在训练数据模型时的效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1